







摘要:
我们提出了一种不依赖模型的元学习算法,它与任何梯度下降训练的模型兼容,适用于各种不同的学习问题,包括分类、回归和强化学习。元学习的目标是在各种学习任务上训练一个模型,这样它只需要少量的训练样本就可以解决新的学习任务。在我们的方法中,模型的参数被显式地训练,使得少量的梯度步骤和少量的来自新任务的训练数据能够在该任务上产生良好的泛化性能。实际上,我们的方法训练模型易于微调。结果表明,该方法在两个few-shot图像分类基准上都取得了最新的性能,在few-shot回归上取得了良好的效果,并加速了基于神经网络策略的策略梯度强化学习的微调。
关键词:模型无关 元学习 具有很好的泛化能力 模型易于微调
1、Introduction
提出了一个通用的和模型无关的元学习算法,可以直接应用于任何学习问题和模型的梯度下降训练过程。并且我们的方法运用最小的修改来轻松的处理不同的体系和不同的问题设置,包括分类,回归和policy gradient reinforcement learning策略梯度强化学习。我们方法的关键思想是训练模型的初始参数,使得经过参数通过一个或者多个梯度步骤更新以后模型在新任务上具有最大的性能,该梯度步骤由来自该新任务的少量数据计算。
2、Model-Agnostic Meta-Learning
2.1. Meta-Learning Problem Set-Up
few-shot元学习的目标是训练一个模型,该模型仅使用少量数据点和训练迭代就能快速适应新任务。为了实现这一点,模型或学习者在元学习阶段接受一组任务的训练,这样训练后的模型只需使用少量的例子或试验就可以快速适应新的任务。实际上,元学习问题把整个任务当作训练的例子。
我们考虑一个表示为f的模型,它将观测值x映射到输出a。在元学习过程中,该模型被训练成能够适应大量或无限数量的任务。每一个任务![]()
包括一个损失函数![]() ,一个初始观测的分布
,一个初始观测的分布![]() ,一个过渡分布
,一个过渡分布![]() ,还有一个Episode的长度H。在i.i.d.监督学习问题中长度
,还有一个Episode的长度H。在i.i.d.监督学习问题中长度![]() 。模型可以通过选择第t次的输出
。模型可以通过选择第t次的输出![]() 来生成长度为H的样本。损失
来生成长度为H的样本。损失![]()
提供特定于任务的反馈,其形式可能是错误分类损失或马尔可夫决策过程中的成本函数。

2.2. A Model-Agnostic Meta-Learning Algorithm
我们的目标是找到对任务变化敏感的模型参数,使得参数的微小变化将对从p(T)中提取的任何任务的损失函数产生很大的改善,当沿着损失梯度的方向改变时。我们不假设模型的形式,而是假设它是由某个参数向量θ参数化的,损失函数在θ中足够光滑以至于我们可以使用基于梯度的学习技术。
梯度更新方法:![]()
元目标: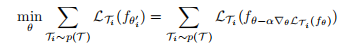
模型参数更新:![]()
完整算法:
3、Species of MAML
3.1. Supervised Regression and Classifification
对于使用均方误差的回归任务,损失的形式为:

对于具有交叉熵损失的离散分类任务,损失采取以下形式:
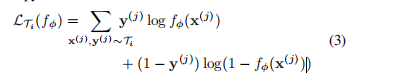
具体算法:
3.2. Reinforcement Learning
在强化学习(RL)中,少量元学习的目标是使代理能够使用少量的测试设置经验快速获取新测试任务的策略。一项新的任务可能包括实现一个新的目标或者在一个新的环境中成功地完成一个先前训练过的目标。例如,一个代理可能学会快速找出如何导航迷宫,这样,当面对新迷宫时,它可以确定如何仅用少量样本可靠地到达出口。
每一个RL任务包括一个初始状态分布一个过渡分布,和一个对应于(负)奖励函数R的损失,因此,整个任务是一个水平H的Markov决策过程(MDP),学习者可以查询有限数量的样本轨迹进行few-shot学习。
损失的形式: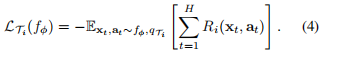
由于动态未知,expected reward通常是不可微的,因此我们使用策略梯度方法来估计模型梯度更新和元优化的梯度。由于策略梯度是一种on-policy算法,在自适应过程中,每个额外的梯度步骤都需要从当前策略中获取新的样本。
4、Related Work
一种流行的元学习方法是训练一个元学习者,学习如何更新学习者模型的参数。该方法已应用于学习优化深层网络,以及学习动态变化的递归网络。最近的一种方法是学习权值初始化和优化器。我们的方法不引入元学习的附加参数,也不需要特定的学习者架构。
元学习的另一种方法是在许多任务上训练记忆增强模型。
我们的方法也涉及到深层网络的初始化方法。
5、Experimental Evaluation
我们实验评估的目标是回答以下问题:
- MAML能实现快速学习吗
- MAML是否可以用于多个不同领域的元学习,包括监督回归、分类和强化学习?
- 使用MAML学习的模型是否可以通过额外的梯度更新和/或示例继续改进?
5.1 Regression
从一个简单的回归问题开始,它说明了MAML的基本原理。每个任务都涉及到从输入到输出的正弦波的回归,正弦波的振幅和相位在不同的任务之间是不同的。
我们在定性和定量结果(图3和附录B)中都观察到,使用MAML学习的模型在使用额外的梯度步骤时继续得到改进,尽管在一个梯度步骤之后进行了最大性能的训练。这一改进表明MAML优化了参数,使其位于一个易于快速适应且对p(T)的损失函数敏感的区域,















 1677
1677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









