






模型思路
一个人对某个知识点的掌握或对某个题目的理解都受到其以往做题经验的影响,而且这个影响会随着时间衰退。比如,学生A和B都依次做了(a,b,c,d,e)五个题目,A的答题记录是(1,0,1,1,1),B的答题记录是(0,1,0,1,0),那么A和B都做到题目e时,他们对其的理解是不同的,即同一个题目对不同做题经验的人来说含义不同(在模型里表现为表征这个题目的vector x 并不是固定的,而是会随着人变化);而对于同样的题目d,学生A和B的response都是1,但是这两个学生答对这个题目后对自身知识的更新结果是不一样的(在模型里表现为答对或答错这个题目之后,知识更新vector y 并不一样)。本文使用context-aware attention的机制来引入这个影响。
模型设置
模型示意图

-
Rasch model-based Embeddings
把原始的题目vector x 和表征题目-反应的vector(原文为raw question-response embeddings) y 纳入到Rasch Model模型中:
x t = c c t + μ q t ⋅ d c t , y t = e ( c t , r t ) + μ q t ⋅ f ( c t , r t ) \mathbf{x}_{t} = \mathbf{c}_{c_{t}} + \mu_{q_{t}} \cdot \mathbf{d}_{c_{t}},\\ \mathbf{y}_{t} = \mathbf{e}_{(c_{t},r_{t})} + \mu_{q_{t}} \cdot \mathbf{f}_{(c_{t},r_{t})} xt=cct+μqt⋅dct,yt=e(ct,rt)+μqt⋅f(ct,rt)
其中 c c t \mathbf{c}_{c_t} cct代表这个题目对应的概念或知识embedding vector, μ q t \mu_{q_t} μqt是一个标量,代表题目难度(我理解为对应Rasch model的 β \beta β参数), d c t \mathbf{d}_{c_t} dct代表这个概念上所有题目的变异(variation)。 e ( c t , r t ) \mathbf{e}_{(c_{t},r_{t})} e(ct,rt)和 f ( c t , r t ) \mathbf{f}_{(c_{t},r_{t})} f(ct,rt)则分别代表concept-response的embedding vector和variation vector。
这个模型把一个题目用其对应的concept embedding和所有与该题目concept相关的题目的变异来表示,相当于在concept embedding的每一个concept上都以 m e a n + μ q t ⋅ s d mean+\mu_{q_t}\cdot sd mean+μqt⋅sd来表示,concept相同上的不同题目只有 μ q t \mu_{q_t} μqt变化,代表的是这个题目与平均难度差多少。
对于question-response y t y_t yt,同样的用 m e a n + μ q t ⋅ s d mean+\mu_{q_t}\cdot sd mean+μqt⋅sd表示为
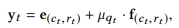
其中 e ( c t , r t ) e_{(c_t,r_t)} e(ct,rt)表示的是concept-response的embedding, f ( c t , r t ) f_{(c_t,r_t)} f(ct,rt)代表其对应concept的所有concept-response embedding的变异。为了减少要估计的参数,作者将 e ( c t , r t ) e_{(c_t,r_t)} e(ct,rt)定义为 e ( c t , r t ) = c c t + g r t e_{(c_t,r_t)} = \mathbf{c}_{c_t} + \mathbf{g}_{r_t} e(ct,rt)=cct+grt, c c t \mathbf{c}_{c_t} cct跟题目向量 x t x_t xt中的 c c t \mathbf{c}_{c_t} cct相同, g r t \mathbf{g}_{r_t} grt只有两个可能的值, g 0 \mathbf{g}_0 g0和 g 1 \mathbf{g}_1 g1分别代表答错和答对的反应向量,对所有concept都相同。
?参数怎么估计呢?文中没有详细讲怎么用Rasch model来估计这些参数,看上去题目和反应都用向量来表示,用的就应该是MIRT模型。 -
Question encoder & Knowledge encoder(context-aware representation)
如前文所述,这篇文献认为当某个学生t时刻遇到一个问题qt时,对这个问题的理解会受到之前做题经验的影响,故而对当前问题的理解 x ^ t \hat{\mathbf{x}}_t x^t有 x ^ t = f ( x 1 , . . . , x t ) \hat{\mathbf{x}}_t = \mathit{f}(\mathbf{x_1},...,\mathbf{x_t}) x^t=f(x1,...,xt),从当前问题获取的知识 y ^ t \hat{\mathbf{y}}_t y^t有 y ^ t = f ( y 1 , . . . , y t − 1 ) \hat{\mathbf{y}}_t = \mathit{f}(\mathbf{y_1},...,\mathbf{y_{t-1}}) y^t=f(y1,...,yt−1)。这里得区分下 x t ^ \hat{\mathbf{x_t}} xt^、 y t ^ \hat{\mathbf{y_t}} yt^和 x t \mathbf{x_t} xt和 y t \mathbf{y_t} yt。 x t \mathbf{x_t} xt代表t时刻遇到的题目,(我的理解就是 x t = q t \mathbf{x_t} =\mathbf{q_t} xt=qt,即一个代表当前题目是第几个题目的独热编码向量),而 x t ^ \hat{\mathbf{x_t}} xt^经过encoder之后代表的是这个学生对当前问题的理解,即这个题目对当前学生意味着什么。再举个更具体的例子,假如张三在做一个题目,这个题目包含了加减法和乘除法两个知识点,但张三之前已经做了100个加减法的题目了,那么受到之前做题经验的影响,这个题目其实对张三来可能主要是乘除法的问题(因为加减法已经太熟练了)。但如果是一个从来没做过加减法题目的李四遇到这个问题,这个题目就既是加减法题目也是乘除法题目。再来说 y t \mathbf{y_t} yt和 y t ^ \hat{\mathbf{y_t}} yt^,原始的 y t \mathbf{y_t} yt代表question-response embedding vector,对于每个题目来说,只有做对的vector和做错的vector两种,但是经过编码之后, y t ^ \hat{\mathbf{y_t}} yt^对每一个人可能都不一样,因为它加入了每个人独特的做题经验。
具体计算过程就是:
x ^ t = ∑ i = 1 t a i ⋅ x i , \hat{\mathbf{x}}_t = \sum_{i=1}^ta_i\cdot x_i , x^t=i=1∑tai⋅xi,
y ^ t − 1 = ∑ i = 1 t − 1 a i ⋅ y i , \hat{\mathbf{y}}_{t-1} = \sum_{i=1}^{t-1}a_i^\cdot y_i , y^t−1=i=1∑t−1ai⋅yi,
其中 x t x_t xt是学生在t时刻做的题目的原始编码, a t a_t at是这个题目对应的attention权重。 y t − 1 y_{t-1} yt−1用同样的方法计算,区别在于只计算到t-1时刻的y。
这个 a t a_t at的权重计算方式即为本篇文章标题中的Context-Aware Attention,
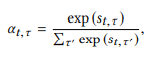
其中,
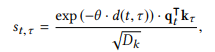
进一步其中,
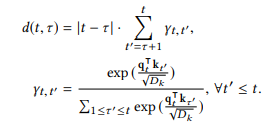
下面对这几个计算公式进行一下分析,首先 a t , τ a_{t,\tau} at,τ就是对一个学生的整个做题记录的注意进行softmax归一, s t , τ s_{t,\tau} st,τ中的 q t T k τ D k \frac{q_t^Tk_{\tau}}{\sqrt{D_k}} DkqtTkτ这部分是DKVMN的一个常规查询操作,而前面的 d ( t , τ ) d(t,\tau) d(t,τ)这个函数就是用来“查询context”的。这里用 ∣ t − τ ∣ |t-\tau| ∣t−τ∣代表的是查询的两个题目之间的次序之差,而后面一部分的求和项相当于查询的两个题目之间有多少相同概念的题目,而且这里说的多少也不是单纯的个数,而是DKVMN查询并归一化后的有多少相同成分的多少。假如说,从 τ \tau τ时刻的题目到t时刻的题目之间,没有任何有相同概念的题目的话,我们就不对 τ \tau τ时刻题目的影响进行衰减,就相当于把同样概念的 τ \tau τ时刻和t时刻的两个题目是连续做的(实际上中间可能间隔了其他概念的题目)。
引入了context-aware的距离 d ( t , τ ) d(t,\tau) d(t,τ)之后,用这个距离来计算context-aware的attention。 s t , τ s_{t,\tau} st,τ一式中还有一个 θ \theta θ,这个是一个学习到的decay参数。 -
Knowledge Retriever
这一部分同样使用DKVMN查询,以t时刻题目的 q t ^ \hat{q_t} qt^与之前所有题目的 k i k_{i} ki相乘,然后经过Monotonic Attention的衰减后与i时刻用户的知知识状态相乘(我的理解:存在一个比较固定的知识DKVMN,用i时刻用户的item-response向量作为query查询到的value,代表这个时刻用户的只是状态),最后求和得到 h t h_t ht,这个 h t h_t ht代表经过前面所有题目经验的积累,用户对当前题目的理解。(我感觉这像是用t时刻的题目query之前所有时刻的知识状态,然后衰减后求和作为当前的知识状态)
模型效果

在三个不同的公开数据集都得到了最佳的预测效果,其中ASSISTment2009和ASSISTment2017因为有知识点标注,所以可以用Rasch model进行embedding(AKT-R模型中的R代表使用了Rasch model进行embedding)。
可以看到context-aware attention 和 Rasch model embedding这两个操作分别都能提高模型表现。此外,Rasch model embedding还能将不同的题目映射到同一个embedding空间里,在这个空间里同一个concept的题目会被映射到一起,但是又能区分这些题目的难度。
















 1506
1506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









