







目录
5.改好网关和时间之后,找空白处,点击鼠标右键,打开Open in Terminal
最后都做完了,请参考hadoop分布式运算集群中MapReduce跑我的第一个“Hello World”进行下一步应用。
这里的hadoop分布式安装的是基于VMWare虚拟机,用的是CentOS镜像。

1.安装CentOS虚拟机。
2.用root账户登录。

3.改网关。

注意:这里的Gataway填写的是自己本机的IP地址,然后Address填写的是你的虚拟机将要虚拟的IP地址(随便填,但是尽量有规律)
4.改时间。
(hadoop是离线计算,但是多台虚拟机之间的时间不要误差超过20分钟,所以我统一悬着了北京时间)

5.改好网关和时间之后,找空白处,点击鼠标右键,打开Open in Terminal
.

6.打开SourceCRT
也可以用Xshell,用软件对Linux系统进行操作。


连接成功。

7.打开notepad++
安装nppftp插件,方便对Linux文件系统中文件的管理。



连接成功

8.关闭防火墙,禁用selinux
chkconfig iptables off
vim /etc/sysconfig/selinux
9.修改主机名
vim /etc/sysconfig/network
10.修改主机名与IP対应关系
vim /etc/hosts
11.重启机器。
reboot
12.免密登录。
ssh-keygen -t rsa
ssh-copy-id 192.168.80.100
ssh 192.168.80.100
 13.开始准备hadoop中文件的东西。
13.开始准备hadoop中文件的东西。
13、创建文件夹
在home文件夹中创建data、softwares、tools文件夹。
data存放数据,softwares存放应用数据,tools存放应用、压缩包之类 。

14.配置java环境变量。
rpm -qa|grep jdk
rpm -qa|grep java
15.安装lrzsz
方便上传软件,其实你也可以用拖拽的方式,拖到Linux文件系统tools中。
yum install -y lrzsz
//等待安装ing
rz


文件上传成功之后;
16.解压javaJDK文件
在softwares文件夹中创建一个java8文件夹,其实你创建什么文件夹都可以,记住就好,是因为JDK文件解压之后文件有点散,我们统一的放在java8中而已。(这里你自己创建,我没有截图)
17.解压到java8中
tar -zxf jdk1.8.0_162.tar.gz -C ../softwares/java8
18.配置java环境
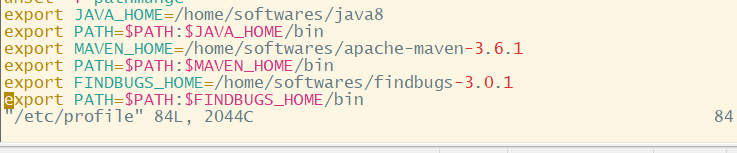
vim /etc/profile在profile文件的最后一行:写
export JAVA_HOME=/home/softwares/java8
export PATH=$PATH:$JAVA_HOME/bin解压之后刷新一些文件系统
source /etc/profile
//查看一下jdk是否安装完成。
java -version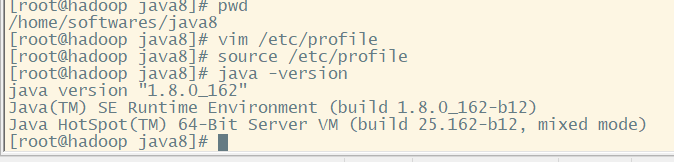
19.把上传的所需要的压缩包都解压一下
每一个都要手动写入配置。

所有配置如图:
20.protobuf安装:
yum -y install automake libtool cmake ncurses_devel openssl-devel lzo-devel zlib-devel gcc gcc-c++
21.上传hadoop-linux tar 文件,并解压
rz

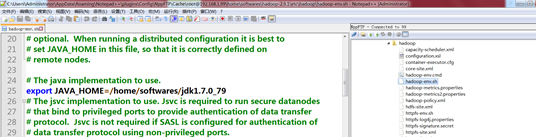
拷贝一下JAVA_HOME的地址

用notepad++打开hadoop-env.sh,将JAVA_HOME更改一下:/home/softwares/java8
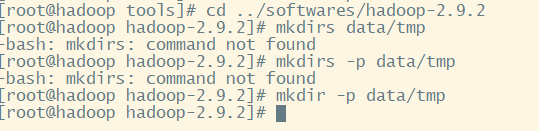
在hadoop-2.9.2文件夹下创建日志文件夹:data/tmp
好,下面的内容就是官网上的了,如果看不懂我的就参照官网地址吧:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
22.修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/softwares/hadoop-2.9.2/data/tmp</value>
</property>
</configuration>把mapred-queues.xml。tamplate改名为mapred-queues.xml
23.配置hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
24.格式化文件系统
(这里建议手敲,不然格式容易错误导致失败,实在不行就复制这个和官网的看看)
bin/hdfs namenode -format

25.重启文件系统。
sbin/start-dfs.sh查看一下现在是否有4个进程了
jps
26.查看界面
http://192.168.80.100:50070/
27.配置yarn
修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>28.启动yarn
sbin/start-yarn.sh
29.查看一下现在有没有5个进程;
jps
查看页面:
30.停止yarn
sbin/stop-yarn.sh
















 863
863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









