








一、简介
前些天发布了YOLOv11,也是Ultralytics公司在之前的YOLO版本上推出的最新一代实时目标检测器,支持目标检测、追踪、实力分割、图像分类和姿态估计等任务。官方代码:ultralytics/ultralytics:ultralytics YOLO11 🚀 (github.com)![]() https://github.com/ultralytics/ultralytics
https://github.com/ultralytics/ultralytics
二、使用教程
2.1 准备代码
首先,点击上方链接进入YOLOv11的GitHub仓库,按照图示流程下载打包好的YOLOv11代码与预训练权重文件到本地。


下载完成后解压, 使用PyCharm(或VsCode等IDE软件)打开,并将下载的预训练权重拷贝到解压的工程目录下,下文以PyCharm为例。


2.2 准备数据集
Ultralytics版本的YOLO所需格式的数据集标签为txt格式的文本文件,文本文件中保存的标签信息分别为:类别序号、中心点x/y坐标、标注框的归一化信息,每一行对应一个对象。图像中有几个标注的对象就有几行信息。

自制数据集标注教程可看此篇文章:深度学习工具|LabelImg(标注工具)的安装与使用教程_labelimg安装-CSDN博客文章浏览阅读8.7k次,点赞15次,收藏66次。软件界面上包含了常用的打开文件、打开文件夹、更改保存路径、下一张/上一张图片、创建标注的格式、创建标注框等按钮,右侧显示从文件夹导入的文件列表、标签等信息。使用时可以进行如下设置,便于快速标注。_labelimg安装https://blog.csdn.net/StopAndGoyyy/article/details/139906637 如果没有自己的数据集,本文提供一个小型数据集(摘自SIMD公共数据集)以供测试代码,包含24张训练集以及20张测试集,约17.7MB,百度云链接:https://pan.baidu.com/s/1sCivMDjfAmUZK1J2P2_Dtg?pwd=1234
![]() https://pan.baidu.com/s/1sCivMDjfAmUZK1J2P2_Dtg?pwd=1234 下载完成后将提供的datasets文件夹解压并复制到工程路径下。
https://pan.baidu.com/s/1sCivMDjfAmUZK1J2P2_Dtg?pwd=1234 下载完成后将提供的datasets文件夹解压并复制到工程路径下。

创建 data.yaml文件保存数据集的相关信息,如果使用本文提供的数据集可使用以下代码:

# dataset path
train: ./images/train
val: ./images/test
test: ./images/test
# number of classes
nc: 15
# class names
names: ['car', 'Truck', 'Van', 'Long Vehicle','Bus', 'Airliner', 'Propeller Aircraft', 'Trainer Aircraft', 'Chartered Aircraft', 'Fighter Aircraft',\
'Others', 'Stair Truck', 'Pushback Truck', 'Helicopter', 'Boat']
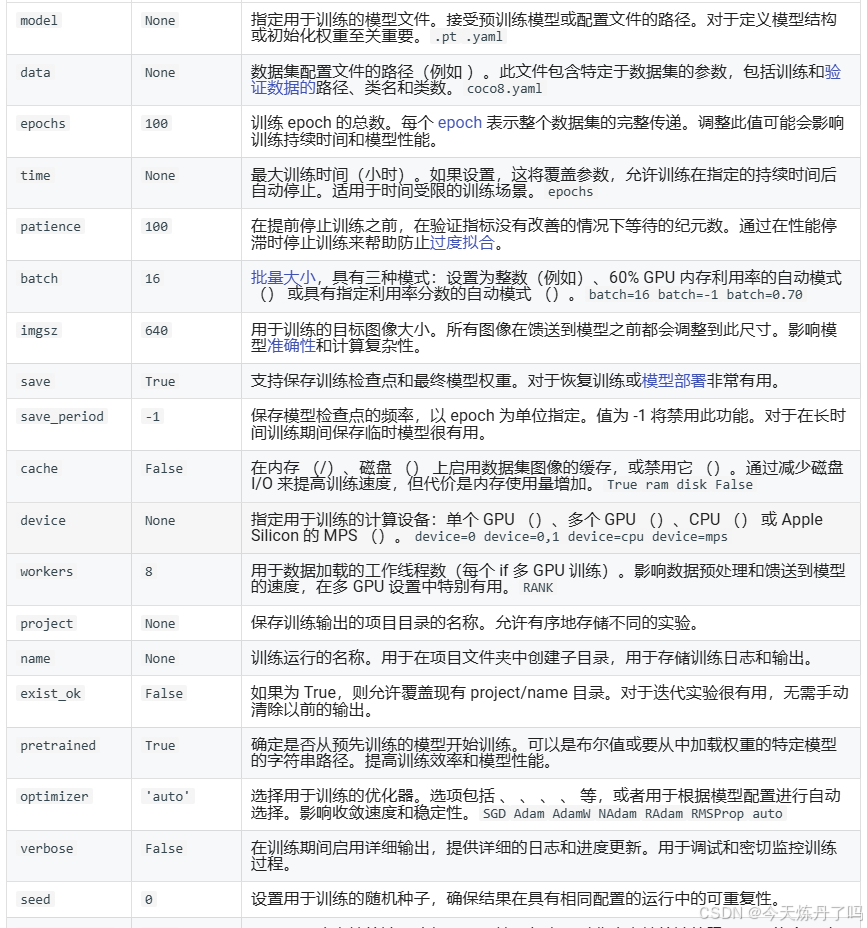
2.3 模型训练
创建train.py文件,依次填入以下信息。epochs=2表示只训练两轮,通常设置为100-300之间,此处仅测试两轮。batch=1表示每批次仅训练一张图片,可按显存大小调整batchsize,一般24g卡可设置为16-64。
from ultralytics.models import YOLO
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
if __name__ == '__main__':
model = YOLO(model='ultralytics/cfg/models/11/yolo11.yaml')
# model.load('yolov8n.pt')
model.train(data='./data.yaml', epochs=2, batch=1, device='0', imgsz=640, workers=2, cache=False,
amp=True, mosaic=False, project='runs/train', name='exp')


相关参数网址:https://docs.ultralytics.com/modes/train/#train-settings
选择安装好的torch环境,本文无torch环境的安装教程,可按照其他博主推文或视频安装torch环境。

待软件控制台打印如下信息即为运行成功。

训练完成后在runs/train文件夹下保存有训练好的权重及相关训练信息。

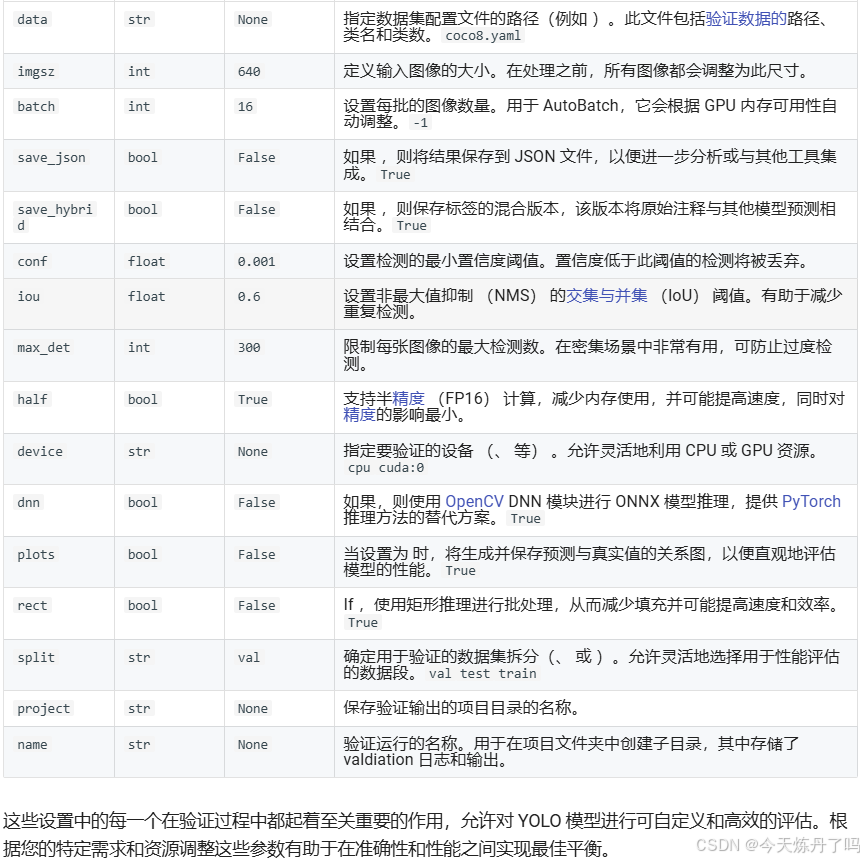
2.4 模型验证
在工程下创建val.py文件,填入刚才训练好的权重路径及相关信
from ultralytics.models import YOLO
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
if __name__ == '__main__':
model = YOLO(model='./run/train/exp/weights/best.pt')
model.val(data='./datasets/data.yaml', split='val', batch=1, device='0', project='run/val', name='exp',
half=False,)

运行即可获得该权重针对不同目标的性能指标。本文只测试2个epochs,且数据集较小,可能无相关信息。

正常信息如下图:

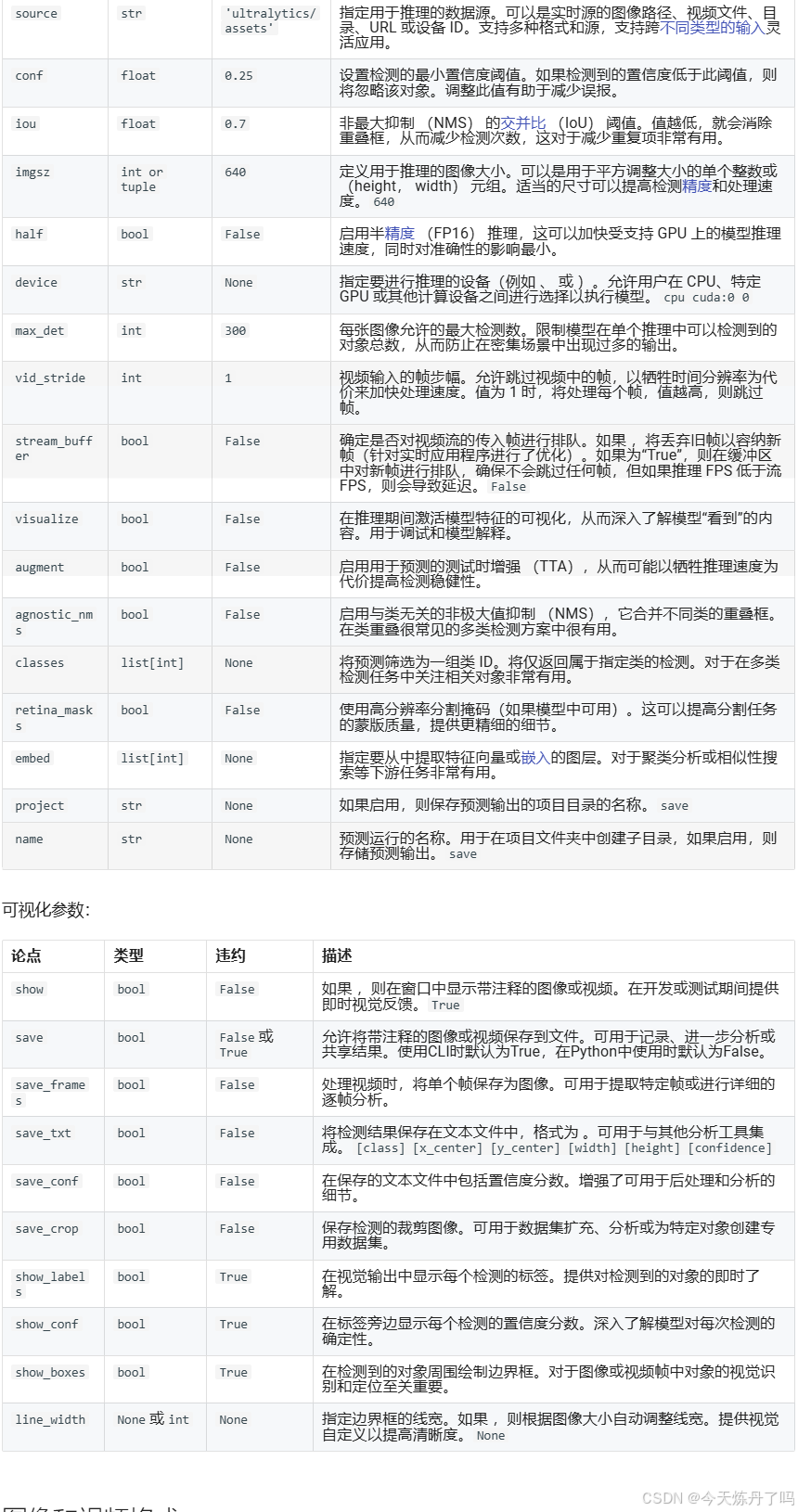
2.5 模型预测
创建detect.py文件,填入训练好的权重路径及要检测的图片信息。
from ultralytics.models import YOLO
if __name__ == '__main__':
model = YOLO(model='yolov8s.pt')
model.predict(source='', device='0', imgsz=640, project='runs/detect/', name='exp')

运行即可开始检测,本文训练次数较少,可能无法检测到目标,如图左。可通过使用完整数据集进行训练,增大epochs提高检测准确率。正常检测图片如图右。


2.6 模型导出
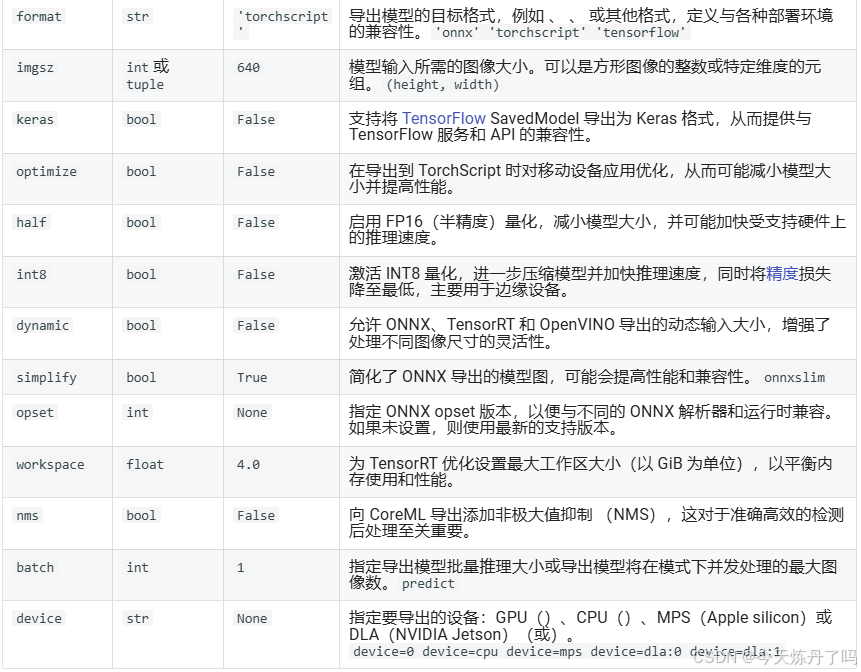
为便于部署,将模型进行导出为onnx\torchscript\tensorflow等格式。创建export.py脚本,填入想要导出的模型路径。
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11n.pt") # load an official model
# model = YOLO("path/to/best.pt") # load a custom trained model
# Export the model
model.export(format="onnx")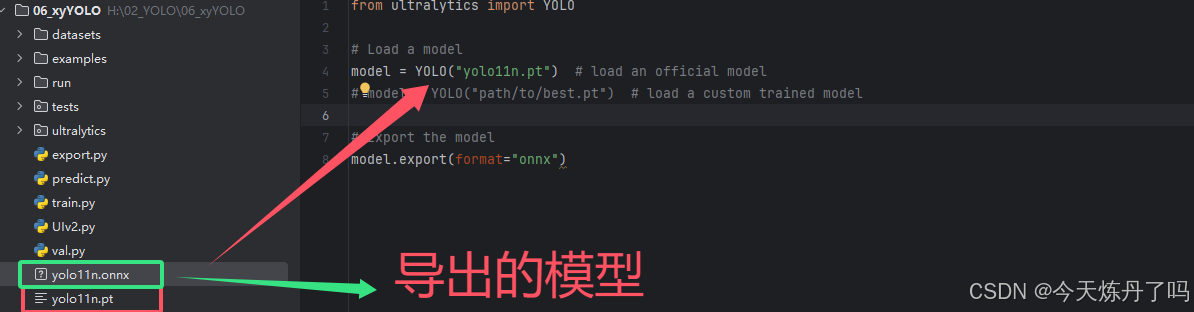
2.7 目标追踪
import cv2
from ultralytics import YOLO
# Load the YOLO11 model
model = YOLO("yolo11n.pt")
# Open the video file
# video_path = "path/to/video.mp4"
video_path = 0
cap = cv2.VideoCapture(video_path)
# Loop through the video frames
while cap.isOpened():
# Read a frame from the video
success, frame = cap.read()
if success:
# Run YOLO11 tracking on the frame, persisting tracks between frames
results = model.track(frame, persist=True)
# Visualize the results on the frame
annotated_frame = results[0].plot()
# Display the annotated frame
cv2.imshow("YOLO11 Tracking", annotated_frame)
# Break the loop if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
# Break the loop if the end of the video is reached
break
# Release the video capture object and close the display window
cap.release()
cv2.destroyAllWindows()至此,模型使用教程结束。
三、模型分析
YOLOv11的结构如下,在YOLOv8的基础上将C2f替换为C3K2模块,更改C3k2模块中子模块的重复次数,并在SPPF层之后增加C2PSA模块,其他结构改动较小(检测头增加两个DWConv卷积)。

其中YOLOv11网络及主要模块的可视化化结构如下图。
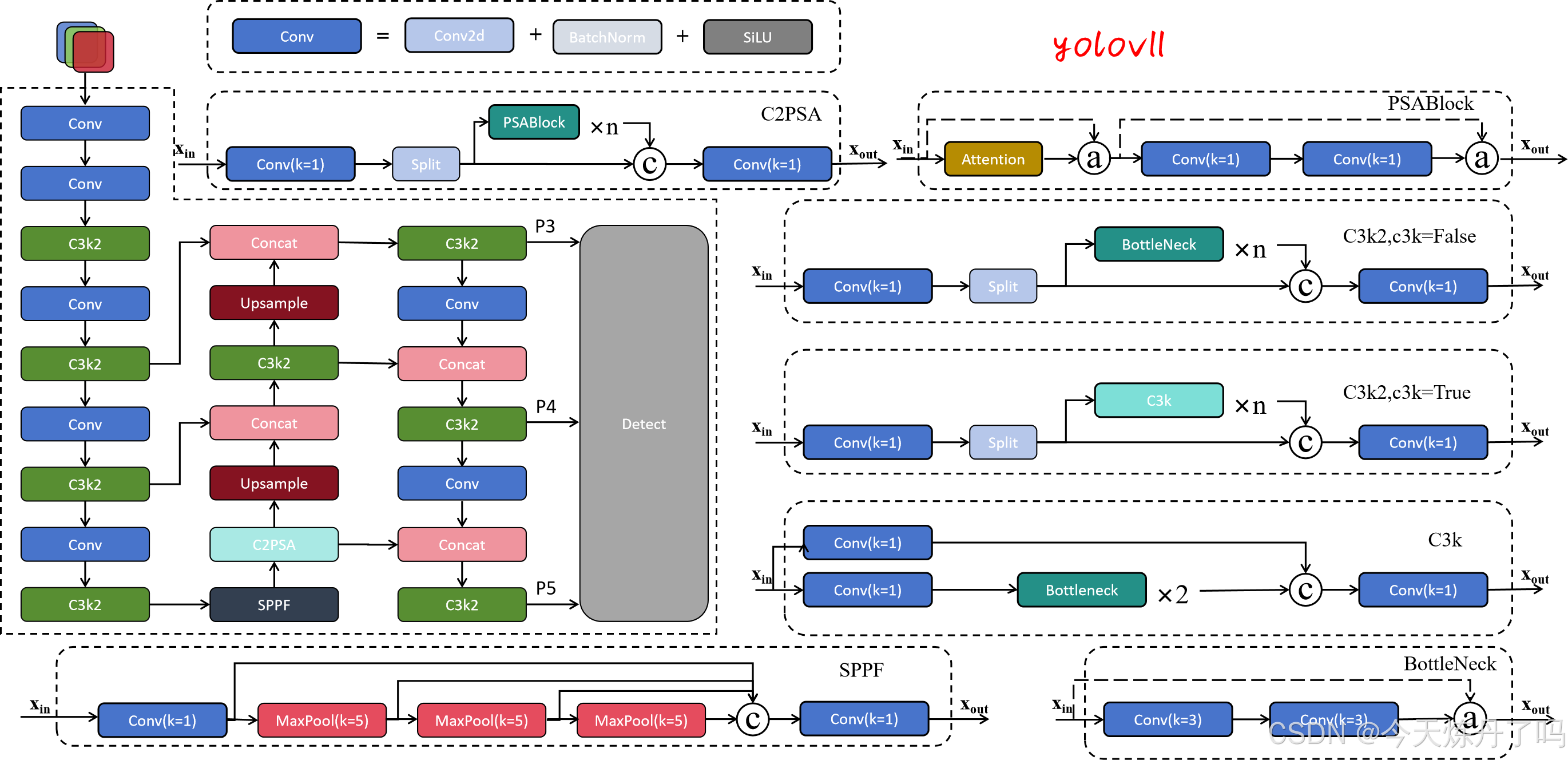
C3K2模块存在两种结构,将其中的C3k参数设置为False时等于C2f模块。
class C3k2(C2f):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
"""Initializes the C3k2 module, a faster CSP Bottleneck with 2 convolutions and optional C3k blocks."""
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(
C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck(self.c, self.c, shortcut, g) for _ in range(n)
)


C3k模块与C3模块区别为其中的BottleNeck个数,C3k为两个BottleNeck,C3默认1个,并按照模型缩放因子及重复个数变化。

C2PSA模块与C2f模块相似,结构如下:

四、博主自研模型(广告)
上文是YOLOv11的使用教程及模型分析,下文是博主的一点广告。如果你觉得YOLO日益频繁的更新频率太快或者使用人数太多,可以考虑博主的自研模型作为Baseline(2024/10/30日之前群内更新),使用人数更少,相对好发文,且在SIMD数据集上拥有与YOLOv11相差不多的性能,欢迎入群交流。后面本群将以此模型作为基线模型进行更新,结合今年顶刊定会模块,进行二创三创,并在SIMD数据集上进行测试调整好,预计每周都会更新(每月 四更,纯自研模块更新时间可能久一些),以下是测试结果图和我的QQ二维码。⭐上百种改进仅79.9,QQ:2668825911,欢迎交流⭐


此篇完


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









