







论文阅读:知识图谱综述笔记
面向可解释性的知识图谱推理研究分享
面向可解释性的知识图谱推理研究针对知识推理介绍了研究背景、前沿进展,针对可解释性介绍了研究动机、近期研究(主要使用强化学习技术)和研究展望。个人觉得此文很不错,脉络清晰,还对知识图谱推理的可解释性来源进行了分类,对强化学习结合推理进行了较为深层次的介绍,而非泛泛之谈。
《知识图谱综述——表示、构建、推理与知识超图理论》2021
介绍了知识图谱发展过程(时间轴从1965~2012年)
知识图谱分类
按内容划分:
“早期知识库、开放知识图谱、中文常识知识图谱和领域知识图谱等”
早期: 人工,WordNet、ConceptNet等
“WordNet 主要定 义了名词、动词、形容词和副词之间的语义关系。例如名词之 间的上下位关系中,“Canine”是“Dog”的上位词。”
“ConceptNet 采用了非形式化、类似自然语言的描述,侧重 于词与词之间的关系。ConceptNet 以三元组形式的关系型知 识构成”
开放: 开源访问、使用、修改,Freebase、Wikidata等
“Freebase 基于 RDF 三元组模型,底层采用图数据库存储,包含约 4400 万个实体,以及 29 亿相关的事实。”
“Wikidata 以三元组的形式存储知识条目,其中每个三元组代表一个条目的陈述,例如“Beijing” 的条目描述为“ Beijing,isTheCapitalOf,China ”。Wikidata 包含超过 2470 万个知识条目。”
按架构划分:
“模式层和数据层,概念及关系,事实三元组”
模式层:结点、边的定义(具体有哪些)e和r
数据层:结点、边的位置和连接方式(他们是怎么组合的)f
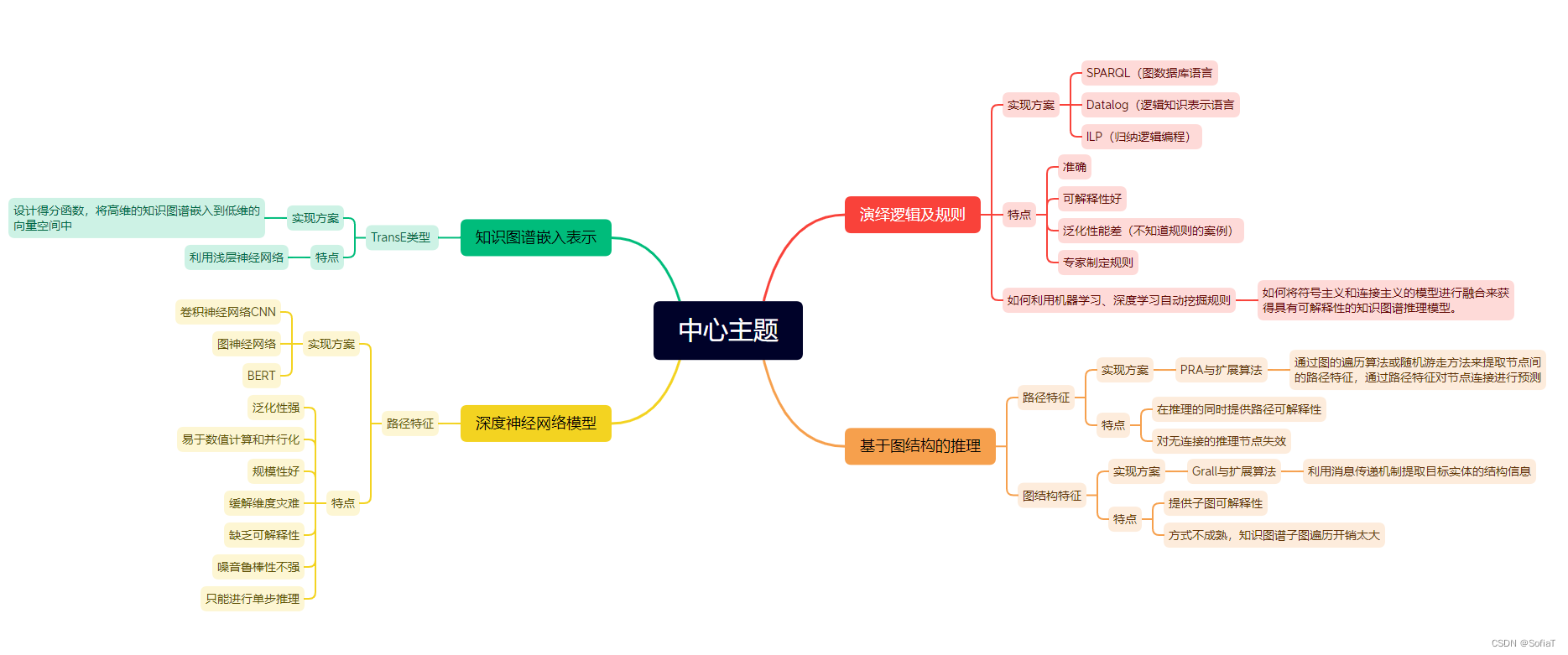
知识推理:
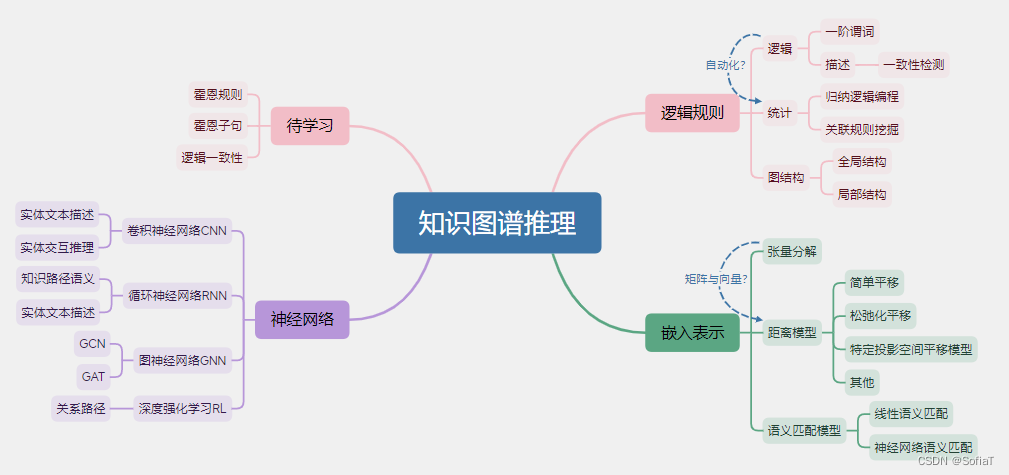
基于逻辑规则
按照专家(人类)设定的逻辑、特征规则进行推理
- 基于逻辑
-
基于一阶谓词逻辑:对专家预先定义好的规则进行表示,以命题 (Propositions)为基本单位,命题包含个体(实体)和谓词(关系)。开山作用了马尔可夫逻辑网络(MLN),引入置信值、缺少数据等小场景。简单可解释,适用于小规模图谱。
-
基于描述逻辑:将复杂关系、推理转换为一致性检测。降低了复杂度。以术语集(Terminological Axioms,TBox)和断言集(Assertional Axioms,ABox)为基本单位。TBox包含描述概念和关系的一系列公理,ABox包含Tbox概念的实例。确定一个描述是否满足逻辑一致性。开山作是Halaschek-Wiener提出的描述逻辑推理方法。 引入信息不完备、模糊理论、属性描述逻辑、上下文感知、可解释性。
- 基于统计
- 基于归纳逻辑编程(ILP):在图谱上归纳出抽象的规则集以完成推理,摈弃了人工定义规则的模式。开山作为一阶规则学习算法(First OrderInductive Leaner,FOIL) ,将霍恩子句(Horn Clauses)作为特征,用穷举法搜索,为每个关系建立判别器,预测指定实体间是否存在关系。引入了贝叶斯算法用于处理不确定性,引入核方法降低复杂度。
- 基于关联规则挖掘:在知识图谱中自动挖掘出高置信度的规则,利用这些规则在知识图谱上推理以得到新的知识。比传统方法更快,处理数据更多、更复杂。开山作是基于不完备知识库的关联规则挖掘算法(Association rule Mining under Incomplete Evidence,AMIE),通过在知识图谱上挖掘霍恩规则(Horn Rules),将这些规则用于知识图谱得到新的知识,补全并检测图谱中的错误。引入AMIE+扩大图谱规模,RDF2Rules并行挖掘规则,非结构化文本结合图谱。
- 基于图结构
利用图谱结构作为特征完成推理,特别是路径特征。
- 基于全局结构:整个知识图谱进行路径提取,判断实体间是否存在目标关系。开山作为路径排序算法(Path Ranking Algorithm,PRA),为没类关系都训练一个逻辑回归模型,采用随机游走策略。 引入Cor-PRA、CPRA、ELP减少巨大计算代价。需要考虑数据稀疏性。
- 引入局部结构:利用与推理高度相关的局部图谱结构为特征,实现知识图谱推理。开山作为SFE(Subgraph Feature Extraction),首先使用广度优先搜索得到局部子图,然后进行多特征提取,再进行推理。HIRI(Hierarchical Random-walk Inference)分层随机游走算法提高随机游走性能,TRWA(Two-tier Random Walk Algorithm)双层随机游走算法同时考虑子图和关系语义的双向性,考虑更细的局部结构特征,忽略了子图之间的关系。
基于嵌入表示
- 张量分解方法
- 张量分解(Tensor Decomposition,TD)将关系张量分解为多个矩阵,构造低维嵌入表示。开山作为RESCAL,得到实体和关系类型的嵌入表示,反映实体或关系邻域结构的相似性。 YAGO引入属性信息模块,Rendle考虑二元关系与大规模关系,Jenatton概率模型稀疏表示来处理极大规模。
- 距离模型
Distance Model(DM)优课称为平移模型(Translational Model,TM),将关系看做从主体向量到客体向量的平移变换。
- 简单平移TransE:h+r~t,r向量可以复用在多个h与t之间。
- 第一个问题,平移过于严格,缺少鲁棒性,引出松弛化平移模型:TransM 权重、ManifoldE 流型、TransF 噪声、TransAt 注意力机制、TransA 马氏距离。
- 第二个问题,无法处理非一对一关系,引出在特定投影空间平移模型:TransH 超平面、TransR 实体空间与关系空间 经典但是开销高、TransD 向量transR、TransSparse 稀疏矩阵、TransAH 自适应度量方法,对角权重矩阵,加权欧氏距离。
- 其他改进:KG2E、TransG、Totate、TorusE、CEKGRL、TransE-NA、MCKRL。
- 语义匹配模型
设计基于相似度的目标函数,在低维向量空间匹配不同实体和关系类型的潜在语义,定义基于相似性的评分函数,度量一个三元组的合理性。认为关系组内部应有高相似度,反之有低相似度。
- 线性语义匹配:开山作TATEC(Two And Three-way Embeddings Combination)对二元语义和三元语义进行匹配,衡量各关系的合理性。在匹配主谓宾三元语义时,也对主体与关系、关系与客体、主体与客体进行匹配,然后加权得到评分总值,运算复杂度较高。 引入DistMult对角矩阵减少运算量,引入HolE向量卷积实现主客体信息融合,引入ComplEx复空间,引入QuatE超复空间,引入ANALOGY考虑到实体的隐喻关系。
- 神经网络语义匹配:开山作SME(Semantic Matching Energy),通过神经网络学习关系和实体的低维向量表示。引入NTN(Neural Tensor Networks)加入非线性函数增强拟合能力但开销大幅增加,引入NAM(Neural Association Models)采用深度神经网络方法。
基于神经网络
- 卷积神经网络:实体文本描述或实体关系交互 → 卷积 → 文本嵌入或交互特征
- 基于实体文本描述的推理(Entity Text Description,ETD):利用CNN对ETD进行解析,从中提取出关键的文本片段,转换为嵌入向量,利用文本特征辅助语义实体。开山作DKRL,利用连续词袋模型(CBOW)和CNN学习无序特征和词序特征,实现新实体的有效发现。
- 基于实体交互的推理:利用在同一个三元组中,实体语义和关系语义的相互关系。开山作ConvE利用二维卷积、嵌入投影、内积等操作。引入InteractE增加交互数量,M-DCN交替输入实体关系嵌入,ConvKE、Convolution-based KG结合注意力机制。
- 循环神经网络:知识路径结构或实体文本描述 → 循环结构 → 路径嵌入或文本嵌入
提取知识序列特征,预测缺失关系。
- 基于知识路径语义的推理:知识路径指知识图谱中由实体关系交替组成的有序路径,迭代学习路径的语义特征,发现关联路径上的隐含语义。开山作RNN+RPA Classifier。引入Single-Model组合多条关系路径、DSKG双向语义。
- 基于实体文本描述的推理:利用RNN读入ETD信息,完成不同三元组中实体语义信息匹配。开山作KGDL(learning Knowledge Graph Embeddings wiith entity Descriptions based on LSTM networks)逐词编码相关文本描述,嵌入三元组编码的实体描述。引入CATT、T-CRNN、CRU、MATT等。
- GNN图神经网络方法:知识图谱拓扑结构 → GCN、GAT → 实体关系嵌入
- 基于GCN的推理:引入傅里叶变换,把图结构变换到由图拉普拉斯矩阵特征向量构成的正交空间中。基于GCN的推理,把图谱视为无向图,分析拓扑结构,实现领域向中心实体的语义聚合。开山作SACN。
- 基于GAT(Graph Attention Networks)的推理:在聚集邻域特征信息时,通过ATT确定邻居节点权重信息,从而实际邻近区域对中心投资程度的自适应调节。开山作DPMPN。
- 深度强化学习:知识图谱拓扑结构 → 路径生成策略 → 路径嵌入和路径生成策略
- 基于关系路径的推理:结合深度学习的感知能力和强化学习的决策能力,将图谱的推理建模为序列决策模型,基于关系路径推理。开山作为DeepPath。
超图理论:
《Knowledge Hypergraphs: Prediction Beyond Binary Relations》2020
《the representation and embedding of knowledge bases beyond binary relations》2016
个人感知:
基于统计是基于逻辑的机器学习版本。
简介
从知识图谱的Knowledge Representation Learning、知识获取和知识感知应用三个方面对知识图谱进行了综述。
该综述也广泛覆盖了新兴主题,包括基于变压器的知识编码transformer-based knowledge encoding、基于图神经网络(GNN)的知识传播knowledge propagation、基于强化学习的路径推理和元关系学习。
发展历史

高频术语介绍与中英文对照
知识图 knowledge graph 是事实的结构化表示,它由实体、关系和语义描述组成。
实体 entities 可以是现实世界的对象或抽象概念;关系 relationships 表示实体之间的关系;实体及其关系的语义描述 semantic descriptions 由类型和性质组成,这些类型和性质有着精确的定义。

知识图谱的结构上是图,在语义形式上是知识库 knowledge base(知识图谱能解释和推断事实)。
在the resource description framework (RDF)资源描述框架中,我们把知识定义为一种三重奏即(头-关系-尾巴)或者(主语-谓语-宾语)。

近年来,基于知识图的研究主要集中在knowledge representation learning (KRL) 知识表示学习 或knowledge graph embedding (KGE)知识图嵌入 ,通过将实体和关系映射到低维向量中并获取其语义。
具体的知识获取任务包括知识图完成 (knowledge graph completion, KGC) 、三重分类 triple classification、实体识别 entity recognition和关系提取 relation extraction。
知识感知模型 Knowledge aware models受益于集百家之大成,它包含了异构信息heterogeneous information、丰富的本体ontologies与语义semantics知识表示以及多语言multilingual知识。
知识图谱在工业应用中取得了优异的表现,主要是推荐系统与question-answering。
分类

KRL 知识表示学习
我们分为四个方面介绍,包括空间表示、评分函数、编码模型和辅助信息auxiliary information,它们组成了开发一个KRL的流程:
1)表征空间:用来表示关系和实体;
2)评分函数:用于测量factual三元组的可信性;
3)编码模型:表示和学习关系交互;
4)辅助信息:纳入embedding methods
表征空间包括逐点空间、流形、复向量空间、高斯分布和离散空间。
评分指标一般分为基于距离的评分函数和基于相似度匹配的评分函数。
编码模型目前的研究主要集中在线性/双线性模型,因式分解和神经网络。
辅助信息包括文本信息、视觉信息和类型信息。
Knowledge Acquisition 知识获取
知识获取任务分为三大类,即KGC、关系抽取relation extraction和实体发现entity discovery 。第一个是扩展已有的知识图,另外两个是从文本中发现新的知识(也就是关系和实体)。
知识图完成KGC研究了基于嵌入排序embedding-based ranking、关系路径推理relational path reasoning、逻辑规则推理logical rule reasoning和元关系学习meta relational learning。
关系抽取模型利用注意机制,图卷积网络(GCNs),对抗训练,强化学习,深度剩余学习和迁移学习。
实体发现分为实体识别entity recognition、输入typing、消歧disambiguation和对齐alignment;并根据神经范式neural paradigms讨论了关系的提取。
Temporal Knowledge Graphs 时间知识图
包含用于表示学习的时间信息。本综述分为四个研究领域,包括时间嵌入、实体动力学、时间关系依赖和时间逻辑推理。
Knowledge-aware Applications 知识感知的应用
包括自然语言理解(NLU)、问题回答、推荐系统和其他现实世界的任务,它们注入知识来提高表示学习。
KNOWLEDGE REPRESENTATION LEARNING
2) knowledge acquisition and completion 知识获取与完成
3) temporal knowledge graph 时序知识图谱
4) knowledge-aware applications 知识感知应用
summarize recent breakthroughs and perspective directions 近期突破与展望方向总结
知识图谱嵌入综述
简介
定义: 知识图(KG)嵌入是将包含实体和关系的知识图的分量嵌入到连续向量空间中,从而在保持知识图固有结构的同时简化操作。
作用: 可以帮助各种下游任务,如KG完成和关系提取
首先介绍的技术只使用在知识图谱中观察到的事实现象来进行嵌入。















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









