






在众多科技企业竞相提升大模型的多模态能力,致力于将文本总结、图像编辑等功能集成到移动设备中的时候,OpenAI 又双叒叕上新了!CEO奥特曼用了3个字母表达他的状态:her(就像电影《Her》一样)。

5月14日凌晨,OpenAI 首次“春季新品发布会”上,正式发布最新的 GPT-4o ,并展示了一系列新功能。不仅颠覆了产品的形态,更是又一次让全球科技界为之沸腾。GPT-4o 作为一款人机交互的先进大模型,融合了文本、语音和图像三种模态的理解能力,其响应速度之快、情感表达之丰富以及对人类行为的深刻理解,都标志着人机交互领域的又一次飞跃。
FounderPark
,赞6400
大家惊叹于Her时代来了,AI超拟人化也备受关注。 拟人化TTS指的是系统能够模拟自然对话中的口语特征,如延长音、停顿、口语化词汇填充、重复、倒装和重读等。为了实现这一点,TTS模型在建模时必须复现这些口语化事件,并考虑到文本和声学的上下文。
此外,模型还需要关注更多的非语言信息,以增强语音的自然性和表达力。下面是Base TTS模型对于各项指标的评估,可以看副语言和情感评分最低,这表明情感和副语言的合成仍然是语音合成任务中最具挑战性的任务。
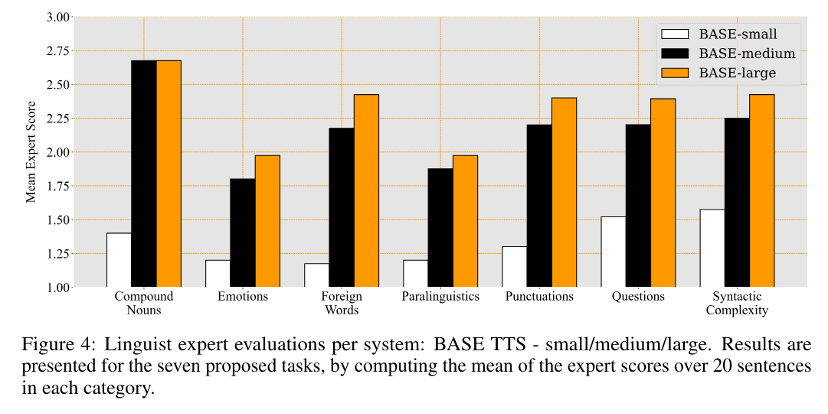
来自论文 BASE TTS: Lessons from building a billion-parameter Text-to-Speech model on 100K hours of data
01 开发拟人化TTS系统的挑战
数据的获取和处理
开发拟人化的TTS系统面临的一个主要挑战是数据的获取和处理。
首先,为了训练一个能够精确处理非语言信息,如语调、强度和情感状态的TTS系统,需要依赖于大量的、高质量的、详细标注的语音数据。这些数据的标注不仅需包含文字信息,还应详细记录语音的多种声学特征,以便系统能够学习并复现自然语音中的复杂变化。
其次,语音数据的多样性也是一个关键因素。由于不同地区、不同性别、不同年龄群体的人们在说话时会展现出独特的语音特征和习惯,为了确保TTS系统在多种口音和语言风格中都能保持良好的表现,必须收集来自极其广泛背景的语音样本。这包括多种方言、口音以及从正式到非正式的各种语言风格,以确保系统的广泛适用性和自然性。因此,高质量和高多样性的数据收集及其处理,成为开发拟人化TTS系统的重大挑战之一。
模型的设计和训练
开发拟人化的TTS系统在模型的设计和训练方面面临重大挑战,主要集中在模型复杂性和声音的自然性与一致性两大领域。
1. 模型复杂性
为了精准捕捉和再现人类的副语言信息,如语调、停顿、强调和情感变化,TTS模型必须具备高度的复杂性和表现力。这要求模型不仅能理解文本的字面意义,还需深入解析文本中蕴含的情感和语境,进而在语音输出中体现这些细微差别。
情感的自动检测是通过NLP技术实现,如情感分析,但如何将这些情感映射到具体的声音表达上,如语调的高低、语速的快慢及音量的强弱,仍然是AI研究中的前沿问题。
此外,模型还需要能够处理各种复杂的语音模式和非标准语言表达,如方言、口音或特定群体的说话习惯。
2. 声音的自然性与一致性
在自然对话中,人们根据上下文和情感状态不断调整自己的语调和语速,这种动态的语音调整在TTS系统中实现极为困难。
尽管现代TTS系统通过采用先进的机器学习模型如深度神经网络已经能够提高语音合成的自然度,但在保持语音输出的一致性和真实感方面仍存在挑战。尤其是在处理长文本或复杂对话时,保持语音的流畅性和自然度,同时不失去情感的真实表达,是技术上的难点。
此外,为了提高自然性,TTS系统经常需要在运行时做出复杂的决策以适应文本内容的变化,这对实时语音生成的算法效率和响应速度提出了更高的要求。
针对这些挑战,研究人员正在探索包括但不限于以下方向:增强的情感建模技术、上下文感知的语音生成算法、以及利用大规模数据进行深度学习训练的方法。通过对大量的语音数据进行深入分析和学习,TTS系统能够更好地理解和模拟人类的语言多样性和复杂性,进而提升语音合成的自然度和应用广度。
02 应对挑战的解决方案
1. LLM模型的辅助TTS
Zhifan Guo et.al 开发了一个文本到语音(TTS)系统(被称为PromptTTS),该系统接受包含风格和内容描述的提示作为输入,以合成相应的语音。
PromptTTS包括一个风格编码器和一个内容编码器,用于从提示中提取相应的表示,以及一个语音解码器,根据提取的风格和内容表示合成语音。
与以往需要用户具备声学知识以理解诸如韵律和音高等风格因素的可控TTS作品相比,PromptTTS更加用户友好,因为文本描述是表达语音风格的更自然的方式。该模型能很好的捕捉语音合成中的风格和韵律等副语言信息。
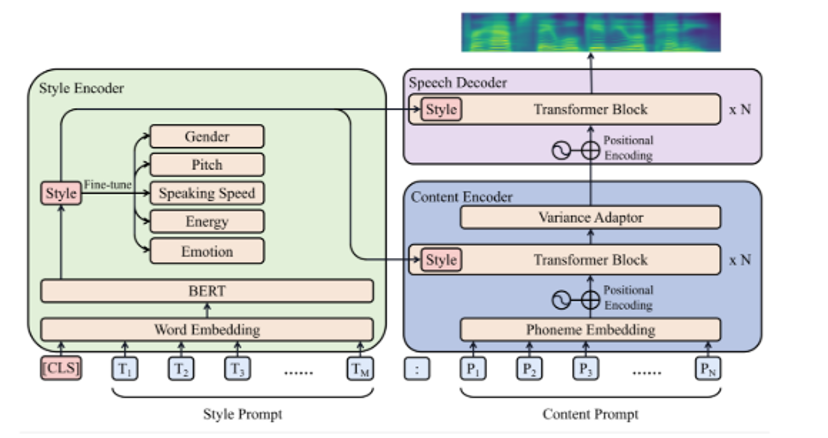
出自论文 PROMPT TTS: controllable Text-to-Speech with text descriptions
2. 带副语言标注的合成数据库
由于精细化标注的含副语言标签的TTS数据库不足,目前少有研究通过直接训练而非借助语言模型来提升TTS系统中副语言的合成效果。
然而,直接使用这些数据训练TTS模型可以更直接有效地学习如何表达情感、语气等副语言特征,简化系统结构,提高数据的一致性与质量,增强模型的泛化能力,并减少对外部系统的依赖。这为开发者提供了更好的用户定制性,允许针对特定需求优化TTS输出。
尽管直接训练的好处显著,但其挑战却很大,尤其是在高质量标注数据的获取上需要巨大的时间和资源投入,可能还需开发新技术以最大化数据的效用。
03 海天瑞声精标副语言数据集
为了应对当前市场上精细标注副语言信息的中文语音合成数据库的短缺,海天瑞声推出创新精标副语言数据集,专为副语言现象如拖音、重音和停顿等进行了详细标注。
主要聚焦于对话环境下的闲聊语料,非常适合用来训练和优化文本到语音(TTS)系统,以提高其在实际对话应用中的自然性和表达力。该数据库的特点包括:
丰富的副语言标注:每条语音数据不仅标注了基本的发音和语调信息,还精细标记了如拖音、重音和停顿等多种副语言信息,使得TTS系统能更真实地复现人类的语言表达。
对话式语料设计:所有语料都是基于对话场景,尤其是闲聊类型的对话,这有助于TTS系统更好地应用于聊天机器人、虚拟助手等互动式应用。
高质量音频采集:采用专业录音设备在声学处理过的环境中录制,确保语音数据的纯净度和高质量。
全新推出的精细标注副语言信息的中文语音合成数据集,将成为AI聊天机器人、虚拟助手、教育软件和游戏娱乐等领域开发人员的强大工具,能够极大地提升语音交互的自然性和表达力。
该数据集能够有效的促进TTS系统的研发,更精准的复现人类语音的多样性和复杂性,推动超拟人语音合成技术的广泛应用。

















 1285
1285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









