






首先我们先读取数据。
df = pd.read_csv('../B005放电数据集.csv')
数据显示如下:
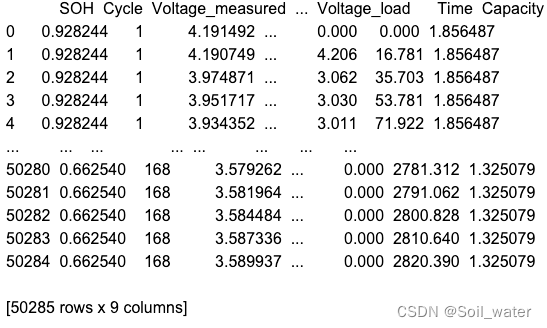
这是一个50285*9大小的数据矩阵,我们想要的是以一个Cycle所对应的所有的除去SOH外的所有特征进行行压缩变成一个值。例如当Cycle为1时,对应的Voltage_measured有一百多个,而我想要一个,以便于达到属性之间的一一对应。(在这里我想要避一个雷。虽然我最终实现了特征压缩,但是我把一个50285*9大小的数据矩阵压缩到了168*9大小,但是结果表明,压缩可能过于激烈了,把一些数据间的分布规律给压缩掉了,后面直接使用50285*9大小矩阵进行学习,结果大幅度优化),在这里我只介绍我理解的PCA的用法。
df = df.iloc[:, 1:-1] # 去掉数据集的第一列和最后一列
# 将cycle列数值类型转化
df['Cycle'] = pd.to_numeric(df['Cycle'], errors='coerce').astype('Int64')在这里出去第1、2、9列外都不是一一对应的,因此我们需要使用PCA进行行压缩。因此要剔除第一列以及第九列。我们使用第二列Cycle进行分组,因为PCA方法时特征提取的方法,适合列压缩,如果我们要用行压缩并一一对应,必须要将原来的数据按分组的形式转置,把每一个数据都看成一个特征,在使用PCA即可。因此我们必须使用Cycle分组进行转置,在使用PCA。
这边为了使转置后按Cycle顺序排列,必须把Cycle数值化。
df['Cycle'] = pd.to_numeric(df['Cycle'], errors='coerce').astype('Int64')
这里向大家展示分组并转置的代码和结果:
for _, group in df.groupby('Cycle',): #这里gropby()是分组方法,参数为列名
group_t = group.set_index('Cycle').T # .T为矩阵转置
print(group_t) # ‘——’为占位符可以为任意字符,因为后续用不到结果如下:

之后对每一个分组使用PCA即可。
代码如下:
pca = PCA(n_components=1)
pca.fit(group_t)
group_pca = pca.transform(group_t).flatten()
results.append(pd.Series(group_pca))相关解释如下:
pca(n_components=1):创建一个pca对象,其中n_components参数设置为值1,这表示将输入数据减少到一维。pca.fit(group_t):把group_t中的数据用于训练 pca 模型,训练出数据中的主成分。pca.transform(group_t).flatten():transform函数对数据应用由fit得到的转换,将group_t(一般是二维数组)投影到主成分轴上,使用flatten把所有元素放在同一个维度上results.append(pd.series(group_pca)):将得到的一维数据作为 series 对象附加到results列表尾部。
其中group_pca的输出如下:

现在我们只需要将其输出到CSV文件就大功告成了。
results = pd.DataFrame(results)
results.to_csv('./B0005_特征数据集.csv')DataFram()将python中的数据转换成 pandas 数据框的格式,使之易于后续直接转换为CSV文件。















 349
349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









