







Exploring Lottery Prompts for Pre-trained Language Models
清深的工作,比较有意思的一篇。作者先给出假设,对于分类问题,在有限的语料空间内总能找到一个prompt让这个问题分类正确,作者称之为lottery prompt。为此,作者组织了一个prompt集合,每个prompt的组成都很简单,名词+动词+介词/形容词/副词+<MASK>,语料都是从常用英语词库中选出的,整个prompt集合一共包含76725个prompt。
之后,作者在RoBERTa-large和GPT-2上进行了测试,每个数据集1000个样例,对于每个样例,只要76725个prompt里有一个prompt能让模型预测正确,那么就算这个样例回答正确,结果表明几乎每个输入都有一个prompt可以作对这个分类。说明至少对于这些分类问题,lottery prompt是存在的。

之后作者分析了搜索到一个正确的prompt所需要的次数,这里的搜索按照作者的说法其实就是在7w个prompt里面枚举的。发现任务越困难,需要的搜索次数就越多,同时在同一个任务中,需要的搜索次数多的也是困难的输入。
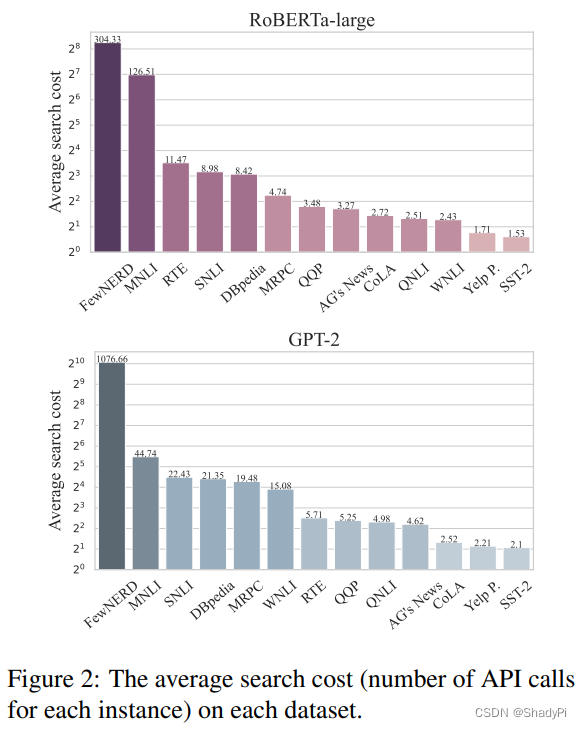
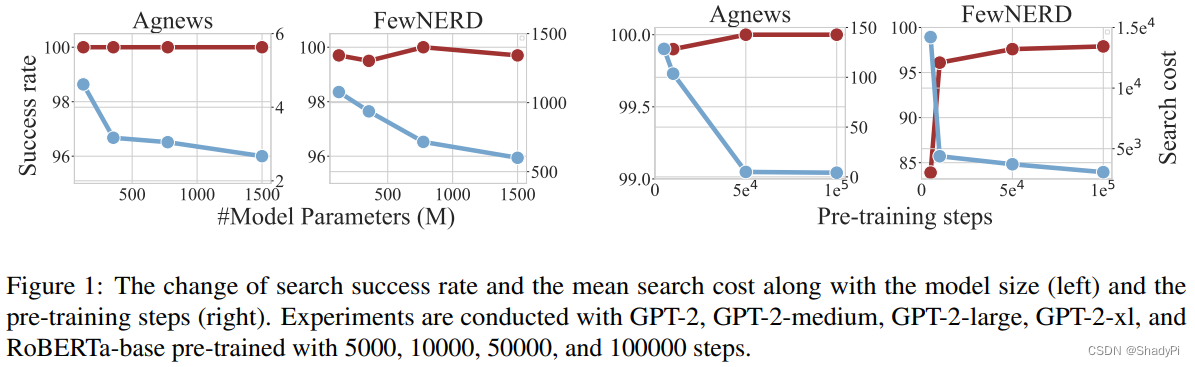
而模型的能力也对搜索次数有影响,越大的模型需要的搜索次数越少。同时没有训练过的模型很难找到有效的prompt,经过一定的训练后成功找到的概率则显著上升,搜索次数显著下降。这说明lottery prompt存在确实不是考运气,而是基于模型确实掌握了语言知识。
除了多个prompt对一个input,那自然也有一个prompt对多个input,作者统计了prompt在整个数据集上的表现,除了有66个类的最难的Few-NERD,其他数据集都能找到一个表现不错的prompt。
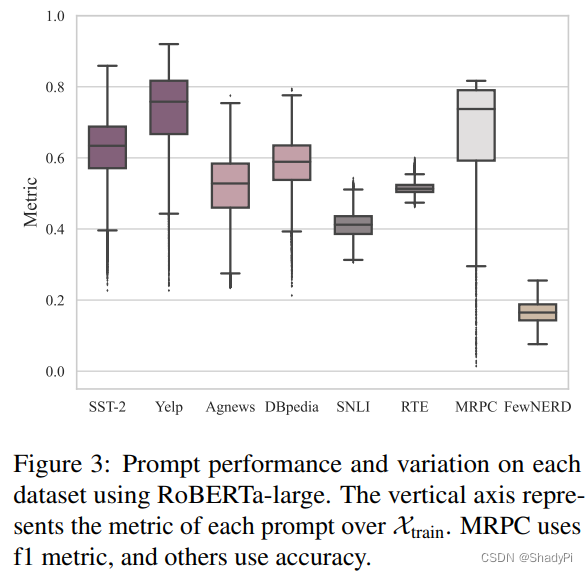
分析这些优秀的prompt作者也发现他们有一些相似的特征,这里就不详述了。
基于此,作者提出了一种集成prompt方法,在少量的训练集上选出优秀的prompt以后,根据他们的表现赋予不同的权重,表现越好的prompt权重越高,之后将这些prompt的分类预测加权在一起,得到最后的分类。他们的整个集合只有10个prompt,训练集大小为16shot和32shot,效果惊人的不错。

这个方法可以说是很简洁,得到的prompt结构都很简单,集成方式同样简单,整个方法甚至都没有参数,但是打败了像RLPrompt这样参数量巨大的prompt方式。
















 1637
1637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











