







FastSpeech: Fast, Robust and Controllable Text to Speech
文章目录
Abstract
基于神经网络的端到端文本到语音(TTS)显著提高了合成语音的质量。著名的方法(例如,Tacotron 2)通常首先从文本生成mel声谱图,然后使用声码器(如WaveNet)从mel声纹图合成语音。与传统的串联和统计参数方法相比,基于神经网络的端到端模型推理速度慢,合成的语音通常不鲁棒(即一些单词被跳过或重复),并且缺乏可控性(语速或韵律控制)。在这项工作中,我们提出了一种新的基于Transformer的前馈网络来并行生成TTS的mel谱图。具体而言,我们从基于编码器-解码器的teacher模型中提取注意力对齐,用于phoneme duration预测,长度调节器| length regulator使用该模型来扩展源音素序列| phoneme sequence,以匹配目标mel声谱图序列的长度,用于并行mel声纹图生成。在LJSpeech数据集上的实验表明,我们的并行模型在语音质量方面与自回归模型相匹配,几乎消除了在特别困难的情况下跳过和重复单词的问题,并且可以平滑地调整语速。最重要的是,与自回归Transformer TTS相比,我们的模型将mel声谱图生成速度提高了270倍,端到端语音合成速度提高了38倍。因此,我们将我们的模型称为FastSpeech。
Introduction
近年来,由于深度学习的进步,文本到语音(TTS)引起了人们的广泛关注。基于深度神经网络的系统在TTS中越来越受欢迎,如Tacotron、Tacotron 2、Deep Voice 3和完全端到端的ClariNet。这些模型通常首先从文本输入 自回归地生成mel声谱图,然后使用声码器| vocoder(如Griffin Lim、WaveNet、Parallel WaveNet或WaveGlow)从mel声纹图合成语音。在语音质量方面,基于神经网络的TTS优于传统的串联和统计参数方法。
在目前基于神经网络的TTS系统中,mel谱图是自回归生成的。由于mel谱图的长序列和自回归性质,这些系统面临着几个挑战:
- mel谱图生成的推理速度较慢。尽管基于CNN和Transformer的TTS可以加快基于RNN的模型的训练,但所有模型都会在先前生成的mel声谱图的基础上生成mel声图,并且推理速度较慢,因为mel声纹图序列的长度通常为数百或数千。
- 合成语音通常不鲁棒。由于自回归生成中的错误传播和文本和语音之间的错误注意力对齐,生成的mel声谱图通常存在单词跳跃和重复的问题。
- 合成语音缺乏可控性。以前的自回归模型一个接一个地自动生成mel声谱图,而没有明确地利用文本和语音之间的对齐。因此,在自回归生成中通常很难直接控制语音速度和韵律。
考虑到文本和语音之间的单调对齐,为了加快mel声谱图的生成,本文提出了一种新的模型FastSpeech,该模型以文本(音素)序列| phoneme sequence为输入,非自回归地生成mel声图。它采用了基于Transformer中的自注意和1D卷积的前馈网络。由于mel声谱图序列比其对应的音素序列长得多,为了解决两个序列之间的长度不匹配问题,FastSpeech采用了长度调节器,该长度调节器根据音素持续时间(即每个音素对应的mel声图的数量)对音素序列进行上采样,以匹配mel声纹图序列的长度。调节器建立在音素持续时间预测器上,该预测器预测每个音素的持续时间。
我们提出的FastSpeech可以解决上述三个挑战,具体如下:
- 通过并行生成mel声谱图,FastSpeech大大加快了合成过程
- 音素持续时间预测器确保音素及其融合谱图之间的硬对齐,这与自回归模型中的软和自动注意力对齐非常不同。因此,FastSpeech避免了错误传播和错误注意力对齐的问题,从而降低了跳过单词和重复单词的比例。
- 长度调节器可以通过延长或缩短音素持续时间来轻松调整语速,以确定生成的mel声谱图的长度,还可以通过在相邻音素之间添加中断来控制部分韵律。
我们在LJSpeech数据集上进行了实验来测试FastSpeech。结果表明,在语音质量方面,FastSpeech几乎与自回归Transformer模型相匹配。此外,与自回归Transformer TTS模型相比,FastSpeech在mel声谱图生成上实现了270倍的加速,在最终语音合成上实现了38倍的加速。几乎消除了单词跳跃和重复的问题,并且可以平滑地调整语音速度。我们在补充材料中附上了一些由我们的方法生成的音频文件。
Background
在本节中,我们简要概述了这项工作的背景,包括文本到语音、序列到序列学习和非自回归序列生成。
Text to Speech TTS
TTS旨在合成给定文本的自然和可理解的语音,长期以来一直是人工智能领域的研究热点。TTS的研究已经从早期的级联合成、统计参数合成转向了基于神经网络的参数合成和端到端模型,端到端的模型合成的语音质量接近人类parity。基于神经网络的端到端TTS模型通常首先将文本转换为声学特征(例如,mel声谱图),然后将mel声纹图转换为音频样本。然而,大多数神经TTS系统自回归生成mel声谱图,推理速度慢,合成语音通常缺乏鲁棒性(单词跳跃和重复)和可控性(语音速度或韵律控制)。在这项工作中,我们提出了FastSpeech来生成非自回归的mel谱图,它充分地处理了上述问题。
Sequence to Sequence Learning
序列到序列学习通常建立在编码器-解码器框架上:编码器将源序列作为输入,并生成一组表示。之后,解码器在给定源表示及其先前元素的情况下估计每个目标元素的条件概率。注意力机制被进一步引入编码器和解码器之间,以便在预测当前元素时找到要关注的源表示,并且是序列到序列学习的重要组成部分。
在这项工作中,我们提出了一种前馈网络来并行生成序列,而不是使用传统的编码器-注意力-解码器框架进行序列到序列的学习。
Non-Autoregressive Sequence Generation
与自回归序列生成不同,非自回归模型并行生成序列,而不明确依赖于先前的元素,这可以大大加快推理过程。
在一些序列生成任务中,如神经机器翻译和音频合成,研究了非自回归生成。我们的FastSpeech与上述工作的区别在于两个方面:1)以前的工作主要是在神经机器翻译或音频合成中采用非自回归生成来提高推理速度,而FastSpeach则侧重于推理速度和提高TTS中合成语音的鲁棒性和可控性。2) 对于TTS,尽管Parallel WaveNet、ClariNet和WaveGlow并行生成音频,但它们以mel频谱图为条件,这些频谱图仍然是自回归生成的。
因此,它们没有解决这项工作中所考虑的挑战。有一项并行工作也并行生成了mel谱图。然而,它仍然采用具有注意力机制的编码器-解码器框架,1)与教师模型相比,需要2~3倍的模型参数,从而实现比FastSpeech慢的推理加速;2) 不能完全解决单词跳跃和重复的问题,而FastSpeech几乎消除了这些问题。
FastSpeech
在本节中,我们将介绍FastSpeech的架构设计。为了并行生成目标融合谱图序列,我们设计了一种新的前馈结构,而不是使用大多数基于序列到序列的自回归和非自回归生成所采用的基于编码器-注意力-解码器的架构。FastSpeech的整体模型架构如图1所示。我们将在以下小节中详细描述这些组件。
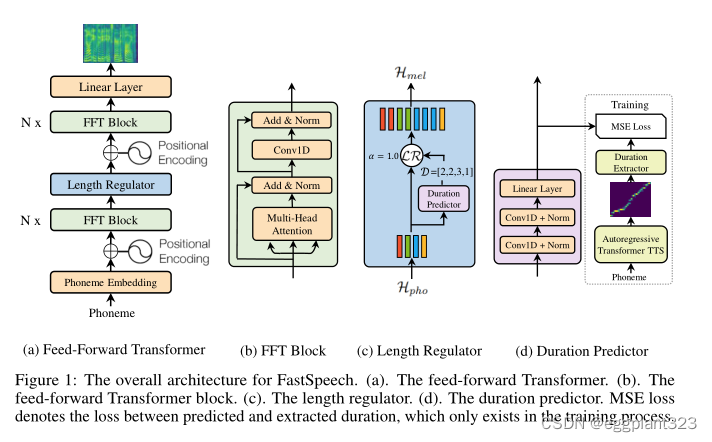
Feed-Forward Transformer
FastSpeech的架构是一种基于Transformer和1D卷积中的自注意的前馈结构。我们将这种结构称为前馈变换器(FFT),如图1a所示。前馈transformer堆叠用于音素到mel声谱图变换的多个FFT块,在音素侧上有N个块,在mel声纹图侧上有N个块,其间有长度调节器(将在下一小节中描述),以桥接音素和mel声韵图序列之间的长度间隙。
每个FFT块由一个自注意和1D卷积网络组成,如图1b所示。自注意网络由多头注意组成,用于提取交叉位置信息。与Transformer中的2层dense网络不同,我们使用了具有ReLU激活的2层1D卷积网络。其动机是,在语音任务中,相邻的隐藏状态在字符/音素和mel声谱图序列中关系更密切。我们在实验部分评估了1D卷积网络的有效性。继Transformer之后,在自注意网络和1D卷积网络之后分别添加了残差连接、层归一化和丢弃。
Length Regulator
长度调节器用于解决前馈变换器中音素和声谱图序列之间的长度不匹配问题,以及控制语速和部分韵律。一个音素序列的长度通常小于其mel声谱图序列的长度,并且每个音素对应于几个mel声纹图。我们将对应于一个音素的mel声谱图的长度称为音素持续时间(我们将在下一小节中描述如何预测音位持续时间)。基于音素持续时间d,长度调节器将音素序列的隐藏状态扩展d次,然后隐藏状态的总长度等于mel声谱图的长度。
将音素序列的隐藏状态表示为
H
p
h
o
=
[
h
1
,
h
2
,
…
,
h
n
]
\mathcal{H}_{p h o}=\left[h_{1}, h_{2}, \ldots, h_{n}\right]
Hpho=[h1,h2,…,hn]其中n是序列的长度。将音素持续时间序列表示为
D
=
[
d
1
,
d
2
,
…
,
d
n
]
\mathcal{D}=\left[d_{1}, d_{2}, \ldots, d_{n}\right]
D=[d1,d2,…,dn],其中
∑
i
=
1
n
d
i
=
m
\sum_{i=1}^{n} d_{i}=m
∑i=1ndi=m,
m
m
m是mel声谱图序列的长度。
H
mel
=
L
R
(
H
pho
,
D
,
α
)
,
\mathcal{H}_{\text {mel }}=\mathcal{L R}\left(\mathcal{H}_{\text {pho }}, \mathcal{D}, \alpha\right),
Hmel =LR(Hpho ,D,α),
其中,
α
\alpha
α是用于确定扩展序列
H
m
e
l
\mathcal{H}_{m e l}
Hmel的长度的超参数,从而控制语音速度。例如,给定
H
p
h
o
=
[
h
1
,
h
2
,
h
3
,
h
4
]
\mathcal{H}_{p h o}=\left[h_{1}, h_{2}, h_{3}, h_{4}\right]
Hpho=[h1,h2,h3,h4]并且对应的音素持续时间序列
D
=
[
2
,
2
,
3
,
1
]
\mathcal{D}=[2,2,3,1]
D=[2,2,3,1],如果
α
=
1
\alpha=1
α=1(正常速度),则基于等式1的扩展序列
H
mel
\mathcal{H}_{\text {mel }}
Hmel 变为
[
h
1
,
h
1
,
h
2
,
h
2
,
h
3
,
h
3
,
h
3
,
h
4
]
\left[h_{1}, h_{1}, h_{2}, h_{2}, h_{3}, h_{3}, h_{3}, h_{4}\right]
[h1,h1,h2,h2,h3,h3,h3,h4]。
当α=1.3(低速)和0.5(高速)时,持续时间序列变为
α
=
1.3
\alpha=1.3
α=1.3和
α
=
0.5
\alpha=0.5
α=0.5 ,
D
α
=
1.3
=
[
2.6
,
2.6
,
3.9
,
1.3
]
≈
\mathcal{D}_{\alpha=1.3}=[2.6,2.6,3.9,1.3] \approx
Dα=1.3=[2.6,2.6,3.9,1.3]≈
[
3
,
3
,
4
,
1
]
[3,3,4,1]
[3,3,4,1] 和
D
α
=
0.5
=
[
1
,
1
,
1.5
,
0.5
]
≈
[
1
,
1
,
2
,
1
]
\mathcal{D}_{\alpha=0.5}=[1,1,1.5,0.5] \approx[1,1,2,1]
Dα=0.5=[1,1,1.5,0.5]≈[1,1,2,1] 扩展序列分别变为
[
h
1
,
h
1
,
h
1
,
h
2
,
h
2
,
h
2
,
h
3
,
h
3
,
h
3
,
h
3
,
h
4
]
\left[h_{1}, h_{1}, h_{1}, h_{2}, h_{2}, h_{2}, h_{3}, h_{3}, h_{3}, h_{3}, h_{4}\right]
[h1,h1,h1,h2,h2,h2,h3,h3,h3,h3,h4] and
[
h
1
,
h
2
,
h
3
,
h
3
,
h
4
]
\left[h_{1}, h_{2}, h_{3}, h_{3}, h_{4}\right]
[h1,h2,h3,h3,h4]。我们还可以通过调整句子中空格字符的持续时间来控制单词之间的中断,从而调整合成语音的部分韵律。
Duration Predictor
音位持续时间预测对于长度调节器来说是重要的。如图1d所示,持续时间预测器由一个具有ReLU激活的2层1d卷积网络组成,每个网络后面都是层归一化和丢弃层,以及一个额外的线性层来输出标量,这正是预测的音素持续时间。注意,该模块堆叠在音素侧的FFT块的顶部,并且与FastSpeech模型联合训练以预测具有均方误差(MSE)损失的每个音素的mel声谱图的长度。我们在对数域中预测长度,这使它们更具高斯性,更容易训练。注意,训练的持续时间预测器仅用于TTS推理阶段,因为我们可以在训练中直接使用从自回归教师模型中提取的音素持续时间(见以下讨论)。
为了训练持续时间预测器,我们从自回归教师TTS模型中提取基本事实音素持续时间,如图1d所示。我们将详细步骤描述如下:
- 我们首先训练一个基于自回归编码器-注意力-解码器的Transformer TTS模型,如下所示
- 对于每个训练序列对,我们从训练的教师模型中提取解码器到编码器的注意力对齐。由于多头自注意,存在多个注意对齐,并且并非所有的注意头都表现出对角线性质(音素和mel声谱图序列是单调对齐的)。我们提出了一个聚焦率 F F F来测量注意力头部如何接近对角线: F = 1 S ∑ s = 1 S max 1 ≤ t ≤ T a s , t F=\frac{1}{S} \sum_{s=1}^{S} \max _{1 \leq t \leq T} a_{s, t} F=S1∑s=1Smax1≤t≤Tas,t其中, S S S和 T T T是基本事实声谱图和音素的长度,因为, T T T表示关注矩阵的第 S S S行和第 T T T列中的元素。我们计算每个头部的聚焦率,并选择具有最大F的头部作为注意力对齐。
- 最后,我们根据持续时间提取器 D = [ d 1 , d 2 , … , d n ] \mathcal{D}=\left[d_{1}, d_{2}, \ldots, d_{n}\right] D=[d1,d2,…,dn]提取音素持续时间序列 d i = ∑ s = 1 S [ arg max t a s , t = i ] d_{i}=\sum_{s=1}^{S}\left[\arg \max _{t} a_{s, t}=i\right] di=∑s=1S[argmaxtas,t=i].。也就是说,一个音素的持续时间是根据在上述步骤中选择的注意力头部而关注的mel声谱图的数量。
Experimental Setup
Datasets
我们在LJSpeech数据集上进行了实验,该数据集包含13100个英语音频片段和相应的文本转录本,总音频长度约为24小时。我们将数据集随机分为3组:12500个样本用于训练,300个样本用于验证,300个样品用于测试。为了缓解发音错误问题,我们使用内部字形到音素转换工具将文本序列转换为音素序列,如下所示。
对于语音数据,我们将原始波形转换为mel频谱图,如下所示。我们的帧大小和hop size 大小分别设置为1024和256。
为了评估我们提出的FastSpeech的稳健性,我们还按照中的实践,选择了50个对TTS系统特别困难的句子。
Model Configuration
FastSpeech model
我们的FastSpeech模型由音素side和梅尔声谱图side的6个FFT块组成。音素词汇的大小是51,包括标点符号。
FFT块中的音素嵌入的维度、self-attention的隐藏大小和1D卷积都被设置为384。attention head的数量设置为2。2层卷积网络中的1D卷积的核大小都设置为3,第一层的输入/输出大小为384/1536,第二层的输出大小为1536/384。输出线性层将384维隐藏转换为80维mel光谱图。在我们的持续时间预测器中,1D卷积的核大小被设置为3,两层的输入/输出大小都为384/384。
Autoregressive Transformer TTS model
自回归Transformer TTS模型在我们的工作中有两个目的:1)提取音素持续时间作为训练持续时间预测器的目标;2) 以在序列级知识蒸馏(sequence-level knowledge distillation )中生成mel谱图(将在下一小节中介绍)。我们参考了解该模型的配置,该模型由6层编码器和6层解码器组成,只是我们使用1D卷积网络而不是位置FFN。
这个教师模型的参数数量与我们的FastSpeech模型相似。
Training and Inference
我们首先在4个NVIDIA V100 GPU上训练自回归Transformer TTS模型,每个GPU上的批量大小为16句。我们使用Adam优化器,其中
β
1
\beta 1
β1 =0.9,
β
2
\beta 2
β2=0.98,
ε
ε
ε=10−9,并遵循中相同的学习率计划。训练需要80k步,直到收敛。我们将训练集中的文本和语音对再次馈送到模型中,以获得编码器-解码器注意力对齐,用于训练持续时间预测器。此外,我们还利用在非自回归机器翻译中取得良好性能的序列级知识提取,将知识从教师模型转移到学生模型。
对于每个源文本序列,我们使用自回归Transformer TTS模型生成mel声谱图,并将源文本和生成的mel声纹图作为FastSpeech模型训练的配对数据。
我们将FastSpeech模型与持续时间预测器一起训练。FastSpeech的优化器和其他超参数与自回归Transformer TTS模型相同。FastSpeech模型训练在4个NVIDIA V100 GPU上需要大约80k步。在推理过程中,我们的FastSpeech模型的输出mel频谱图使用预训练的WaveGlow (vocoder)转换为音频样本
Results
在本节中,我们评估了FastSpeech在音频质量、推理加速、鲁棒性和可控性方面的性能。
Audio Quality
我们对测试集进行MOS(平均意见得分)评估,以测量音频质量。我们保持不同模型之间的文本内容一致,以排除其他干扰因素,只检查音频质量。每个音频至少有20名测试人员收听,他们都以英语为母语。我们将FastSpeech模型生成的音频样本的MOS与其他系统进行了比较,这些系统包括:1)GT,ground-truth;2) GT(Mel+WaveGlow),其中我们首先将ground-truth音频转换为Mel频谱图,然后使用WaveGlove将Mel频谱转换回音频;3) Tacotron 2(Mel+WaveGlow);4) transformer TTS(Mel+WaveGlow)。5) Merlin(WORLD),一种以WORLD为声码器的流行参数TTS系统。结果如表1所示。可以看出,我们的FastSpeech几乎可以与Transformer TTS模型和Tacotron 2 6的质量相匹配。

Inference Speedup
与自回归Transformer TTS模型相比,我们评估了FastSpeech的推理延迟,该模型的模型参数数量与FastSpeech相似。
我们首先在表2中显示了mel谱图生成的推理加速。可以看出,与Transformer TTS模型相比,FastSpeech将mel声谱图的生成速度提高了269.40倍。然后,我们展示了使用WaveGlow作为声码器时的端到端加速。可以看出,FastSpeech在音频生成方面仍然可以实现38.30倍的加速。
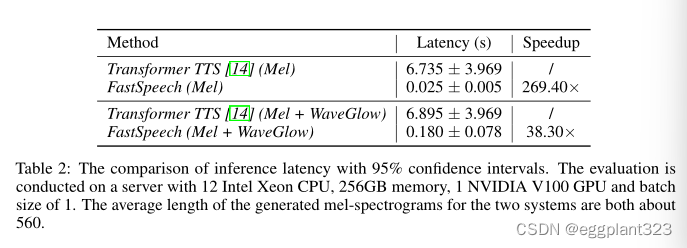
我们还可视化了推理延迟和测试集中预测的融合谱图序列长度之间的关系。图2显示,对于FastSpeech,推理延迟几乎不会随着预测的mel声谱图的长度而增加,而在Transformer TTS中则大幅增加。这表明,由于并行生成,我们的方法的推理速度对生成的音频的长度不敏感。
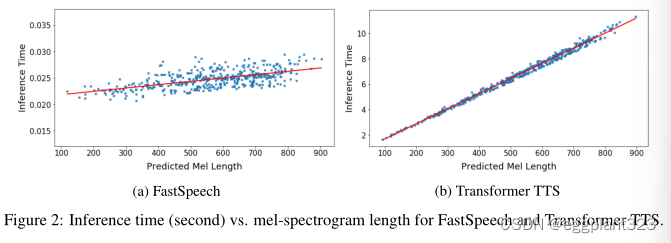
Robustness
自回归模型中的编码器-解码器注意力机制可能导致音素和mel声谱图之间的错误注意力对齐,导致单词重复和单词跳跃的不稳定性。为了评估FastSpeech的稳健性,我们选择了50个对TTS系统来说特别困难的句子。表3列出了单词错误计数。可以看出,Transformer TTS对这些困难情况并不鲁棒,错误率为34%,而FastSpeech可以有效地消除单词重复和跳跃,以提高清晰度。
Length Control
如第3节所述。FastSpeech可以通过调整音素持续时间来控制语音速度和部分韵律,这是其他端到端TTS系统无法支持的。我们展示了长度控制前后的mel频谱图,并将音频样本放在补充材料中供参考。
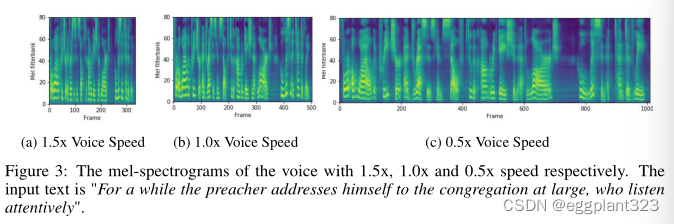
Voice Speed
通过延长或缩短音素持续时间生成的具有不同语速的mel声谱图如图3所示。我们还在补充材料中附上了几个音频样本供参考。如示例所示,FastSpeech可以平稳地将语音速度从0.5倍调整到1.5倍,音调稳定且几乎不变。
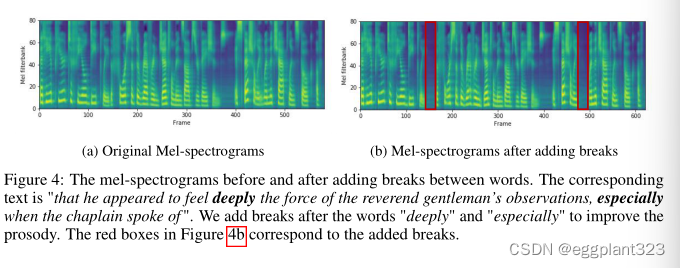
Breaks Between Words
FastSpeech可以通过延长句子中空格字符的持续时间来增加相邻单词之间的中断,从而提高语音的韵律。我们在图4中展示了一个例子,其中我们在句子的两个位置添加了中断,以提高韵律。
Ablation Study
我们进行了消融研究,以验证FastSpeech中几个组件的有效性,包括1D卷积和序列级知识提取。我们对这些消融研究进行CMOS评估。

1D Convolution in FFT Block
如第3.1节所述,我们建议用FFT块中的1D卷积替换原始的全连接层(在Transformer中采用)。在这里,我们进行实验,将1D卷积的性能与具有相似参数数量的全连接层进行比较。如表4所示,用全连通层代替1D卷积的结果为-0.113。CMOS,证明了1D卷积的有效性.
Sequence-Level Knowledge Distillation
如第4.3节所述,我们利用FastSpeech的序列级知识提取。我们进行了CMOS评估,以比较有序列级知识提取和没有序列级知识蒸馏的FastSpeech的性能,如表4所示。我们发现,去除序列级知识蒸馏的结果为-0.325。CMOS,证明了序列级知识提取的有效性。
Conclusions
在这项工作中,我们提出了FastSpeech:一个快速、鲁棒和可控的神经TTS系统。
FastSpeech有一个新的前馈网络来并行生成mel频谱图,该网络由几个关键组件组成,包括前馈变压器块、长度调节器和持续时间预测器。在LJSpeech数据集上的实验表明,我们提出的FastSpeech在语音质量方面几乎可以与自回归Transformer TTS模型相匹配,将mel声谱图的生成速度提高了270倍,端到端语音合成速度提高了38倍,几乎消除了单词跳跃和重复的问题,并且可以平滑地调整语速(0.5x-1.5x)。
对于未来的工作,我们将继续提高合成语音的质量,并将FastSpeech应用于多speaker和低资源设置。我们还将与并行神经声码器联合训练FastSpeech,使其完全端到端并行。

















 1120
1120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









