







我们通过引入两种类型的上下文感知指导模型,即加性模型和对比模型来解决这个问题,这两种模型利用它们周围的上下文区域来改进定位。
加性模型鼓励预测的对象区域得到其周围上下文区域的支持。 对比模型鼓励预测的对象区域从其周围的上下文区域中突出。
给定提取的ROI作候选区,本文提出两个基本的上下文感知模型,加性模型和对比模型,利用周围的上下文区域来改进候选区;加性模型依赖于语义一致性,它从ROI和上下文中聚合类激活;对比模型依靠语义对比来计算ROI和上下文之间类的激活
方法

1、Convolutional and ROI Pooling Layers
conv layers:VGG-F
ROI pooling与faster RCNN相同
2、Feature Pooling for Context-Aware Guidance

为了上下文定位与学习,本文扩展了ROI pooling。ROI pooling包括三个部分, ROI pooling, context pooling, and frame pooling,ROI pooling是候选框,context pooling是ROI周围的外部区域,frame pooling是内部区域ROI。注意,context pooling和frame pooling生成相同形状的特征映射,即输出的中心区域的值将为零。这三个部分经过FC 分别输出ROI featue vector,context feature vector,frame feature vector。
3、Two-Stream Network.
为了将指导模型组件与分类相结合,采用了双分支结构。在这种双流策略中,ROI的分类得分与其相应的Softmax定位得分重新加权。
分类分支将
F
R
O
I
F_{ROI}
FROI作为输入,通过
F
C
c
l
s
FC_{cls}
FCcls输出分类分数
S
∈
R
K
∗
C
S\in{R^{K*C}}
S∈RK∗C,C个类别,K个ROIs。定位分支将
F
R
O
I
F_{ROI}
FROI和
F
c
o
n
t
e
x
t
F_{context}
Fcontext作为输入,通过guidance models,输出定位分数
L
∈
R
K
∗
C
L\in{R^{K*C}}
L∈RK∗C,之后
L
L
L通过softmax层,得到
[
σ
(
L
)
]
k
c
=
e
x
p
(
L
k
c
)
∑
k
′
=
1
K
e
x
p
(
L
k
′
c
)
[\sigma(L)]_{kc}=\frac{exp(L_{kc})}{{\sum_{k^{\prime}=1}}^{K}exp(L_{k^{\prime}c})}
[σ(L)]kc=∑k′=1Kexp(Lk′c)exp(Lkc)。
将
S
S
S与
σ
(
L
)
{\sigma}(L)
σ(L)做element-wise得到最后的分数。
对所有ROI类分数进行求和,以获得图像类分数。 在训练期间,我们使用hinge loss:
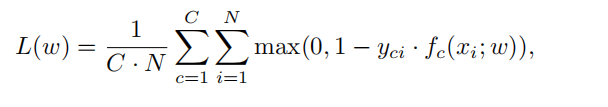

4、Additive Model

受上下文信息的启发,鼓励网络选择语义上与上下文兼容的ROI。具体地说,我们引入了两个全连接的层FCROI和FC上下文,如图4(a)所示。每个ROI的定位分数通过层的输出相加获得。
5、 Contrastive Model
对比模型鼓励网络从上下文中选择一个突出的ROI。
如图4(b)所示,注意,
F
C
R
O
I
FC_{ROI}
FCROI与
F
C
c
o
n
t
e
x
t
FC_{context}
FCcontext的权重共享。
















 2385
2385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









