







交叉验证既可以解决数据集的数据量不够大问题,也可以解决参数调图优的问题。这块主要有三种方式:简单交叉验证(HoldOut检验)、k折交叉验证(k-fold交叉验证)、自助法。该文仅针对k折交叉验证做详解。
1、简单交叉验证(HoldOut检验)
方法
将原始数据集随机划分成训练集和验证集两部分。比如说,将样本安照70%~30%的比例分成两部分,70%的样本用于训练模型;30%的样本用于模型验证
缺点
- 数据都只被所用了一次,没有被充分利用
- 在验证集上计算出来的最后的评估指标与原始分组有很大关系
2、k折交叉验证(k-fold交叉验证)
为了解决简单交叉验证的不足,提出k-fold交叉验证
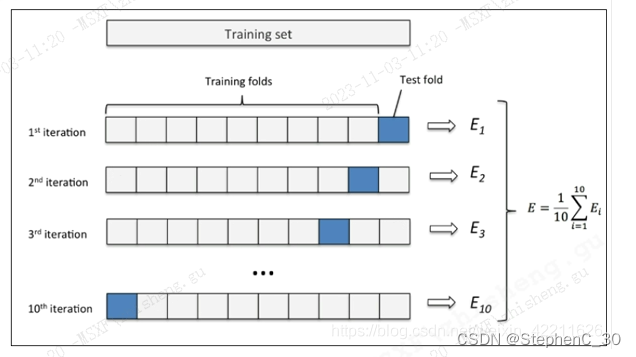
- 首先,将全部样本划分成k个大小相等的样本子集
- 依次遍历这k个子集,每次把当前子集作为验证集,其余所有样本作为训练集,进行模型的训练和评估
- 最后把k次评估指标的平均值作为最终的评估指标。在实际实验中,k通常取10
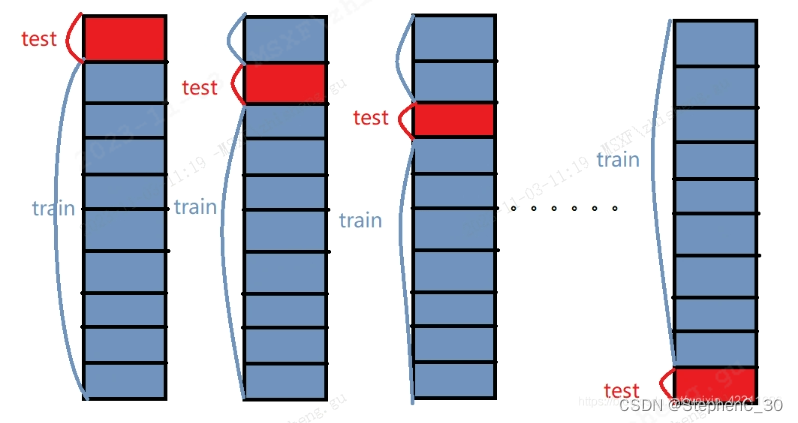
- 举个例子:这里取k=10,如下图所示:
- 先将元数据集分成10份
- 每一次,将其中一份作为测试集,剩下9个作为训练集
- 最后计算k次求得的分类率的平均值,作为该模型或者假设函数的真实分类率
K折交叉验证python实现
# K折交叉检验
def printing_Kfold_scores(x_train_data,y_train_data):
'''
x_train_data:训练集特征值
y_train_data:训练集标签
'''
#k-fold表示K新的交叉验证,会得到满个*素引*集合:训练集=indicess[0],验证集=indices[1]
#shuffle:是否打乱顺序进行样本划分
fold = KFold(n_splits=10, shuffle=True, random_state=0)
recall_accs = []
for iteration, indices in enumerate(fold.split(x_train_data)):
'''
1、实例化算法模型,指定L1正则化(逻辑回归)
2、L1正则化可以看做是损失函数的惩罚项,可产生稀就权值矩阵,即产生一个稀疏模型用于特征选择(各特征对横型的贡献度是不一样的,有的特征正页献大,有的特征贡献小)。
3、C是正则化系数,通过控制C来调整惩罚力度
'''
lr = LogisticRegression(C=0.08, penalty='ll',solver='liblinear')
# 支持向量机分类器(用于验证的另外分类器模型)
# lr=svm.SVC(kernel='linear')
# 训练模型,传入的是训练集,所以x和v的索引都是0
lr.fit(x_train_data.iloc[indices[0],:], y_train_data.iloc[indices[0],:]['label'])
# 建模后,预测楼型结果,这里用的是验证集,索引为1
y_pred_undersample = lr.predict(x_train_data.iloc[indices[1],:])
# 评估召回率,需要传入真实值和预测值
recall_acc = round(recall_score(y_train_data.iloc[indicess[1],:].values, y_pred_undersample),4)
recall_accs.append(recall_acc)
print('第', iteration+1, '次选代:召回率=', recall_acc)
# 当执行完交叉验证后,计算平均结果
print('平均召回率',round(np.mean(recall_accs),4))
return None
3、自助法
自助法是基于自助采样法的检验方法。对于总数为n的样本合集,进行n次有放回的随机抽样,得到大小为n的训练集。n次采样过程程中,有的样本会被重复采样,有的样本没有被抽出过,将这些没有被抽出的样本作为验证集,进行模型验证。
sklearn.model_selection.cross_val_score(estimator,
X,
y=None,
groups=None,
scoring=None,
CV='warn',
n_jobs=None,
verbose=0,
fit_params=None,
pre_dispatch='2*n_jobs',
error score='raise-deprecating')
- estimator:需要使用交叉验证的算法
- X:输入样本数据
- y:样本标签
- groups:将数据集分割为训练/测试集时使用的样本的组标签(一般用不到
- scoring:交叉验证最重要的就是他的验证方式,选择不同的评价方法,会产生不同的评价结果。具体可用哪些评价指标,下图中
- CV:交叉验证折数或可迭代的次数
- n jobs:同时工作的cpu个数(-1代表全部)
- verbose:详细程度
- fit_params:传递给估计器(验证算法)的拟合方法的参数
- pre_dispatch:控制并行执行期间调度的作业数量。减少这个数量对付于避免在CPU发送更多作业时CPU内存消耗的扩大是有用的。该参数可以是
- 没有,在这种情况下,所有的工作立即创建并产生。将其用于轻量级和快速运行的作业,以避免由于按需产生作业而导致延迟
- 一个int,给出所产生的总工作的确切数量
- 一个字符串,给出一个表达式作为njobs的函数,如'2*njobs
- error_score:如果在估计器拟合中发生错误,要分配给该分数的值(一般不需要指定)
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









