








专栏地址:目前售价售价69.9,改进点70+
专栏介绍:YOLOv9改进系列 | 包含深度学习最新创新,助力高效涨点!!!
本文对YOLOv9中出现的新模块进行整理
1. Silence模块
模块介绍:Silence是YOLOv9中便于辅助分支调用输入到网络中的原始img的模块,模块自身不进行运算,输出与输入无变化,模块代码:
class Silence(nn.Module):
def __init__(self):
super(Silence, self).__init__()
def forward(self, x):
return x2. RepNCSPELAN4模块
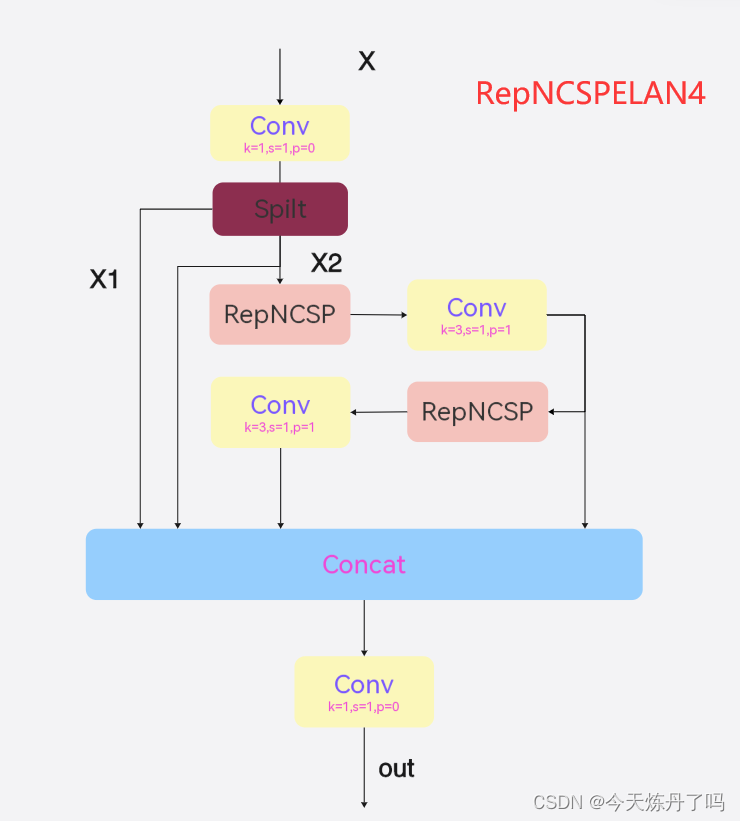
RepNCSPELAN4是YOLOv9中的特征提取-融合模块,类似前几代YOLO中的C3、C2f等模块。作者通过结合两种神经网络架构,即带有梯度路径规划的 CSPNet 和 ELAN,考虑轻量化、推理速度和准确性设计出的一种广义高效层聚合网络(GELAN),作者使用带有 CSPNet 块的 GELAN 替换了 ELAN,并 RepConv作为计算块。RepNCSPELAN4可拆分为RepN-CSP-ELAN4 ,代码及模块图如下:
class RepNCSPELAN4(nn.Module):
# csp-elan
def __init__(self, c1, c2, c3, c4, c5=1): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = c3//2
self.cv1 = Conv(c1, c3, 1, 1)
self.cv2 = nn.Sequential(RepNCSP(c3//2, c4, c5), Conv(c4, c4, 3, 1))
self.cv3 = nn.Sequential(RepNCSP(c4, c4, c5), Conv(c4, c4, 3, 1))
self.cv4 = Conv(c3+(2*c4), c2, 1, 1)
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend((m(y[-1])) for m in [self.cv2, self.cv3])
return self.cv4(torch.cat(y, 1))
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in [self.cv2, self.cv3])
return self.cv4(torch.cat(y, 1))
3. ADown模块
ADown是YOLOv9中的下采样模块,模块中使用卷积、平均池化、最大池化完成下采样操作,代码及结构图如下:
class ADown(nn.Module):
def __init__(self, c1, c2): # ch_in, ch_out, shortcut, kernels, groups, expand
super().__init__()
self.c = c2 // 2
self.cv1 = Conv(c1 // 2, self.c, 3, 2, 1)
self.cv2 = Conv(c1 // 2, self.c, 1, 1, 0)
def forward(self, x):
x = torch.nn.functional.avg_pool2d(x, 2, 1, 0, False, True)
x1,x2 = x.chunk(2, 1)
x1 = self.cv1(x1)
x2 = torch.nn.functional.max_pool2d(x2, 3, 2, 1)
x2 = self.cv2(x2)
return torch.cat((x1, x2), 1)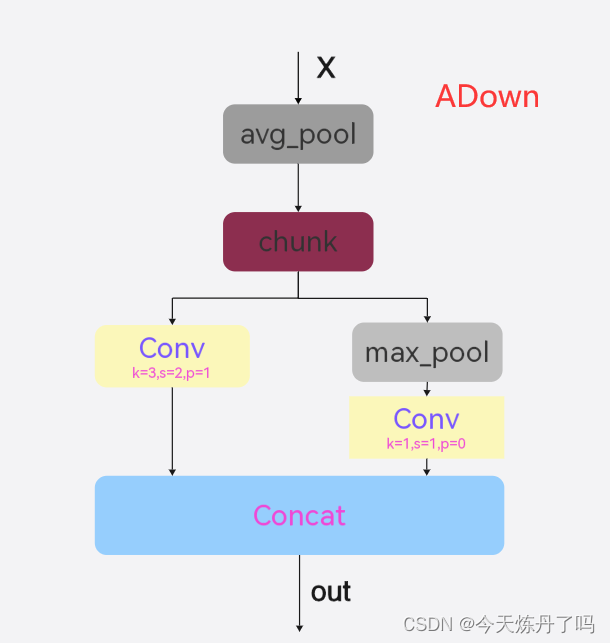
4. CBLinear模块
CBLinear是YOLOv9用于辅助分支的一个模块,包含一个卷积模块,将经过一次卷积后得到的张量拆分成包含为1-N个元素的元组,模块代码和结构如下:
class CBLinear(nn.Module):
def __init__(self, c1, c2s, k=1, s=1, p=None, g=1): # ch_in, ch_outs, kernel, stride, padding, groups
super(CBLinear, self).__init__()
self.c2s = c2s
self.conv = nn.Conv2d(c1, sum(c2s), k, s, autopad(k, p), groups=g, bias=True)
def forward(self, x):
outs = self.conv(x).split(self.c2s, dim=1)
return outs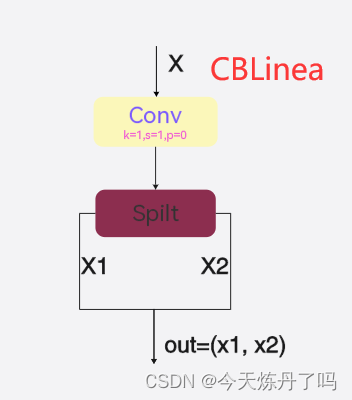
包含模块、卷积、检测头、损失等改进,目前已有70+!
⭐入手价$ 69.9,打造全站最具性价比的YOLOv9改进项目!⭐
⭐联系QQ: 2668825911 ,欢迎交流!⭐



















 835
835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









