






实话实说,对MDT和HMM的区别仍旧不是很确定。以下仅仅记录分析的过程。
动态纹理的表达式:

HMM的表达式:(系统介绍可见HMM隐马尔可夫模型的例子、原理、计算和应用 - 知乎,HMM隐马尔可夫模型详解_WeisongZhao-CSDN博客_hmm模型,这里面有代码。)
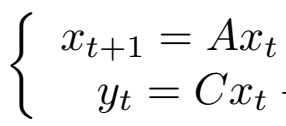
动态纹理(DT)与隐马尔可夫(HMM)的共同点:
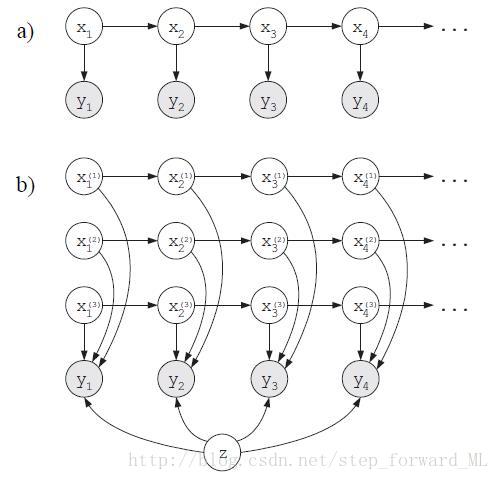
1)二者有相同的概率图结构,如下图。
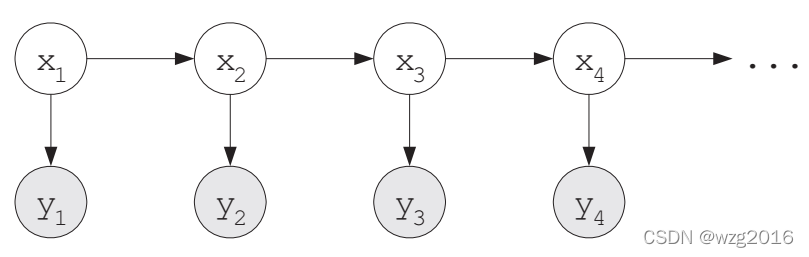
2)二者都遵从HMM的两个假设:
- 隐状态序列是一个马尔可夫链,当前隐状态仅仅与前一个隐状态有关
- 当前观测仅仅与当前的隐状态有关
动态纹理(DT)与隐马尔可夫(HMM)的不同点:
1)有人说,HMM的观测变量和状态变量是离散的,是从离散数值的集合中采样的,动态纹理工程的观测和变量是连续的。对于这点我这点不是很确定,或不敢认同。从公式来看,二者都是线型系统,都是由变换矩阵进行状态变换,既然如此,那么状态就都是有限的,都是离散的。另外根据博客,HMM的观测也可以是连续的,比如服从一个Gauss或GMM分布,有对应的有GaussHMM和GMMHMM,所以这个不同点不可靠。
2)个人理解,从公式看,动态纹理过程比HMM在状态转移和观测生成过程中增加了噪声变量。但是对这个区别,自己也不是很确定,应该也有改进的HMM考虑到了噪声吧。
以下转自:关于混合动态纹理模型,来解决监控视频中的异常检测,建模过程,数据的输入输出是什么? - 知乎
小白来瞎答下,动态纹理是一个升级版的线性动态系统(Linear Dynamical System),输入是一段视频序列,输出是对视频序列在时间空间上的聚类,空域具体单位可以是每个像素,也可以是预处理之后的超像素,思想类似Emission Probablity Distribution为Gaussian Mixture Model的HMM,但混合动态纹理假定隐状态由从一个先验分布中采样生成,这样每个时空cluster可以认为是一个马尔科夫链,整个模型为多个Linear Dynamical Systems,具体模型参数用传统EM算法估计。
理解:可以把MDT看作一个聚类?对线性序列的聚类?建模了K中线性动态系统,每个线性动态系统可以看作是一种聚类,发射概率是多个线性动态系统的加权和,加权的权重与GMM的权重类似?
再理解:如果不考虑改进的MDT算法和HMM算法,仅仅比较最原始的MDT和HMM算法,那么可能有以下不同:
1)最原始的MDT本身就具有分布的概念,所有的状态都是从一个分布里采样的;最原始的HMM的观测都是指定的离散数值,如骰子的6种观测,对应的隐状态也是有固定指定的个数的。
2)MDT确实考虑了噪声变量,HMM没有考虑噪声变量。
3)MDT的本质是聚类。从一个分布里采样若干样本训练MDT模型,只要一个样本序列都是从这个分布里采样的,那么MDT就能对它输出一个较高的概率值,如果这个序列中掺杂了其他分布的样本,那么MDT就会输出一个较低的概率值。
以下是个人理解,似乎应该是正确的
MDT捕捉的是聚类,只要样本序列都服从一个分布,那么MDT就会输出一个高概率值。
而HMM捕捉的实际是有限观测之间的转移规律,即使服从同一个分布(其实只有有限个状态,比如骰子的6中观测值),只要不服从这个转移规律,就会输出低概率值。
所以,从这里讲,最原始的MDT的观测是无限的,而最原始的HMM的观测是有限的。只不过,后来有人对HMM提出了改进,比如GaussHMM,GMMHMM等,把HMM从有限观测向无限观测改进,就有点像MDT了。
混合动态纹理(MDT)
多个线性动态系统,或,一个观测受多个隐状态序列的影响,每个隐状态的影响是有权重的,这个权重由一个隐变量z来控制。
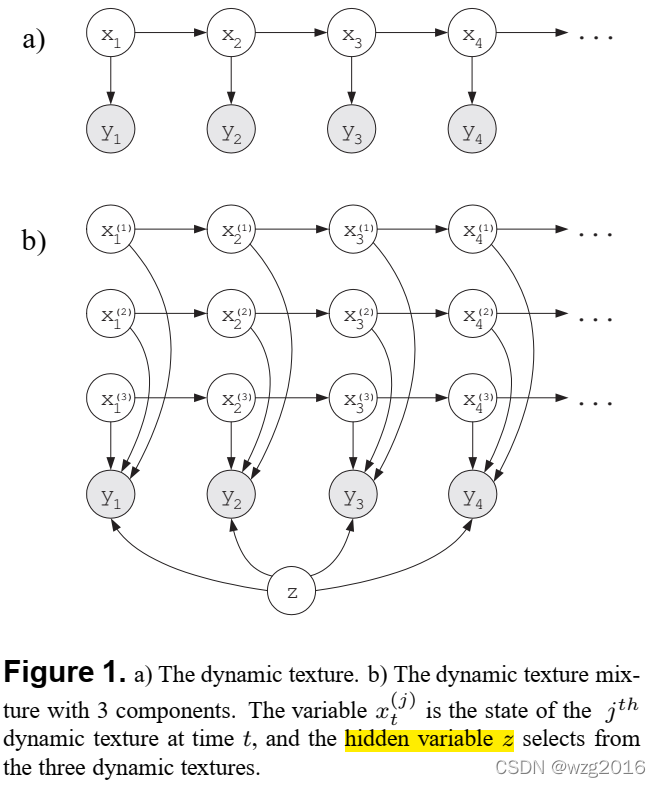
在HMM中也有类似上图b)的结构。

本以下转自:计算机视觉-混合动态纹理模型(Mixtures of Dynamic Textures)_JRRG的博客-CSDN博客_混合动态纹理
下面格式有错,建议转至原文。
在计算机视觉领域,混合动态纹理模型(Mixtures of Dynamic Textures, MDT)常用于视频帧序列建模。比如对帧序列的分割,局部或全局的异常事件检测。下图能很好表明MDT的建模过程及其应用,该模型用于人群场景中局部异常的检测。首先,训练阶段:在一定的训练时间内且在每一个子区域中学习相应的MDT模型;其次,测试阶段:针对每一个子区域的MDT模型计算测试帧对应区域的负对数似然。整个过程类比于GMM模型用于视频建模,其中两者的区别在于GMM模型中的样本数据点为单帧中的local patch;而在MDT模型中的样本数据点多考虑了时间信息,即为spatio-temporal local patchs。而这层时间信息可以用马尔科夫链进行建模,下面我们先描述一下动态纹理模型(DT),然后再讨论MDT。
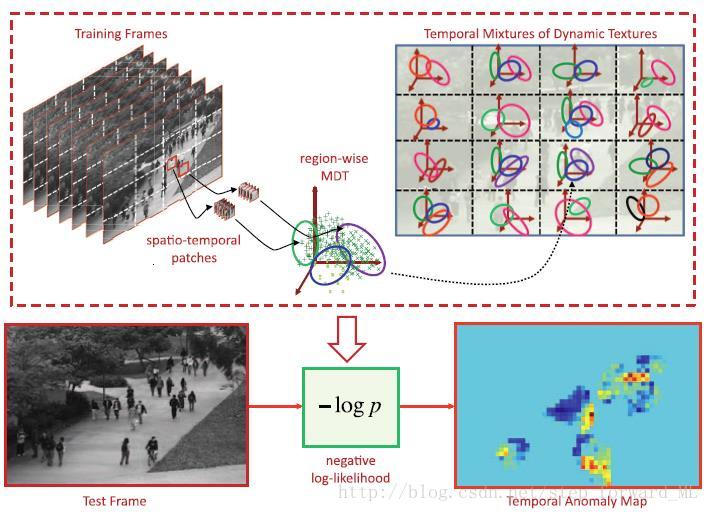
1. 动态纹理模型(DT)
DT是一个典型的视频帧序列的生成模型。这个随机过程通过一系列隐变量和观测变量{x,y}{x,y}并结合线性动态系统(linear dynamical system, LDS)进行形式化:
{xt+1=Axt+vtyt=Cxt+wt
{xt+1=Axt+vtyt=Cxt+wt
其中 xt∈Rnxt∈Rn为帧序列中时刻 tt对应的隐变量,刻画视频序列随时间的演变;yt∈Rmyt∈Rm为对应的观测变量 (一般 n≪mn≪m),刻画视频帧;参数 A∈Rn×nA∈Rn×n为状态转移矩阵,参数 C∈Rm×mC∈Rm×m为发射矩阵;而 vt,wtvt,wt为高斯白噪声,即 vt∼N(0,Q),wt∼N(0,R)vt∼N(0,Q),wt∼N(0,R),其中 Q∈Rn×n,R∈Rm×mQ∈Rn×n,R∈Rm×m。扩展定义初始状态 x1x1服从参数为 μ,Sμ,S的高斯分布。那么DT模型的参数为 Θ={A,Q,C,R,μ,S}Θ={A,Q,C,R,μ,S},概率图模型如下图(a)所示。模型中的隐变量 ytyt为连续性变量,可理解为整个模型要学习的就是视频帧的上层语义信息(即纹理信息)。该模型与隐马尔科夫模型类似,区别仅在于隐状态变量的离散型或连续性。
很显然,初始状态分布,状态转移条件分布和观测条件分布如下
⎧⎩⎨p(x1)=G(x1,μ,S)p(xt|xt−1)=G(xt,Axt−1,Q)p(yt|xt)=G(yt,Cxt,R)
{p(x1)=G(x1,μ,S)p(xt|xt−1)=G(xt,Axt−1,Q)p(yt|xt)=G(yt,Cxt,R)
其中 G(x,μ,Σ)=(2π)−n/2|Σ|−1/2exp{−12∥xt−μ∥2Σ}G(x,μ,Σ)=(2π)−n/2|Σ|−1/2exp{−12‖xt−μ‖Σ2}为 nn维高斯分布,∥xt−μ∥2Σ=(xt−μ)TΣ−1(xt−μ)‖xt−μ‖Σ2=(xt−μ)TΣ−1(xt−μ)。那么, {x,y}{x,y}的联合概率分布为
p(x,y)=p(x1)∏t=2τp(xt|xt−1)∏t=1τp(yt|xt)
p(x,y)=p(x1)∏t=2τp(xt|xt−1)∏t=1τp(yt|xt)
由于隐变量的存在,该模型的参数学习一般通过 EM算法求解;而隐变量的推断(预测问题)一般采用经典的维特比算法。这里就不过多介绍细节,下面我们来看MDT模型。
2. 混合动态纹理模型(MDT)
所谓MDT,即一个视频帧序列yy采样于某一个动态纹理,且每一个动态纹理参数为ΘkΘk,对应概率为αkαk,满足∑Kkαk=1∑kKαk=1。整个模型的生成过程如下:
从多项式分布{α1,⋯,αK}{α1,⋯,αK}中采样一个成分kk;
从动态纹理成分ΘkΘk中采样一个视频帧序列yy。
那么该序列从该生成模型中采样的概率为
p(y)=∑k=1Kαkpk(y;Θk)
其中 pk(y;Θk)pk(y;Θk)为第 kk个动态纹理的条件概率分布,参数为Θk={Ak,Qk,Ck,Rk,μk,Sk}Θk=其中 pk(y;Θk)pk(y;Θk)为第 kk个动态纹理的条件概率分布,参数为Θk={Ak,Qk,Ck,Rk,μk,Sk}Θk={Ak,Qk,Ck,Rk,μk,Sk}。这就是混合动态纹理模型,概率图模型即为上图(b)。那么联合概率分布为

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









