







目录
机器学习2021 类神经网络训练不起来怎么办(一) 局部最小值和鞍点
初入手心得
课程链接很多,不知道要从哪里入手,信息量大。
先看了class和hw,以下是Lecture1 涉及到的网路课件(发现有交叉部分Lecture2的内容):
| Preparation | 【機器學習2021】預測本頻道觀看人數 (上) - 機器學習基本概念簡介 | 从Regression介绍到神经网络 |
| 【機器學習2021】預測本頻道觀看人數 (下) - 深度學習基本概念簡介 | ||
| Class Material | 【機器學習2022】開學囉~ 又要週更了~ | 这学期的课程大纲 |
| Pytorch 1 | Pytorch入门 | |
| Pytorch 2 | ||
| Extra Material | Introduction of Deep Learning | 往年其他版本的授课 |
| Backpropagation | ||
| Predicting Pokémon CP | ||
| Pokemon classification | ||
| Logistic Regression | ||
| HW1.pdf内链接 | 【機器學習2021】類神經網路訓練不起來怎麼辦 (一) | 实际工程中可能遇到的问题(鞍点、批次大小等) |
| 机器学习2021 机器学习任务攻略 |
做了HW1后回顾发现,想要提升HW1的performance,重点是注释里面的TODO和HW1.ppt里面的提示。课件主要偏理论介绍,老师授课内容并不涉及具体py代码,学长学姐的讲解主要是工具包的介绍等。
Preparation—预测本频道观看人数
机器学习的模型分类
按照输出类别来定义,有以下的结论。
Regression:输出对一个常量的预测
Classification:给出各种类别,选择正确的类别
Structured Learning:输出具有结构的预测(如pictures等)
一个机器学习例子
通过讲如何对youtuber频道观看人数预测,达到介绍机器学习做了哪些工作。以及介绍了简单的神经网络。
1. Function with unknown Parameters 选择一个适合该问题的函数or模型
2. Define Loss from Training Data 定义评判输出的预测与实际值的误差计算方法
3. Optimization 最佳化使Loss最小
如以下两个不同的预测过程:
1. gradient descent + linear regression(对于当前例子是高bias的,模型过于简单)
2. 单层神经网络,利用sigmoid的组合来模拟不同形状的curve
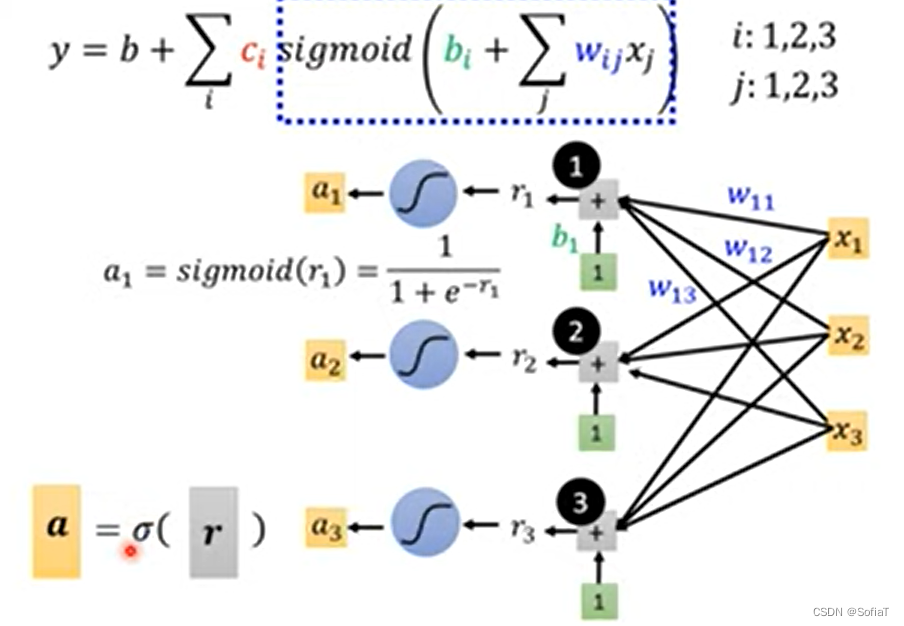
Class Material
Week1
简介本学年课程的主题设置
lecture1~5是监督式学习
lecture6 generative adversarial network(生成对抗网络)
lecture7 自监督式学习(pre-train与downstream task)
lecture8 异常检测,lecture9 可解释性AI
lecture10 模型攻击
lecture11 domain adaptation(领域适应)
lecture12 reinforcement learning(增强学习)
lecture 13 network compression
lecture14 life-long learning
lecture15 meta learning/few-shot learning
HW1.pdf内链接
机器学习2021 机器学习任务攻略
开局一张图:
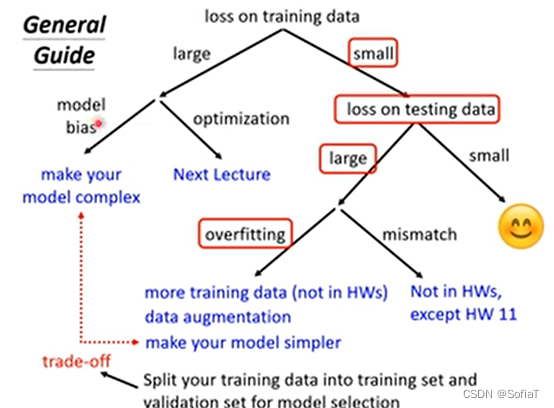
如果training比较高,可能是Model Bias(模型过于简单),或是Optimization Issue(训练过程有问题,没法找到最小的Loss),可以通过比较不同的模型来判断。

尝试不同的层数/不同的features

由简单到难,如果难的比简单的表现差,那代表optimization做的不好。
机器学习2021 类神经网络训练不起来怎么办(一) 局部最小值和鞍点
判断是否是鞍点——利用泰勒微积分
理论上:
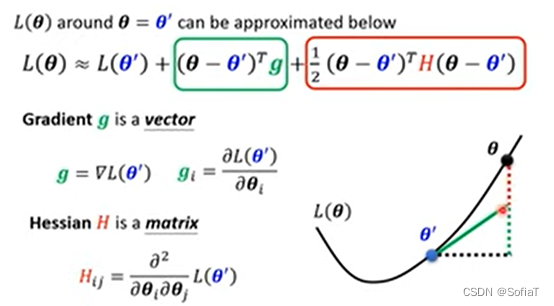

那么,可以用特征向量来逃离鞍点:
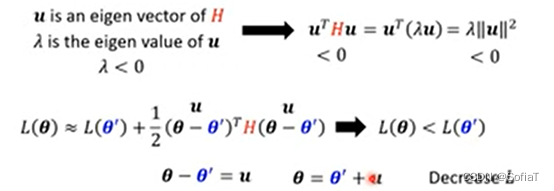
实际上,因为要求二次偏导/特征向量等,运算量过大,所以一般不采用上述理论。下面是老师给出来的一个训练例子:
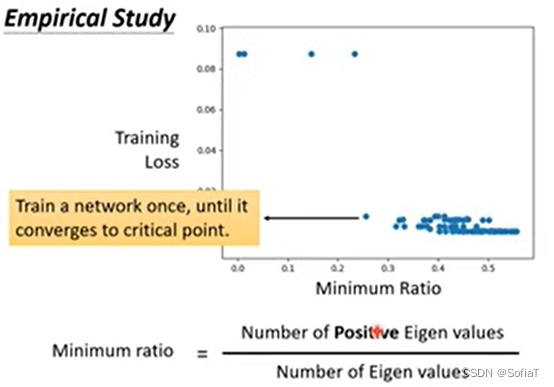
很少有卡在local minimal ,很多都是在鞍点loss就无法下降
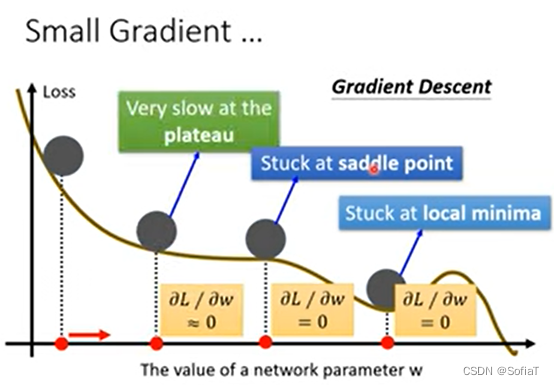
Batch size
梯度下降/批量梯度下降/随机梯度下降等的batch与优缺点

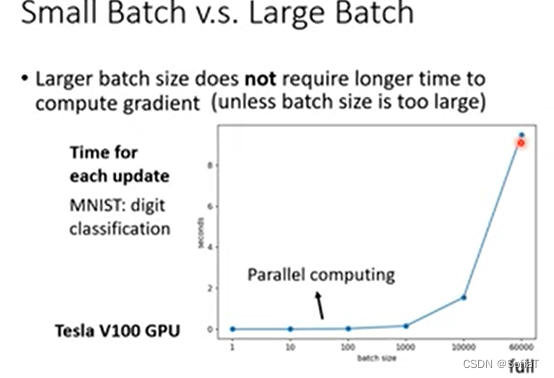
如果用GPU做平行运算,大的batch size所需时间并不会立即增大,再考虑上跑一次epoch需要的循环,并不是越小就越快。
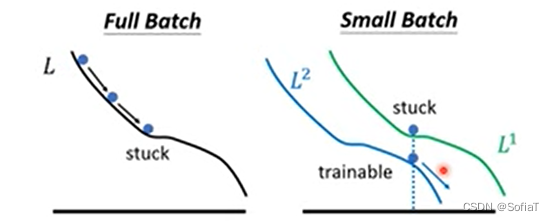
但是 ,比较noisy的batch size,在较大的数据集上获得的效果反而要更好:

可能是因为batch size小有助于逃离鞍点:
且甚至在test set上表现的也更好,大的batch size会over fitting:
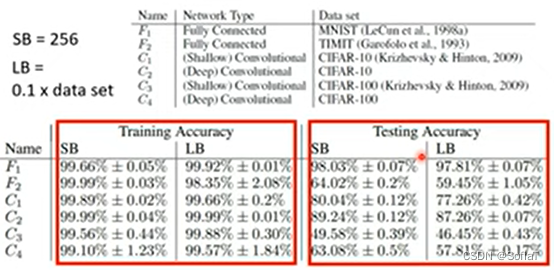
如果对解决这个问题感兴趣,可以阅读以下paper:

















 944
944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









