






笔记自用记录【随时更新】
目录
- argmax用法
- 广播机制
- torch.matmul()
- torch.scatter_
- torch.gather
- nn.Embeddings
- uniform_函数
- torch.arange.view()!!!!一定要学会创建张量方式
- torch.sum
- nn.ConvTranspose2d
- next() 和 iter() 的用法
- register_buffer
- 变量@变量
- sys.argv[1]
- torch.clamp
- nn.PixelShuffle
- torch.utils.data.Dataset
- torch.utils.data.Dataloader
- torch.einsum
- np.random.choice()
- F.one_hot()
argmax用法
返回的是下标
关于dim的详细用法见 argmax—dim
广播机制
广播机制详见 张量的广播机制
torch.matmul()
矩阵乘法(第一个参量一般是batch,后面的按照矩阵乘法来计算,可能会有广播机制)
matmul
torch.scatter_
scatter (分散)一般用于生成one-hot向量 scatter_
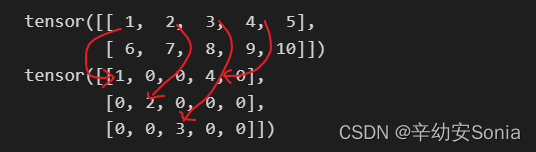
scatter_(input, dim, index, src) 将src中数据根据index中的索引按照dim的方向填进input中。
dim=0 按列填充
src = torch.arange(1, 11).reshape((2, 5))
print(src)
index = torch.tensor([[0,1,2,0]])
opt=torch.zeros(3, 5, dtype=src.dtype).scatter_(0, index, src)
print(opt)
输出结果:
tensor([[ 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10]])
tensor([[1, 0, 0, 4, 0],
[0, 2, 0, 0, 0],
[0, 0, 3, 0, 0]])
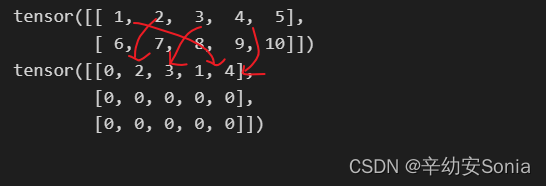
dim =1 按行填充
src = torch.arange(1, 11).reshape((2, 5))
print(src)
index = torch.tensor([[3, 1, 2, 4]])
opt=torch.zeros(3, 5, dtype=src.dtype).scatter_(1, index, src)
print(opt)
torch.gather
这个博文将的非常的清楚 torch.gather
.t()操作相当于矩阵的转置,列 / 行 向量相互转换
gather相当于【根据坐标,去t上找值】。
scatter_相当于【根据坐标,把x值填入前置对象中】
使用的时候都是embedding.scatter_
nn.Embeddings
nn.Embeddings
是一个lookup table,存储了固定大小的dictionary(的word embeddings)。输入是indices,来获取指定indices的word embedding向量。
a=embedding(input)是去embedding.weight中取对应index的词向量
uniform_函数
import random
random.uniform(x, y)
uniform() 方法将随机生成下一个实数,它在[x,y]范围内。
torch.arange.view()!!!一定要学会创建张量方式
torch.sum
keepdim:求和之后这个dim的元素个数为1,所以要被去掉,如果要保留这个维度,则应当keepdim=True
- dim=0:将第0维相加,第1维不动
a=torch.arange(1,13).view(3,4)
print(a)
b=torch.sum(a**2, dim=0, keepdim=True)
print(b)
tensor([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
tensor([[107, 140, 179, 224]])
- dim=1:将第1维相加,第0维不动
b=torch.sum(a**2, dim=1, keepdim=True)
tensor([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
tensor([[ 30],
[174],
[446]])
如果去掉keepdim,则变成
tensor([107, 140, 179, 224])
tensor([ 30, 174, 446])
数据类型,在括号内直接声明dtype
# CPU
a=torch.arange(1, 10, 2,device="cpu",dtype=torch.float16) # 不可以
a=torch.arange(1, 10, 2,device="cpu",dtype=torch.float32) # 可以
a=torch.arange(1, 10, 2,device="cpu",dtype=torch.float64) # 可以
# GPU
a=torch.arange(1, 10, 2, device="cuda:0",dtype=torch.float16) # 可以
a=torch.arange(1, 10, 2, device="cuda:0",dtype=torch.float32) # 可以
a=torch.arange(1, 10, 2, device="cuda:0",dtype=torch.float64) # 可以
nn.ConvTranspose2d
传统的卷积通常是将大图片卷积成一张小图片,而反卷积就是反过来,将一张小图片变成大图片
在传统卷积中,我们的 padding 范围为[0,p-1],p = 0 被称为 No padding,p = k − 1 被称为 Full Padding。
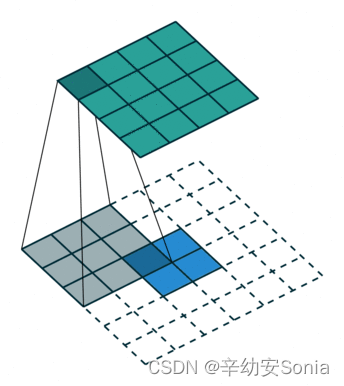
这是一个padding=0的反卷积,因为在反卷积中,p ′= k − 1 − p 。
也就是当我们传 p ′ = 0 时,相当于在传统卷积中传了 p = k − 1 ,而传 p ′ = k − 1 时,相当于在传统卷积中传了 p = 0 。
next() 和 iter() 的用法
next()函数用于取出可迭代对象的元素,一般与iter()函数联合使用。
next(iterobject, defalt)
- iterobject:可迭代的对象
- default:可选
当第二个参数不写入的时候,如果可迭代的元素全部取出来后,会返回Stoplteration的异常;
当第二个参数写入的时候,可迭代对象完之后,会一直返回第二个参数写的数值。
register_buffer
在内存中定一个常量,同时,模型保存和加载的时候可以写入和读出。
pytorch一般情况下,是将网络中的参数保存成orderedDict形式的,这里的参数其实包含两种,一种是各种module含的参数,即nn.Parameter。另一种就是buffer,前者每次optim.step会得到更新,而不会更新后者。
- 网络存储时也会将buffer存下,当网络load模型时,会将存储的模型的buffer也进行赋值。
- buffer的更新在forward中,optim.step只能更新nn.parameter类型的参数。
变量@变量
出现在一行代码中间位置的@这个@是矩阵相乘的意思,
就是比如
A的shape是[batch_size, sequence_length2, sequence_length1]
B的shape是[batch_size, sequence_length1, hidden_dim]
C = A @ B
则C的shape是[batch_size, sequence_length2, hidden_dim]
sys.argv[1]
python temp.py a b c d
python temp.py 时,同时传入4个参数:a、b、c、d
sys.argv == ["temp.py","a","b","c","d"] # sys.argv是持有5个元素的list对象
sys.argv[0] == "temp.py" #第1个元素为模块名“temp.py”
sys.argv[1] == "a" #第2个元素为"a"
sys.argv[2] == "b" #第3个元素为"b"
sys.argv[3] == "c" #第4个元素为"c"
sys.argv[4] == "d" #第5个元素为"d"
torch.clamp
torch.clamp(input, min, max, out=None) → Tensor
将输入input张量每个元素的夹紧到区间 [min,max] 并返回一个新张量
| min, if x_i < min
y_i = | x_i, if min <= x_i <= max
| max, if x_i > max
nn.PixelShuffle
class torch.nn.PixleShuffle(upscale_factor)
这里的upscale_factor就是放大的倍数,数据类型为int。

>>> pixelshuffle = nn.PixelShuffle(3)
>>> input = torch.tensor(1, 9, 4, 4)
>>> output = pixelshuffle(input)
>>> print(output.size())
torch.Size([1, 1, 12, 12])
torch.utils.data.Dataset
自己定义的 dataset 类需要继承 Dataset。
需要实现必要的魔法方法:
在 __init__ 方法里面进行 读取数据文件 。
在 __getitem__ 方法里支持通过下标访问数据。
在__len__方法里返回自定义数据集的大小,方便后期遍历。
torch.utils.data.Dataset
torch.utils.data.Dataloader
torch.einsum
用 i 和 j 去表示矩阵的行和列,比如矩阵乘法的实现
>>> import torch
>>> A = torch.randn(3, 4)
>>> B = torch.randn(4, 5)
>>> C = torch.einsum('ik,kj->ij', A, B)
>>> C.shape
torch.Size([3, 5])
np.random.choice()
F.one_hot()
torch.arange(0,5) % 3
即 tensor([0, 1, 2, 0, 1])
F.one_hot(torch.arange(0, 5) % 3)
tensor([[1, 0, 0],
[0, 1, 0],
[0, 0, 1],
[1, 0, 0],
[0, 1, 0]])
>>> F.one_hot(torch.arange(0, 5) % 3, num_classes=5)
tensor([[1, 0, 0, 0, 0],
[0, 1, 0, 0, 0],
[0, 0, 1, 0, 0],
[1, 0, 0, 0, 0],
[0, 1, 0, 0, 0]])














 276
276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









