







文章目录
SPARQL的四种查询方式
SELECT
单三元组模式、最简单的图模式
查询张三认识的其他程序员
PREFIX ex:<http://www.example.com/>
SELECT ?p
WHERE{ex:zhangsan ex:know ?p.}
抽象来看
SELECT <variable>
WHERE{
<graph pattern>
}
说明:
- SPARQL的变量以
?开始; - 三元组模式;
- SELECT能够返回满足条件的变量的TABLE;

返回FOAF文件中每个人的URI、名字和邮箱地址。
PREFIX foaf:<http://xmlns.com/foaf/0.1/>
SELECT *
WHERE
{
?person foaf:name ?name.
?person foaf:mbox ?email.
}
*会选取所有在查询中提及的变量。
多三元组查询、基本图模式
查询程序员张三认识的其他程序员参加的项目
PREFIX ex:<http://www.example.com/>
SELECT ?pr
WHERE{
ex:zhangsan ex:knows ?p.
?p ex:participate ?pr.
}
输出:
ex:graphdb
ex:triple
这是由两个三元组模式组成的一个基本图模式查询,简称为BGP查询。这两个三元组通过一个公共变量?p连接为一个链式查询。

这里注意一下这个指定了目标图哦。
下面这个意思是:找一下那些参与过三次ISWC或ESWC会议的人。

a表示有属性。
在三个不同的图中,找到?person。

knows/name表示先找到x认识的人,再找到他的名字。这称之为一跳。
+表示knows经历了多跳。
CONSTRUCT

返回以模板形式构建的集合,其中变量被查询的内容所替换。
ASK

DESCRIBE


返回的是与P2556相关的全部三元组,而不简简单单是P2556。
Cypher查询语言
属性图

形式化定义:
- 节点:图中的实体,用表示其类型的0到多个文本标签进行标记,相当于实体;
- 边:节点之间的定向连接,也称为关系。每条边都有一个类型,相当于实体之间的关系;
- 属性:键值对,顶点和边都有属性。
Cypher概述
| 名词 | 解释 | 实例 |
|---|---|---|
| 节点 | ()表示节点 | (n:Person)表示使用变量n引进了Person节点 |
| 关系 | -表示无方向关系;->,<-表示有方向关系 | (:Person)->(:Animal)表示人这个实体和动物实体之间的关系 |
| 关系描述 | []描述关系详情 | (:Person)-[:relation]->(:Animal)表示这个relation表示人和动物的关系 |
| 属性描述 | {}描述属性 | (:Person{name:“张三”})描述姓名为张三的Person节点 |
Cypher查询语句
# 查询Dept下的内容
MATCH (dept:Dept) return dept
# 查询Employee标签下id=123,name=“Lokesh”的节点
MATCH(p:Employee{id:123,name:"Lokesh"}) return p
# 查询Employee标签下name="Lokesh"的节点,使用(where)
MATCH(p:Employee)
WHERE p.name = "Lokesh"
return p
基本查询:

关注非空的写法。

分别是:改数据、降序排序、只输出两个、取值集合。

分别是:单标签、多标签、特定属性($表示一个类型)、任意无方向(区别于有方向)关系(关系)。

分别是:特定无方向关系、无方向或关系、特定无方向关系及标签、任意无方向但有关系(节点)

分别是:任意有方向关系(节点)、有方向的单层关系、有方向的多层(取值范围)关系
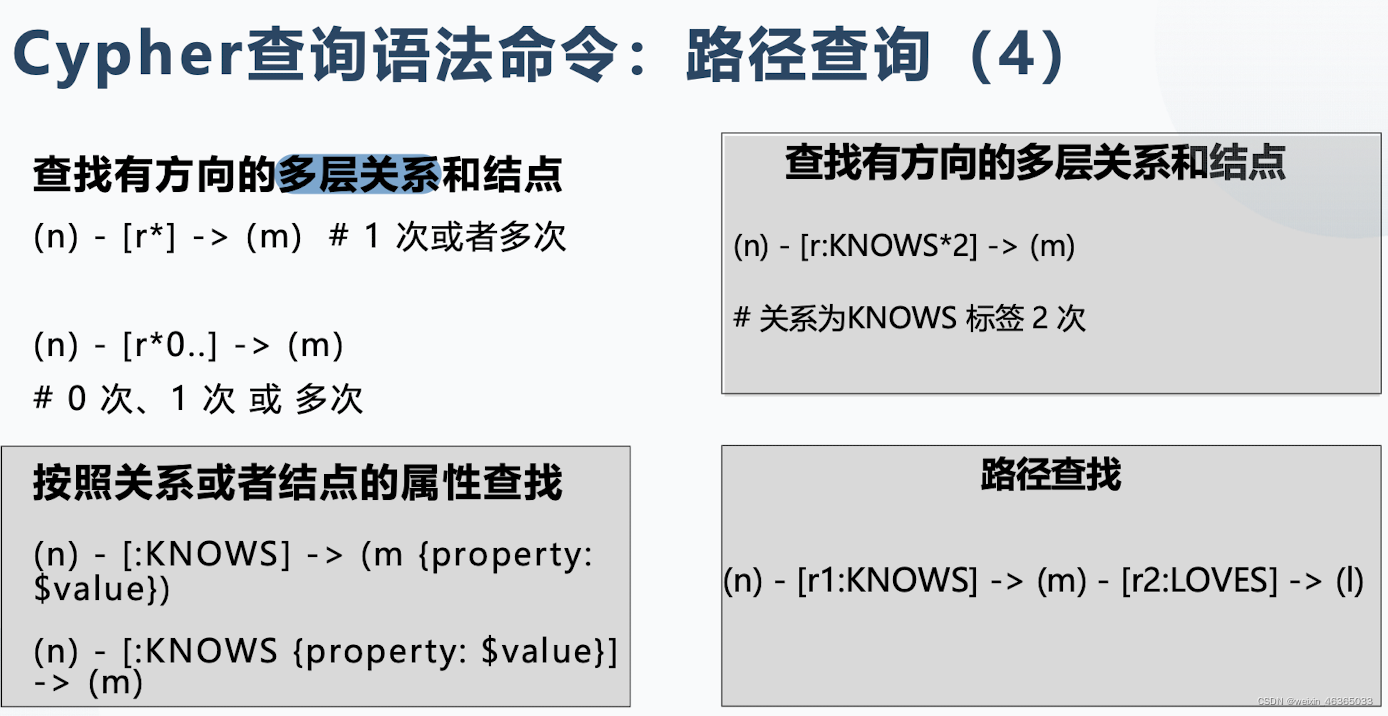
最后是:两个关系。


OPTINAL MATCH语句⽤于搜索模式中描述的匹配项,对于找不到的项⽤null。
match (n {name: 'aaa'})
optional match (n) --> (b)
return b, b.name
如果b存在就返回b, 否则返回null
对于不存在的b, 尝试返回b的属性返回的也是null
with作为管道将查询结果从一部分以管道形式传递给另一部分作为开始点。第2行的r被第3行的r筛选出来传递给第4行。
count则能返回每个s 的数量。
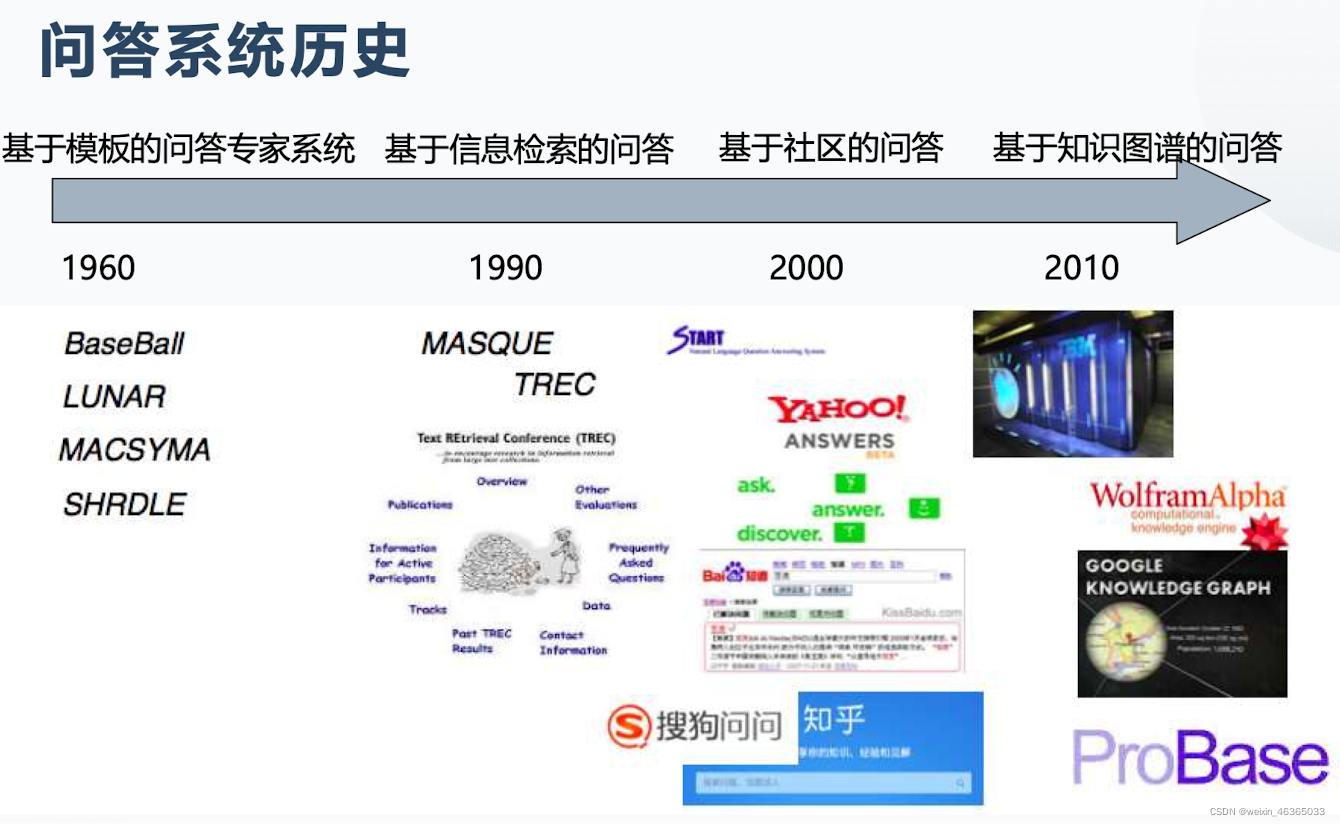
Q13:问答系统的发展史及不同时期的代表系统或平台
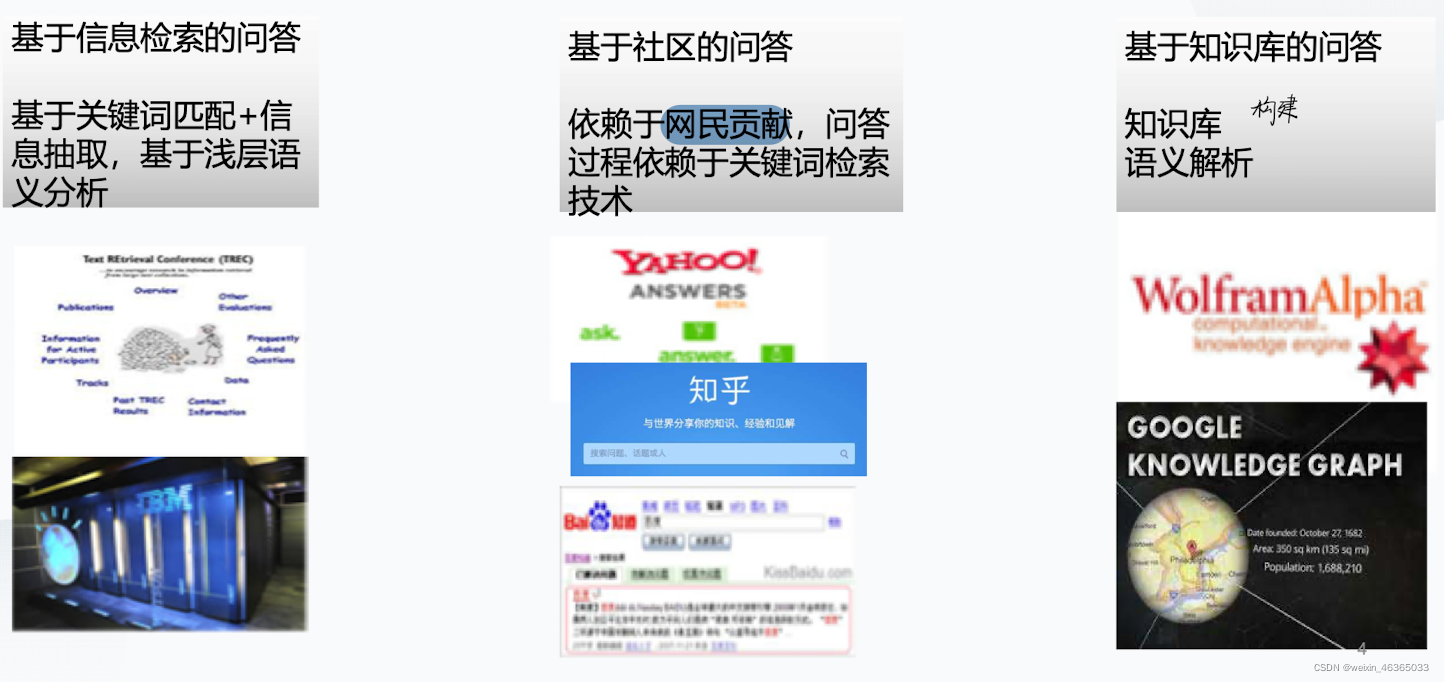
Q14:知识库问答的三种常见方法(基本原理)及优缺点
问答系统概述
问答形式的类型:一问一答、交互式问答以及阅读理解。
问答系统的框架:

构造query及构造查询语句。
问答系统的流程:

| 问答系统的基本概念 | 描述 |
|---|---|
| 问句短语 | 问句短语定义问的是什么:who/what/which/when/where/why/how |
| 问题类型 | 问题类型决定后续采用什么样的回答处理策略 |
| 答案类型 | 常见的有:事实性、摘要性、描述性 |
| 问题主题 | 问题是关于什么方面的 |
| 答案来源类型 | 数据源 |
| 领域类型 | 数据类型(文本、图片、音频、视频);开放域、特定淤 |
知识库问答方法
基于模板的问答方法(TBSL)
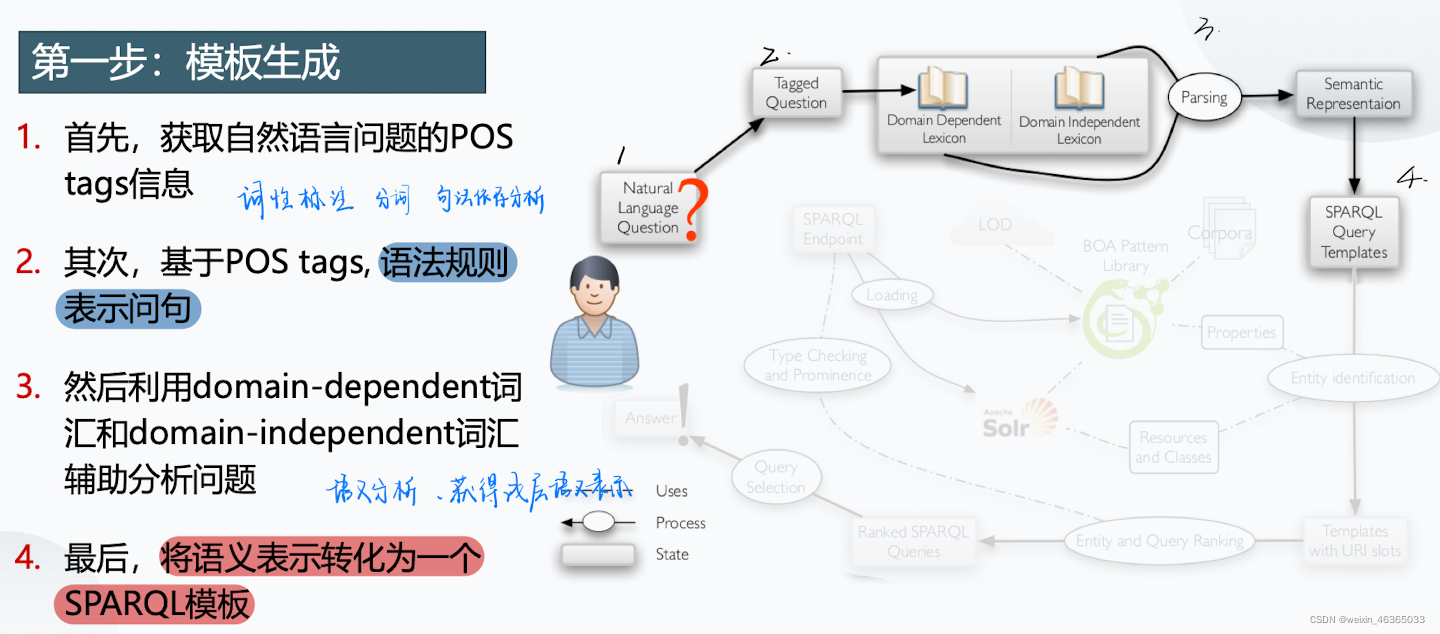
pos tag表示语义标签。

通过语义标签与领域相关性词汇找到关键词,然后以此为依据构建三元组。
这里一共有两种模板,一个表示的是:x导演了y,y是电影;另一个表示的是:x的电影有y。
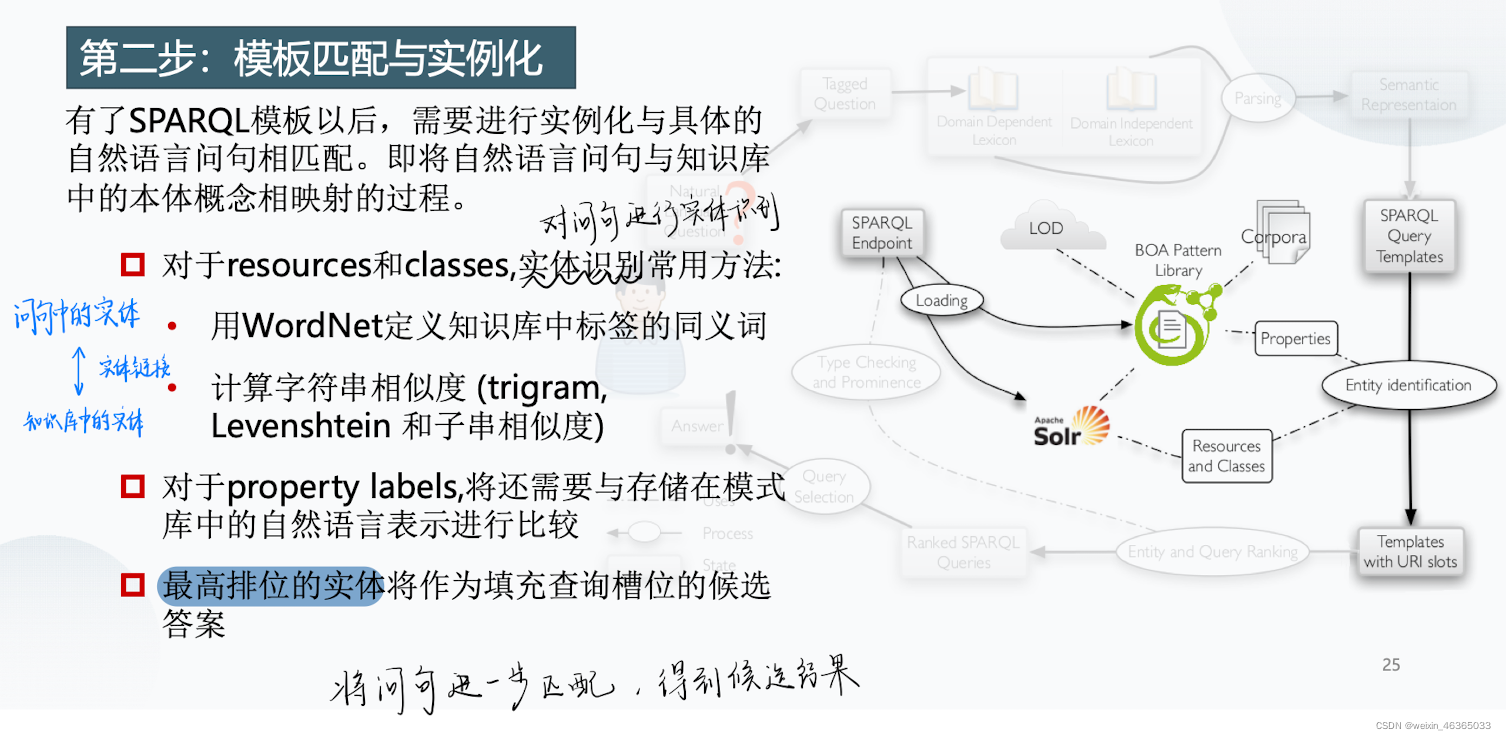
我有了这个模板,模板里面也有了一些名词,但这个名词还需要和知识库中的名词建立对应关系。最后在模板中的属性还得是知识库中的实体。

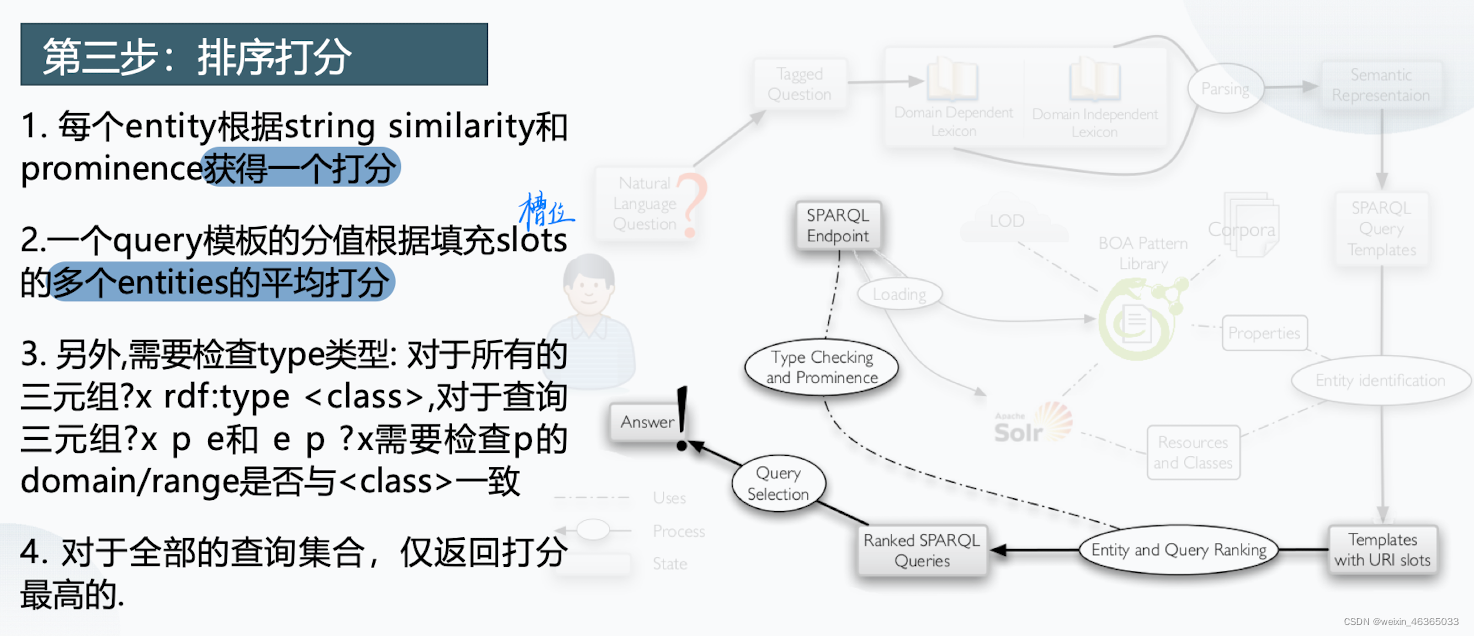

| 优点 | 缺点 |
|---|---|
| 模版查询响应速度快 | 人工定义的模版结构经常无法与真实用户问题进行匹配 |
| 准确率较高,可以回答相对复杂的问题 | 如果为了尽可能匹配上一个问题的多种不同表述,则需要建立庞大的模板库,耗时耗力且查询起来效率低 |
基于语义解析的方法
主要思想是将自然语言转化为一系列形式化的逻辑形式,通过对逻辑形式进行自底向上的解析,得到一种可以表达整个问题语义的逻辑形式,之后通过相应的查询语句,在知识库中进行查询,从而得到答案。
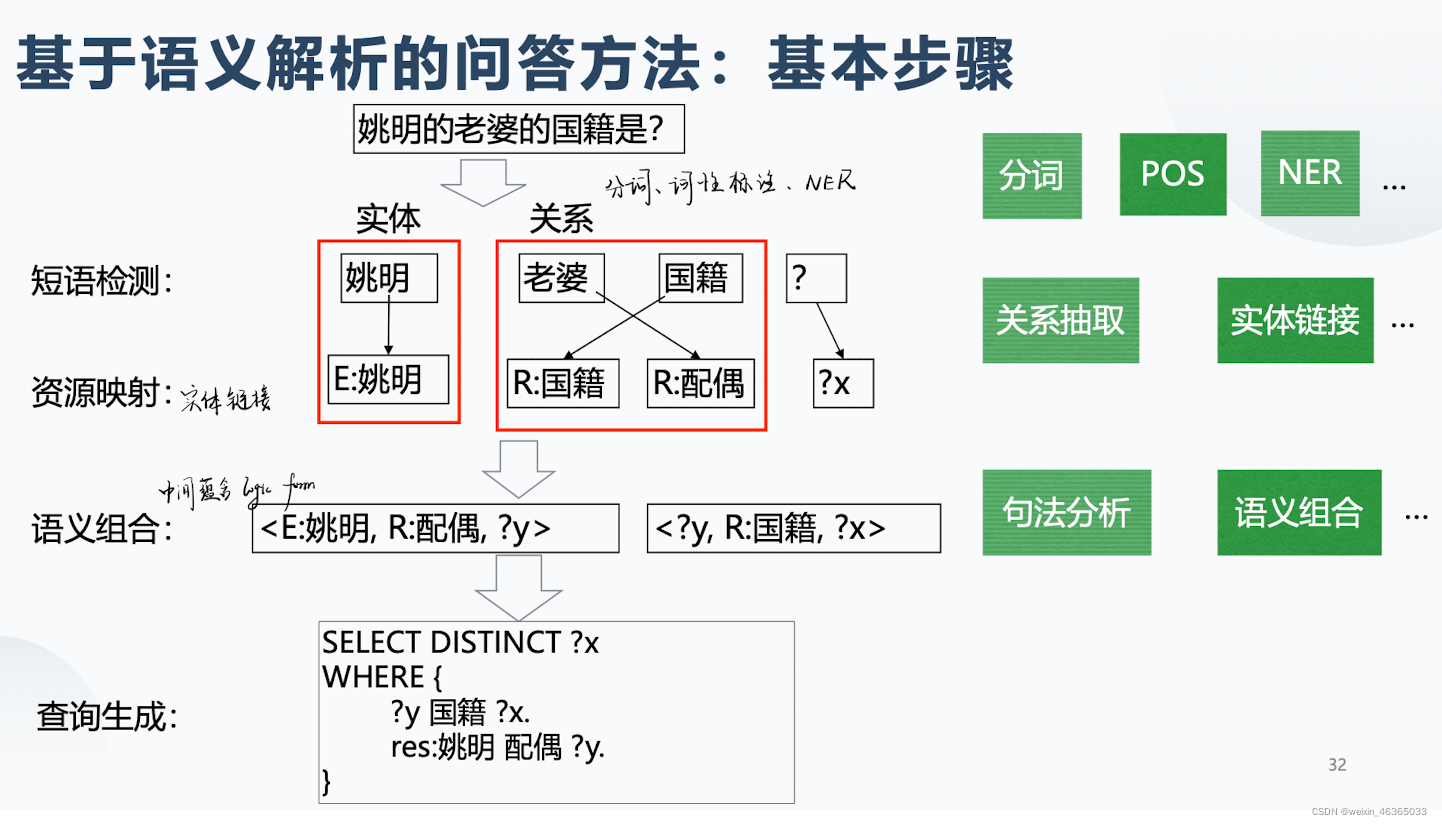
首先检测问句中的关键短语,然后资源映射到数据库中,接着构建起逻辑表达式,最后转化为查询语句,经过查询得到最后的结果。
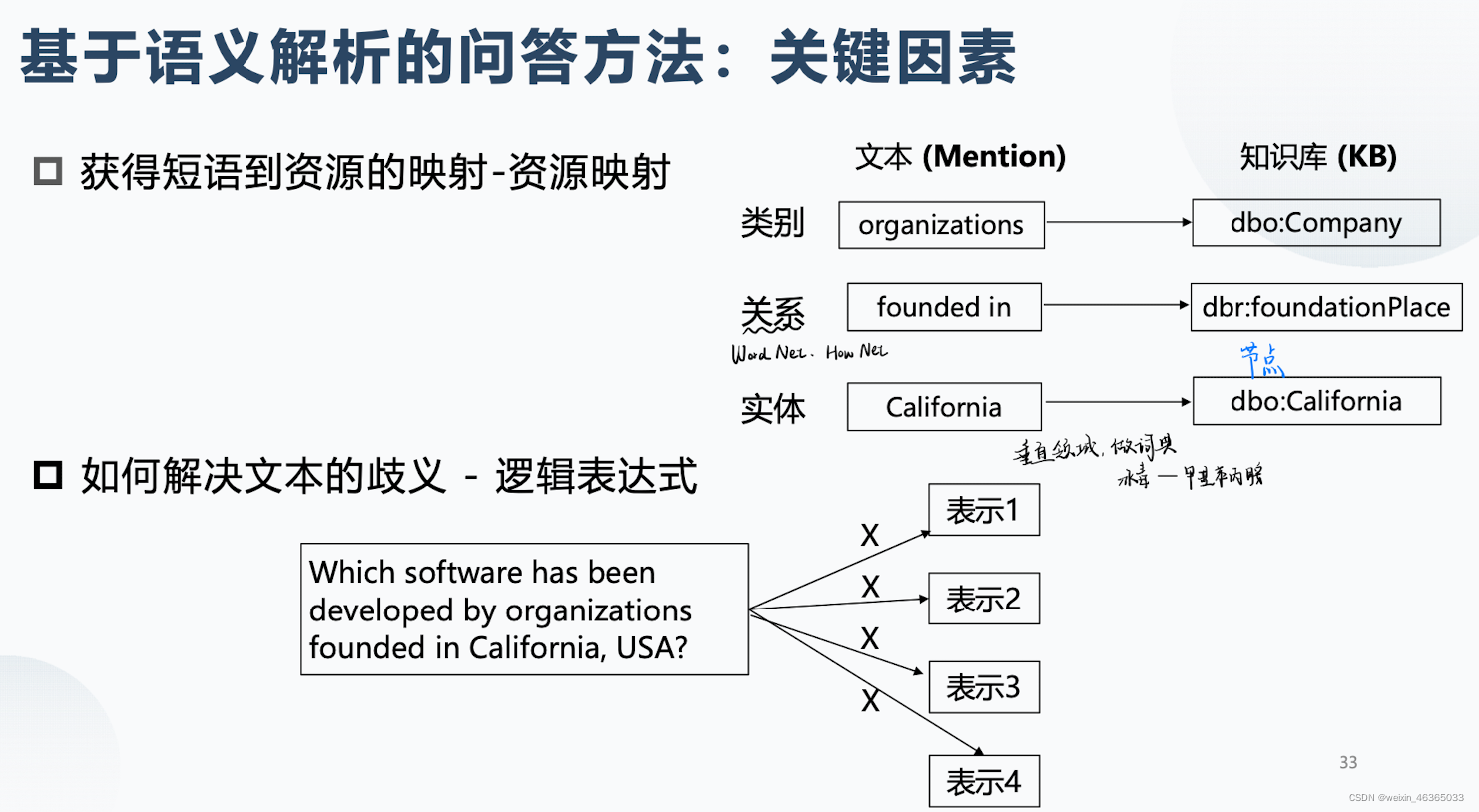
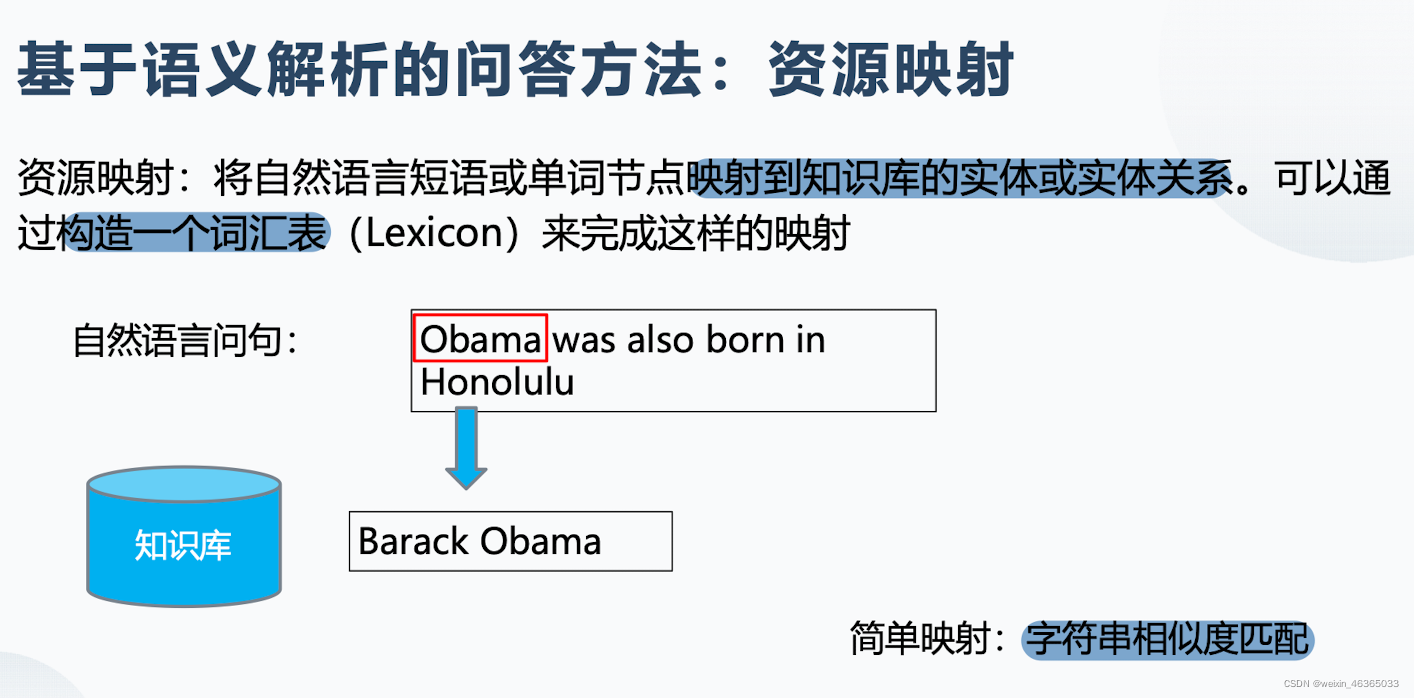

上面两幅图介绍了资源映射的基本概念,然后介绍了两个映射方法。

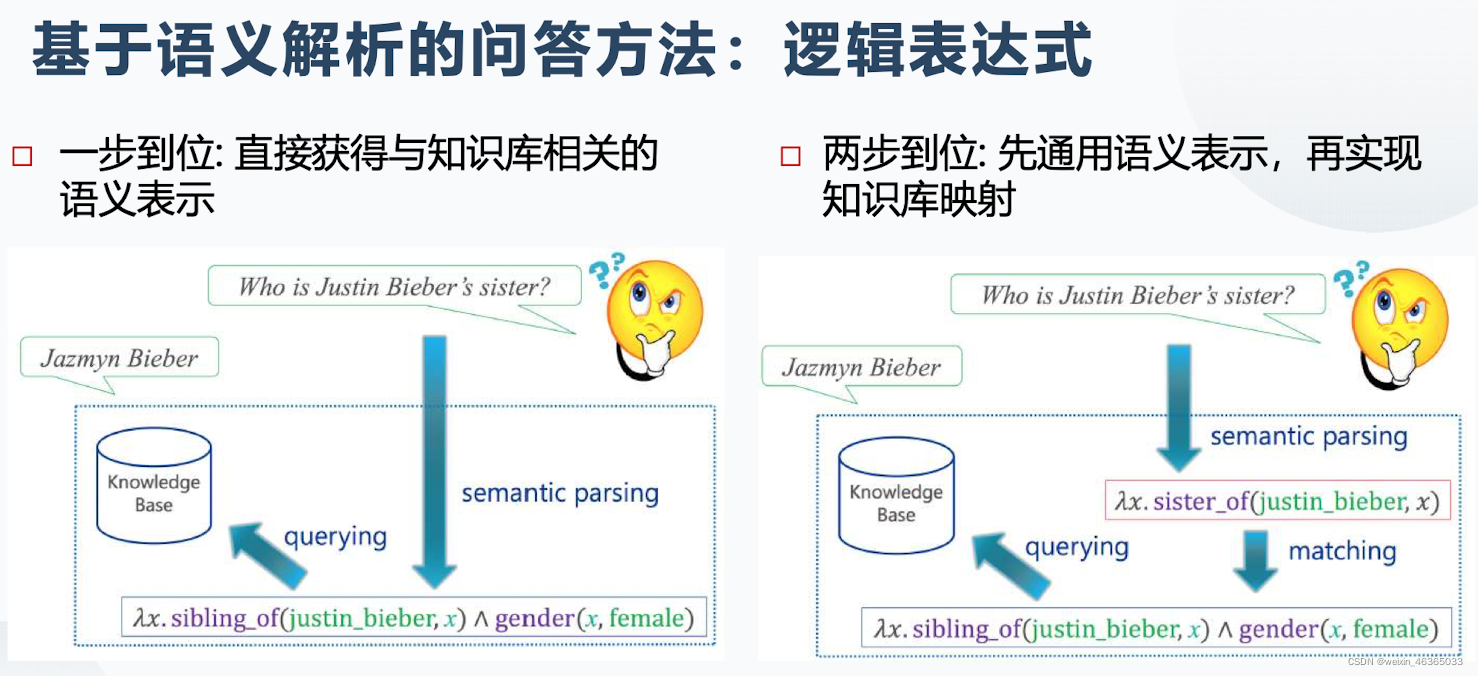
语义解析的过程是通过一个分类器完成,这是一个监督学习的过程,需要提前准备好数据集。
基于深度学习的问答方法
略
三种方法的比较
| 方法 | 优点 | 缺点 |
|---|---|---|
| 模板 | 查询响应快、准确率高,可以回答相对复杂的问题 | 人工定义模板费时费力,且经常无法与用户真实问题匹配 |
| 语义解析 | 可以回答较为复杂的问题,例如时序性问题 | 人工编写规则工程量大 |
| 深度学习 | 无需人工编写规则定义模板,整个学习过程自动进行 | 只能处理简单题和单边关系问题,通常不包含聚类操作,因此时序性问题无法应对 |
Q5:Elasticsearch系统和gAnswer系统的主要算法框架及优缺点
Elasticsearch
系统功能
不是专门用来做知识问答的系统,是一个比较成熟的搜索和数据分析引擎。借助Elasticsearch强大的搜索功能,可以实现简单的知识问答。其主要基于以下四个功能实现:
- 基于实体检索的回答;
- 基于实体属性检索的回答;
- 基于多跳查询的回答;
- 根据属性值查询实体的回答。

根据实体,找到属性。

根据实体和属性找到属性。

多对实体属性组合,找到目标。

根据属性,找到实体。
知识问答流程
基于Elasticsearch的知识问答主要包括以下四个步骤:
- 数据准备:将数据集转化为JSON格式,必要时可进行属性同义词扩展;
- 导入Elasticsearch:在Elasticsearch中创建index和type索引,并导入JSON数据;
- 自然语言转化为Logical form:解析自然语言,生成logical form;
- Logical form翻译成ES查询语句:生成ES查询语句,并执行查询。
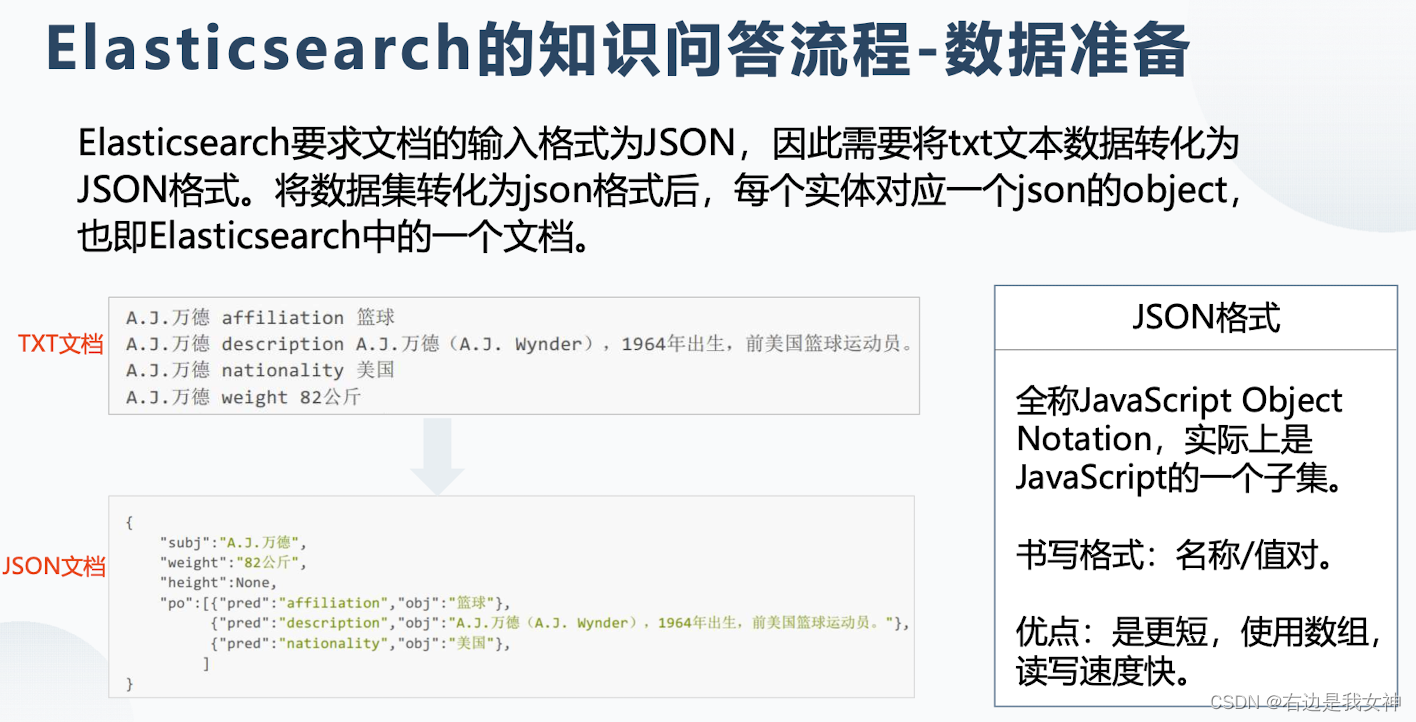


根据问题判断对应使用的模板,填充之后构成logic form。

将logic form填入对应的ES模板,并从ES中开始查询。
优缺点
| 优点 | 缺点 |
|---|---|
| 分布式索引(索引index是一组文档的集合)、搜索 | 只支持简单的自然语句查询,对于复杂的问题无法回答 |
| 索引自动分片(ES是分布式搜索引擎,所以索引被自动分配在不同的地方)、负载均衡 | 在添加新数据和新字段时,ElasticSearch进行搜索可能需要重新修改格式 |
| 自动发现机器、组成集群(多个节点组成的小群体) | ElasticSearch是基于符号逻辑的,符号的匹配会造成语义鸿沟(机器和人类的理解差距)的问题 |
| 支持Restful风格接口 | - |
| 配置简单 | - |
gAnswer
系统功能
主要解决RDF Q/A的以下两个挑战:
- 语义消岐(资源映射):如何将自然语言中具备歧义的实体短语和关系短语对应到知识库中确定的实体和谓词上;
- 查询构建(语义组合):如何将映射后的实体和谓词拼接为一个完整的SPARQL查询。
解决方案:
- 将消岐和查询评估结合起来,具体来说,在查询匹配时解决自然语言问题的歧义。如果找不到匹配项将节省消除歧义的成本。
- 构建了一个表示用户查询意图的查询图,允许在问题理解阶段出现歧义。解决了在查询评估中找到匹配项的模糊性。
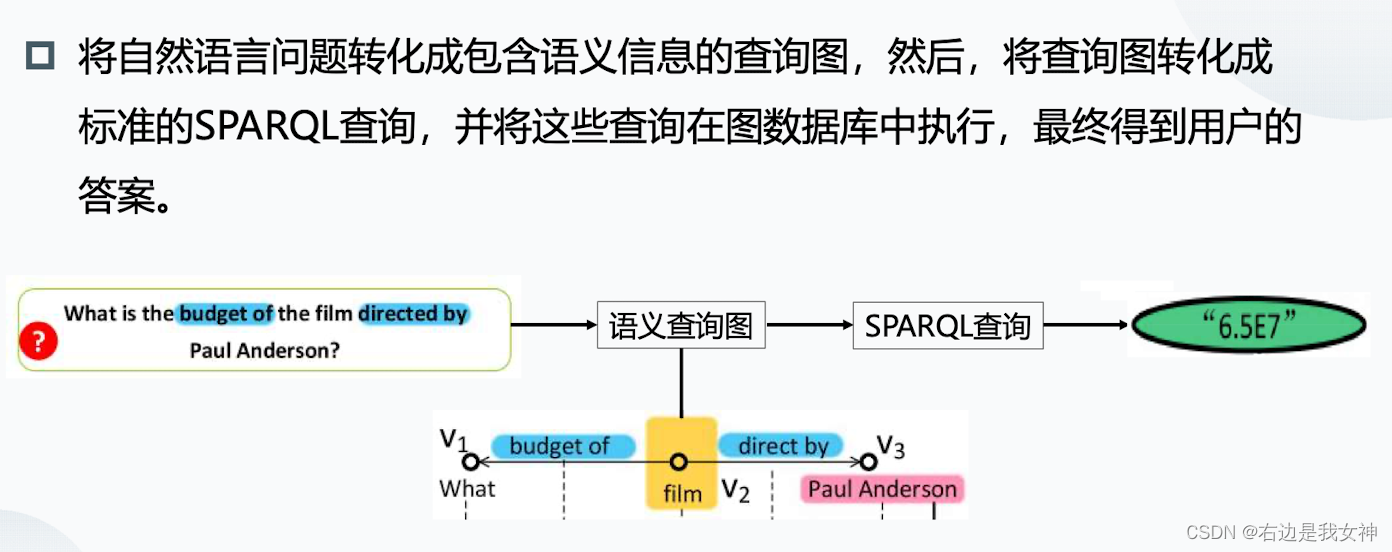
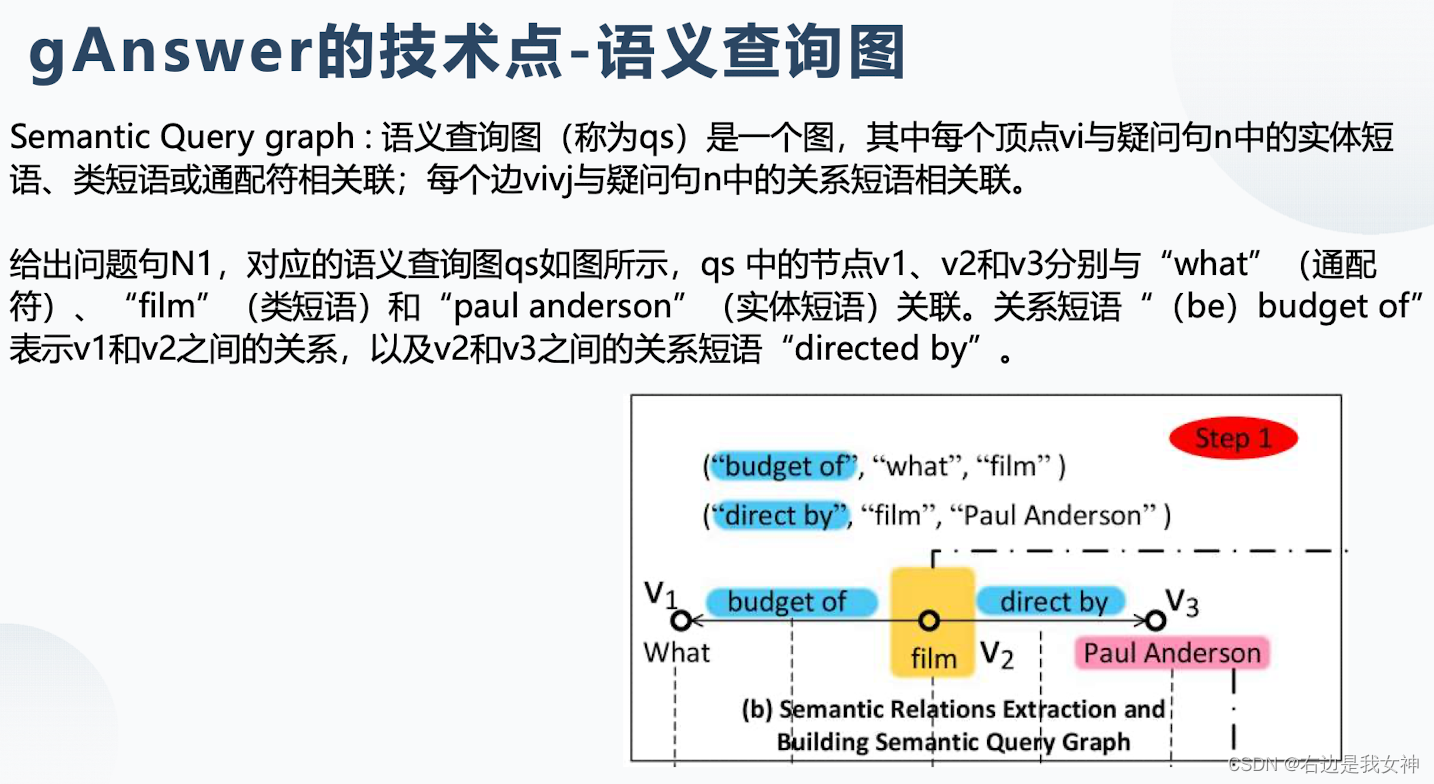
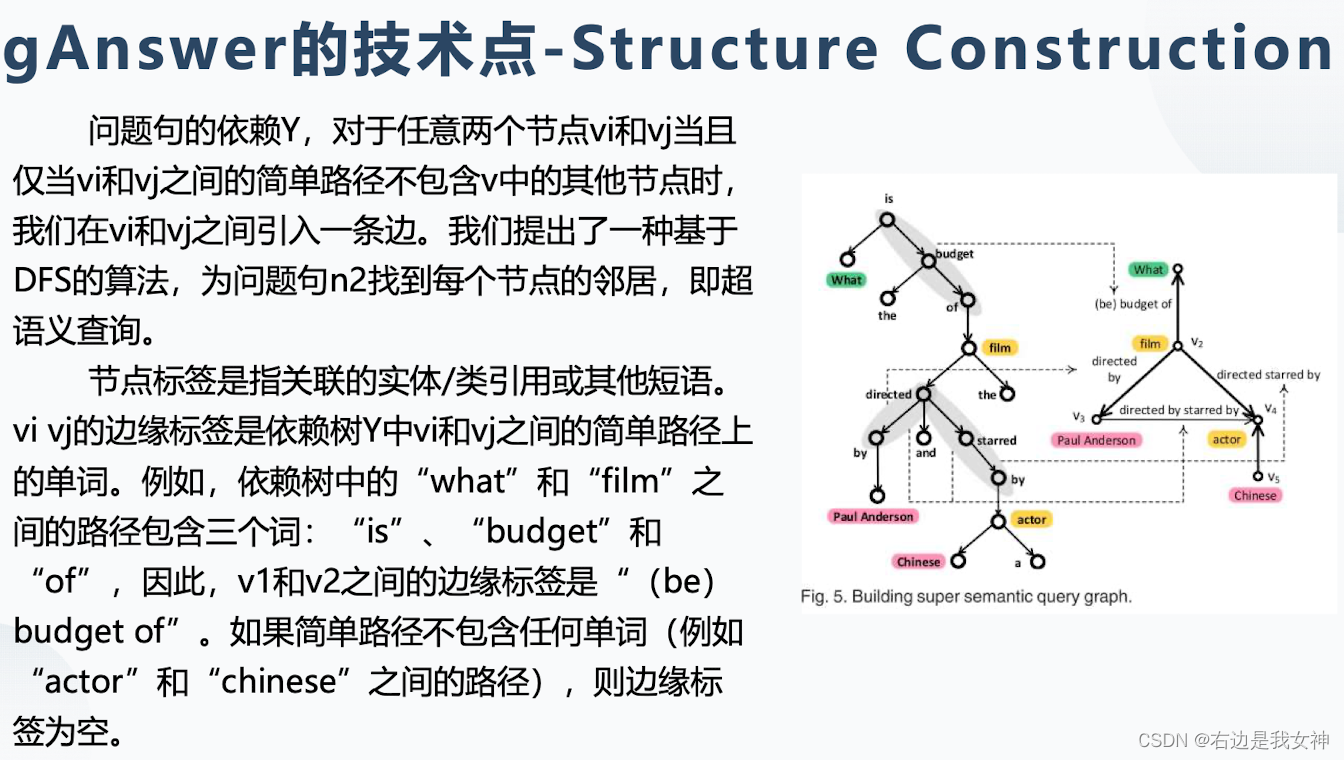
问句解析(问题-语义查询图):从问句中提取关系、实体。即建立依赖树,然后通过自己的方法从里面提取出关系和实体。
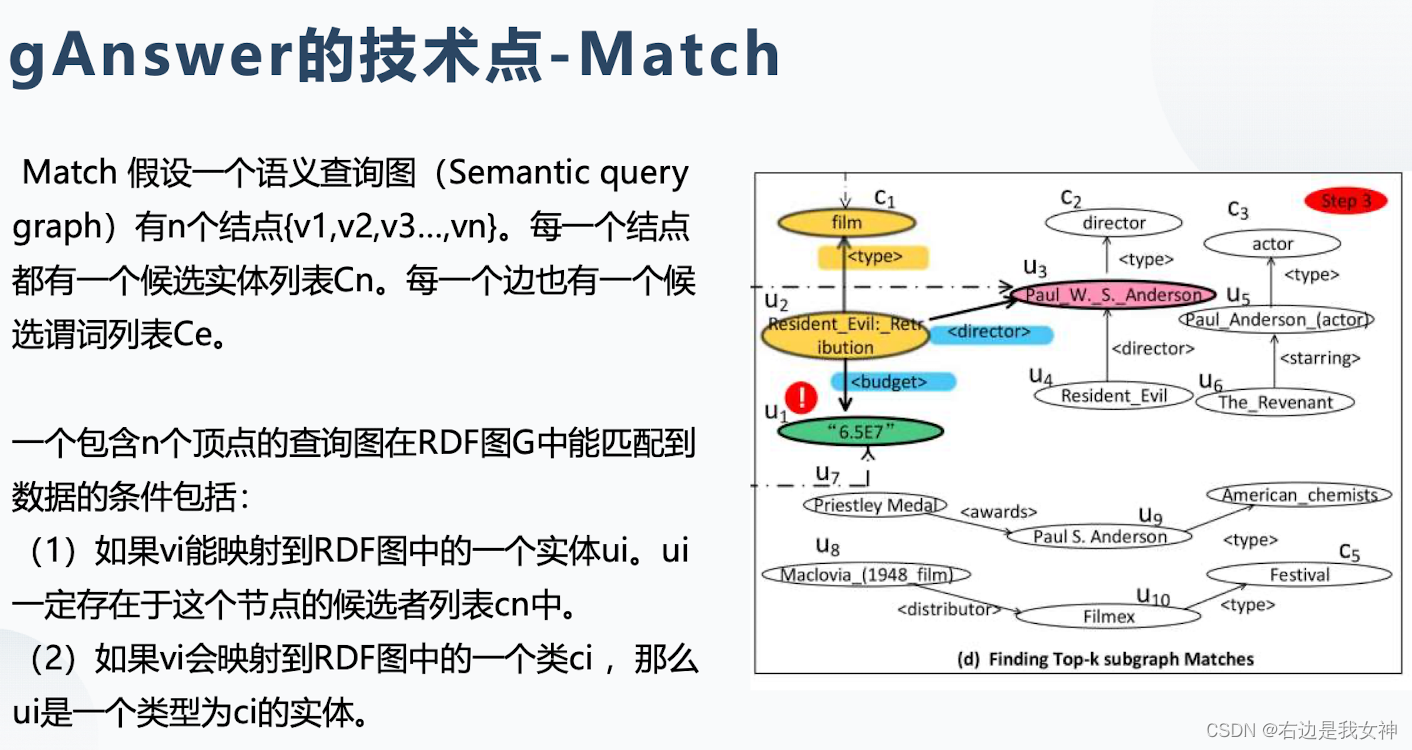
答案查询(语义查询图-查询):在查询图中每个结点和每个边都有候选实体和关系。首先得到每个结点和候选者之间的相似度,然后进行子图匹配。(语义消岐、查询构建)
系统框架
使用两个数据驱动框架将消岐和查询评估结合在一起:
- 关系优先框架,解决了查询评估中短语链接的歧义;
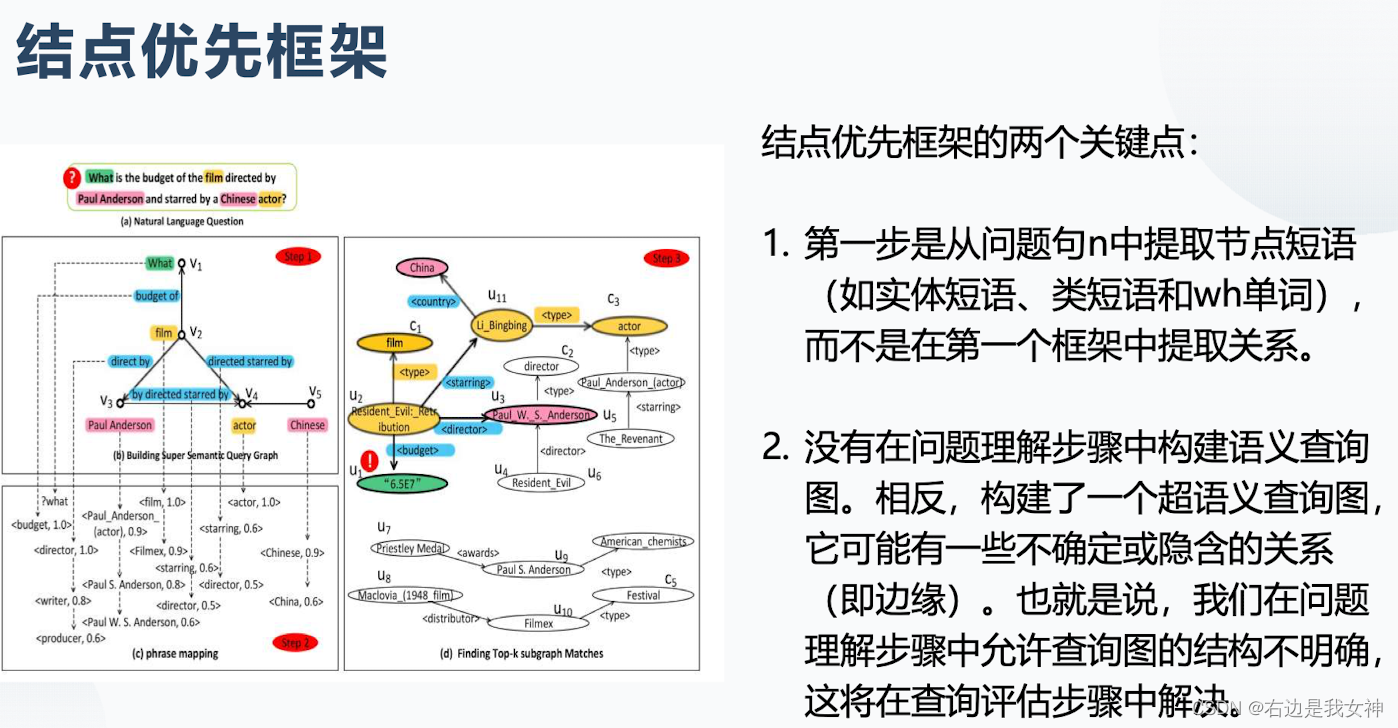
- 节点优先框架,短语链接和查询图形结构的模糊性都得到了解决。
构建方式:
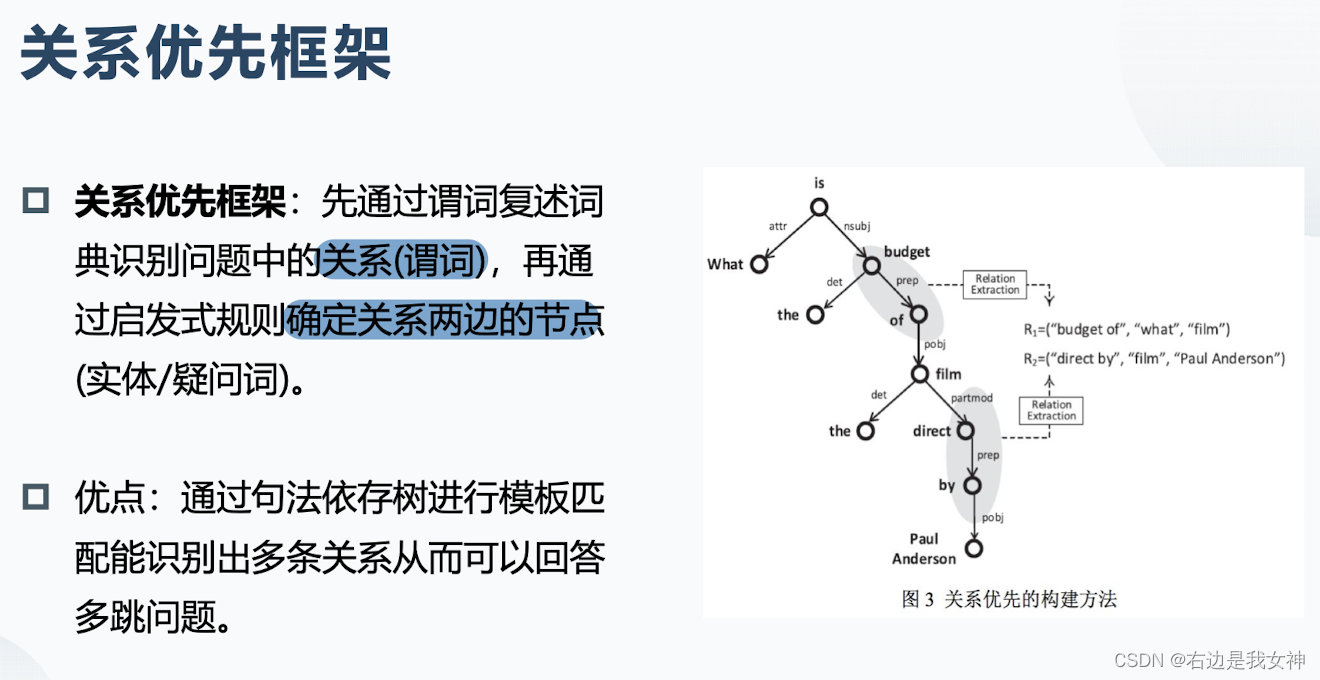
查询方式:
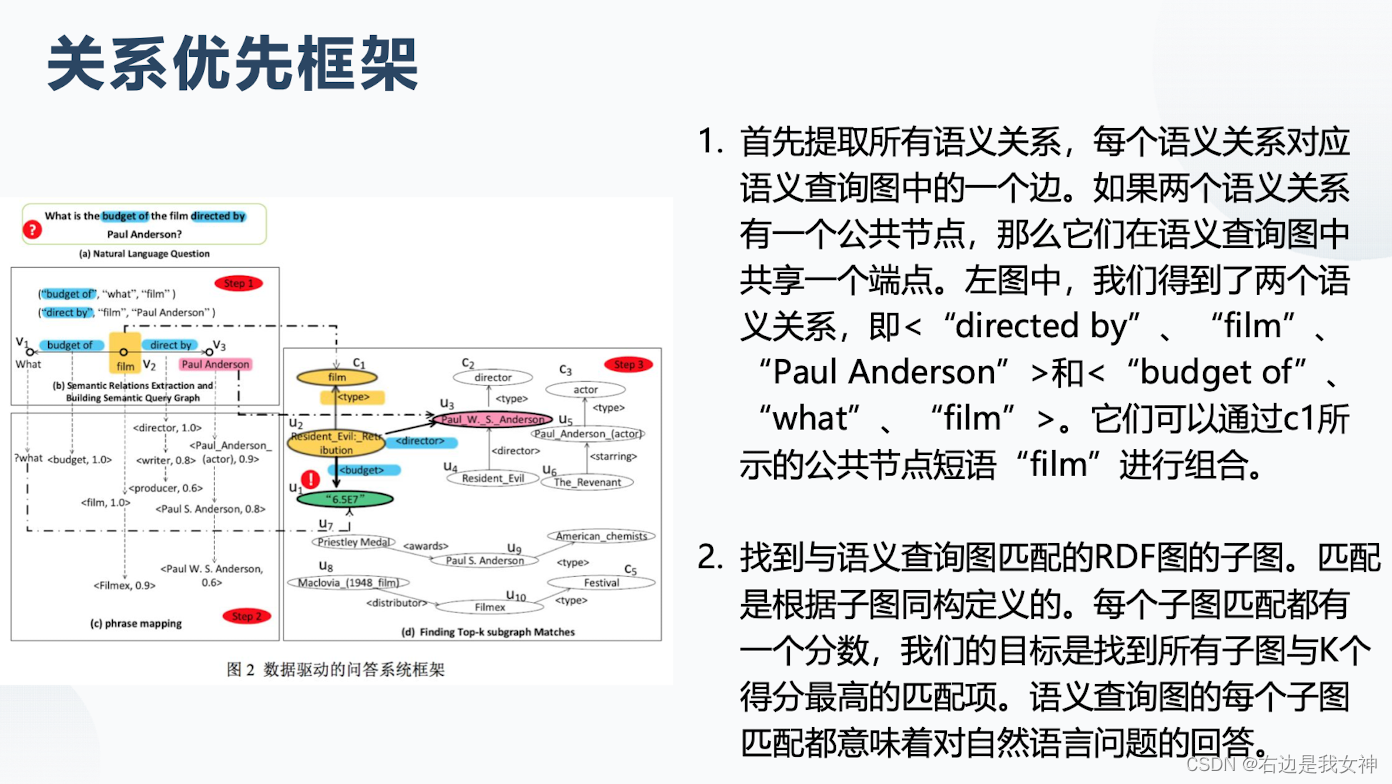

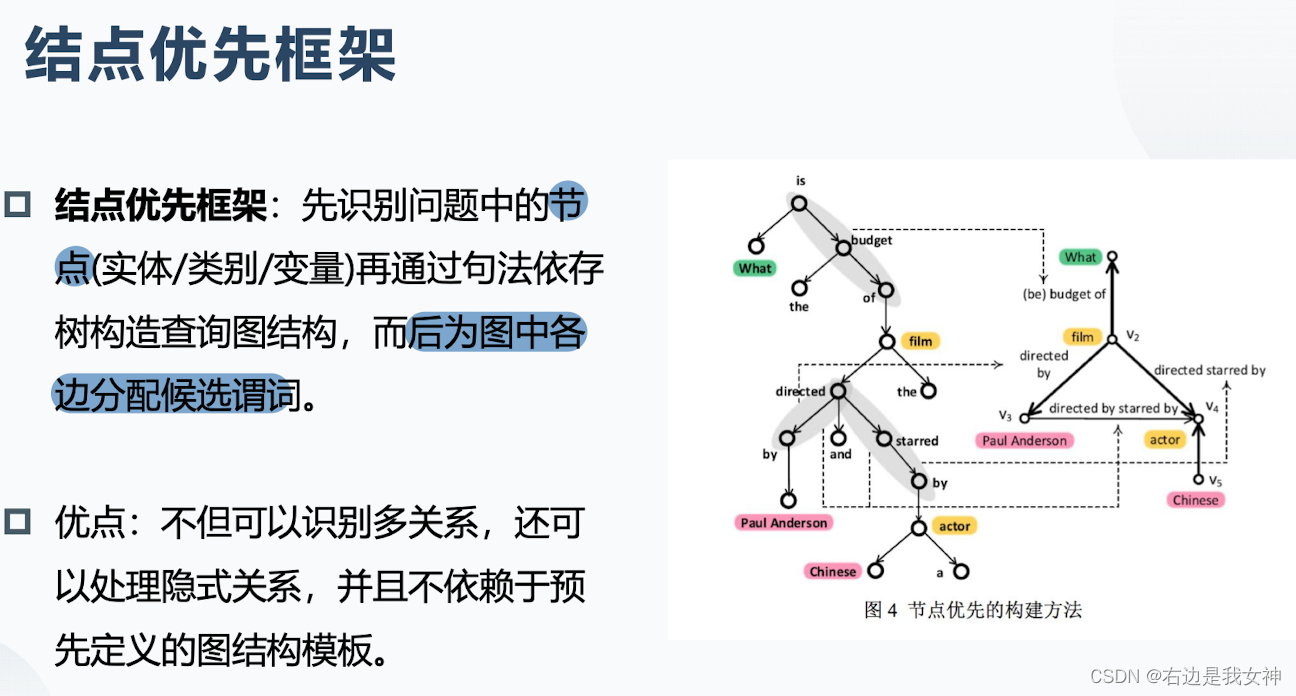
优缺点
| 优点 | 缺点 |
|---|---|
| 在问题理解阶段允许短语和结构的歧义,将消除歧义推到查询评估阶段 | 难以解决复杂问题 |
| 有效地解决了模糊问题 | - |
Q16:传统推理的三种形式
- 演绎推理;
- 归纳推理;
- 溯因推理。
演绎推理
从一般到特殊的推理方法,与归纳法相对。
其形式有:
- 三段论:以一个一般性的原则(大前提)以及一个附属于一般性的原则的特殊化称述(小前提),由此引申出一个符合一般性原则的特殊化陈述(结论)的过程。
- 假言推理:是以假言判断为前提的推理。假言推理分为充分条件假言推理和必要条件假言推理两种。这种推理与三段论有相似之处但却不是三段论。
前者的基本原则是:小前提肯定大前提的前件,结论就肯定大前提的后件;小前提否定大前提的后件,结论就否定大前提的前件。
后者的基本原则是:小前提肯定大前提的后件,结论就要肯定大前提的前件;小前提否定大前提的前件,结论就要否定大前提的后件。 - 选言推理、关系推理(不在此赘述)。

归纳推理

溯因推理

从结果出发,推测事情发生的原因的过程。
我们首先知道了假设,之后观察到了结果,此时推断出原因。
三者可表述为:
- 演绎推理:已知规则、前提,推测出结果;
- 归纳推理:已知前提、结果,推测出规则;
- 溯因推理:已知规则、结果,推测出前提(原因)。
必要性假言推理看着和溯因推理差不多,但是溯因推理得到的原因并不是确定的。
三段论看着和假言推理差不多,但是三段论给出的前提更加抽象。
Q17:基于规则的推理算法之归纳推理算法PRA和AMIE
知识图谱的推理任务
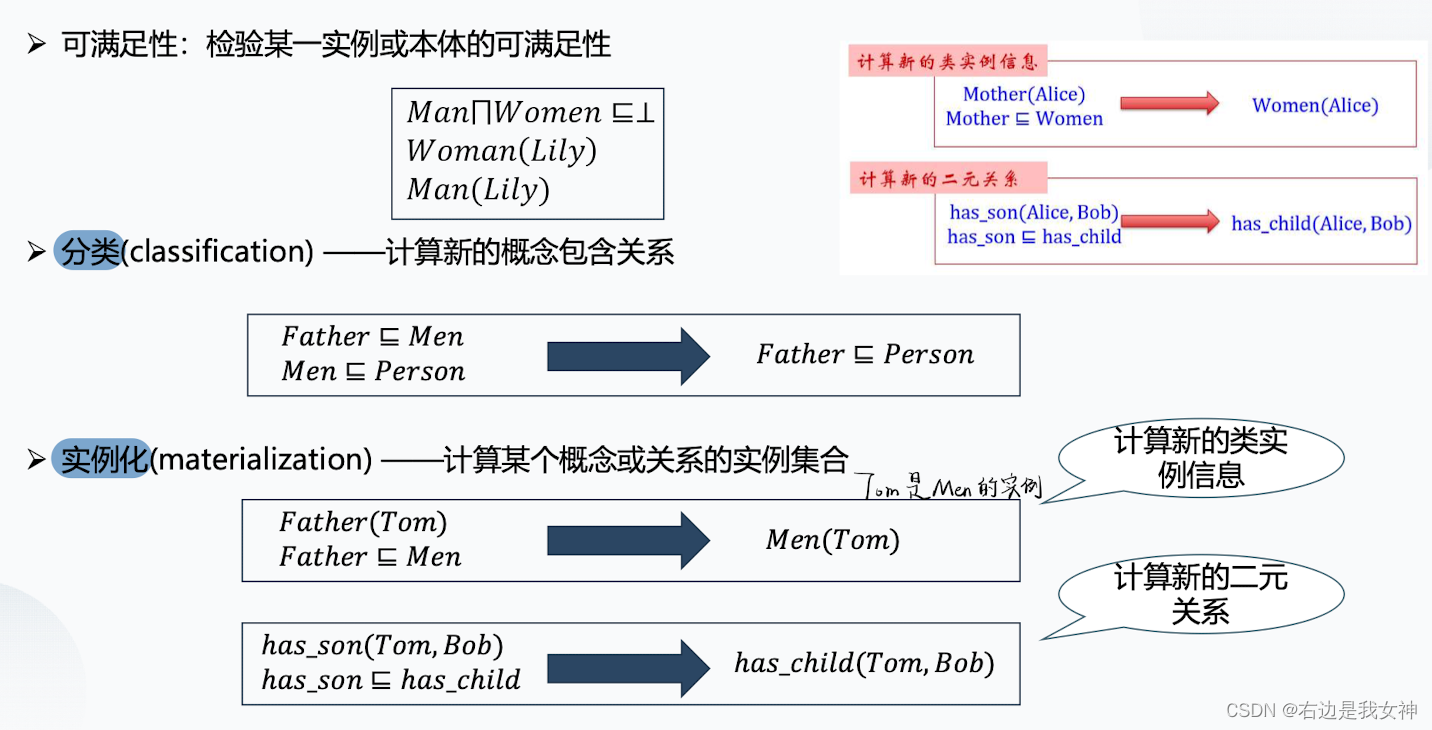
判断关系的正确性以及推断关系是知识推理的主要任务。
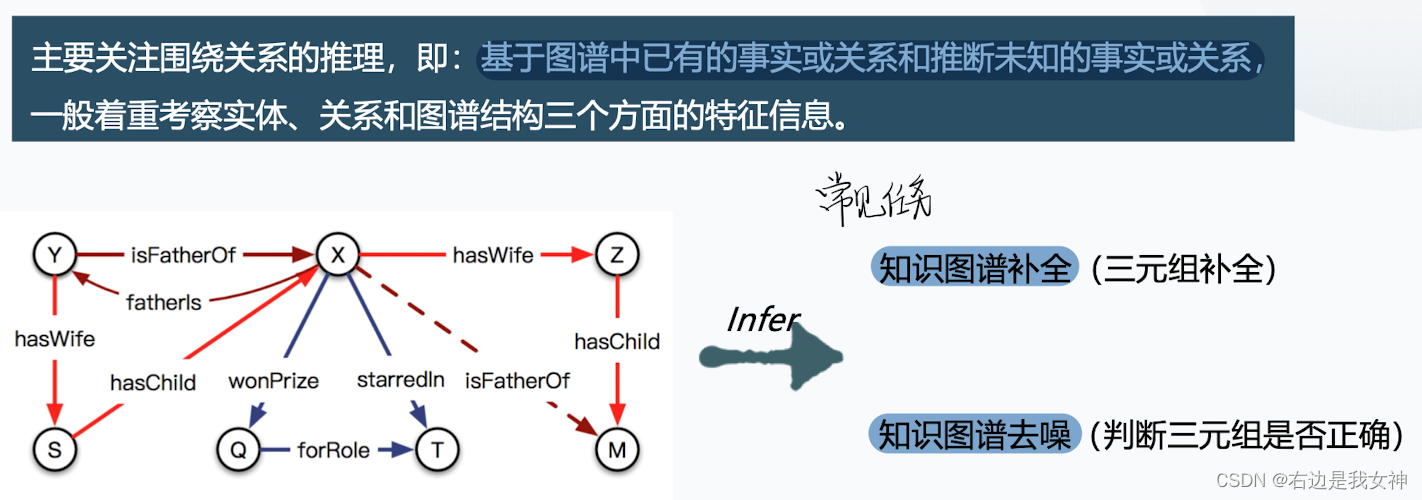
PRA和AMIE属于基于规则推理中的归纳推理方法。
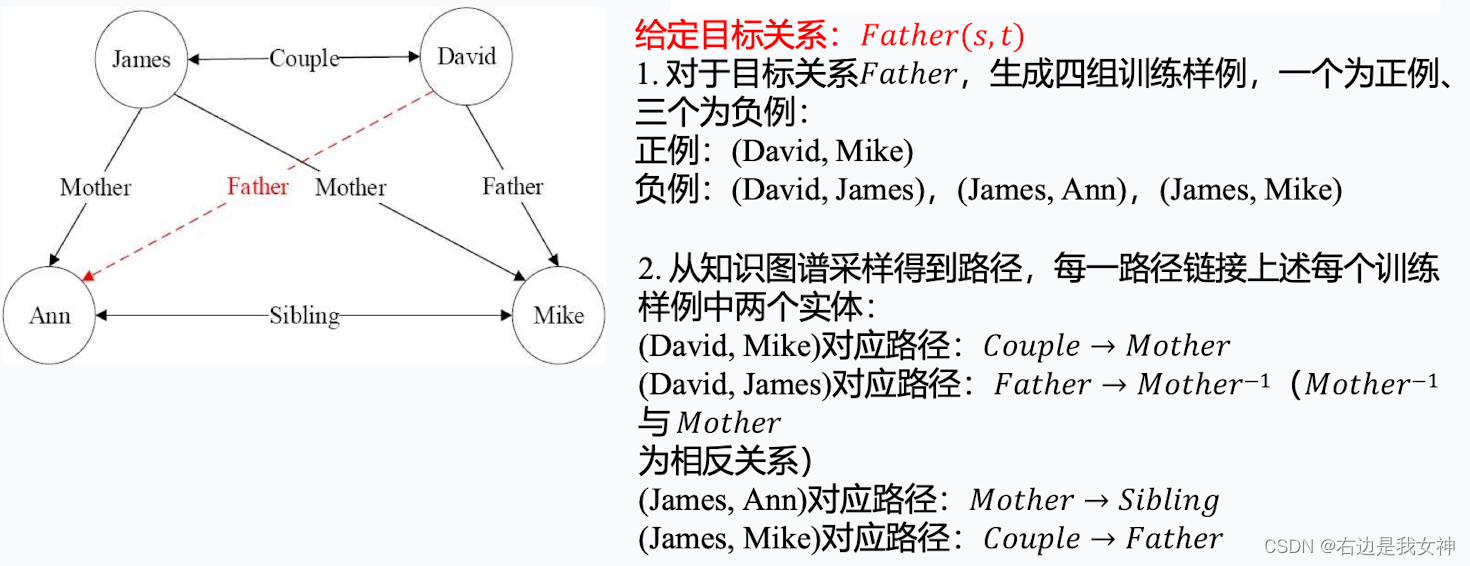
PRA:路径排序算法
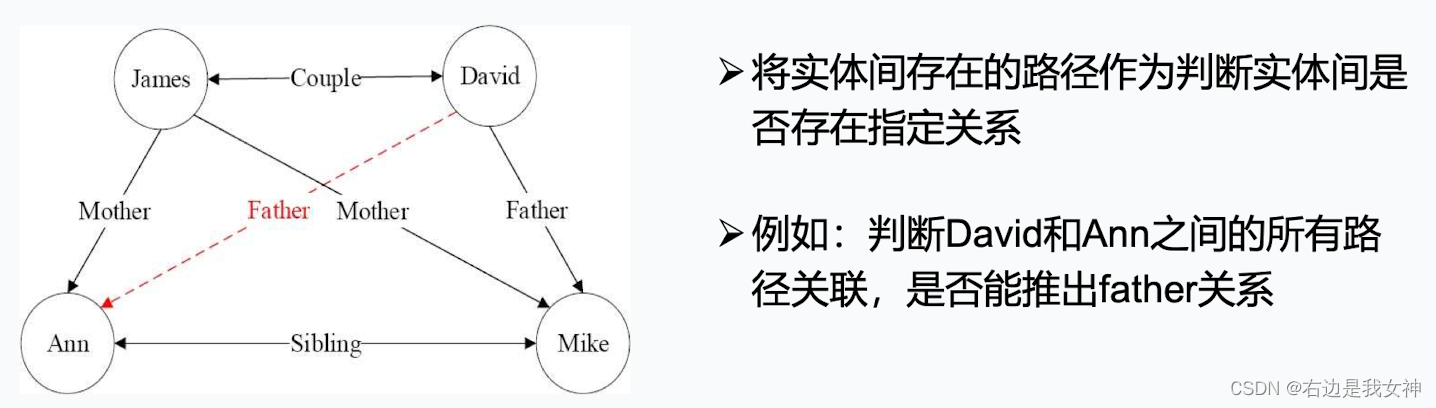
PRA是一种将关系路径作为特征的推理算法,经常用于知识图谱中的链接预测任务。其获取的关系路径实际上对应着一种霍恩子句,因此PRA计算的路径特征可以转换为逻辑规则。
其思想是通过发现连接两个实体的一组关系路径来预测实体间可能存在的某种关系。
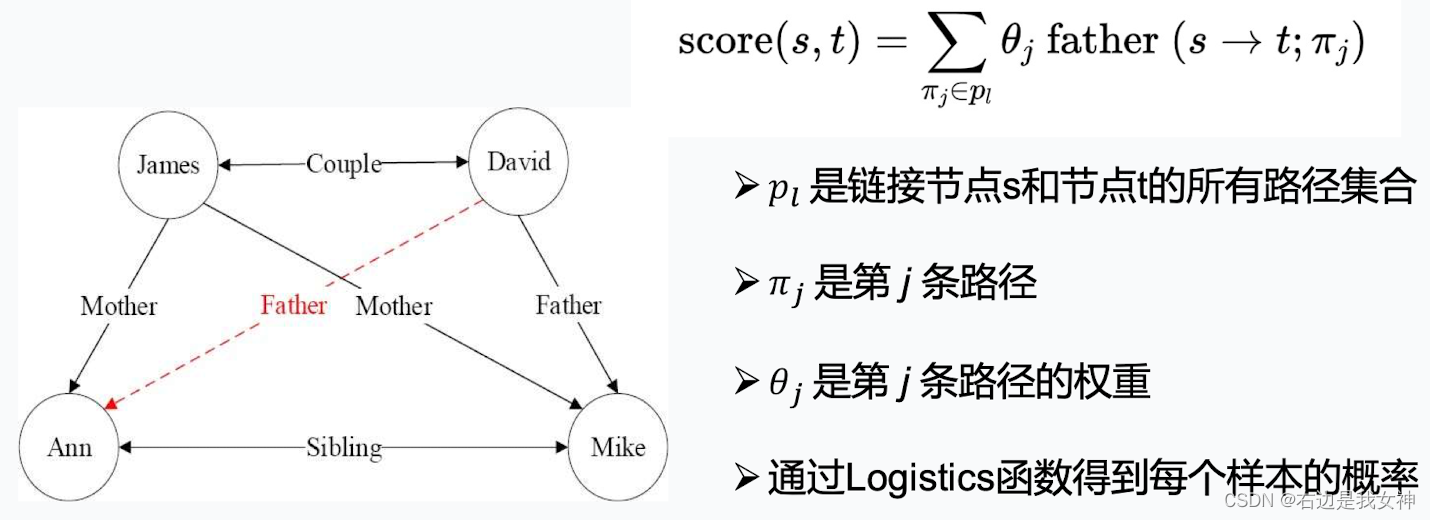
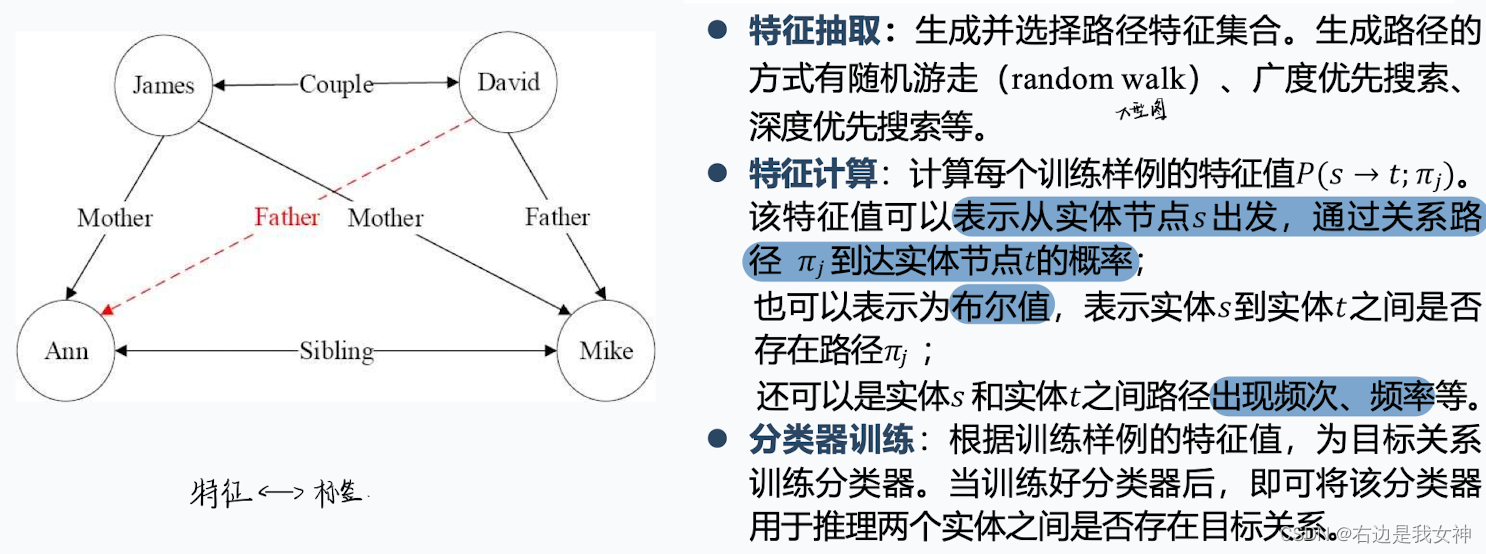
有点像感知机, ω \omega ω为每一个路径的权重组合的向量, x x x为路径组成的特征。
AMIE(基于不完备知识库的关联规则挖掘算法)

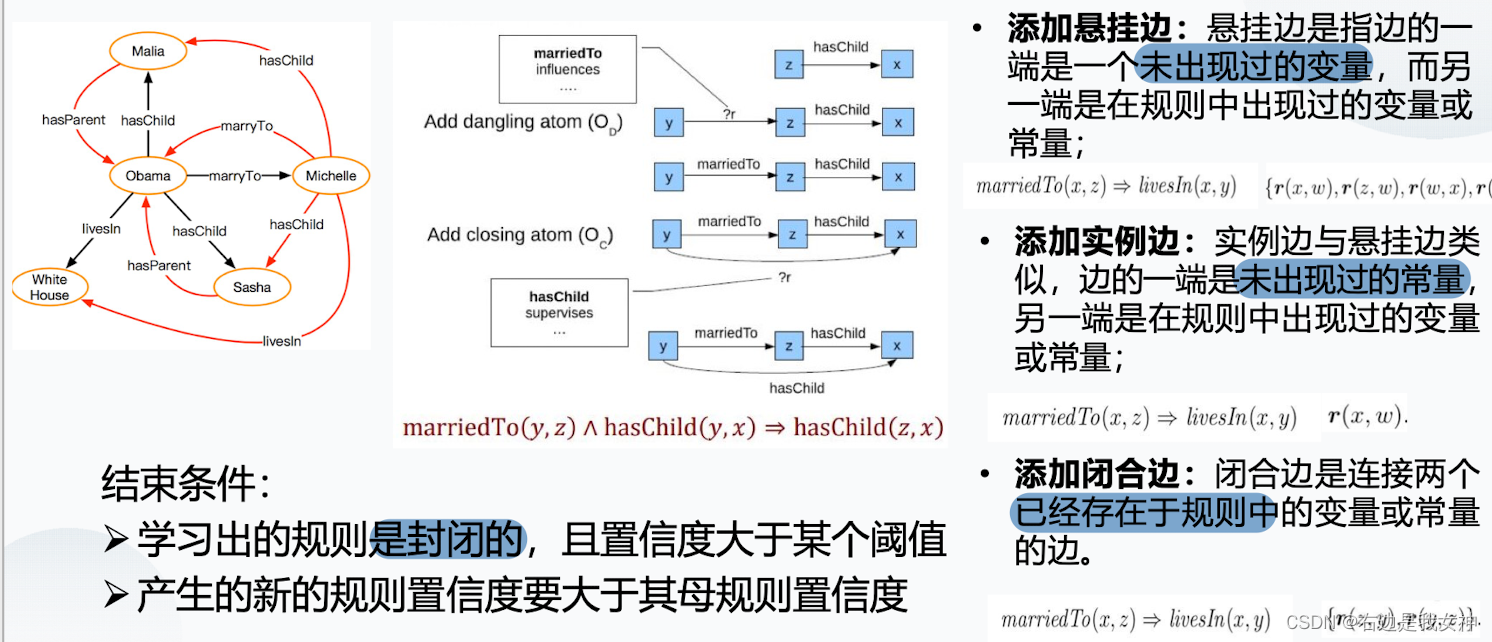
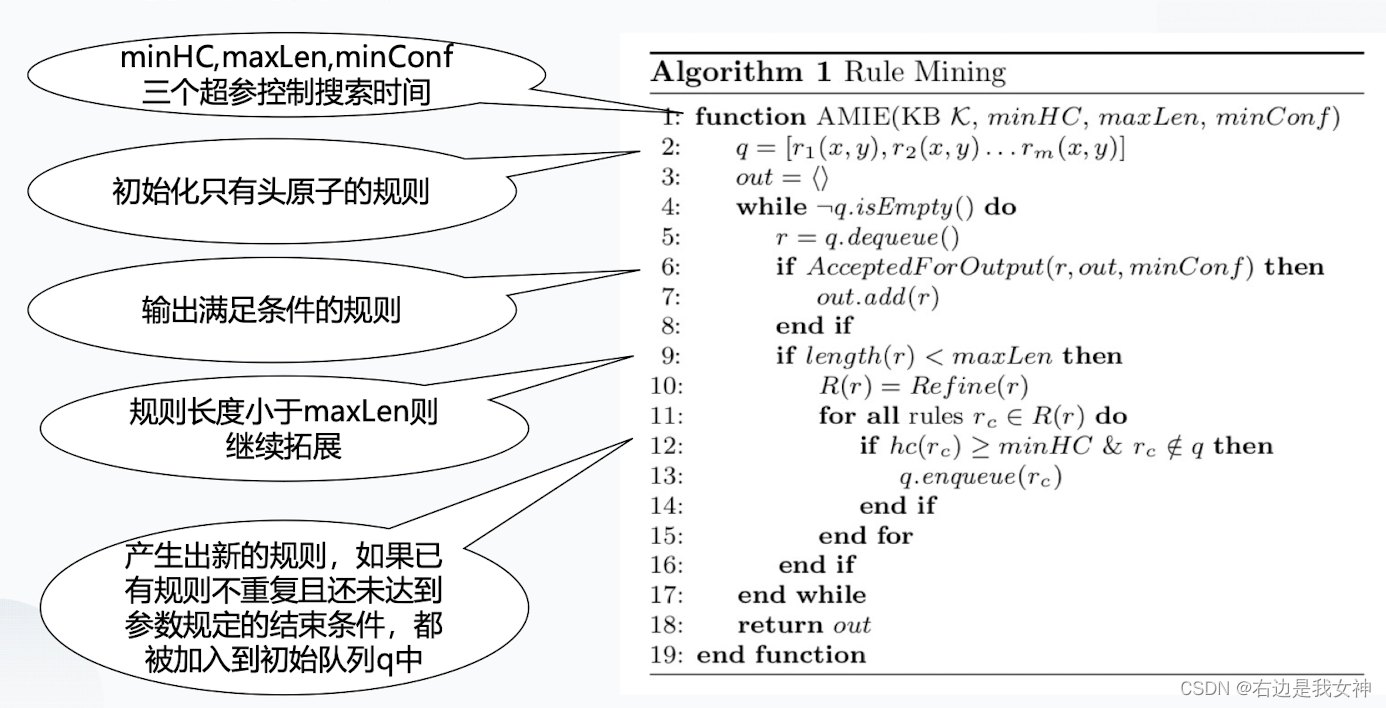
- q是一个规则库,首先我们对它进行初始化;
- 进入循环,从q中取出一个规则,如果这个规则没有封闭,就把这个规则添加进去;
- 然后将所有运算符对这个规则使用,产生的新规则添加到q中;
- 重复此过程,直到队列为空。
Q18:基于嵌入式表示的推理之距离模型及优缺点
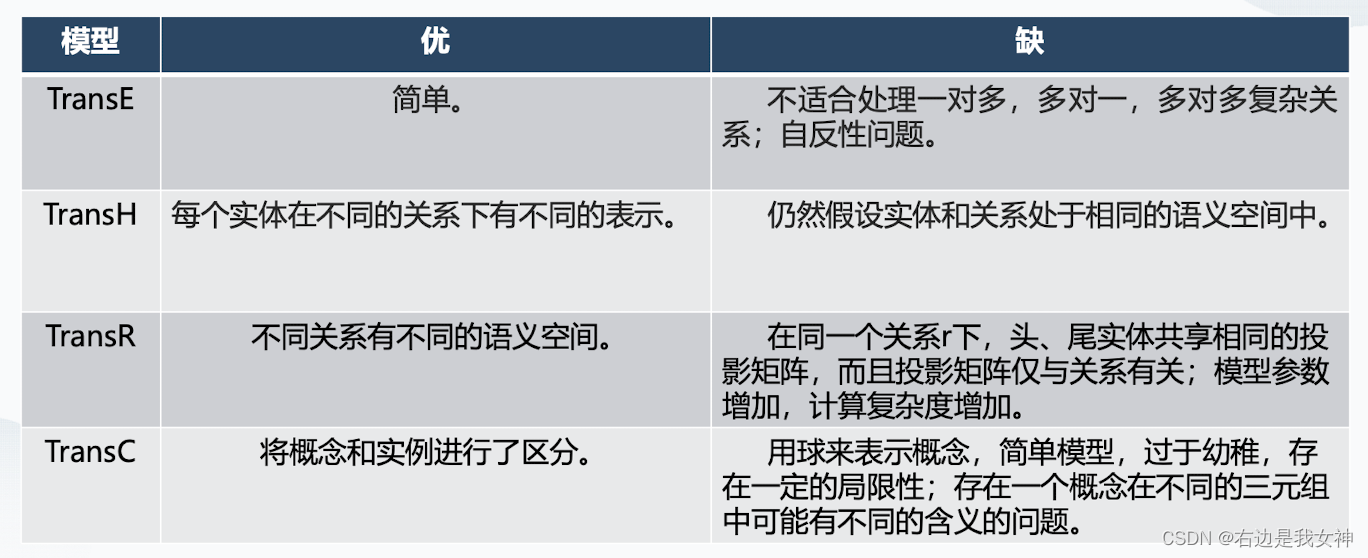
TransE
TransE模型的原理在先前已经提及,这里只在一次介绍其问题:
- 自反性问题:如果关系 r r r具有自反性,即 ( h , r , t ) , ( t , r , h ) ∈ G (h,r,t),(t,r,h)\in G (h,r,t),(t,r,h)∈G,那么根据TranE模型可以推测出 h = t , r = 0 h=t,r=0 h=t,r=0;
- 不适合处理一对多,多对一问题,这在之前已经提及。
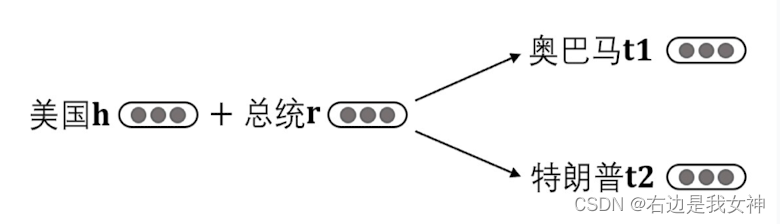
一个实体,根据一个关系对应多个实体,那么这些实体会近乎一致。
TranH
TranH主要解决的是1-to-Many、Many-to-1和Many-to-Many的问题。
比如说:谈论国籍时,莎士比亚和牛顿应该是接近的(人,英国,莎士比亚)(人,英国,牛顿);谈论职业时,前者应该和马克吐温接近(人,作家,莎士比亚)(人,作家,马克吐温)。如果还是用TranE模型,牛顿和马克吐温就会凑一块,这是不合理的。
TransH通过为具有不同关系的相同实体赋予不同的向量表示来解决这个问题。
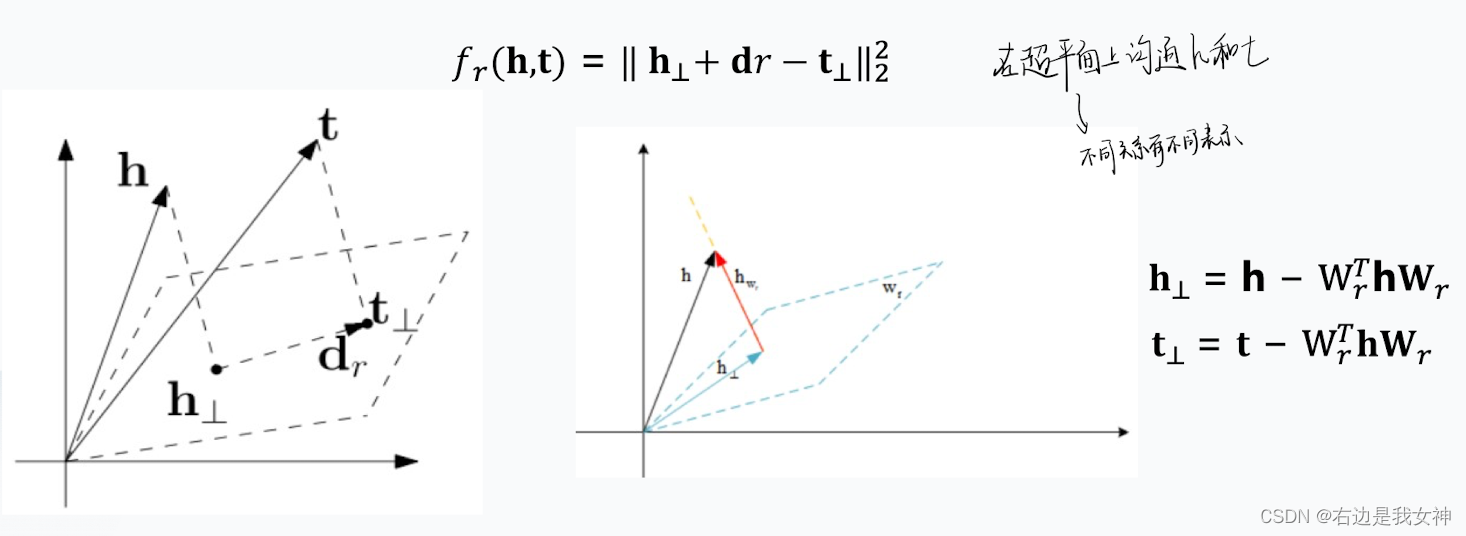
TransH为每个关系赋予一个超平面
w
r
w_r
wr,然后判断超平面上的相似性。
d
r
d_r
dr就是正常的关系。
另外,损失函数和训练方式同TransE。
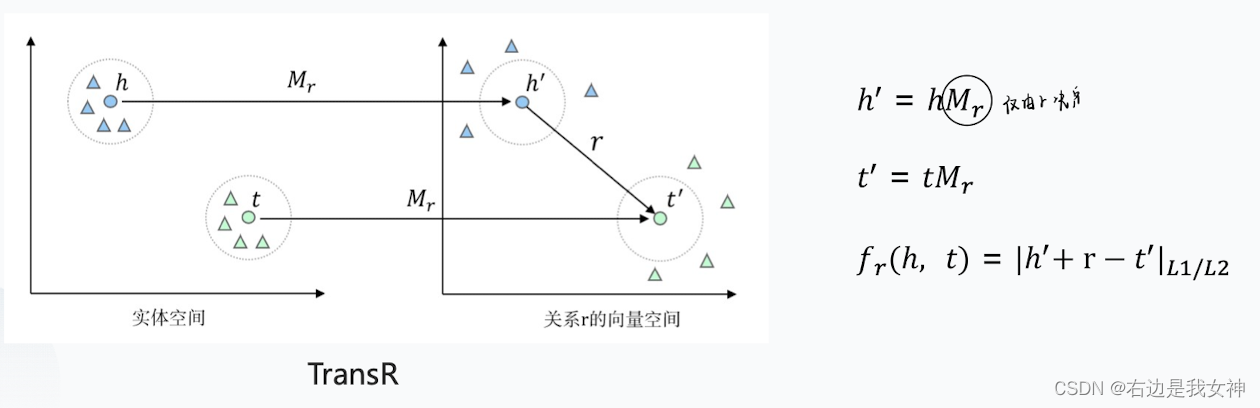
TransR
TransH通过使用超平面的方式为具有多个关系的实体赋予不同的向量表示,但是实体和关系仍然在相同的语义空间,这限制了建模实体和关系的能力。
TransR认为不同的关系应该有不同的语义空间,因此为每个关系构造相应的向量空间。对每个三元组,首先应该将实体投影到对应的关系空间中,然后再建立从头实体到尾实体的翻译关系。
TransC
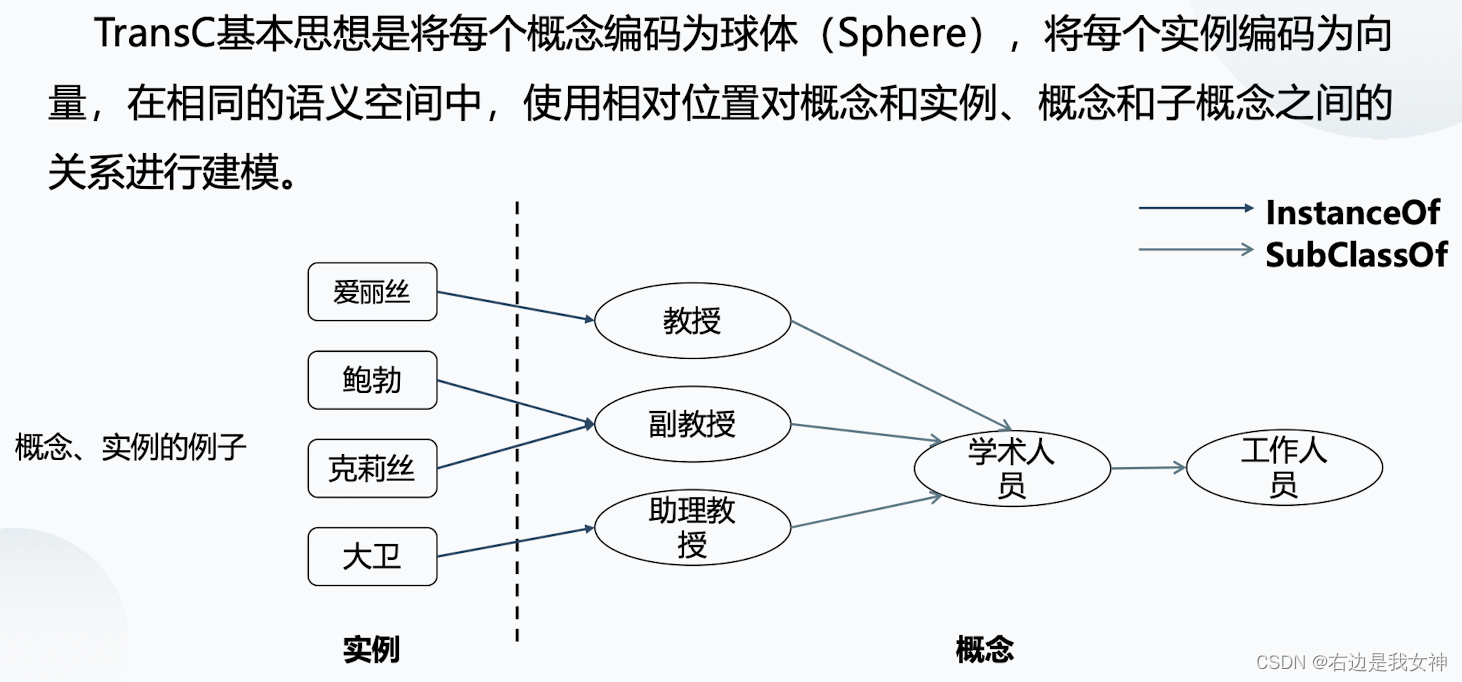
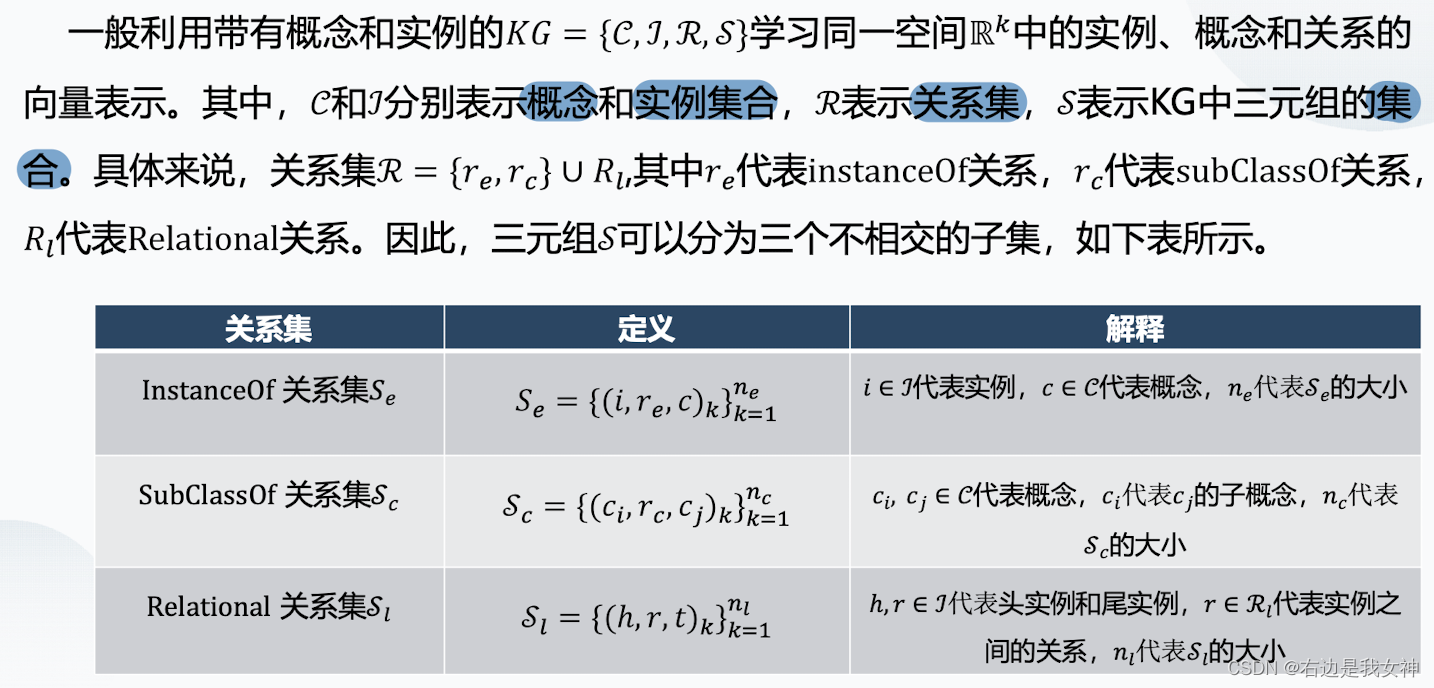
实例和概念之间的关系、概念和子概念之间的关系、实例和实例之间的关系。
相比于传统的Trans E、H、R,TransC将实体区分为了概念和实例,并进一步细化了这些关系。
概念抽象为了一个圆。根据实体与概念、概念与概念间的不同关系对应着不同的得分函数。

优缺点
















 1813
1813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











