







在看MAML这篇论文的时候,因为是初学者,很多都不懂,网上查了许多资料也没看明白,最后来来回回找了很多资料结合原文才看懂一些,在这简单分享一下。
什么是元学习?
元学习(meta-learning)已经有很多定义了,最常见的就是学习学习,即learning to learn。这里从其他方向说一个可能不是很好但是有助于理解的定义,就是把常规的训练模型的某一个过程替换成一个可学习的模块。比如:
MAML就是把模型初始化的过程拿出来换成了一个可以学习的过程。
MetaReg是把正则项换成了一个可以学习的部分。
还有将梯度下降过程替代为单独的神经网络模型的。
Optimization as a Model for Few Shot Learning 原文
要解决什么问题?
MAML提出来时是为了解决少样本学习问题,即few-shot learning。后续MLDG将该方法拓展到域泛化(Domain Generalization)的问题,其他方法也有将MAML类似的学习过程用于解决其他问题,不过后续我就不是很了解了。
那什么是少样本学习呢?顾名思义,就是样本比较少的学习。。。。。比如对小孩子来说,给他看几张长颈鹿的图片他就能认识长颈鹿,但是对于机器学习来说,需要大量的数据进行训练,如果学习样本比较少的话,模型就很难work起来,少样本学习要解决的就是这个问题。
概念定义

MAML将原来普通的训练集和测试集更改为了训练任务和测试任务,每种任务都有相应的训练集和测试集,为了便于区分,也叫做支持集support set和查询集query set。其中训练任务的支持集和查询集用于训练,测试任务的支持集用于微调,为了区别于预训练,也可以叫快速学习,最后测试任务的查询集是模型要表现良好的目标,这也是MAML的一个重点,即不关心在训练任务上的效果,只希望在测试任务的查询集上有较好的表现。
MAML算法

这是MAML原文的伪代码,为了理解这篇文章,我在YouTube找到一个视频,其中有一个示意图画得很好。
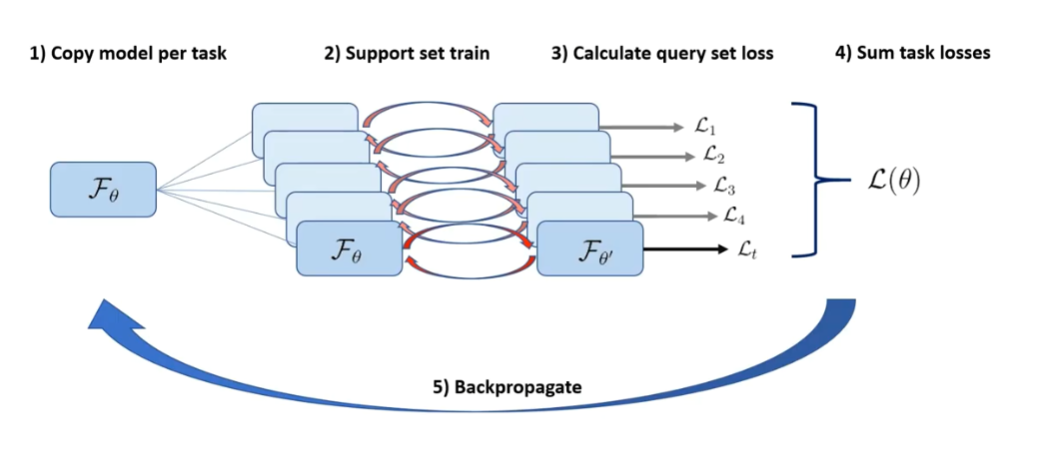
就是这张图帮我理解了MAML的学习过程。可大致分为以下五步:
先把模型的参数copy很多份;
在copy出来的副本上使用训练任务的support set进行训练,将参数更新一次(或多次);
使用更新后的参数,在训练任务的query set上计算损失;
将所有损失结合,计算一个总的损失;
使用这个损失更新原始参数θ,这也是第一步copy模型的目的,就是计算两次梯度,但是更新是对于原始参数而言的。
有兴趣的可以看下原视频,讲的比我写的要好很多。

由于我不太了解强化学习的内容,所以就拿MAML原文的前一部分即监督学习的部分讲解一下有关的定义。如图所示,红色框是外循环outer loop,使用的数据是query set,蓝色框是内循环inner loop,使用support set。
其他论文的实验细节问题就不再赘述了,大家可以阅读原文,同时有一些比较相关的文章列举如下:
Probabilistic Model-Agnostic Meta-Learning (原作者工作)
HOW TO TRAIN YOUR MAML (对MAML的问题进行了改进)
MAML刚开始理解起来很困难,希望这篇能有帮助,因为看MAML的时候已经是很久之前了,所以写的比较简单,下边列举一些博文可以一起阅读帮助理解。















 5498
5498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









