






者:Shervin Minaee, Ping Luo, Zhe Lin, Kevin Bowyer
人脸检测是许多人脸识别和人脸分析系统的关键的第一步。早期的人脸检测方法主要是基于从图像局部区域提取的手工特征建立分类器,如Haar Cascades和Histogram of Oriented gradient。然而,这些方法还不够强大,无法在不受控制的环境中获得高精度的图像。随着2012年深度神经网络在图像分类方面的突破性工作,人脸检测发生了巨大的范式转变。受计算机视觉领域深度学习快速发展的启发,在过去的几年中,许多基于深度学习的框架被提出用于人脸检测,在准确性方面取得了显著的提高。在这项工作中,我们通过将一些最具代表性的基于深度学习的人脸检测方法分成几个主要类别,详细概述了它们的核心架构设计和在流行基准上的准确性。我们还描述了一些最流行的人脸检测数据集。最后,我们讨论了该领域目前面临的一些挑战,并提出了未来可能的研究方向。
介绍
人脸检测是人脸识别、人脸属性分类、人脸编辑、人脸跟踪等任务必不可少的早期步骤,其性能直接影响到[Deep Face Recognition: A Survey]、[Biometric Recognition Using Deep Learning: A Survey]等任务的有效性。尽管在过去的几十年里,不受控制的人脸检测取得了巨大的进步,但在野外准确高效的人脸检测仍然是一个公开的挑战。这是由于姿势的变化、面部表情、比例、光照、图像失真、面部遮挡等因素造成的。与一般的目标检测不同,人脸检测的特点是在纵横比上的变化较小,但在尺度上的变化大得多(从几个像素到数千像素)。
早期的人脸检测工作主要基于经典方法,即从图像(或图像上的滑动窗口)提取手工制作的特征,并输入分类器(或分类器集成)来检测可能的人脸区域。人脸检测的两个标志性经典作品是Haar Cascades分类器[Rapid object detection using a boosted cascade of simple features]和HOG (Histogram of Oriented gradient, HOG),其次是SVM[Histograms of oriented gradients for human detection]。这些作品代表了对当时艺术水平的极大改进。然而,对于图1所示的具有多种变异因素的具有挑战性的图像,人脸检测精度仍然有限。
随着深度学习在计算机视觉中的巨大成功,研究人员在过去的6-7年里提出了几种很有前途的模型架构。受级联分类器思想的启发,许多早期的基于深度学习的模型都是基于cascade - cnn架构。但是随着几种用于普通目标检测的新架构的引入,许多最新的基于深度学习的模型已经转向单发检测、基于R-CNN的架构、特征金字塔网络(FPN)模型、甚至更多。

图1.
到2000年左右,关于人脸检测研究的主要调查有Yang等人[6]、Rowley等人[7]、Hjelm̊as和Low[8]。Zhang和Zhang调查了未来十年人脸检测的进展,大约到2010年[9]。Zafeiriou等人的[10]调查人脸检测的研究大约在未来五年,到接近深度学习浪潮的开始,大约在2015年左右。他们的一个结论是,“即使允许相对较多的假阳性(大约1000个),仍然有大约15-20%的面孔没有被检测出来。”我们的调查从[10]结束的地方开始,覆盖了从深度学习波开始到当前时间的人脸检测的快速进展。表1总结并比较了现有的调查与我们的工作。本文综述了基于深度学习的人脸检测的最新文献,包括50多种基于深度学习的人脸检测方法。它提供了一个全面的回顾,洞察这些方法的不同方面,包括训练数据,网络架构的选择,损失函数,训练策略,以及他们的关键贡献。根据这些作品在人脸检测方面的主要技术贡献,可以将其分为以下几类:
1)基于Cascade-CNN的模型
2) 基于R-CNN和Faster-RCNN的模型
3)单发探测器模型
4) 基于特征金字塔网络的模型
5) Other model
流行的深度学习架构概述
本节概述了计算机视觉界使用的著名的DNN架构,包括卷积神经网络、循环神经网络和长短时记忆、编码器-解码器和自编码器模型以及生成式对抗网络。由于空间限制,已经提出的其他几个DNN架构,如变压器、胶囊网络、门控循环单元和空间变压器网络,没有被包括在内。
卷积神经网络(CNN)
cnn是深度学习领域中最成功和应用最广泛的架构之一,特别是在计算机视觉任务方面。cnn最初是由福岛[Neocognitron--A Self-organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position]在他关于“新认知子”的开创性论文中提出的,该论文基于Hubel和Wiesel的视觉皮层分层接受场模型。随后,Waibelet al.[Phoneme recognition using time-delay neural networks]引入了在时间接收域和反向传播训练之间共享权值的CNN来进行音素识别,LeCun et al.[Gradient-based learning applied to document recognition]开发了一种实用的CNN架构用于文档识别(图2)。CNN通常包括三种层:i)卷积层,其中卷积核(或过滤器)来提取特征;Ii)非线性层,它应用(通常是元素)一个激活函数到特征映射,从而使网络建模非线性函数;iii)池化层,通过用一些关于这些邻里(mean, max等)的统计信息来替换特征图中的小邻里,从而降低空间分辨率。各层神经元单元是局部连接的;也就是说,每个单元接收来自前一层单元的一个小邻域的加权输入,这个邻域被称为接收域。通过堆叠层形成多分辨率金字塔,较高层的层从越来越宽的接受域学习特征。CNNs的主要计算优势是一层中所有的接收域共享权值,导致参数的数量明显少于全连接神经网络。一些最著名的CNN架构包括AlexNet [ImageNet Classification with Deep Convolutional Neural Networks], VGGNet[Very deep convolutional networks for large-scale image recognition]和ResNet[Deep Residual Learning for Image Recognition]
图2.

RNN的模型
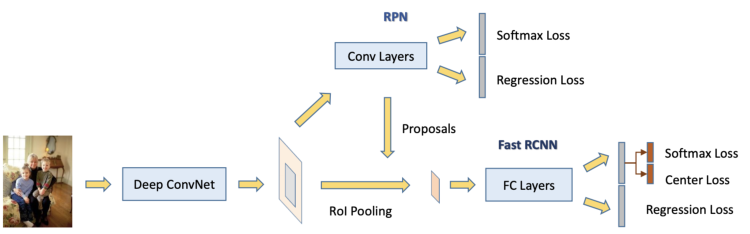
区域CNN (R-CNN)及其扩展已被证明在物体检测应用中是成功的。特别是Faster R-CNN[Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks]架构(图3)使用了一个区域建议网络(RPN)来提出边界框候选。RPN提取一个感兴趣区域(RoI), RoIPool层从这些建议中计算特征,从而推断出对象的边界框坐标和类。R-CNN的一些扩展已经被用于解决实例分割问题;即同时进行目标检测和分割的任务。

单发多盒探测器
单次射击检测器(Single Shot Detector, SSD)是为对象检测[SSD: Single Shot MultiBox Detector]而提出的一种流行的深度学习体系结构。它将边界框的输出空间离散化为一组默认框,每个特征地图位置的不同纵横比和比例。在预测时,网络根据每个默认框中存在的对象类别生成分数,并对该框进行调整,以更好地匹配对象的形状。此外,该网络结合了来自不同分辨率的多个特征映射的预测,以自然地处理各种大小的对象。SSD相对于需要对象提议的方法来说是简单的,因为它完全消除了提议生成和随后的像素或特征重采样阶段,并将所有计算封装在一个单一的网络中。图4说明了原始SSD模型的高级架构。

Feature Pyramid Network (FPN)
特征金字塔是用于检测不同尺度物体的识别系统的基本组成部分。在这项工作中,Lin等人利用深度卷积网络固有的多尺度金字塔层次结构,以边际额外成本构建特征金字塔。他们开发了一种具有横向连接的自顶向下架构,用于在所有尺度上构建高级语义特征图(称为FPN),并证明了FPN可以在几个视觉任务中带来显著的改进。图5是[Feature Pyramid Networks for Object Detection]中提出的特征金字塔网络的高层架构。

生成对抗网络(GANs)
GANs[Generative Adversarial Nets]是一个较新的深度学习模型家族。它们由两个网络组成——一个发生器和一个鉴别器(图7)。在传统GAN中,发生器网络G学习从噪声z(具有先验分布)到目标分布y的映射,这与“真实”样本相似。鉴别器网络D试图将生成的“假”样本与真实样本区分开来。GAN训练可以被描述为G和D之间的minimax博弈,其中D在区分假样本和真样本时试图使其分类错误最小化,从而使损失函数最大化,G试图使鉴别器网络的错误最大化,从而使损失函数最小化。GAN的一些变体包括ConvolutionalGANs [Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks], conditional-GANs [Conditional Generative Adversarial Nets], Wasserstein-GANs[Wasserstein Generative Adversarial Networks]和CycleGAN[Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks]。
不同深度人脸检测模型综述
目前有许多基于不同深度学习架构的人脸检测方法。为了更好地更全面地总结现有的工作,我们将这些工作分成几个突出的类别,并在以下部分回顾每个类别的主要工作:
基于级联cnn模型、基于R-CNN模型、单发探测器模型、基于特征金字塔网络模型、基于变形金刚模型、其他架构
图6提供了一个示例,概述了2015年至2021年最流行的基于深度学习的人脸检测模型。

级联模型
Li等人[A convolutional neural network cascade for face detection]提出了一种早期的基于卷积神经网络级联的人脸检测深度模型。提出的CNN级联在多个分辨率下运行,在快速低分辨率阶段快速拒绝背景区域,在最后一个高分辨率阶段仔细评估少量候选区域。对于vga分辨率的图像,该方法在单个CPU核上以14帧/秒的速度运行,在GPU上以100帧/秒的速度运行。12层的CNN-Cascade网络架构如图8所示。
Zhang et al.[Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks]将该方法扩展用于关节面检测和对准。这项工作利用了一个级联架构,通过三个阶段精心设计的深度卷积网络,以粗到细的方式预测人脸和地标位置。他们还提出了一种新的在线硬样本挖掘策略,以进一步提高准确性。该模型的高级架构如图9所示。

在随后的工作中,Zhang等[Detecting Faces Using Inside Cascaded Contextual CNN]提出了“内部级联结构”(Inside Cascaded Structure),在同一个CNN的不同层引入了人脸/非人脸分类器。他们引入了一种两流上下文CNN架构,自适应地利用身体部位信息来增强人脸检测。在训练阶段,他们提出了一种数据路由机制,使不同的层可以通过不同类型的样本进行训练,从而使更深的层可以专注于处理比传统架构更难的样本。该模型的架构如图10所示。

其他的后续工作也依赖于级联CNN架构,包括“级联CNN联合训练用于人脸检测”[Joint Training of Cascaded CNN for Face Detection]、“基于级联卷积网络的人脸检测方法”[Face Detection Method Based on Cascaded Convolutional Networks]。
R-CNN and Faster-RCNN Based Models
基于区域提议的CNN模型在目标检测方面非常成功,也有几部作品将其应用于人脸检测。在[Supervised Transformer Network for Efficient Face Detection]中,Chen等人提出了一种用于人脸检测的级联CNN模型,称为监督的Transformer网络(Supervised Transformer Network, STN)。第一阶段是多任务区域提议网络(RPN),它同时预测候选人脸区域以及相关的面部地标。然后,通过将检测到的面部标志映射到它们的规范位置来扭曲候选区域,以更好地规范化面部模式。第二阶段是R-CNN,验证弯曲的候选区域是否是有效的人脸。
Jiang和Miller[Face Detection with the Faster R-CNN]探索了fasterRCNN模型[Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks]在人脸检测中的应用。他们能够在两个广泛使用的人脸检测基准上实现最先进的结果,通过简单地在大规模宽脸数据集上训练更快的rcnn。这说明了训练数据量的持续重要性。
与此同时,[Face R-CNN]、Wang等人提出了“Face R-CNN”(Face R-CNN),将fast - rcnn与其他一些技术结合起来进行人脸检测。他们利用多个新技术,包括多任务损失函数设计、在线硬例挖掘方案和多尺度训练策略,从多个方面改进Faster R-CNN。这项工作的架构类似于Faster-RCNN,如图所示
在[Face Detection using Deep Learning: An Improved Faster RCNN Approach]中,Sun等人提出了一种使用改进的Faster-RCNN的人脸检测框架。他们通过结合一系列策略改进了Faster RCNN框架,包括特征拼接、硬负向挖掘、多尺度训练、模型预训练和关键参数的仔细校准。
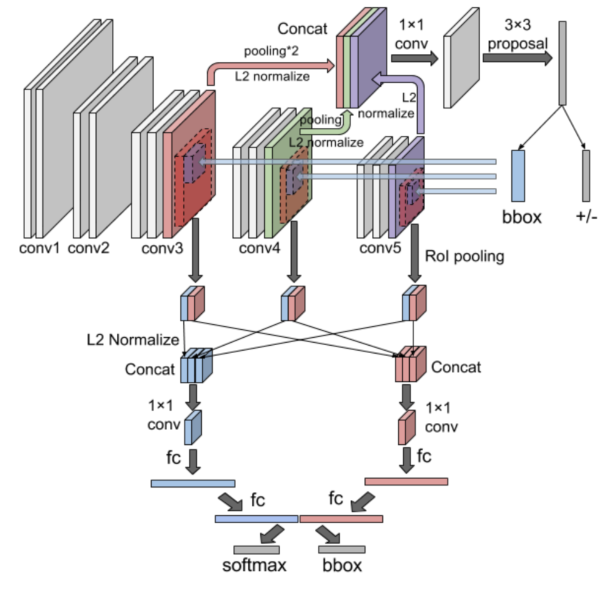
为了更好地融合上下文信息,Zhu等人[CMS-RCNN: Contextual Multi-Scale Region-Based CNN for Unconstrained Face Detection]提出了“CMS-RCNN”,这是一种基于上下文的多尺度区域CNN模型,用于无约束人脸检测。除了典型的区域建议组件和感兴趣区域(RoI)检测,他们介绍了两个主要的思想,专门用于人脸检测。首先,在区域提议和感兴趣区域检测中对多尺度信息进行分组,处理微小人脸区域;其次,受人类视觉系统的启发,在网络中加入了显式的人体语境推理。CMSRCNN的结构如图所示。
在另一项工作中,[ Detecting faces using region-based fully convolutional networks],Wang等人提出了一种基于区域的全卷积网络用于人脸检测。采用全卷积残差网络(ResNet)作为骨干网,采用位置敏感平均池化、多尺度训练与测试、在线硬实例挖掘等新技术提高检测精度。图13给出了R-FCN模型的架构。其他一些基于R-CNN的人脸检测方法包括:“基于更快的R-CNN的不同尺度的人脸检测”[Face Detection With Different Scales Based on Faster R-CNN]、“使用改进更快的RCNN的人脸检测”[Face Detection Using Improved Faster RCNN.]、“利用面具R-CNN设计深度人脸检测器”[Design of a Deep Face Detector by Mask R-CNN]。

Single Shot Detection Models
单阶段检测(SSD)是基于深度学习的人脸检测的另一个热门和主要方向。与R-CNN模型等两阶段提议分类探测器不同,SSD直接从分类网络的早期卷积层在单个阶段检测人脸。
在[ "Ssh: Single stage headless face detector]中,Najibi等人提出了一种“单阶段无头(SSH)”人脸检测框架,该框架在wide Faces、FDDB和Pascal-Faces的所有子集上实现了最先进的结果。SSH在设计上是尺度不变的,而不是依靠图像金字塔来检测不同尺度的人脸。它在网络的一次前向传递中同时检测不同尺度的人脸,但来自不同的层。这些属性使SSH快速且轻量级。图14说明了所提出的SSH模型的架构。

Zhang等人提出了FaceBoxes[FaceBoxes: A CPU real-time face detector with high accuracy],这是一种基于“快速消化卷积层(RDCL)”和“多尺度卷积层(MSCL)”的实时人脸检测器。RDCL旨在使facebox实现实时速度。MSCL的目的是丰富接受域和离散锚在不同层上处理不同尺度的面。他们还提出了一种新的锚点致密化策略,使不同类型的锚点在图像上具有相同的密度。这显著提高了小脸的召回率。关于FaceBoxes,一个有趣的事实是它的速度与脸的数量是不变的。
Hu和Ramanam提出了一个有趣的算法,旨在解决检测小人脸[Finding Tiny Faces]的问题。该模型能够在一张图像中检测出几百张小面孔。图16显示了这种情况的一个示例。他们探索了寻找小人脸问题的三个方面:尺度不变性的作用、图像分辨率和上下文推理。他们采用了与以往不同的方法,并针对不同的尺度训练了不同的探测器。为了保持效率,检测器以多任务的方式进行训练:它们利用从单个(深度)特征层次的多层中提取的特征。它们表明,语境是非常重要的,它利用了巨大的接受域。该模型的总体架构如图17所示。


最近,在[Refineface: Refinement neural network for high performance face detection]中,Zhang等人提出了一种名为RefineFace的单发细化人脸检测器。该框架基于RetinaNet[Focal loss for dense object detection],提出了5个模块:选择两步回归(STR)、选择两步分类(STC)、尺度感知边缘损失(SML)、特征监督模块(FSM)和接受域增强(RFE)。为了增强高定位精度的回归能力,STR从高水平检测层中粗调整锚点的位置和大小,为后续回归提供更好的初始化。该模型的总体架构如图18所示。

在这个类别中还有其他的作品,例如 scale-friendly faces[Face Detection through Scale-Friendly Deep Convolutional Networks],YOLO-face:一个实时的脸检测器[YOLO-face: a real-time face detector],和“SANet:平滑的注意网络单级脸检测器”[SANet: Smoothed Attention Network for Single Stage Face Detector]。
基于特征金字塔网络的模型(Feature Pyramid Network Based Models)
人脸检测中另一个流行的深度模型家族是基于特征金字塔网络[Feature Pyramid Networks for Object Detection]的。也被用于对象检测,以及语义分割。特征金字塔是一种利用跨连接将弱特征和强特征结合起来的神经网络结构。
在[Feature Agglomeration Networks for Single Stage Face Detection]中,Zhang等人受到特征金字塔网络(Feature Pyramid Network)的启发,提出了用于单阶段人脸检测的“特征集聚网络(Feature clustering Networks, FANet)”。该框架的核心思想是利用单个卷积神经网络固有的多尺度特征,通过聚合不同尺度的高级语义特征图作为上下文线索,通过分层聚合的方式以边际额外计算成本增强低级特征图。他们还提出了一种分层损失来有效地训练FANet模型。FANet模型的总体架构如图25所示。

在[50]中,Chi等人提出了一种新的单镜头人脸检测模型“选择性细化网络(SRN)”。SRN由两个新模块组成:选择两步分类(STC)模块和选择两步回归(STR)模块。STC旨在从低级检测层中过滤出最简单的负面锚点,以减少后续分类器的搜索空间,而STR则旨在从高级检测层中粗调整锚点的位置和大小,为后续回归变量提供更好的初始化。此外,他们还设计了一个接收域增强(RFE)块,以提供更多样化的接收域,这有助于更好地捕捉一些极端姿势的面孔。所提出的选择性细化网络模型的网络架构如图21所示。

在[DSFD: Dual Shot Face Detector]中,Li等人提出了一种新的人脸检测算法,称为“双镜头人脸检测器(dual shot face detector, DSFD)”,其关键贡献有三个:首先,他们开发了一个特征增强模块(Feature Enhance Module, FEM),用于增强原始特征映射,将单镜头检测器扩展到双镜头检测器。 二是采用累进锚损(PAL)通过两组不同的锚来计算有效地提取特征。第三,他们使用改进锚匹配(IAM),将新的锚分配策略集成到数据增强中,为回归变量提供更好的初始化。图22给出了DSFD框架的总体架构。该模型的关键组成部分“Feature Enhance Module”如图23所示。在[Pyramidbox++: High performance detector for finding tiny face]中,Li等人提出了PyramidBox++,这是他们早期PyramidBox框架的改进版本。

在[Retinaface: Single-stage dense face localisation in the wild]中,Dent等人提出了一个非常受欢迎的这一类单阶段人脸检测模型,称为RetinaFace[Retinaface: Single-stage dense face localisation in the wild]。利用联合超监督和自我监督多任务学习的优势,对不同尺度的人脸进行像素级的人脸定位。这项工作的一个重要贡献是,他们在WIDER FACE数据集上手动标注了五个面部关键点,并观察到在这个额外的监督信号的帮助下难度人脸集检测得到显著改进。另一个贡献是,他们添加了一个自监督网格解码器分支,与现有的监督分支并行预测像素级3D形状人脸信息。他们能够在几个人脸检测基准上达到最先进的表现。RetinaFace模型的整体架构如图24所示。

在[TinaFace: Strong but Simple Baseline for Face Detection.]中,Zhu等人提出了一种简单而强的人脸检测基线TinaFace,它使用ResNet-50作为特征提取部分,6级特征金字塔网络提取输入图像的多尺度特征,然后加入Inception块增强接收野。这项工作的一个主要目的是表明在人脸检测和一般目标检测之间没有差距。
在[FA-RPN: Floating Region Proposals for Face Detection]中,Najibi等人提出了一种用于生成用于人脸检测的区域提议的新方法,称为“浮动锚区域提议网络(FARPN)”。它们不是使用卷积特征图中的像素级特征对锚框进行分类,而是使用基于池的方法生成区域建议。FA-RPN的总体架构如图25所示。

在这个类别中也有其他的作品,包括Robust and High Performance Face Detector,Improved Selective Refinement Network for Face Detection,Fast cascade face detection with pyramid network,Proposal pyramid networks for fast face detection等。
其他一些流行的人脸检测模型包括: "A Light and Fast Face Detector for Edge Devices" , "Accurate face detection for high performance". UnitBox , "HAMBox: Delving Into Mining High-Quality Anchors on Face Detection" , "Joint face detection and facial motion re-targeting for multiple faces", "Hierarchical attention for part-aware face detection" , "Group Sampling for Scale Invariant Face Detection", "Dafefd: Density aware feature enrichment for face detection", "Triple loss for hard face detection", "BlazeFace: Sub-millisecond Neural Face Detection on Mobile GPUs", and Face Detection with End-to-End Integration of a ConvNet and a 3D Model.
人脸检测基准数据集
FDDB
人脸检测数据集(也称为FDDB)包含了来自野生数据集[FDDB: A benchmark for face detection in unconstrained settings]中带标签的人脸的2845张图像中的5171张人脸的注释。
WIDER FACE (2016)
Wider face[WIDER FACE: A Face Detection Benchmark]是在FDDB之后引入的,包含32,203张图像和393,703张在尺度、姿势和遮挡方面具有高度变化的标记面孔,这使它成为一个非常具有挑战性的数据集
PASCAL Face
PASCAL人脸数据集包含851张具有较大面部外观和姿态变化的图像中的1335张已标记的人脸 [Face detection by structural models].
MALF
MALF是第一个支持精细获取评估的人脸检测数据集。MALF由5250张图像和11,931张面孔组成[Fine-grained evaluation on face detection in the wild]。除了包围框注释外,每个面还包含其他注释,如:偏航、俯仰、滚转的姿态变形水平(小、中、大);其他面部特征:性别(女性,男性,未知),是否戴眼镜,是否遮挡,是否夸张表情。
UFDD (2018)
Unconstrained Face Detection Dataset, UFDD[Pushing the limits of unconstrained face detection: a challenge dataset and baseline results,]包含6425张图像,10897张人脸标注。它涉及关键的退化或条件,包括:雨、雪、雾霾、镜头障碍、模糊、照明变化和干扰物。
VGGFace2 Dataset
VGGFace2数据集包含9131个受试者的331万张图像,平均每个受试者362.6张图像[83]。
性能评价
在本节中,我们首先介绍一些常用的指标,用于评估人脸检测模型的性能。然后,我们总结了在流行数据集上更有前景的基于DL的人脸检测模型的定量性能。
Evaluation Metrics
有几个指标被广泛用于评价人脸检测模型的性能,包括:平均精度(AP)、精确召回(PR)曲线和受试者工作特征(ROC)曲线。下面我们将给出这些指标的简要定义。
Precision-Recall Curve
在描述查全率-查全率曲线之前,我们需要给出查全率和查全率指标的数学定义。这些指标被定义为
Precision = TP /( TP + FP) ; Recall = TP / (TP + FN ),
现在假设模型输出的分数为[0,1],我们可以将输出与阈值进行比较,以获得类标签。因此,对于每个阈值,我们都可以找到对应的precision和recall值。准确率-召回率曲线显示了对于所有不同的阈值,准确率作为召回率的函数。
Average Precision (AP)
如前所述,模型的精度是指在特定决策阈值处的精度。Average precision计算所有这些可能的阈值下的平均precision,它也类似于precision-recall曲线下的面积。这是一个很有用的度量来比较模型的预测有多好,而不考虑任何具体的决策阈值。
ROC Curve
受试者工作特征(ROC)曲线是一个曲线,它显示了模型的性能作为其截止阈值的函数(类似于精确召回曲线)。它本质上显示了各种阈值的真阳性率(TPR)和假阳性率(FPR)。


通常,阳性类别的截止阈值越低,预测为阳性类别的样本越多,即真阳性率(召回率)越高,假阳性率也越高(对应于曲线右侧)。因此,在高召回率和我们想要限制的误差(FPR)之间存在一个权衡。
除了上面列出的模型的平均精度,我们还提供了这些模型在WiderFace数据集上的precision - recall曲线(图35),以及它们在FDDB基准上的Receiver工作特征(ROC)曲线(图36)。我们还在图37中提供了一些著名的人脸检测模型在f1评分方面的比较



挑战和机遇
微小人脸的检测鲁棒性,
人脸遮挡,
准确的轻量级模型,
Few-Shot人脸检测
可解释的深度模型,
减少人脸检测偏差














 3337
3337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









