







Hui Liu, Wenya Wang, and Haoliang Li. 2023. Interpretable Multimodal Misinformation Detection with Logic Reasoning. In Findings of the Association for Computational Linguistics: ACL 2023, pages 9781–9796, Toronto, Canada. Association for Computational Linguistics.
核心:多模态、可解释
基本架构
输入为文本 T T T和图片 I I I,(此处貌似只允许输入一张图片,而实际上情况中可能不止一张)
使用Tokenizer处理 T T T,另用CNN处理 I I I,将处理后的feature用GCN组合到一起得到object o o o,由
Methodology
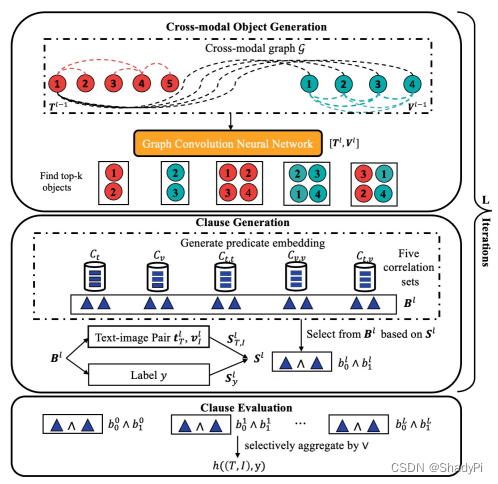
Feature Extraction
对于文本 T T T,先将其分割成 m m m个token,对每个token再使用BERT+一层LSTM将其转换为 d d d维的向量 X T \textbf{X}_T XT, m m m个token总共得到 T ∈ R m × d \textbf{T}\in \mathcal{R}^{m\times d} T∈Rm×d
对于图片 I I I,先resize到 224 × 224 224\times224 224×224,再划分为 z = r 2 z=r^2 z=r2个patch,每个patch大小为 224 / z × 224 / z 224/z\times224/z 224/z×224/z,每个patch使用ResNet34+ViT+2层MLP转化为 d d d为向量 X I \textbf{X}_I XI,最后得到 I ∈ R r × d \textbf{I}\in \mathcal{R}^{r\times d} I∈Rr×d
Cross-modal Object Generation
在这一步,生成单模态和跨模态的隐式表征。
在这篇工作中,定义了5种Object,分别是单文本、单图像、双文本、双图像以及文本图像混合,如下所示。

在上一步得到若干feature后,我们通过GCN将这些feature结合起来,将之前提取出的
X
T
,
X
I
\textbf{X}_T,\ \textbf{X}_I
XT, XI当作GCN中的节点,这些节点的embedding就是一个
d
d
d维向量。在连GCN的边时,使用Spacy技术寻找token之间的依赖关系,在存在依赖关系的token之间连边,而对每个patch则是将在原图片里相邻的patch连在一起,而文本和图片之间则是直接全连接的。
GCN的初始输入 H 0 = [ T , I ] ∈ R ( m + r ) × d \textbf{H}^0=[\textbf{T},\textbf{I}]\in\mathcal{R}^{(m+r)\times d} H0=[T,I]∈R(m+r)×d,邻接矩阵 A ∈ R ( m + r ) × ( m + r ) \textbf{A}\in \mathcal{R}^{(m+r)\times (m+r)} A∈R(m+r)×(m+r) ,每一层graph都有一个线性变换权重矩阵 W ∈ R d × d W\in\mathcal{R}^{d\times d} W∈Rd×d,整个GCN的转移方程为 H l = ReLU ( D − 1 2 A D − 1 2 H l − 1 W l ) \textbf{H}^l=\text{ReLU}(\textbf{D}^{-\frac{1}{2}}\textbf{A}\textbf{D}^{-\frac{1}{2}}\textbf{H}^{l-1}\textbf{W}^l) Hl=ReLU(D−21AD−21Hl−1Wl)。如此即可得到每一层的每个节点的feature,即 H l = [ T l , V l ] , l ∈ { 0 , 1 , 2 , ⋯ , L } \textbf{H}^l=[\textbf{T}^l, \textbf{V}^l], l\in \{0, 1, 2, \cdots, L\} Hl=[Tl,Vl],l∈{0,1,2,⋯,L}。
利用这些feature,即可根据上表中的公式计算出每层的5种Objects,分别是 O t l ∈ R m × d , O v l ∈ R r × d , O t , t l ∈ R ( m × m ) × d , O v , v l ∈ R ( r × r ) × d , O t , v l ∈ R ( m × r ) × d \textbf{O}_t^l\in\mathcal{R}^{m\times d},\textbf{O}_v^l\in\mathcal{R}^{r\times d},\textbf{O}_{t,t}^l\in\mathcal{R}^{(m\times m)\times d},\textbf{O}_{v,v}^l\in\mathcal{R}^{(r\times r)\times d},\textbf{O}_{t,v}^l\in\mathcal{R}^{(m\times r)\times d} Otl∈Rm×d,Ovl∈Rr×d,Ot,tl∈R(m×m)×d,Ov,vl∈R(r×r)×d,Ot,vl∈R(m×r)×d
每种 O \textbf{O} O中的小 o ∈ R d \textbf{o}\in \mathcal{R}^{d} o∈Rd会再通过一个一层+ReLU的MLP,得到一个分数。每个种类的 O \textbf{O} O种top-k的object会被抽出,记作 O ^ t l , O ^ v l , O ^ t , t l , O ^ v , v l , O ^ t , v l \hat{\textbf{O}}_t^l,\hat{\textbf{O}}_v^l,\hat{\textbf{O}}_{t,t}^l,\hat{\textbf{O}}_{v,v}^l,\hat{\textbf{O}}_{t,v}^l O^tl,O^vl,O^t,tl,O^v,vl,O^t,vl,均属于 R k × d \mathcal{R}^{k\times d} Rk×d。为了让这个过程可以反向传播,实现的时候可以通过disable其他非top-k的节点实现。
Clause Generation
得到这些object的feature之后,我们就要计算他们支持不同label的概率,首先要得到对应body predicate,比如
b
t
(
t
,
y
)
b_t(t,y)
bt(t,y) 的表征,记作
B
t
∈
R
k
×
d
\textbf{B}_t\in \mathcal{R}^{k\times d}
Bt∈Rk×d,其他同理。
B
t
\textbf{B}_t
Bt计算如下
B
t
=
sparsemax
(
[
O
^
t
,
y
]
W
t
e
C
t
T
)
C
T
\textbf{B}_t=\text{sparsemax}([\hat{\textbf{O}}_t,\textbf{y}]\textbf{W}_t^e\textbf{C}_t^T)\textbf{C}^T
Bt=sparsemax([O^t,y]WteCtT)CT
[
O
^
t
,
y
]
∈
R
k
×
2
d
,
其中
y
∈
R
k
×
d
[\hat{\textbf{O}}_t,\textbf{y}]\in\mathcal{R}^{k\times 2d}, 其中\textbf{y}\in\mathcal{R}^{k\times d}
[O^t,y]∈Rk×2d,其中y∈Rk×d为label的
d
d
d维表征广播为
k
×
d
k\times d
k×d的产物,
W
t
e
∈
R
2
d
×
d
\textbf{W}_t^e\in\mathcal{R}^{2d\times d}
Wte∈R2d×d为可学习参数,
C
t
∈
R
g
×
d
\textbf{C}_t\in\mathcal{R}^{g\times d}
Ct∈Rg×d则是预先定义的correlation(这里的“预先定义”指每个correlation对应的predicate是先定义好的,实际上也是随机初始化的)但在训练过程中也是可学习的。
以此类推,我们也可以得到其他几种predicate的表征, B = [ B t , B v , B t , t , B v , v , B t , v ] ∈ R 5 k × d \textbf{B}=[\textbf{B}_t,\textbf{B}_v,\textbf{B}_{t,t},\textbf{B}_{v,v},\textbf{B}_{t,v}]\in\mathcal{R}^{5k\times d} B=[Bt,Bv,Bt,t,Bv,v,Bt,v]∈R5k×d(这应该只是一个label对应的表征,严格来说应该写作 B y \textbf{B}_y By作为区分)。
除了这几个从GCN里提取的表征,我们还对整个文本和图片进行了编码,文本的编码 t T = T T softmax ( T W T ) ∈ R d \textbf{t}_T=\textbf{T}^T\text{softmax}(\textbf{T}\textbf{W}_T)\in\mathcal{R}^d tT=TTsoftmax(TWT)∈Rd,图片的编码 v I = V T softmax ( V W I ) ∈ R d \textbf{v}_I=\textbf{V}^T\text{softmax}(\textbf{V}\textbf{W}_I)\in\mathcal{R}^d vI=VTsoftmax(VWI)∈Rd,其中 W T , W I \textbf{W}_T,\textbf{W}_I WT,WI均属于 R d × 1 \mathcal{R}^{d\times 1} Rd×1为可学习参数,注意与之前一层的打分MLP不是参数共用的。
接下来,我们计算两种attention score,分别是
S
T
,
I
=
sparsemax
(
B
X
T
,
I
[
t
T
,
v
I
]
)
,
S
y
=
sparsemax
(
[
B
,
y
,
B
−
y
,
B
∘
y
]
W
y
)
\textbf{S}_{T,I}=\text{sparsemax}(\textbf{B}\textbf{X}_{T,I}[\textbf{t}_T,\text{v}_I]),\\ \textbf{S}_y=\text{sparsemax}([\textbf{B},\textbf{y},\textbf{B}-\textbf{y},\textbf{B}\circ\textbf{y}]\textbf{W}_y)
ST,I=sparsemax(BXT,I[tT,vI]),Sy=sparsemax([B,y,B−y,B∘y]Wy)其中,
X
T
,
I
∈
R
d
×
2
d
,
W
y
∈
R
4
d
×
1
\textbf{X}_{T,I}\in\mathcal{R}^{d\times 2d}, \textbf{W}_y\in\mathcal{R}^{4d\times 1}
XT,I∈Rd×2d,Wy∈R4d×1均为可学习参数。这两个分数一个注重news的内容(文本和图片),另一个注重和label的关系,最终两个score再合为一个score,
S
∈
R
5
k
\textbf{S}\in\mathcal{R}^{5k}
S∈R5k
S
=
sparsemax
(
S
T
,
I
∘
S
y
)
\textbf{S}=\text{sparsemax}(\textbf{S}_{T,I}\circ\textbf{S}_y)
S=sparsemax(ST,I∘Sy)每个分数描述了其对应的clause(根据我的理解,predicate是模板,填入内容后称为clause)与判断整个news是否为真的相关性,因此我们并不需要将整个
5
k
5k
5k个clause全部用到,而是筛选其中一部分,即top-
⌊
5
k
×
β
⌋
\lfloor5k\times \beta\rfloor
⌊5k×β⌋的predicate。这些筛选出的clause进入下一个step。
Clause Evaluation
以上只是生成clause的过程,最终目的还是要判断这个news是不是真的。从可解释性的角度出发,一个news为不为真的可以从某些clause为不为真推导出来,因此我们需要先得到这些clause为真的概率。
对于
b
t
(
t
,
y
)
b_{t}(t,y)
bt(t,y),他的truth value可以计算为:
μ
(
b
t
(
t
,
y
)
)
=
sigmoid
(
[
b
t
,
p
,
b
t
−
p
,
b
t
∘
p
]
W
μ
)
\mu(b_{t}(t,y))=\text{sigmoid}([\textbf{b}_t,\textbf{p},\textbf{b}_t-\textbf{p},\textbf{b}_t\circ\textbf{p}]\textbf{W}_{\mu})
μ(bt(t,y))=sigmoid([bt,p,bt−p,bt∘p]Wμ)其中,
p
=
o
t
∘
y
∈
R
d
,
W
μ
∈
R
4
d
×
1
\textbf{p}=\textbf{o}_t\circ\textbf{y}\in\mathcal{R}^d,\textbf{W}_{\mu}\in\mathcal{R}^{4d\times 1}
p=ot∘y∈Rd,Wμ∈R4d×1为可训练参数,
b
t
∈
R
d
\textbf{b}_t\in\mathcal{R}^{d}
bt∈Rd是从
B
t
\textbf{B}_t
Bt的对应行中取出的。
将这些clause的truth value用and运算连接,即可得到对应label的概率。更进一步,由于GCN中每层都会输出一组
O
^
t
l
,
O
^
v
l
,
O
^
t
,
t
l
,
O
^
v
,
v
l
,
O
^
t
,
v
l
\hat{\textbf{O}}_t^l,\hat{\textbf{O}}_v^l,\hat{\textbf{O}}_{t,t}^l,\hat{\textbf{O}}_{v,v}^l,\hat{\textbf{O}}_{t,v}^l
O^tl,O^vl,O^t,tl,O^v,vl,O^t,vl,因此我们也会得到
L
L
L组object及其后面的clause,这些clause可以看作是相对独立的,因此可以用or运算连接。记第
l
l
l层第
i
i
i个clause的truth value为
b
i
l
b_i^l
bil,则整则news为label
y
y
y的概率为
(
b
1
0
∧
⋯
)
∨
(
b
1
1
∧
⋯
)
∨
⋯
∨
(
b
1
L
∧
⋯
)
⇒
h
(
(
T
,
I
)
,
y
)
(b_1^0\land\cdots)\lor(b_1^1\land\cdots)\lor\cdots\lor(b_1^L\land\cdots)\Rarr h((T,I),y)
(b10∧⋯)∨(b11∧⋯)∨⋯∨(b1L∧⋯)⇒h((T,I),y)这里的and和or运算使用product T-norm,即
a
∧
b
=
a
b
,
a
∨
b
=
1
−
(
1
−
a
)
(
1
−
b
)
a
,
b
∈
[
0
,
1
]
a\land b=ab,a\lor b=1-(1-a)(1-b)\ \ a,b\in[0,1]
a∧b=ab,a∨b=1−(1−a)(1−b) a,b∈[0,1]
对于每个label y y y,都算出一个truth value,使用cross-entropy计算loss。
实验
指标
在三个数据集上实施了实验,两个misinformation数据集Twitter和Weibo,一个sarcasm数据集sarcasm。
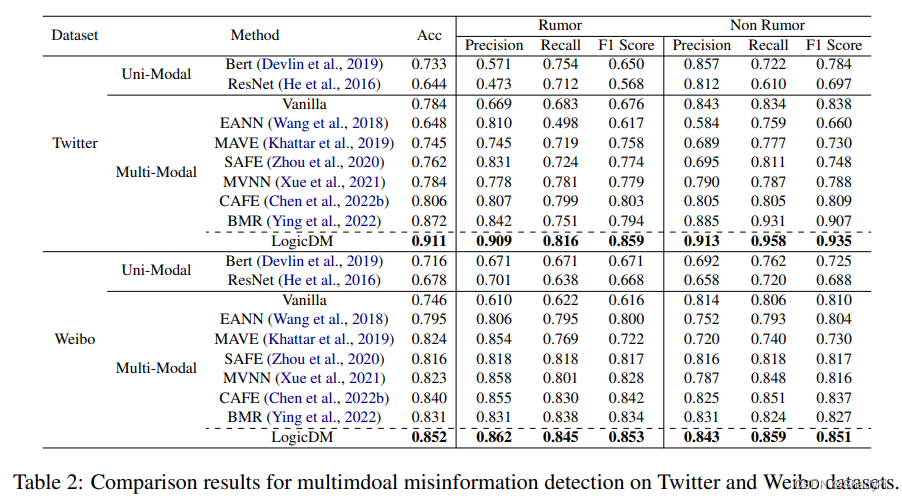
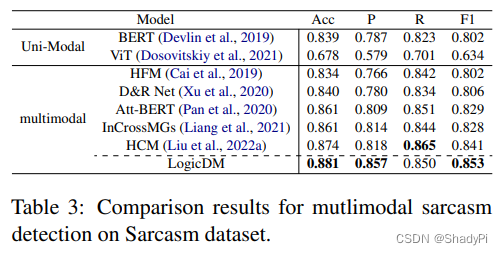
从准确性来讲,很好,都是SOTA,而且在有一定解释性的基础上还提升了模型性能。另外,Precision明显要比其他的模型好,可能是logic帮助模型更好的学习到了rule而不是对噪声过拟合。
可解释性

cd展现出模型会根据文本中是否有足够清晰的表述来判断一则消息是否是rumor,a则是模型发现图片中有地方是P的,b则是人类不是很能理解但判断对了的例子。
消融实验
调整Correlation的多少,即
g
g
g,发现最初随着
g
g
g升高,performance一路升高,但到达一个峰值后缓慢下降。
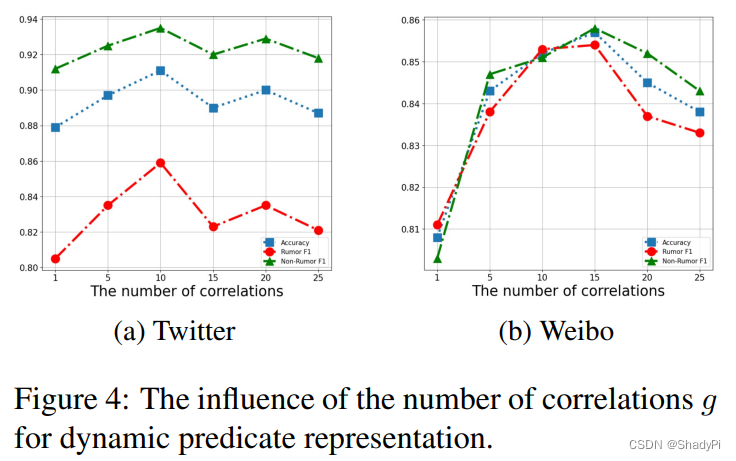
调整筛选Clause的阈值,即
β
\beta
β,发现在
β
\beta
β超过
0.15
0.15
0.15后性能急剧下降,可能有两个原因:1)选出来的clause多了以后,conjunction的操作会导致指数消失,最后得到的概率很小。2)选出来的clause太多,包含了一些低分的clause,引入了噪声。
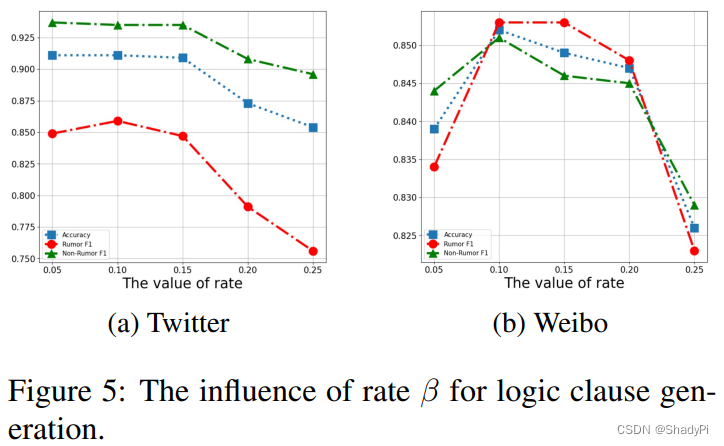
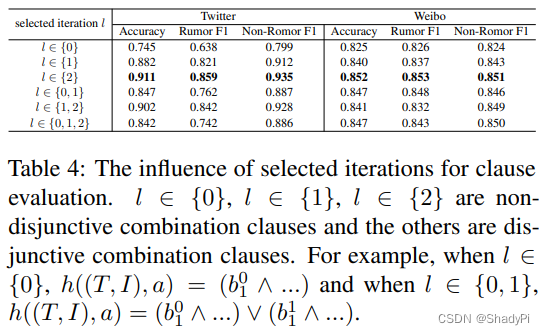
同时,考察GCN不同Layer的选取对实验结果的影响,发现只挑选第二层时效果最佳,说明经过多层GCN整合后的多模态信息对判断misinformation更有用,但加了多层以后似乎效果有所下降。
可改进
只支持一张图片,实际操作中可能不止一张图片。
product T-norm 的 conjunction操作容易遭遇概率消失,或许可以使用其他方法连接这些clause的truth value。
文本和图片直接全部匹配连接,这部分是否可以改进?
predicate只能填入两个变量,不知道
t
,
t
t,t
t,t和
v
,
v
v,v
v,v的predicate是否有那么大的作用,因为GCN同样有融合几个feature的功能。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











