







今天,腾讯在AI视频创作领域交出了自己的“考卷”,腾讯混元文生视频正式上线。
我试用了下,发现其交互操作比较简便,用户无需注册,只需通过手机短信验证码即可快速登录。
进入平台后,界面直观简洁,操作一目了然。
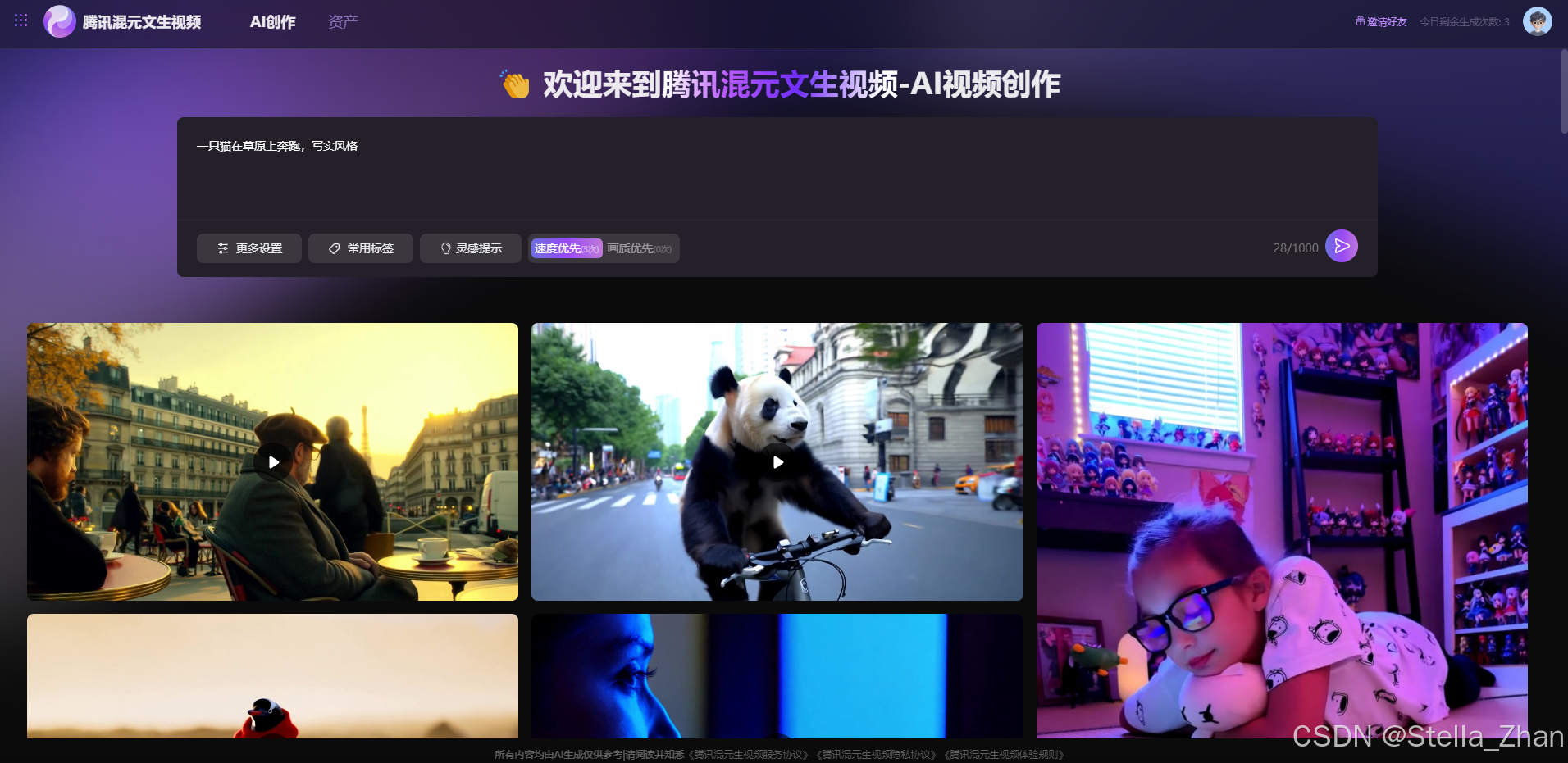
你只需在文本框内输入想要的视频内容的文字描述,点击发布按钮,就可以生成你想要的视频。
在操作界面上,有几个选项供用户根据需求进行配置:
-
“速度优先”或者“画质优先”:用户可以根据自己的需求点击相应按钮进行选择。

需要注意的是,“画质优先”模式的试用次数为2次,而“速度优先”模式的试用次数为4次。生成的视频将会保存在资产页面,方便后续查看。
![]()
-
点击更多设置,你还可以进行更详细的调整:
-
视频比例选择:16:9、9:16、1:1、4:3、3:4(可以根据视频展现的载体进行选择
-
是否启用Prompt增强:你可以选择是否开启该功能,以进一步优化生成效果。、
-
效果偏向性:可以选择生成风格,比如“流畅运镜”、 “动作丰富”或“导演模式”,从而根据期望的风格定制视频内容。
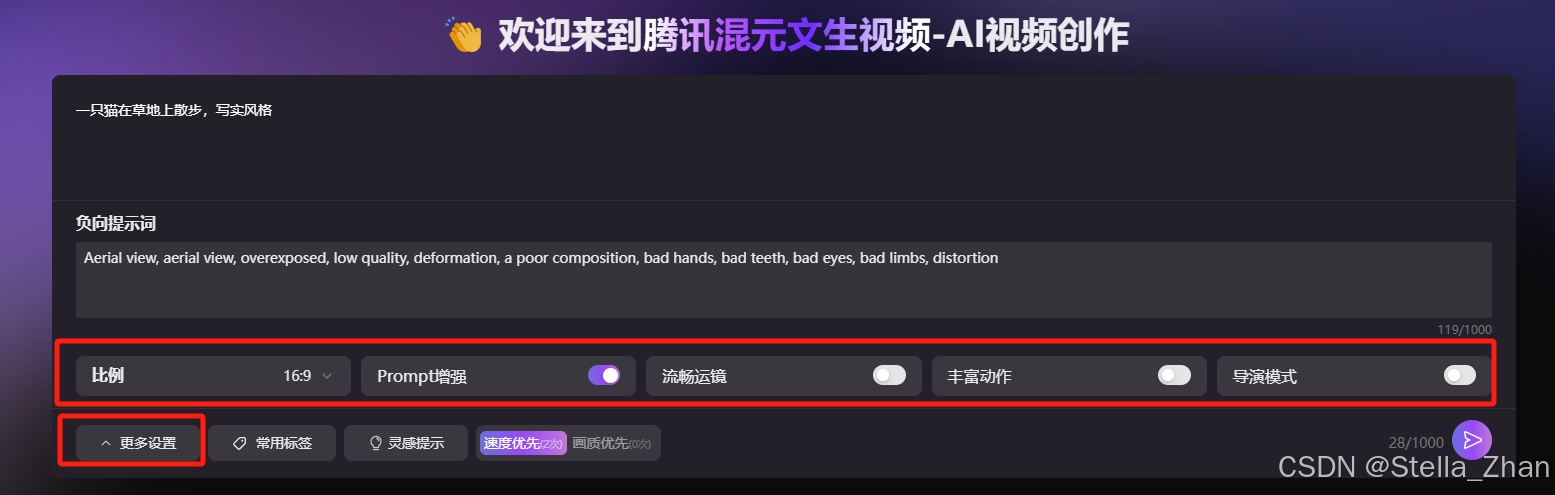
从我的体验来看,生成的视频效果比较写实且自然,AI感相对较弱,整体效果不错。要获得最佳体验,用户需要精准描述自己的需求,并选择合适的设置。

















 1477
1477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









