







注:代码仅供参考,实际到最后用到的也不多,文中大部分代码属于是一个能运行但是得不到想要的结果的状态,只有知识图谱构建部分是有用的
1. 数据准备
首先,需要准备好法律文书的数据集,标注出头实体、关系和尾实体。这些标注数据用于训练和验证模型。将收集到的数据进行整理。
import json
def process_input(input_text):
lines = input_text.split('\n')
for i, line in enumerate(lines):
if "判决书" in line:
return '\n'.join(lines[i:])
return None
def process_jsonl(input_file, output_file):
with open(input_file, 'r', encoding='utf-8') as infile, open(output_file, 'w', encoding='utf-8') as outfile:
for line in infile:
data = json.loads(line.strip())
processed_input = process_input(data['input'])
if processed_input is not None:
new_data = {
'id': data['id'],
'judgement': processed_input
}
json.dump(new_data, outfile, ensure_ascii=False)
outfile.write('\n')
input_file = 'DISC-Law-SFT-Pair.jsonl'
output_file = 'output.jsonl'
process_jsonl(input_file, output_file)
2. 模型架构
2.1 编码器部分
- BERT 编码器:使用
Bert-base-chinese预训练模型对输入文本进行编码,获取上下文语义信息。
from transformers import BertModel, BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
bert_model = BertModel.from_pretrained('bert-base-chinese')
# Example encoding
input_text = "输入的法律文书文本"
inputs = tokenizer(input_text, return_tensors='pt')
outputs = bert_model(**inputs)
encoded_text = outputs.last_hidden_state
2.2 解码器部分
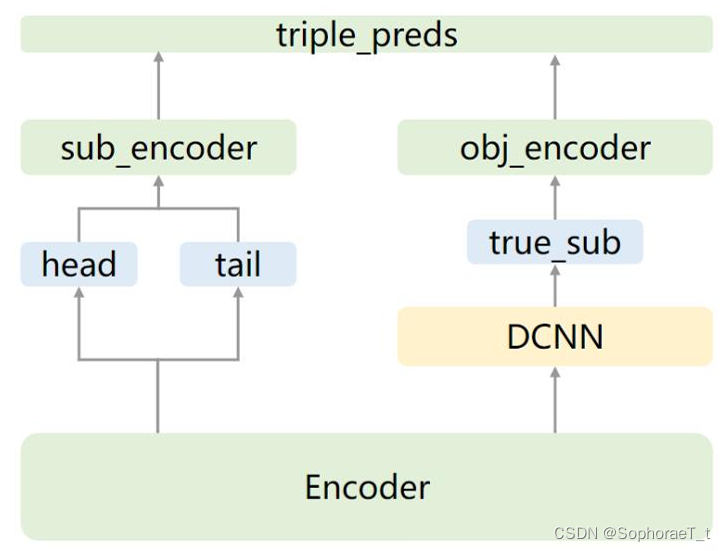
采用层叠指针网络(CasRel),设计两个主要的解码层:
- 头实体识别层:识别文本中的头实体
h。 - 关系和尾实体联合识别层:基于已识别出的头实体,识别对应的关系
r和尾实体t。
具体的训练过程可以用下图表示
3. 实现指针网络
3.1 头实体识别层
- 设计一个分类器,用于识别每个位置是否是头实体。
import torch
import torch.nn as nn
class HeadEntityClassifier(nn.Module):
def __init__(self, hidden_size):
super(HeadEntityClassifier, self).__init__()
self.classifier = nn.Linear(hidden_size, 2) # 二分类:是否是头实体
def forward(self, encoded_text):
logits = self.classifier(encoded_text)
return logits
3.2 关系和尾实体联合识别层
- 基于已识别出的头实体位置,进一步识别关系和对应的尾实体。
class RelationTailClassifier(nn.Module):
def __init__(self, hidden_size, num_relations):
super(RelationTailClassifier, self).__init__()
self.relation_classifier = nn.Linear(hidden_size, num_relations)
self.tail_classifier = nn.Linear(hidden_size, 2) # 二分类:是否是尾实体
def forward(self, encoded_text, head_positions):
# Extract head entity embeddings
head_entity_embeddings = encoded_text[head_positions]
# Predict relations
relation_logits = self.relation_classifier(head_entity_embeddings)
# Predict tail entities
tail_logits = self.tail_classifier(encoded_text)
return relation_logits, tail_logits
4. 联合训练
- 设计损失函数,包括头实体识别的交叉熵损失和关系、尾实体识别的联合损失。
- 使用反向传播优化整个模型。
class CasRelModel(nn.Module):
def __init__(self, bert_model, hidden_size, num_relations):
super(CasRelModel, self).__init__()
self.bert_model = bert_model
self.head_entity_classifier = HeadEntityClassifier(hidden_size)
self.relation_tail_classifier = RelationTailClassifier(hidden_size, num_relations)
def forward(self, input_ids, attention_mask):
outputs = self.bert_model(input_ids=input_ids, attention_mask=attention_mask)
encoded_text = outputs.last_hidden_state
# 头部实体预测
head_logits = self.head_entity_classifier(encoded_text)
# 关系和尾部实体预测
head_positions = torch.argmax(head_logits, dim=1) # 获取预测头部实体的位置
relation_logits, tail_logits = self.relation_tail_classifier(encoded_text, head_positions)
return head_logits, relation_logits, tail_logits
# 损耗与优化
def compute_loss(head_logits, relation_logits, tail_logits, head_labels, relation_labels, tail_labels):
loss_fct = nn.CrossEntropyLoss()
head_loss = loss_fct(head_logits.view(-1, 2), head_labels.view(-1))
relation_loss = loss_fct(relation_logits.view(-1, num_relations), relation_labels.view(-1))
tail_loss = loss_fct(tail_logits.view(-1, 2), tail_labels.view(-1))
return head_loss + relation_loss + tail_loss
# 训练循环
model = CasRelModel(bert_model, hidden_size=768, num_relations=num_relations)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5)
model.train()
for epoch in range(num_epochs):
for batch in dataloader:
input_ids, attention_mask, head_labels, relation_labels, tail_labels = batch
optimizer.zero_grad()
head_logits, relation_logits, tail_logits = model(input_ids, attention_mask)
loss = compute_loss(head_logits, relation_logits, tail_logits, head_labels, relation_labels, tail_labels)
loss.backward()
optimizer.step()
完整代码,前面的代码是在设计阶段的设计,后面根据实际情况修改了很多。
import json
import torch
import torch.nn as nn
from transformers import BertTokenizer, BertModel, AdamW
# 加载数据
def load_data(file_path):
data = []
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
data.append(json.loads(line.strip()))
return data
# 转换数据
def convert_data_to_model_input(data):
sentences = []
head_labels = []
tail_labels = []
rel_labels = []
for doc in data:
for item in doc['content']:
sentence = item['tokens']
sentences.append(sentence)
length = len(sentence)
head_label = [0] * length
tail_label = [0] * length
rel_label = [0] * length
for candidate in doc['candidates']:
if candidate['sent_id'] == doc['content'].index(item):
start, end = candidate['offset']
if start < length and end < length:
head_label[start] = 1
tail_label[end] = 1
for i in range(start, end + 1):
rel_label[i] = 1
head_labels.append(head_label)
tail_labels.append(tail_label)
rel_labels.append(rel_label)
return sentences, head_labels, tail_labels, rel_labels
# 填充标签
def pad_labels(labels, max_length):
padded_labels = []
for label in labels:
if len(label) > max_length:
padded_label = label[:max_length]
else:
padded_label = label + [0] * (max_length - len(label))
padded_labels.append(padded_label)
return padded_labels
# 定义CasRel模型
class CasRelModel(nn.Module):
def __init__(self, bert_model_name):
super(CasRelModel, self).__init__()
self.bert = BertModel.from_pretrained(bert_model_name)
self.head_extractor = nn.Linear(self.bert.config.hidden_size, 2)
self.tail_extractor = nn.Linear(self.bert.config.hidden_size, 2)
self.rel_extractor = nn.Linear(self.bert.config.hidden_size, 2)
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
sequence_output = outputs.last_hidden_state
head_logits = self.head_extractor(sequence_output)
tail_logits = self.tail_extractor(sequence_output)
rel_logits = self.rel_extractor(sequence_output)
return head_logits, tail_logits, rel_logits
# 检查GPU是否可用
if torch.cuda.is_available():
device = torch.device("cuda")
print(f"Using GPU: {torch.cuda.get_device_name(0)}")
else:
device = torch.device("cpu")
print("Using CPU")
# 加载数据
data = load_data('legal_documents.jsonl')[:100]
sentences, head_labels, tail_labels, rel_labels = convert_data_to_model_input(data)
# 定义最大长度并填充标签
max_length = 512
head_labels = pad_labels(head_labels, max_length)
tail_labels = pad_labels(tail_labels, max_length)
rel_labels = pad_labels(rel_labels, max_length)
# 定义模型并转移到GPU
model = CasRelModel('bert-base-chinese').to(device)
# 初始化BERT tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
input_ids = []
attention_masks = []
# Tokenize sentences并转移到GPU
for sentence in sentences:
inputs = tokenizer(sentence, is_split_into_words=True, return_tensors='pt', padding='max_length', max_length=max_length, truncation=True)
input_ids.append(inputs['input_ids'])
attention_masks.append(inputs['attention_mask'])
input_ids = torch.cat(input_ids).to(device)
attention_masks = torch.cat(attention_masks).to(device)
# 将标签转移到GPU
head_labels = torch.tensor(head_labels).to(device)
tail_labels = torch.tensor(tail_labels).to(device)
rel_labels = torch.tensor(rel_labels).to(device)
# 定义优化器和损失函数
optimizer = AdamW(model.parameters(), lr=2e-5)
loss_fn = nn.CrossEntropyLoss()
# 定义batch size
batch_size = 8
# 训练模型
for epoch in range(3):
model.train()
for i in range(0, len(input_ids), batch_size):
batch_input_ids = input_ids[i:i + batch_size]
batch_attention_masks = attention_masks[i:i + batch_size]
batch_head_labels = head_labels[i:i + batch_size]
batch_tail_labels = tail_labels[i:i + batch_size]
batch_rel_labels = rel_labels[i:i + batch_size]
optimizer.zero_grad()
head_logits, tail_logits, rel_logits = model(batch_input_ids, batch_attention_masks)
head_loss = loss_fn(head_logits.view(-1, 2), batch_head_labels.view(-1))
tail_loss = loss_fn(tail_logits.view(-1, 2), batch_tail_labels.view(-1))
rel_loss = loss_fn(rel_logits.view(-1, 2), batch_rel_labels.view(-1))
loss = head_loss + tail_loss + rel_loss
loss.backward()
optimizer.step()
print(f'Epoch {epoch}, Batch {i // batch_size}, Loss: {loss.item()}')
print("Training complete!")
# 定义评估和提取实体关系的函数
def extract_entities_and_relations(model, tokenizer, sentences, max_length=512):
model.eval()
entities_relations = []
for sentence in sentences:
inputs = tokenizer(sentence, is_split_into_words=True, return_tensors='pt', padding='max_length', max_length=max_length, truncation=True)
input_ids = inputs['input_ids'].to(device)
attention_mask = inputs['attention_mask'].to(device)
with torch.no_grad():
head_logits, tail_logits, rel_logits = model(input_ids, attention_mask)
head_predictions = torch.argmax(head_logits, dim=-1).cpu().numpy().flatten()
tail_predictions = torch.argmax(tail_logits, dim=-1).cpu().numpy().flatten()
rel_predictions = torch.argmax(rel_logits, dim=-1).cpu().numpy().flatten()
entities = []
relations = []
for idx, token in enumerate(sentence):
if head_predictions[idx] == 1:
entity_start = idx
for j in range(idx, len(sentence)):
if tail_predictions[j] == 1:
entity_end = j
entities.append("".join(sentence[entity_start:entity_end + 1]))
break
current_relation = []
for idx, token in enumerate(sentence):
if rel_predictions[idx] == 1:
current_relation.append(token)
else:
if current_relation:
relations.append("".join(current_relation))
current_relation = []
entities_relations.append({
'sentence': sentence,
'entities': entities,
'relations': relations
})
return entities_relations
# 提取实体和关系
extracted_data = extract_entities_and_relations(model, tokenizer, sentences)
# 保存提取结果到文件
output_file = 'extracted_entities_relations.jsonl'
with open(output_file, 'w', encoding='utf-8') as f:
for item in extracted_data:
f.write(json.dumps(item, ensure_ascii=False) + '\n')
print(f"Extracted data saved to {output_file}")
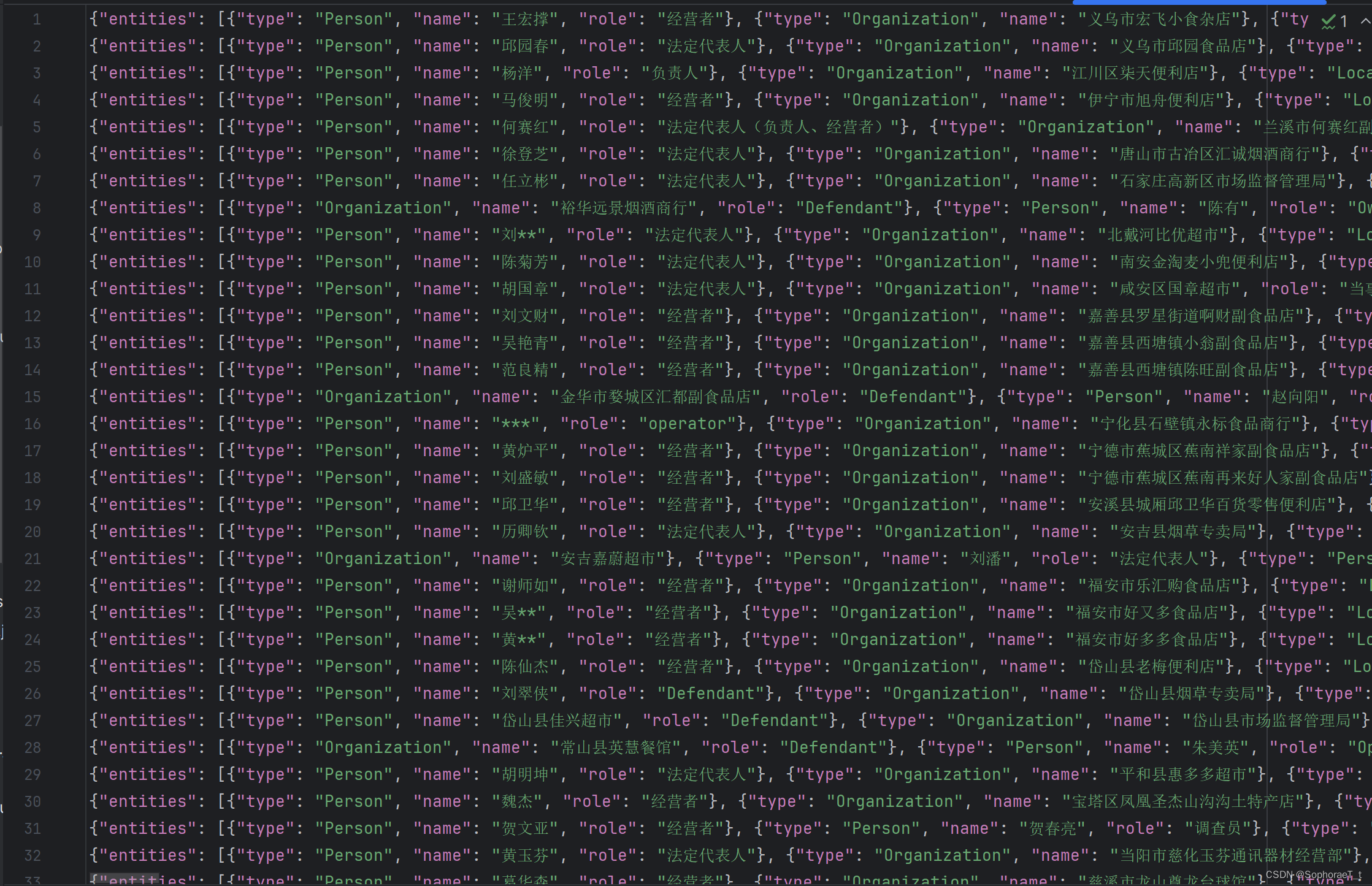
对抽取结果进行整理之后得到最终构建知识图谱所需要的数据如下
5. 评估与优化
- 在验证集上评估模型的性能,使用准确率、召回率和F1分数等指标。
- 根据需要调整模型超参数、增加正则化方法等,以提升模型性能。
from sklearn.metrics import classification_report
# 模型评估
model.eval()
all_preds, all_labels = [], []
with torch.no_grad():
for batch in val_dataloader:
input_ids, attention_mask, head_labels, relation_labels, tail_labels = batch
head_logits, relation_logits, tail_logits = model(input_ids, attention_mask)
head_preds = torch.argmax(head_logits, dim=2)
all_preds.extend(head_preds.cpu().numpy())
all_labels.extend(head_labels.cpu().numpy())
# 计算评估指标
print(classification_report(all_labels, all_preds, target_names=label_names))
根据评估结果,得到的最佳参数是
learning_rate = 1e-5
dilation rate = 50
hidden size = 256
batch_size = 4
max_epoch = 100
max_len = 256
rel_num = 4
optimizer = adamw
weight_decay = 0.01
teacher_pro = 0.8
use_focal = True
sub_threhold = 0.4
dropout = 0.4
attention = "plus"
6. 构建知识图谱
实体和关系抽取完毕后,即可使用neo4j进行知识图谱构建。
import json
from neo4j import GraphDatabase
# 配置Neo4j数据库连接
uri = "bolt://localhost:7687"
username = "neo4j"
password = "******"
# 连接到Neo4j数据库
driver = GraphDatabase.driver(uri, auth=(username, password))
def create_entity(tx, entity):
query = f"""
MERGE (e:{entity['type']} {{name: $name}})
ON CREATE SET e.role = $role
"""
tx.run(query, name=entity['name'], role=entity.get('role', ''))
def create_relationship(tx, relationship):
query = f"""
MATCH (a {{name: $source}})
MATCH (b {{name: $target}})
MERGE (a)-[r:{relationship['relation']}]->(b)
"""
tx.run(query, source=relationship['source'], target=relationship['target'])
def process_line(line):
data = json.loads(line)
entities = data.get("entities", [])
relationships = data.get("relationships", [])
with driver.session() as session:
# 创建实体节点
for entity in entities:
session.execute_write(create_entity, entity)
# 创建关系
for relationship in relationships:
session.execute_write(create_relationship, relationship)
def main(input_file):
with open(input_file, 'r', encoding='utf-8') as infile:
for line in infile:
process_line(line)
if __name__ == "__main__":
input_file = 'extracted_content.jsonl' # 替换为你的JSONL文件路径
main(input_file)
# 关闭数据库连接
driver.close()
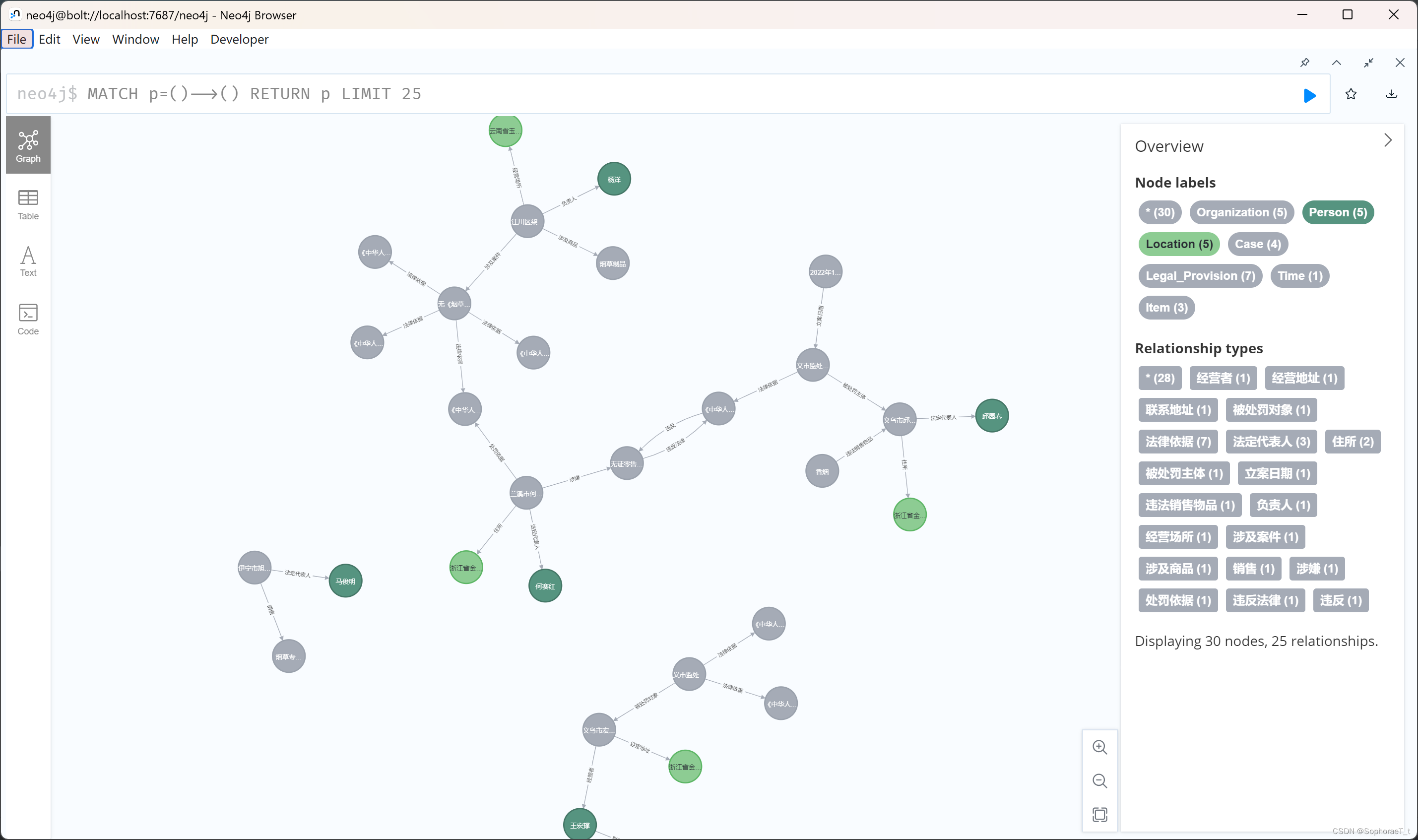
节点图

关系图

由于我们的数据集是集中在一类案件的,因此整个知识图谱比较集中。
7. 使用图神经网络利用知识图谱的图结构信息
import json
import torch
import torch.nn.functional as F
from torch_geometric.data import Data
from torch_geometric.nn import GCNConv
# 步骤 1:读取和解析 JSONL 文件
file_path = 'output.jsonl'
data = []
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
data.append(json.loads(line))
# 步骤 2:构建图数据
nodes = set()
edges = []
for record in data:
for entity in record['entities']:
nodes.add(entity['name'])
for relation in record['relationships']:
edges.append((relation['source'], relation['target']))
# 将节点映射到索引
node_index = {node: idx for idx, node in enumerate(nodes)}
# 构建边索引
edge_index = torch.tensor(
[[node_index[edge[0]], node_index[edge[1]]] for edge in edges],
dtype=torch.long
).t().contiguous()
num_nodes = len(nodes)
num_node_features = 3
x = torch.ones((num_nodes, num_node_features), dtype=torch.float)
y = torch.zeros(num_nodes, dtype=torch.long)
# 创建 PyTorch Geometric 数据对象
graph_data = Data(x=x, edge_index=edge_index, y=y)
# 步骤 3:定义和训练模型
class GCN(torch.nn.Module):
def __init__(self, num_node_features, hidden_channels, num_classes):
super(GCN, self).__init__()
self.conv1 = GCNConv(num_node_features, hidden_channels)
self.conv2 = GCNConv(hidden_channels, num_classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
# 创建模型
model = GCN(num_node_features=graph_data.num_node_features, hidden_channels=16, num_classes=2)
# 设置优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
# 训练模型
def train():
model.train()
optimizer.zero_grad()
out = model(graph_data)
loss = F.nll_loss(out, graph_data.y)
loss.backward()
optimizer.step()
return loss.item()
# 评估模型
def test():
model.eval()
out = model(graph_data)
pred = out.argmax(dim=1)
correct = (pred == graph_data.y).sum()
acc = int(correct) / int(graph_data.y.size(0))
return acc
# 训练和评估
for epoch in range(200):
loss = train()
acc = test()
if epoch % 10 == 0:
print(f'Epoch {epoch}, Loss: {loss:.4f}, Accuracy: {acc:.4f}')
总结
这次项目实训中,我学到了许多,包括使用Doccano对数据进行半人工标注,进而用人工标注的数据对bert_base_chinese模型进行微调,最后就是完成任务的关键在于结合BERT的强大编码能力和指针网络的联合解码机制,有效地抽取出法律文书中的实体和关系信息,为后续构建法律文书合规性检测提供了方向和结构性数据。

















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









