






P1042 [NOIP2003 普及组] 乒乓球
题目背景
国际乒联现在主席沙拉拉自从上任以来就立志于推行一系列改革,以推动乒乓球运动在全球的普及。其中 11 分制改革引起了很大的争议,有一部分球员因为无法适应新规则只能选择退役。华华就是其中一位,他退役之后走上了乒乓球研究工作,意图弄明白 11 分制和 21 分制对选手的不同影响。在开展他的研究之前,他首先需要对他多年比赛的统计数据进行一些分析,所以需要你的帮忙。
题目描述
华华通过以下方式进行分析,首先将比赛每个球的胜负列成一张表,然后分别计算在 11 分制和 21 分制下,双方的比赛结果(截至记录末尾)。
比如现在有这么一份记录,(其中 W 表示华华获得一分,L 表示华华对手获得一分):
WWWWWWWWWWWWWWWWWWWWWWLW
在 11 分制下,此时比赛的结果是华华第一局 11 比 0 获胜,第二局 11 比 0 获胜,正在进行第三局,当前比分 1 比 1。而在 21 分制下,此时比赛结果是华华第一局 21 比 0 获胜,正在进行第二局,比分 2 比 1。如果一局比赛刚开始,则此时比分为 0 比 0。直到分差大于或者等于 2,才一局结束。
你的程序就是要对于一系列比赛信息的输入(WL 形式),输出正确的结果。
输入格式
每个输入文件包含若干行字符串,字符串有大写的 W 、L 和 E 组成。其中 E 表示比赛信息结束,程序应该忽略 E 之后的所有内容。
输出格式
输出由两部分组成,每部分有若干行,每一行对应一局比赛的比分(按比赛信息输入顺序)。其中第一部分是 11 分制下的结果,第二部分是 21 分制下的结果,两部分之间由一个空行分隔。
输入输出样例
输入 #1复制
WWWWWWWWWWWWWWWWWWWW WWLWE
输出 #1复制
11:0 11:0 1:1 21:0 2:1
说明/提示
每行至多 25 个字母,最多有 2500 行。
(注:事实上有一个测试点有 2501 行数据。)
【题目来源】
NOIP 2003 普及组第一题
---------------------------------------------------------------------------------------------------------------------------------
这道题由于我 缺少比赛常识+审题错误+审题缺漏+逻辑混乱 导致直接掉坑。
我考虑过于简单,我想的是,每11个或者21个字母依次判断输赢直到读完所有字母。但是忽略了n分制的比赛,比赛结果得出不仅需要其中一方分数大于n,并且比赛双方的分数差也要大于2。
其次,要考虑代码的逻辑主次。首先判断该字母是否代表输赢;是则me或者cmpt进行++,如果不代表输赢则考虑该字母是否代表比赛结束;如果是,则程序应该忽略该字母之后的所有内容(及时break)。
WA代码↓
#include<bits/stdc++.h>
using namespace std;
int main()
{
char a[62510];
int i,j,len,k;
int me=0,cmpt=0;
int cnt=0;
for(i=0;i<62500;i++)
{
scanf("%c",&a[i]);
if(a[i]=='\n')
i--;
else if(a[i]=='E')
{
j=i;
break;
}
}
for(i=0;i<j;i++)
{
if(a[i]=='W'&&cnt<11)
me++,cnt++;
else if(a[i]=='L'&&cnt<11)
cmpt++,cnt++;
if(me-cmpt>=2||cmpt-me>=2)
if(a[i+1]=='E'||cnt==11)
{
printf("%d:%d\n",me,cmpt);
me=0,cmpt=0,cnt=0;
}
}
printf("\n");
for(i=0;i<j;i++)
{
if(a[i]=='W'&&cnt<21)
me++,cnt++;
else if(a[i]=='L'&&cnt<21)
cmpt++,cnt++;
if(me-cmpt>=2||cmpt-me>=2)
if(a[i+1]=='E'||cnt==21)
{
printf("%d:%d\n",me,cmpt);
me=0,cmpt=0,cnt=0;
}
}
return 0;
}AC代码↓
#include<bits/stdc++.h>
using namespace std;
char a[62510];
int main()
{
int me=0,cmpt=0;
long int i,j;
for(i=0;i<62510;i++)
{
scanf("%c",&a[i]);
if(a[i]=='\n')
i--;
else if(a[i]=='E')
{
j=i;
break;
}
}
for(i=0;i<=j;i++)
{
if(a[i]=='W')
me++;
else if(a[i]=='L')
cmpt++;
else if(a[i]=='E')
{
printf("%d:%d\n",me,cmpt);
me=0,cmpt=0;
break;//重点!!! "程序应该忽略E之后的所有内容。"
}
if(me-cmpt>=2||cmpt-me>=2/*||a[i]=='E'*/)
if(me>=11||cmpt>=11)
{
printf("%d:%d\n",me,cmpt);
me=0,cmpt=0;
}
}
printf("\n");
for(i=0;i<=j;i++)//复制粘贴上面
{
if(a[i]=='W')
me++;
else if(a[i]=='L')
cmpt++;
else if(a[i]=='E')
{
printf("%d:%d\n",me,cmpt);
me=0,cmpt=0;
break;//重点!!! "程序应该忽略E之后的所有内容。"
}
if(me-cmpt>=2||cmpt-me>=2/*||a[i]=='E'*/)
if(me>=21||cmpt>=21)
{
printf("%d:%d\n",me,cmpt);
me=0,cmpt=0;
}
}
return 0;
}P2670 [NOIP2015 普及组] 扫雷游戏
题目背景
NOIP2015 普及组 T2
题目描述
扫雷游戏是一款十分经典的单机小游戏。在n行m列的雷区中有一些格子含有地雷(称之为地雷格),其他格子不含地雷(称之为非地雷格)。玩家翻开一个非地雷格时,该格将会出现一个数字——提示周围格子中有多少个是地雷格。游戏的目标是在不翻出任何地雷格的条件下,找出所有的非地雷格。
现在给出n行m列的雷区中的地雷分布,要求计算出每个非地雷格周围的地雷格数。
注:一个格子的周围格子包括其上、下、左、右、左上、右上、左下、右下八个方向上与之直接相邻的格子。
输入格式
第一行是用一个空格隔开的两个整数n和m,分别表示雷区的行数和列数。
接下来n行,每行m个字符,描述了雷区中的地雷分布情况。字符’*’表示相应格子是地雷格,字符’?’表示相应格子是非地雷格。相邻字符之间无分隔符。
输出格式
输出文件包含n行,每行m个字符,描述整个雷区。用’*’表示地雷格,用周围的地雷个数表示非地雷格。相邻字符之间无分隔符。
输入输出样例
输入 #1复制
3 3 *?? ??? ?*?
输出 #1复制
*10 221 1*1
输入 #2复制
2 3 ?*? *??
输出 #2复制
2*1 *21
说明/提示
对于 100%的数据, 1≤n≤100, 1≤m≤100.
---------------------------------------------------------------------------------------------------------------------------------
这道题数据不大,我的做法是直接遍历。一共两个思路:根据非地雷格“找”周围地雷格;根据地雷格“找”非地雷格。
但是还是掉坑了。掉坑的原因有三点,第一选择了前者思路(计算量大),第二是考虑过多,第三是细节问题(当时就卡测试点6过不了)。
字符串处理问题其实转化为数字会更加简洁直观一些(见AC代码2,思路是后者思路),这一点我应该注意和学习。
我当时想先读入n与m,在创建数组a[n][m]。我不知道是不是这样读入导致数组空间拥挤啥的(大佬轻点骂),我搞懂了再回来填坑。当时我写成a[n+1][m+1]就通过了。
AC代码1↓
#include<bits/stdc++.h>
using namespace std;
int main()
{
int n,m,i,j;
cin>>n>>m;
getchar();
char a[n+1][m+1];//奇怪的细节,n和m得加1,不然测试点6通不过(测试点6?)
memset(a,0,sizeof(a));
/*char a[101][101];
cin>>n>>m;
memset(a,0,sizeof(a));*/
for(i=0;i<n;i++)
{
for(j=0;j<m;j++)
{
scanf("%c",&a[i][j]);
}
getchar();
}
for(i=0;i<n;i++)
{
for(j=0;j<m;j++)
{
int cnt=0;
if(a[i][j]=='*')
{
printf("*");
}
else if(a[i][j]=='?')
{
if(a[i-1][j]=='*')
cnt++;
if(a[i-1][j+1]=='*')
cnt++;
if(a[i][j+1]=='*')
cnt++;
if(a[i+1][j+1]=='*')
cnt++;
if(a[i+1][j]=='*')
cnt++;
if(a[i+1][j-1]=='*')
cnt++;
if(a[i][j-1]=='*')
cnt++;
if(a[i-1][j-1]=='*')
cnt++;
printf("%d",cnt);
}
}
cout<<endl;
}
return 0;
}
AC代码2↓
#include<bits/stdc++.h>
using namespace std;
int main()
{
int a[105][105],n,m;
char b;
memset(a,0,sizeof(a));
cin>>n>>m;
int i,j;
for(i=1;i<=n;i++)
{
for(j=1;j<=m;j++)
{
cin>>b;
if(b=='*')
a[i][j]=1;
else
a[i][j]=0;
}
}
for(i=1;i<=n;i++)
{
for(j=1;j<=m;j++)
{
if(a[i][j]==1)
{
cout<<'*';
}
else
{
cout<<a[i-1][j]+a[i-1][j+1]+a[i][j+1]+a[i+1][j+1]+a[i+1][j]+a[i+1][j-1]+a[i][j-1]+a[i-1][j-1];
}
}
cout<<endl;
}
return 0;
}P1563 [NOIP2016 提高组] 玩具谜题
题目背景
NOIP2016 提高组 D1T1
题目描述
小南有一套可爱的玩具小人, 它们各有不同的职业。
有一天, 这些玩具小人把小南的眼镜藏了起来。 小南发现玩具小人们围成了一个圈,它们有的面朝圈内,有的面朝圈外。如下图:
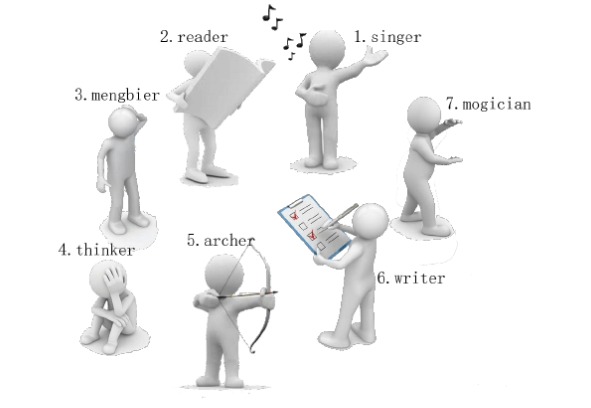
这时singer告诉小南一个谜題: “眼镜藏在我左数第3个玩具小人的右数第1个玩具小人的左数第2个玩具小人那里。 ”
小南发现, 这个谜题中玩具小人的朝向非常关键, 因为朝内和朝外的玩具小人的左右方向是相反的: 面朝圈内的玩具小人, 它的左边是顺时针方向, 右边是逆时针方向; 而面向圈外的玩具小人, 它的左边是逆时针方向, 右边是顺时针方向。
小南一边艰难地辨认着玩具小人, 一边数着:
singer朝内, 左数第33个是archerarcher。
archer朝外,右数第11个是thinkerthinker。
thinker朝外, 左数第22个是writewriter。
所以眼镜藏在writer这里!
虽然成功找回了眼镜, 但小南并没有放心。 如果下次有更多的玩具小人藏他的眼镜, 或是谜題的长度更长, 他可能就无法找到眼镜了 。 所以小南希望你写程序帮他解决类似的谜題。 这样的谜題具体可以描述为:
有 nn个玩具小人围成一圈, 已知它们的职业和朝向。现在第1个玩具小人告诉小南一个包含m条指令的谜題, 其中第 z条指令形如“左数/右数第s,个玩具小人”。 你需要输出依次数完这些指令后,到达的玩具小人的职业。
输入格式
输入的第一行包含两个正整数 n,m,表示玩具小人的个数和指令的条数。
接下来 n 行,每行包含一个整数和一个字符串,以逆时针为顺序给出每个玩具小人的朝向和职业。其中 0 表示朝向圈内,1 表示朝向圈外。 保证不会出现其他的数。字符串长度不超过 10 且仅由小写字母构成,字符串不为空,并且字符串两两不同。整数和字符串之间用一个空格隔开。
接下来 m 行,其中第 i 行包含两个整数 ai,si,表示第 i 条指令。若 ai=0,表示向左数 si 个人;若 ai=1,表示向右数 si 个人。 保证 ai 不会出现其他的数,1 ≤ si <n。
输出格式
输出一个字符串,表示从第一个读入的小人开始,依次数完 m 条指令后到达的小人的职业。
输入输出样例
输入 #1复制
7 3 0 singer 0 reader 0 mengbier 1 thinker 1 archer 0 writer 1 mogician 0 3 1 1 0 2
输出 #1复制
writer
输入 #2复制
10 10 1 C 0 r 0 P 1 d 1 e 1 m 1 t 1 y 1 u 0 V 1 7 1 1 1 4 0 5 0 3 0 1 1 6 1 2 0 8 0 4
输出 #2复制
y
说明/提示
【样例1说明】
这组数据就是【题目描述】 中提到的例子。
【子任务】
子任务会给出部分测试数据的特点。 如果你在解决题目中遇到了困难, 可以尝试只解决一部分测试数据。
每个测试点的数据规模及特点如下表:
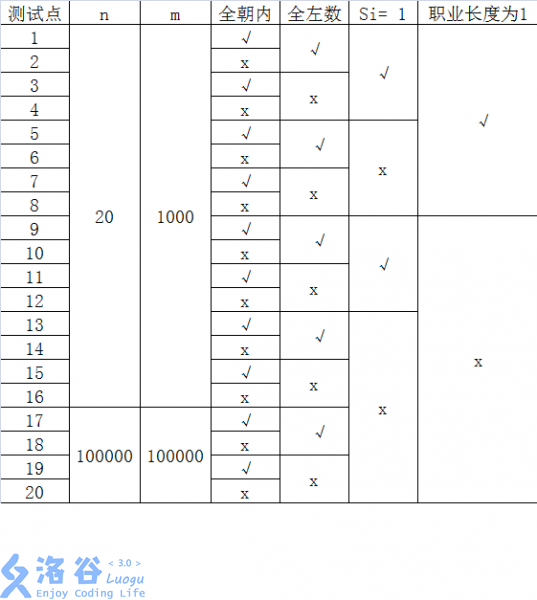
其中一些简写的列意义如下:
• 全朝内: 若为“√”, 表示该测试点保证所有的玩具小人都朝向圈内;
全左数:若为“√”,表示该测试点保证所有的指令都向左数,即对任意的
1≤z≤m , ai=0;
s= 1s=1:若为“√”,表示该测试点保证所有的指令都只数1个,即对任意的
1≤z≤m , si=1;
职业长度为1 :若为“√”,表示该测试点保证所有玩具小人的职业一定是一个
长度为1的字符串。
---------------------------------------------------------------------------------------------------------------------------------
这道题读完我第一反应是小孩报数问题(我感觉特别类似,都存在一个循环,然后我又想到了循环链表。但是这道题用链表我感觉...没必要吧)。
AC代码↓
#include<bits/stdc++.h>
using namespace std;
const int maxn=1e5+10;
struct p
{
int dr;
char a[11];
};
int main()
{
p per[maxn];
long int a,b,i;
int n,m,ans=0;
cin>>n>>m;
for(i=0;i<n;i++)
cin>>per[i].dr>>per[i].a;
for(i=0;i<m;i++)
{
cin>>a>>b;
if(per[ans].dr==0)//若方向朝内
{
if(a==0)//左
ans=(ans+n-b)%n;
else if(a==1)//右
ans=(ans+b)%n;
}
else if(per[ans].dr==1)//若方向朝外
{
if(a==1)//左
ans=(ans+n-b)%n;
else if(a==0)//右
ans=(ans+b)%n;
}
}
cout<<per[ans].a<<endl;
return 0;
}













 1364
1364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









