







 本文基于阿里巴巴移动电商数据,利用MySQL进行数据清洗,使用AARRR模型和RFM模型分析用户行为,通过Power BI进行可视化。分析包括用户活跃度、商品销售情况和用户价值,并提出提升用户活跃度、促进商品成交和差异化营销的策略。
本文基于阿里巴巴移动电商数据,利用MySQL进行数据清洗,使用AARRR模型和RFM模型分析用户行为,通过Power BI进行可视化。分析包括用户活跃度、商品销售情况和用户价值,并提出提升用户活跃度、促进商品成交和差异化营销的策略。
本项目以阿里巴巴移动电商平台的真实用户-商品行为数据为基础,使用MySQL进行数据清洗,以AARRR模型、RFM模型为基础展开分析,再用Power BI做可视化,最后从提升用户活跃度、促进商品成交、差异化用户营销三个方面提出建议。
参考了网上公开分享的一些帖子,把思路整合后发现:需要提取的一些模型、指标、算法,基本可以落到AARRR模型、RFM模型中。因此从这两个模型出发,查找需要的数据,进行分析,再把部分数据使用Power BI可视化。
在正式写代码之前,先理顺分析思路,同时考虑后续可视化过程会用到的数据、表现形式。当然,所有的细节部分不是一下就能全部想好的,也是在敲代码的过程中不断完善。
我的思维导图▼

Let’s Go. 让我们一起开始吧。
一、数据源
数据来自天池竞赛:
https://tianchi.aliyun.com/dataset/dataDetail?dataId=46&userId=1
竞赛数据包含两个部分。
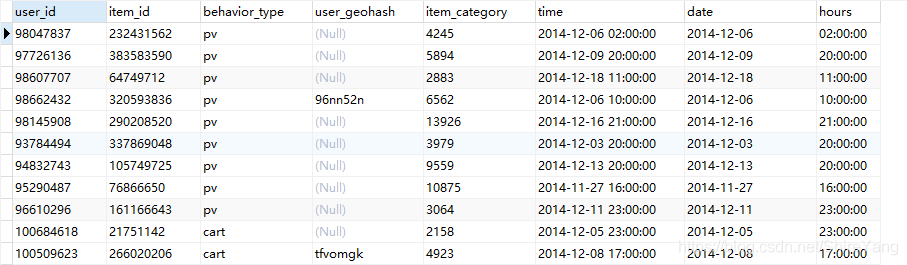
第一部分是用户在商品全集上的移动端行为数据(D),表名为tianchi_mobile_recommend_train_user,包含如下字段:
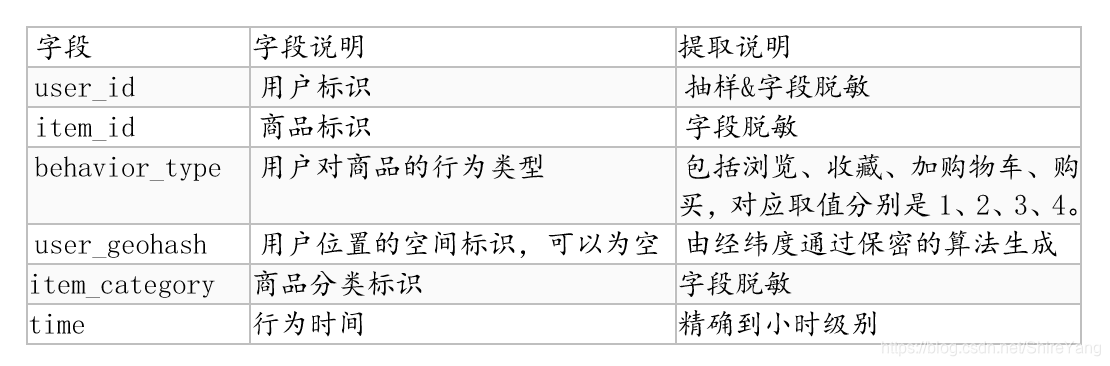
第二个部分是商品子集(P),表名为tianchi_mobile_recommend_train_item,包含如下字段:

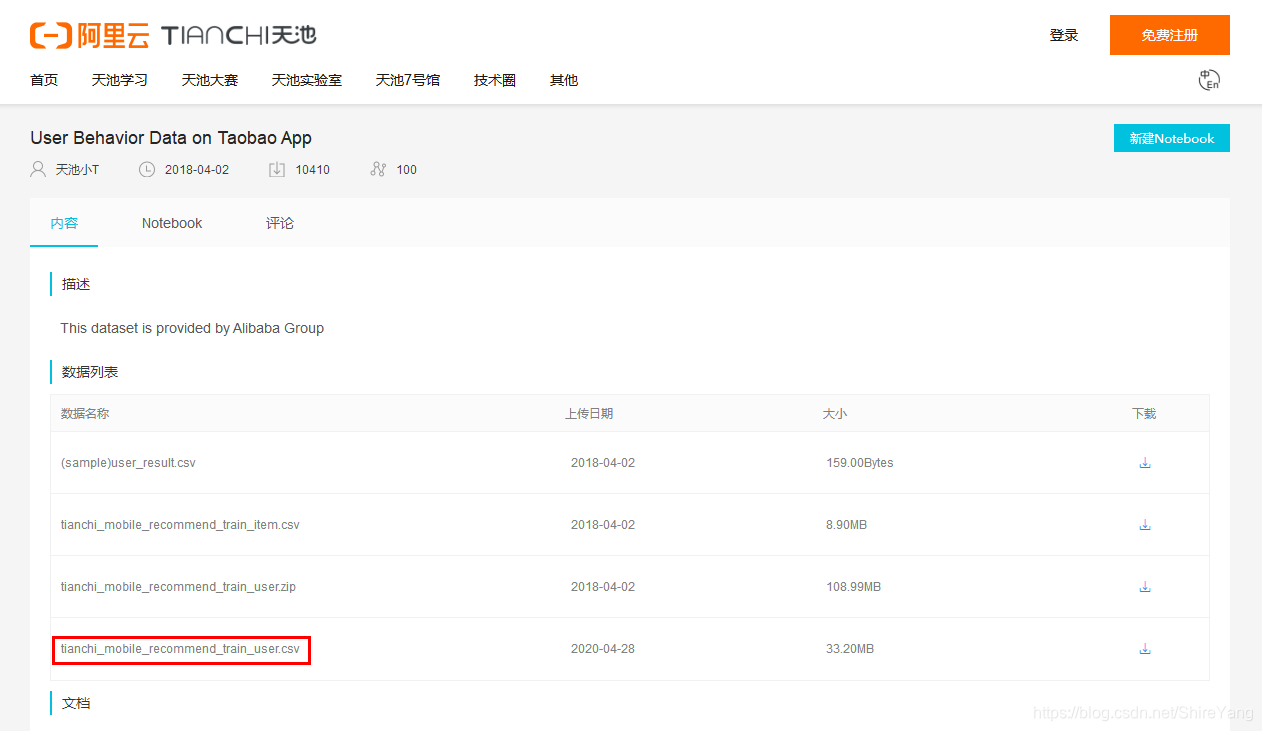
Zip文件中的数据集更大,有1225万。我用的是下图中的红框中的数据,33.2MB,共有80万条。
二、数据清洗
导入数据到mysql
导入数据时,所有的字段都按照默认格式varchar导入▼,导入成功后再设计表,按照需求修改字段格式。

血泪教训 :第一次导入时,把time设置成了datetime格式,导入成功后time一列全部显示为0,后面又费了功夫把它给调对。
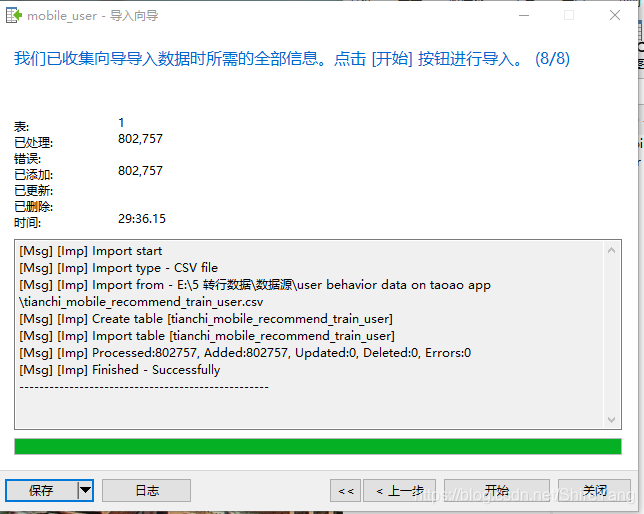
将80万条数据导入mysql,花费了30分钟,导入成功,点击关闭。▼
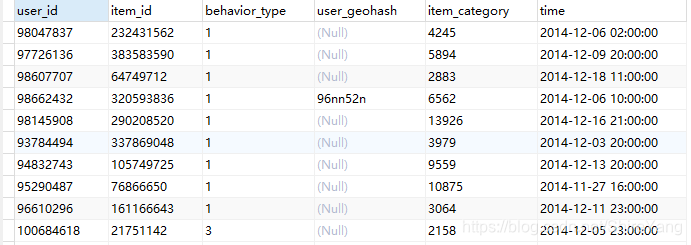
数据概览▼
重复值
有重复,但是根据业务理解,不需要作处理。代码如下:
select *, count(user_id) from data
group by user_id, item_id, behavior_type, item_id, time
having count(user_id) > 1;
异常值
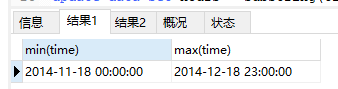
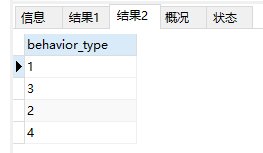
查看time的范围,behaviou_type的类型。代码如下:
select min(time), max(time) from data;
select distinct behavior_type from data;
缺失值
查看各字段的数量,发现time有一条缺失。代码如下:
select count(user_id), count(item_id), count(behavior_type),
count(item_id), count(time)
from data;

查看找到它,删除。代码如下:
select * from data where time is null;
delete from data where time is null;

数据一致化
对time字段分成日期date和时段hours两个字段;为了便于理解,把behavior_type的数字改为英文简写。代码如下:
# 把time分成date和hours两个字段,然后删除time
alter table data add column date date;
alter table data add column hours varchar(255);
update data set date = left(time, 10);
update data set hours = substring(time, 12,2);
# 把behavior_type 分别更名为pv, col, cart, buy
update data
set behavior_type = (
case
when behavior_type = 1 then 'pv'
when behavior_type = 2 then 'col'
when behavior_type = 3 then 'cart'
when behavior_type = 4 then 'buy'
else '其他'
end
);
# 删除time这一列
alter table data drop time;
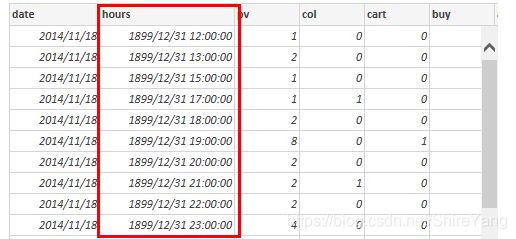
血泪教训:刚开始完全把hours设置成time格式,使用right(time, 8),最终结果显示为00:00:00的格式。但是,后来在使用powerbi可视化过程中发现,这样会出现一些如下图红框中的错误显示。最终决定,hours使用varchar格式,显示12、13、15、17这样的格式,方便可视化。错误代码如下,不要这样做:
# 错误示范
alter table data add column hours time;
update data set hours = right(time, 8);
三、数据分析
使用sql进行数据分析的过程,我把它理解为,理解业务,写代码,建视图,可视化。
视图命名规则基本按照【维度_度量】这样的格式,方便自己理解。命名基本用英文全称,少用简写,方便后续的理解与回顾。
1. 整体活跃度,基于AARRR模型
“获取(Acquisition)”、“激活(Activation)”、“留存(Retention)”、“传播(Referral)”、“收入(Revenue)”
1.1 用户获取Acquisition
代码参照后面的留存率day_0
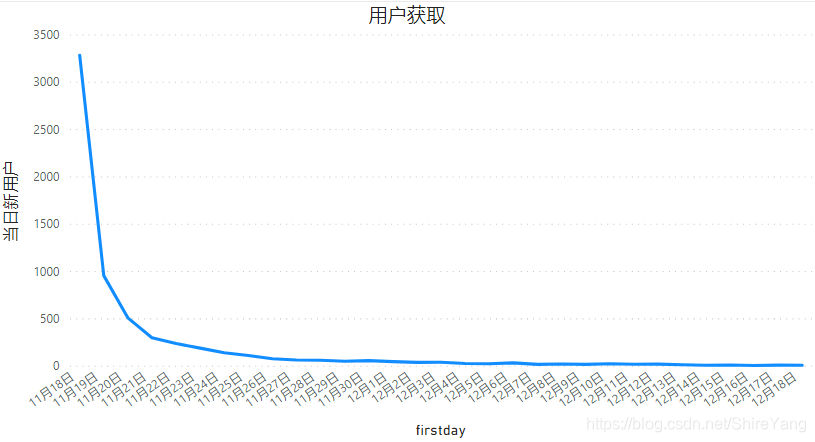
每日都有新增用户。11月18日—11月21日新增用户骤降,后续持续递减。▼
本项目数据从11月18日开始,到12月18日结束,11月18日前无可分析数据。在靠近11月18日的当日新增用户中很大一部分并非当日新增,而是18日前就已经活跃用户。日期靠后的数据,越能体现出当日新增真实值,具体值需要等待后续数据。
1.2 用户激活Activation
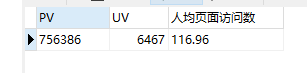
PV, UV
本项目数据源共802757条,pv为756386 ,uv为6467, 人均页面访问数为116.96。代码如下:
# 整体指标
create view whole_index as
select sum(user_pv) as PV, count(user_id) as UV, format(sum(user_pv)/count(user_id), 2) as 人均页面访问数
from (select user_id, count(behavior_type) as user_pv
from data where behavior_type = 'pv' group by user_id) as a;
跳失率
浏览页跳失率为25.84%,关键页跳失率74.16%。
跳失分析:商品不符合用户需求,竞争力不够。可对比竞品网站,在商品的定价、商品陈列故事、商品详情描述等方面做出改进。
代码如下:
-- 浏览页跳失率:用户仅仅有pv行为,没有其它的收藏、加购、购买行为,
create view view_bounce_rate as
select (select count(distinct user_id) from data) as 总用户,
count(distinct user_id) as 仅pv用户,
concat(format(count(distinct user_id)
/(select count(distinct user_id) from data)*100, 2), '%') as 浏览页跳失率
from data
where user_id not in
(select distinct user_id from data where behavior_type = 'col' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4400
4400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









