







 本文介绍了排序算法的基础知识,包括排序的目的和常见基于比较的排序算法,如插入排序、归并排序和堆排序。讨论了这些算法的时间复杂度,其中归并排序和快速排序采用了分治思想。尽管快速排序在最坏情况下时间复杂度为O(n^2),但其平均性能优越,常用于实际应用中。
本文介绍了排序算法的基础知识,包括排序的目的和常见基于比较的排序算法,如插入排序、归并排序和堆排序。讨论了这些算法的时间复杂度,其中归并排序和快速排序采用了分治思想。尽管快速排序在最坏情况下时间复杂度为O(n^2),但其平均性能优越,常用于实际应用中。
排序是基础且重要的问题,排序算法有几十种,可以证明,有些算法是渐进最优的。那为什么还会存在一些不那么快的算法呢?快慢是从时间尺度来衡量的,空间呢?那些运行很快的排序算法,需要多大的空间呢?排序是不是稳定的呢?如果不是,转化为稳定的排序,又需要多少额外的时间和空间呢?
每种算法各有千秋,不存在任何方面都最优的算法,只有限定条件下的最优解,而这也正是我们努力想要求得的。
什么是排序:
- 输入:长度为n的序列
- 输出:长度为n的非降序列
为什么要进行排序:
- 产生有序的输
- 为另一程序做一些前期准备(如二分查找)
排序算法可分为基于比较的排序和线性时间排序(至少要遍历所有元素)。常见的基于比较排序的算法有:冒泡排序、选择排序、插入排序、归并排序、堆排序、快速排序等。任何一种基于比较的排序算法都可以用决策树模型来描述。
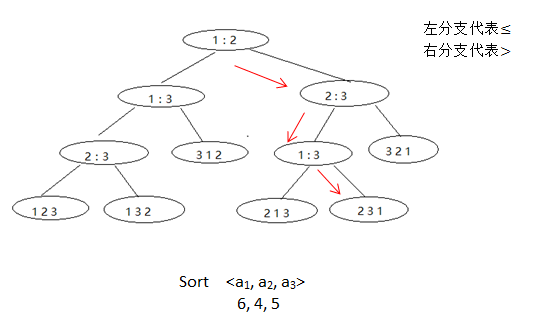
决策树每一个叶节点代表一种可能的排序结果,n个数字(没有重复)的全排列共有n!种情况,因此决策树叶节点数量大于等于n!,又因为简单决策树是二叉树,所以叶节点的数量小于等于 2h (h为树的高度)n! ≤ #leaves ≤ 2h ,由斯特林公式可得h ≥ n logn2 (斯特林公式是对阶乘的近似估计,渐进情况下可简记为:n! = nn )。
结论:
所有基于比较的排序最坏情况下的下界为nlogn。
插入排序:
伪码:
for j = 2 to n
key = A[j]
i = j – 1
while i > 0 and A[i] > key
A[i+1] = A[i]
i = i – 1
A[i+1] = key
运行时间:
- 最坏情况:输入逆序 T(n)=∑j=2nθ(j)=θ(n2)
归并排序::
步骤:
Merge sort A[1,…,n]
- If n = 1, done
- Recursively sort A[1,…,⌈n/2⌉] and A[⌈n/2⌉+1,n]
- Merge 2 sorted lists
关键:
- 归并:
在每一步中,只关注两个数组的首元素,挑选出更小的,然后把数组指针前移一位,每一步只需常数时间,与数组规模无关Time = θ(n)
归并伪码:
Merge(lo, mi, hi) //A[lo, hi)
mi = (lo + hi) / 2
l = mi - lo L = A[0, mi)
Let L[0, m) be new array //开辟原数组一半的额外空间
for j to l -1
L[j] = A[j]
for j = 0 to l or k = mi to hi
if j < l and (hi <= k or L[j] <= A[k]) //L[j] <= A[k]中的"<="以及下一个if语句中的[k] < L[j]中的“<”保证了归并排序的稳定性
A[i++] = L[j++]
if k < hi and (l <= j or A[k] < L[j])
A[i++] = A[k++]
T(n) = θ(1) + 2T(n/2) +θ(n)
递归树:
T(n) = 2T(n/2) + cn c > 0 用cn显式地替换掉了隐式的θ(n)
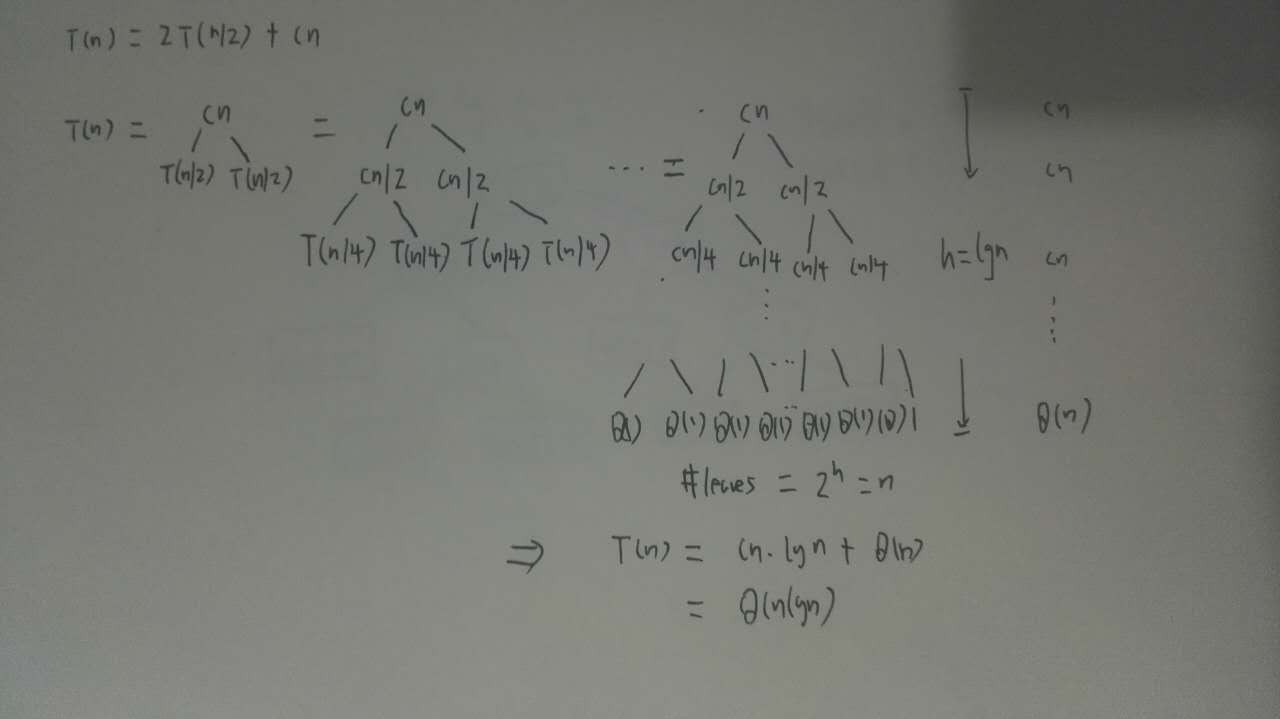
由递归树可得归并排序的运行时间: T(n)=θ(nlogn)
堆排序:
插入排序和归并排序的时间复杂度分别是 O(n2) 、 O(nlogn) ,显然归并排序更快,但是归并排序需要额外开辟空间,而插入排序是原址的(只需要常数个额外空间存储临时数据)。有没有集合这两种排序算法优点的算法呢?堆排序便是一种。
堆排序需要借助一种被称为“堆”的数据结构,堆不仅可以用于堆排序,还可以构造优先队列。
堆具有两种特性:
- 结构性:逻辑上,等同于完全二叉树; 物理上,直接借助数组实现
- 堆序性:物理上,直接借助数组实现; 数值上,父节点大于等于子节点的值
二叉堆的结构性,决定了它可以用数组隐性表示。任一节点其父节点和左右子节点,都可以由自身索引唯一、明确得到。以数组A[1,…,n]为例,A[i]父节点为A[i/2],左子节点和右子节点分别为A[2i]和A[2i+1](动手画一棵完全二叉树,仔细观察,不难发现此规律)。
堆排序的原理:
算法输入是数组A[1,…,n]。首先将数组排列成堆,A[1]为数组中的最大元素,交换A[1]和A[n]。然后考察数组A[1,…,n-1],将数组重新排列成堆,交换A[1]和A[n-1]。接着考察A[1,…,n-2],重复上述过程,直至排序完毕。总的来说,堆排序包括一次初始建堆过程,n-1次交换和重排成堆。
堆排序的关键:建堆
1. 自上而下的上滤法,对应着自左向右扫描数组
2. 自下而上的下滤法,对应着自右向左扫描数组
自上而下的上滤法:最坏情况下,需要上滤所有节点的深度和 只考虑叶节点:深度均为 O(logn) ,累计耗时 O(nlogn)
自下而上的下滤法:最坏情况下,需要下滤所有节点的高度和 记H(i)高度为i的完全二叉树所有节点的高度之和。将高度为i的树看作是两棵高度为i-1的树和一个高度为i的节点,于是有H(i) = 2H(i-1) + i; 仿照图2画出递归树,应用一个小技巧,从底层往上累加求和:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









