







Abstract:
挑战:(1)人脸不同的姿态(2)表情(3)光照(4)计算量
本文研究:提出了一种基于卷积神经网络(CNN)的级联结构,该结构具有很强的鉴别能力和高性能。
框架:
(1)这个级联CNN可以在多种分辨率上运行。
(2)在前面的快速低分辨率阶段,它可以快速拒绝背景区域。
(3)在最后的高分辨率阶段,它可以仔细评估少量有挑战性的候选框。
(4)在级联的每个检测阶段之后,引入了calibration stage。每个校准级的输出用于调整检测窗口的位置,以便输入到下一阶段。
1. Introduction:
人脸检测研究热点:
已解决:检测接近正面的人脸。
待解决:不加控制的人脸检测问题(如姿势的改变,夸张的表情和极端的光照)会严重降低人脸检测器的鲁棒性。
人脸检测的困难及解决方法:
(1)背景乱:需要精确解决二值分类问题的人脸检测器。
(2)搜索人脸的空间太大:提出强制规定时间效率的要求。
以往研究:
(1)Viola等人的开创性工作:具有简单特征的增强级联。
优点:简单特征可以快速评估和快速拒绝假阳性检测,而增强级联构造了一个简单的特征集合,以实现准确的人脸和非人脸分类。
缺点: 由于Haar特征过于简单,所以探测效果比较弱。
(2)Viola等人对原有工作的改进:具有更先进特征的增强级联。
优点:构造了一个更精确的二进制分类器。
缺点:以额外的计算为代价。
这篇论文的研究:
提出一个基于CNN的人脸探测器。
优点:
(1)可以利用大量的训练数据自动学习特征来捕捉复杂的视觉变化。
(2)测试阶段可以很容易的在GPU核上并行加速。
这篇论文主要贡献:
(1)提出了一种用于快速人脸检测的CNN级联算法。
(2)在级联中引入了一种基于CNN的人脸包围盒校准步骤,以帮助加速CNN级联并获得高质量的定位。
(3)提出了一种多分辨率CNN架构,它可以比单分辨率CNN更具鉴别性。
(4)提高了人脸检测数据集和基准测试(FDDB)的最新性能。
2. Related Work:
2.1. Neural network based face detection:
未开源的方法:
(1)Vaillant等人将神经网络应用于人脸检测。他们训练了一个卷积神经网络来检测图像窗口中是否有人脸,并在所有可能的位置用该网络扫描整个图像。
(2)Rowley等人提出了一种用于直立正面人脸检测的视网膜连接神经网络。该方法之后被扩展到旋转不变人脸的检测。
(3)Garcia等人开发了一种神经网络,用于在复杂图像中检测半正面人脸。
(4)Osadchy等人训练了一个同时进行人脸检测和姿态估计的卷积神经网络。
开源的方法:
(1)Girshick等人提出的R-CNN,其遵循“区域识别”范式。它生成独立于类别的区域,并从区域中提取CNN特征。然后应用于类的分类器来识别区域的对象类别。
2.2. Face detection in uncontrolled environments:
具有简单特征的增强级联框架:
(1)Chen等人:提出了利用形状索引特征联合进行人脸检测和人脸对齐。
我们:(1)有可供选择的校准和检测阶段(2)框架更通用(3)采用基于CNN的人脸对齐方法来实现人脸的联合对齐和检测(4)使用CNN来学习人脸的更健壮的特征。
(2)Zhang等人和Park等人:采用多分辨率思想进行一般目标检测。
我们:(1)共享相似技术,但利用CNN作为分类器(2)结合了多分辨率和校正的人脸检测思想。
基于局部模型的人脸探测方法:
(1)Zhu等人提出了一种基于树结构的人脸检测模型,该模型能同时实现姿态估计和人脸地标定位。
(2)Yan等人提出了人脸检测的结构模型。
(3)Mathias等人展示一种经过精心训练的可变形零件模型可以达到最先进的检测精度。
其他方法:
(1)Shen等人提出通过图像检索来检测人脸。
(2)Li等人改进它,使之成为一种改进的基于范例的人脸检测器,具有最先进的性能。
该论文方法的先进之处:
(1)直接从图像中学习分类器,而不是依赖手工构造的特征。
(2)从CNN中更好地区分面孔和高度杂乱的背景。
(3)检测器比基于模型和基于样本的检测系统快很多倍,并且具有与传统的简单特征增强级联相当的帧速率。
(4)利用CNN的优点,我们的检测器很容易在GPU上被并行化,以获得更快的检测速度。
3. Convolutional Neural Network Cascade:
3.1. Overall framework:
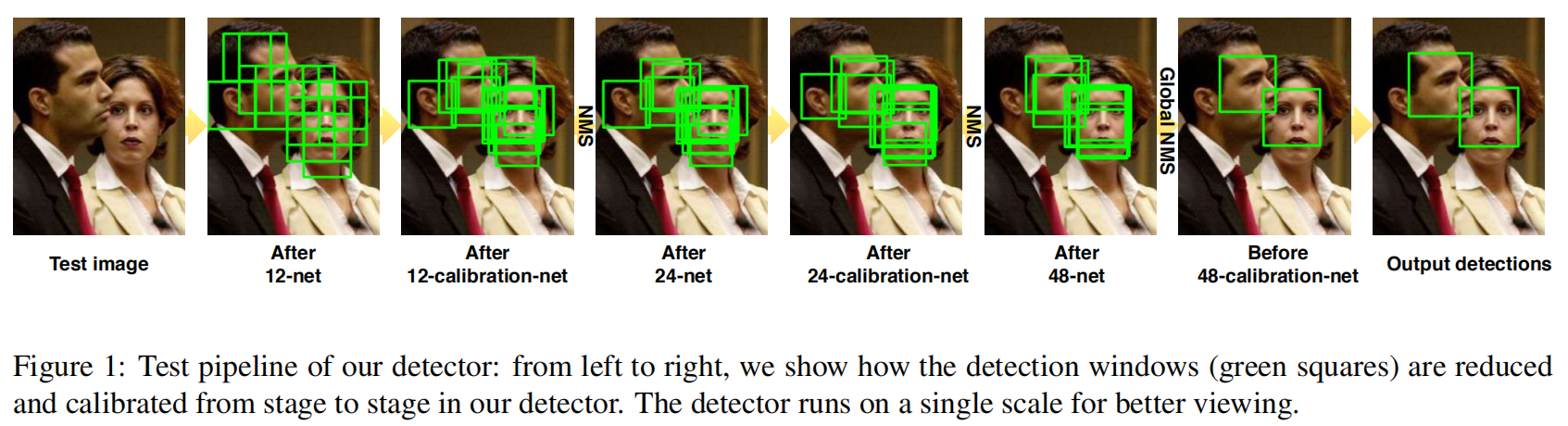
(1)12-net:
输入:Test image。
作用:在不同的尺度上密集地扫描整个图像,以快速拒绝90%以上的检测窗口。
输出:After 12-net。
(2)12-calibration-net:
输入:After 12-net。
作用:将After 12-net剩下的检测窗口处理成12×12图像,调整其大小和位置,以接近附近的潜在人脸。
输出:After 12-calibration-net。
(3)NMS:
作用:非极大值抑制消除高度重叠的检测窗口。
(4)24-net:
输入:After NMS剩下的检测窗口处理成24×24图像。
作用:以进一步拒绝近90%的剩余检测窗口。
输出:After 24-net。
(5)24-calibration-net:
输入:After 24-net。
作用:将After 24-net剩下的检测窗口处理成24×24图像,调整其大小和位置,以接近附近的潜在人脸。
输出:After 24-calibration-net。
(6)NMS:
作用:非极大值抑制消除高度重叠的检测窗口
(7)48-net:
输入:After 24-calibration-net剩下的检测窗口处理成48×48图像
作用:评估检测窗口。
输出:After 48-net。
(8)Global NMS:
作用:非极大值抑制消除高度重叠的检测窗口
(9)48-calibration-net:
输入:After NMS。
作用:对剩余检测边界盒进行校准。
输出:Output detection。
3.2. CNN structure:
级联中有6个CNN:
(1)3个用于人脸和非人脸二进制分类。
(2)3个用于包围盒校准,它被描述为离散位移模式的多类分类。
在这些CNN中,我们遵循AlexNet,在池化层和完全连接层之后使用ReLU非线性函数。
3.2.1 12-net:
作用:是一种浅二分类CNN,快速扫描测试图像。
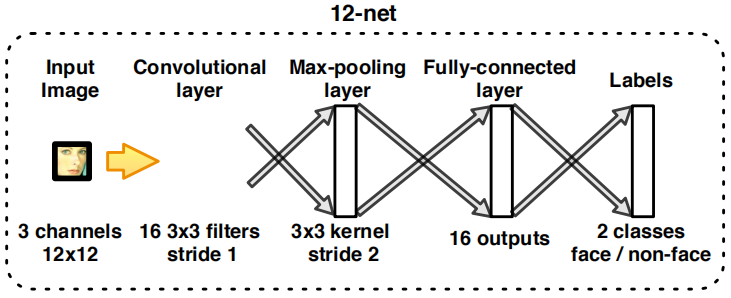
原理:
以4像素间距密集扫描W×H的图像来用于12×12检测窗口,这等于将12-net应用于整个图像来计算
(
W
−
12
4
+
1
)
×
(
H
−
12
4
+
1
)
(\frac{W-12}{4}+1)\times(\frac{H-12}{4}+1)
(4W−12+1)×(4H−12+1)分数,得到信任度图。置信度图上的每个点都是指测试图像上的12×12检测窗口。
实践:
如果可接受的最小人脸尺寸为F,则首先将测试图像构建成图像金字塔来以不同的尺度覆盖面部,其中图像金字塔中的构造是以
12
F
\frac{12}{F}
F12为倍数来缩小,最后得到不同的尺寸的图像来作为12-net的输入。
3.2.2 12-calibration-net:
作用:是一个浅层CNN,用于12-net后的包围盒校准。
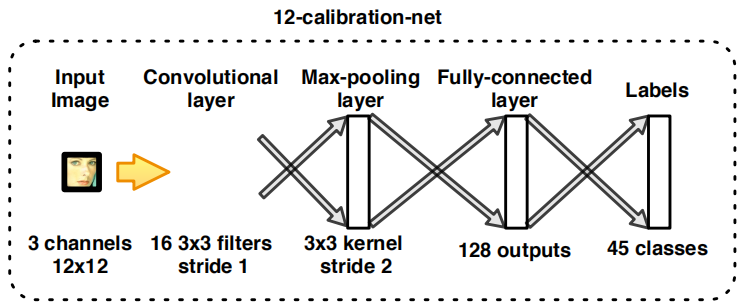
原理:
N校准模式被提前定义为了一组3维规模变化和偏移向量
{
[
s
n
,
x
n
,
y
n
]
}
n
=
1
N
\{[s_n,x_n,y_n]\}^N_{n=1}
{[sn,xn,yn]}n=1N。已知窗口坐标(x,y,w,h),其中(x,y)为左上角的坐标,(w,h)是宽和高,校准模式调整这些窗口坐标
(
x
−
x
n
w
s
n
,
y
−
y
n
h
s
n
,
w
s
n
,
h
s
n
)
(x-\frac{x_nw}{s_n},y-\frac{y_nh}{s_n},\frac{w}{s_n},\frac{h}{s_n})
(x−snxnw,y−snynh,snw,snh)。
在这个工作中,我们设置了N=45个模式,如下组合:
s
n
∈
{
0.83
,
0.91
,
1.0
,
1.10
,
1.21
}
s_n\in\{0.83,0.91,1.0,1.10,1.21\}
sn∈{0.83,0.91,1.0,1.10,1.21}
x
n
∈
{
−
0.17
,
0
,
0.17
}
x_n\in\{-0.17,0,0.17\}
xn∈{−0.17,0,0.17}
y
n
∈
{
−
0.17
,
0
,
0.17
}
y_n\in\{-0.17,0,0.17\}
yn∈{−0.17,0,0.17}
给定一个探测窗口,它被剪裁和调整成 12 × 12 12\times12 12×12的尺寸,来作为12-calibration-net的输入图像。然后这个校正网络输出一个置信分数的向量 [ c 1 , c 2 , . . . , c N ] [c_1,c_2,...,c_N] [c1,c2,...,cN]。因为校准模式不是正交的,所以我们利用高置信分数的那组向量作为调整向量 [ s , x , y ] [s,x,y] [s,x,y]:
[ s , x , y ] = 1 Z ∑ n = 1 N [ s n , x n , y n ] I ( c n > t ) , [s,x,y]=\frac{1}{Z}\sum_{n=1}^N[s_n,x_n,y_n]I(c_n>t), [s,x,y]=Z1∑n=1N[sn,xn,yn]I(cn>t),
Z
=
∑
n
=
1
N
I
(
c
n
>
t
)
,
Z=\sum_{n=1}^NI(c_n>t),
Z=∑n=1NI(cn>t),
I
(
c
n
>
t
)
=
{
1
,
i
f
c
n
>
t
0
,
o
t
h
e
r
w
i
s
e
I(c_n>t)=\begin{cases}1,& if\space\space c_n>t\\0,&otherwise\end{cases}
I(cn>t)={1,0,if cn>totherwise
其中t是一个阈值,用来过滤低置信模式。
实践:
12-net和12-calibration-net拒绝了92.7%的探测窗口,并且在FDDB上保持了94.8%的回调率。
3.2.3 24-net:
作用:是中间浅二分类CNN,进一步减少检测窗口的数量。
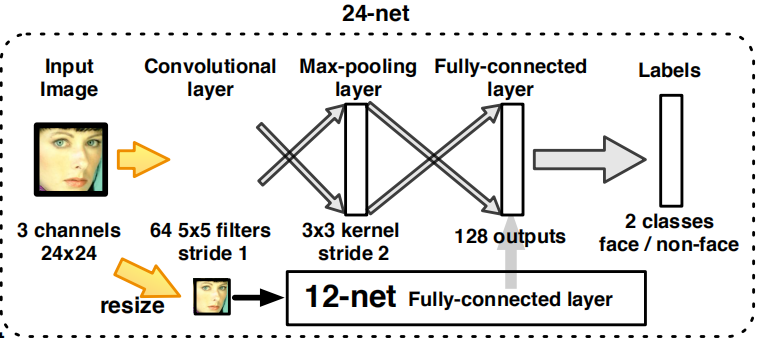
原理:
(1)12-calibration-net后的剩余检测窗口被裁剪出来并调整为24×24图像,并由24-net进行评估。
(2)在24-net中采用了多分辨率结构:
A. 除了24×24的输入外,我们还将12×12分辨率的图片输入到24-net的子结构中,这个子结构与12-net相同。
B. 子结构使用完全连接层,然后其输出作为128outputs全连接层的一部分输出。
C. 这样,24-net以12×12分辨率的信息作为补充,有助于小脸的检测,使总体CNN变得更具判断力,而且12-net的子结构开销很少。
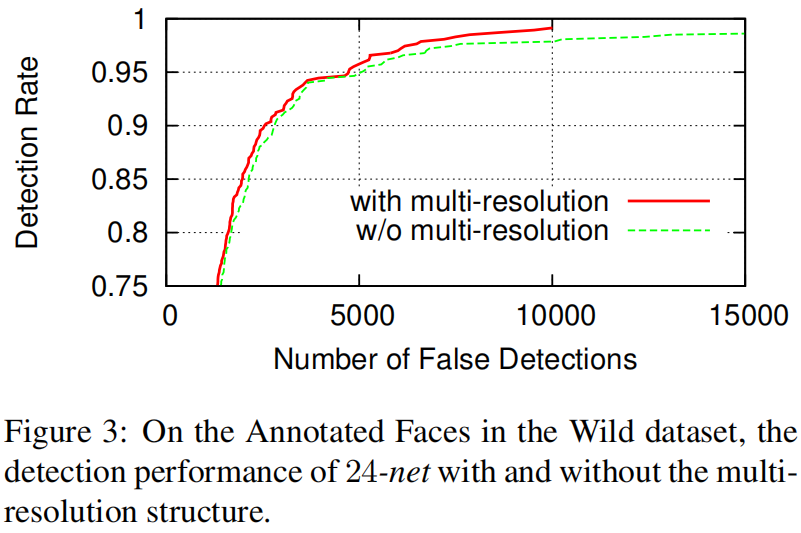
实践:比较了24-net中采用多分辨率设计和不加多分辨率设计的检测性能。
结果:在相同的召回率中,采用多分辨率结构的方法更好。
3.2.4 24-calibration-net:
作用:与12-calibration-net相似,它是另一种具有N种校准模式的校准网。
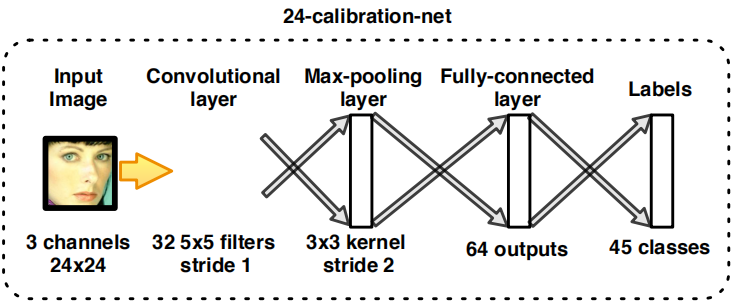
原理:
除了其输入为24×24外,预定义的模式和校准过程与12-calibration-net相同。
实践:
24-net和24-calibration-net进一步拒绝在12-calibration-net后保留的86.2%的检测窗口,同时在FDDB上保持89.0%的召回率。
3.2.5 48-net:
作用:是最后一个二分类CNN,是一个强大的但是慢的CNN。
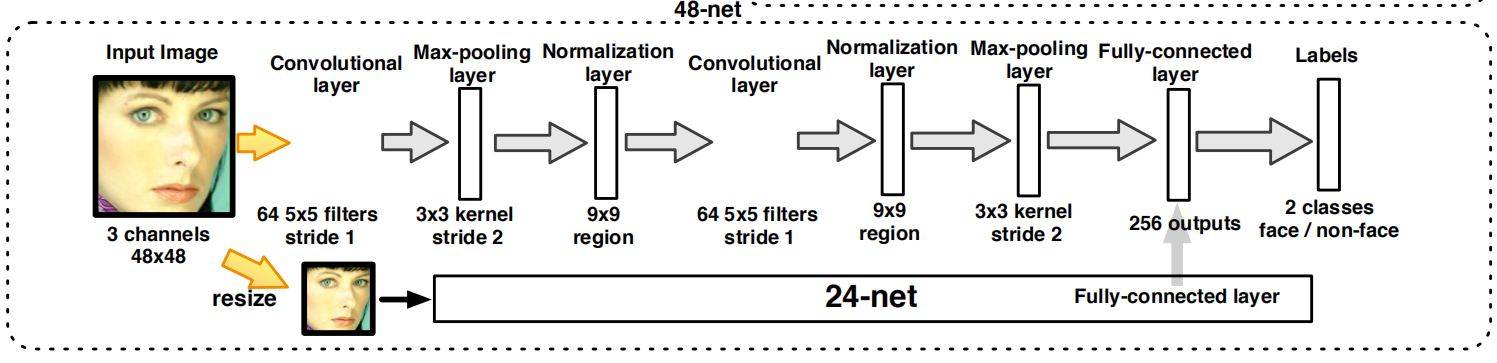
原理:
原理同24-net,采用了多分辨率设计,如图所示。
3.2.6 48-calibration-net:
作用:级联中最后一个步骤。
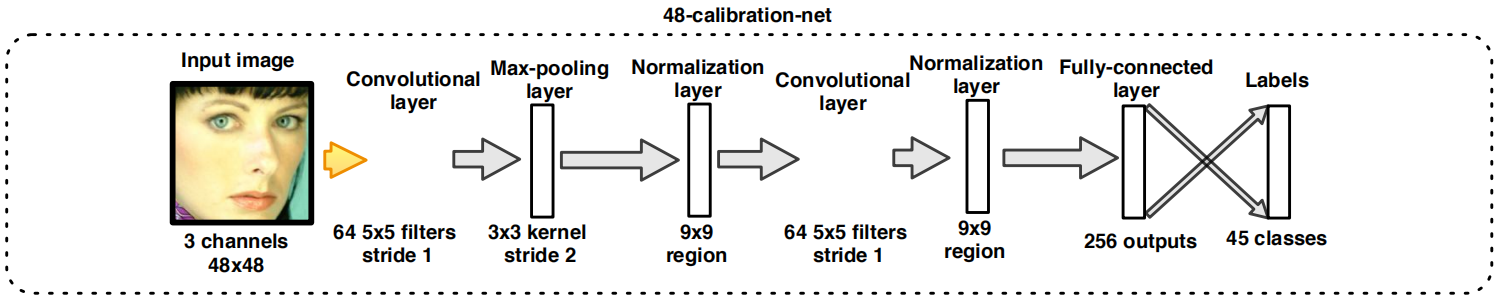
相同的N=45个校准模式被预定义为48-calibration-net,就像在节2.2.2中一样。我们只使用一个池层在这个CNN有更准确的校准。
3.2.7 Non-maximum suppression (NMS):
作用:迭代选择置信度最高的检测窗口,剔除IOU比高于设定阈值的检测窗口。
前两个NMS:
在12-net和24-net中,浅层CNN可能没有足够的判断力来处理具有挑战性的假阳性预测框。在两个calibration-net之后,与真阳性相比,假阳性可能有更高的置信度。因此,在12-calibration-net和24-calibration-net之后,我们保守地将NMS分别应用于相同规模(相同大小)的检测窗口,以避免降低召回率。
最后一个Global NMS:
48-net之后应用的全局NMS使精准的预测框更突出,并且避免48-calibration-net中的冗余评估。
3.3. CNN for calibration

为什么进行calibration:
如图,蓝框是置信度最高的,红框是calibration之后的。所以,置信度最高的检测窗口可能不是很好的对齐脸。如果没有calibration步骤并且要保持相同良好的召回率,那么下一个CNN在级联时将评估更多的区域,浪费时间。
创新:
(1)不是训练一个CNN用于包围盒的回归(简称R-CNN)
(2)而是训练了一个multi-class classification CNN用于校准。
创新原因:
(1)R-CNN要用更多的数据做训练,而multi-class classification CNN不用那么多。
(2)离散化处理降低了校准问题的难度,这样可以使用更简单的CNN来获得好的校准精度。
作用:
calibration网可以使用更粗的扫描窗口来进行更精确的人脸定位。
3.4. Training process
负训练样本:收集的5800幅背景图像。
正训练样本:AFLW的人脸数据集。
优化:multinomial logistic regression objective function。
3.4.1 Calibration nets:
在3.2.2部分提过:收集了45种模式,用于训练calibration网络。
注意:
对于第n组三维调整向量
[
s
n
,
x
n
,
y
n
]
[s_n,x_n,y_n]
[sn,xn,yn],我们将窗口坐标(x,y,w,h)调整为
(
x
−
x
n
w
s
n
,
y
−
y
n
h
s
n
,
w
s
n
,
h
s
n
)
(x-\frac{x_nw}{s_n},y-\frac{y_nh}{s_n},\frac{w}{s_n},\frac{h}{s_n})
(x−snxnw,y−snynh,snw,snh),再应用
[
1
s
n
,
−
x
n
,
−
y
n
]
[\frac{1}{s_n},-x_n,-y_n]
[sn1,−xn,−yn]来调整脸框,裁剪和调整其大小为正确的输入尺寸
(
12
×
12
,
24
×
24
,
48
×
48
)
(12\times12,24\times24,48\times48)
(12×12,24×24,48×48)。
3.4.2 Detection nets:
(1)12-net:
训练集:
正:调整训练脸的尺寸为12×12。
负:随机从背景图像中抽取20万个非人脸贴片。
结果:
在AFLW子集上应用12-net和12-calibration-net的两层级联,以99%的召回率选择阈值T1。
(2)24-net:
训练集:
正:调整上一步骤保留的训练脸尺寸为24×24。
负:置信分数大于域值T1的候选窗口。
结果:
以97%的召回率选择阈值T2。
(3)48-net:
训练集:
正:调整上一步骤保留的训练脸尺寸为48×48。
负:置信分数大于域值T2的候选窗口。
4. Experiments:
benchmarks:
AFW:媲美当前最先进的方法。
FDDB:优于当前最先进的方法。
优点:
级联CNN在性能略有下降的情况下,可以调整成一个速度更快的版本。
4.1. Annotated Faces in the Wild
4.2. Face Detection Data Set and Benchmark
4.3. Runtime efficiency
5. Conclusion:
提出一种检测人脸的快速级联CNN结构:
(1)在低分辨率时快速拒绝非人脸的区域。
(2)在高分辨率时准确处理难以分辨的区域。
(3)引入calibration网,加快检测速度,提高包围盒质量。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









