



1 什么是大语言模型?
大语言模型(后续简称大模型)可以看作是一种强大的计算机程序或者应用,它能够处理复杂的任务,比如理解和生成语言、识别图像、翻译文本等。
但大模型又不同于我们日常使用的传统程序与应用,传统程序的输入与输出(回复)就好比计算器一样,输入1+1,输出一定是2,重复一万次也是如此。而大模型的输出物(文字、图像等)具有一定的随机性,即使输入完全一样,每次的输出(回复)都有差别。
在这一点上,大模型更接近人。想象一下我们问一个人你今天感觉怎样?他的回答在一天内的不同时段随着自己的心情变化会有所差别,大模型也会变。即使我们问一道答案确定的数学题,人类可能因为劳累或一时大意而回答错,大模型一样也会出错。

这是deepseek最新V3模型的回复,答案与分析过程自相矛盾,很显然它此刻有点“累” :)
“把大模型当人看”,而不是当作一个冷冰冰的程序与应用,更有助于理解后续的内容。
2. 大模型是如何工作的?
答案是:不知道,说不清。
好比人类是怎样写出一篇妙笔生花的文章,又是如何解决一道数学题?我们只能看见具体的过程,但并不清楚人脑内的神经元是如何工作的,对于大模型也是一样。
下面是一张经典机器学习的教学图,通过历史上的房价数据总结出波士顿的房价规律,从而可以推测出某一所房子的价值。
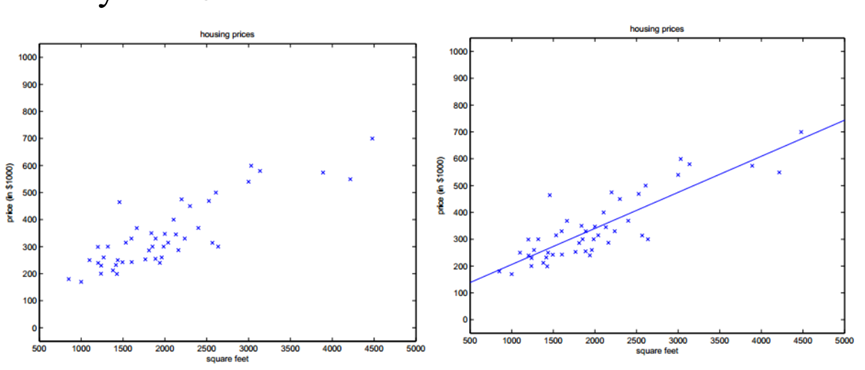
根据以上信息,我们可通过一个一元一次式来预测波士顿房价与面积的关系,例如:
房价 = 2000 * 面积 + 10000这个公式通过2个固定参数2000和10000,处理一个输入变量面积,产生一个输出变量房价。
而大模型可以看做是一个可以处理成千上万输入变量、具有几千亿固定参数,可生成上万输出变量的复杂公式(神经网络)。当我们询问大模型具体的问题,相当于把问题逐字(更确切的说是逐token,token是一种大模型可以理解的技术字符)的输入这个几千亿参数的神经网络进行计算,从而得出结果,也就是大模型的回复。
简单来说,我们可以把大模型看做一个超级复杂的公式,这个公式具有几千亿的参数,并且这个公式在输入不变的情况下,计算结果(回复)却具有随机性。那么大模型是如何掌握现实世界的知识,能够非常准确的回答包罗万象的问题的呢?
3. 如何训练一个大模型
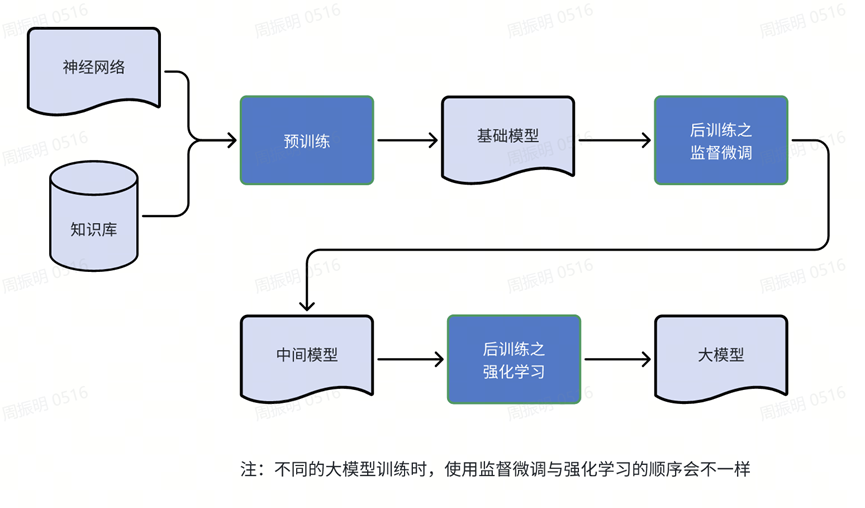
大模型的训练过程,分为三步:
1. 预训练:用现实世界的信息去训练神经网络各项参数,尽可能的去理解现实世界,得到一个基础模型。相当于人类学习过程中的啃书本,博览群书。
2. 后训练之监督微调:由人类书写问题与解答的范例文本,并用这些文本再一次训练基础模型。相当于人类学习过程中的看例题,或者看老师在黑板上讲解具体题目的解题步骤。
3.后训练之强化学习:针对各类问题,由大模型自己尝试数以万计的解题路径,找到可以得出正确答案的路径。相当于人类学习过程中的刷题。
注:第2步与第3步,不同的大模型训练顺序可能不一样,GPT4是先2后3,deepseek-R1是先3后2再3。
3.1 预训练(Pre-training)
这个阶段好比一个人类超级天才,把当前世界上所能找到的书籍全部读了一遍,并且把知识“记忆”在了大脑里。注意这里用了“记忆”而不是“存储”,区别在于“存储”相当于搜集了所有的书籍,放在了仓库里;“记忆”则是通读了一遍,记在了脑子里。
训练大模型时,首先会把互联网上能找到的信息都搜集起来,这些信息需要按照一定的格式整理并存储,并且过滤掉不健康的信息。就如人类学习的知识要整理成册,并且审核内容,不能给人类幼崽读黄赌毒一类的有害书籍。
hugging face的FineWeb项目提供了这类训练信息,当然每一家大模型公司都有自己的训练用信息与数据,基本没有对外公开的。

FineWeb搜集了多少文本数据?44TB!什么概念呢,以汉字为例(当然FineWeb搜集的是英文资料),相当于十五万亿个汉字的信息!一个人一辈子的阅读量撑死几亿个汉字(大多数人远远达不到),按一辈子看五亿汉字计算,十五万亿汉字相当于三万人一辈子的阅读量,并且这些知识涵盖了方方面面,三百六十度无死角。
有了这些知识信息,接下来开始训练神经网络。初始时,神经网络里的几千亿参数都是随机的,训练数据流入神经网络计算出了输出信息,然后把输出信息与正确信息相比较从而计算偏差;接着,根据算法调整神经网络里的参数,使得输出信息与正确信息的偏差越来越小。好比一个人背书,先读一遍,然后边背边和书本比较,直到所背的内容与书本内容基本一致。
要把44TB的内容记得大差不差,需要上万张善于并行计算的高端算力卡(以英伟达生产的产品为代表)连续不断地训练几十天,直到最后葵花宝典练成,得到了一个几千亿参数的神经网络,称为基础模型(基模型,base model)。这一步是大模型训练花费最大,时间最长的一步

预训练好比一个超级天才在图书馆里孜孜不倦的把人类积累的所有书籍读完,并且大差不差的记住了所有的知识点。这里很关键的一点请注意,这个人记住的知识都不是精确的,而是模糊的、大差不差的。
从这种意义上来说,基础模型以及最终训练完的大模型可以看做一个人类所有知识的有损压缩包(知识库),而知识点就存储在大模型上千亿的参数中。
3.2 后训练(Post-training)- 监督微调
通过预训练获得的基模型还不能与人类正常对话,需要通过后训练让基模型学会与人类对话。
如何做到这一步呢?专业术语称作Supervised Fine-Tuning(SFT),即监督微调。可以这样理解,超级天才读完图书管理所有的书籍后,只是模糊掌握了知识点,但并不知道怎么使用。于是有一个导师把如何利用知识回答问题做成了详细的示例文本,并教给了这个超级天才,天才的大脑又进化了。

这个通过旁人生成的示例文本对模型参数进行调整的步骤,称为有监督下(人类监督)的微小调整,微小的意思是相对于预训练来说只需要少量的计算资源与时间。
由人类导师制作的问答示范文本同样涵盖了方方面面的知识领域,而且按照严格的标准撰写,这需要花费大量的人力与时间。示范文本质量的高低,决定了SFT后模型的质量。试想一个吊儿郎当的半吊子导师制作的课件与教材,教出来的学生必然不怎么样。所以人类学习时老师很重要,大模型训练时SFT同样也很重要。
由于SFT使用的示范文本生成需要大量人力,也有人想到了偷懒的方法——用大模型来生成示范文本,于是有了UltraChat这样的项目。
3.3 后训练(Post-training)- 强化学习
如果拿一本教材里的内容来做类比:
1. 预训练:相当于学习教材里的阐述性内容,例如定理与公理,以及对应的解释。
2. 监督微调:相当于学习教材里的例题,包含问题、解题过程与最终答案。
3.强化学习:相当于做教材里的习题,有问题与最终答案,学生需要自己尝试找到解题的方法。英文为Reinforcement Learning (RL)。

在解题的过程中,学生通常需要尝试多个不同的解题思路来得到正确的答案,且得到正确答案的方法并不是唯一的。
同样的,大模型在强化学习过程中不断地调整参数,根据问题去尝试生成最终答案,并与正确答案比较。在这一过程中,能生成正确答案的参数被不断采纳与优化,从而使得模型越来越优秀。
同样,一个人类学习者通过不断地刷题,训练大脑掌握了正确的解题思路与方法。在以后面对考试或者新的问题出现时,大脑自然而然的会通过学习到的方法来解决问题。习题做得越多,尝试的方法越多,正确解决问题的能力越强。
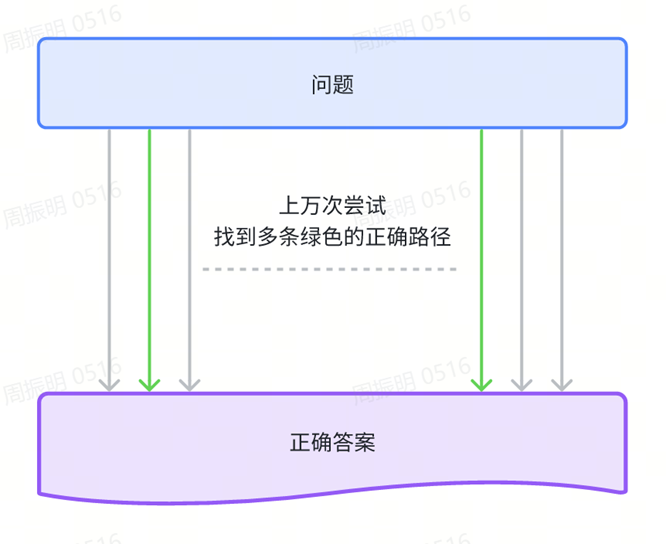
而一个不眠不休、运算速度极快的大模型,其效率是人类无法比拟的。面对一个问题,大模型会短时间内尝试上万种不同的参数组合以发现最优解,从而不断逼近最优的参数组合。通过这种不需要人类干预的自我学习方式一步步增强,这就是强化学习的本质。
深度求索的Deepseek-R1模型,也就是撼动OpenAI霸主地位的模型便主要是通过这种方法训练出来的。在此之前的各类大模型,主要依靠监督微调进行训练,再辅以强化学习。
一点补充,下两段可跳过。
对于有明确答案的理科题,模型可以通过与正确答案比对来找到最佳的方法(不同参数组合)。但面对开放性问题,例如写一篇文章这种没有标准答案的问题,如何判断大模型回复的好坏?如果人类介入判断文章好坏的话,假设有1000个文章撰写类问题,每个问题做1000次迭代循环,每次迭代循环尝试1000条路径,意味着有一亿篇文章需要人类阅读后判断,这不现实。
于是有人提出了RLHF (Reinforcement Learning from Human Feedback),即基于人类反馈的强化学习。先在一亿篇文章里挑出5000篇让人类阅读,并根据文章质量排定好坏次序,然后训练一个小模型模拟人类对于文章质量好坏的判断,最后把一亿篇文章的质量都交给这个小模型去评判并反馈给大模型。
彩蛋:顿悟时刻 Aha Moment
不知读者是否有过类似的体验:当刻苦的学习进行到某种程度时,某一天突然发现原本很难的题目变得简单了,原来很难理解的文章变得通俗易懂了。量变引起质变,整个人开窍了、顿悟了。
人类的学习有顿悟时刻,同样当强化学习迭代重复的次数足够多时,大模型也有它自己的顿悟时刻——Aha Moment,在deepseek-R1的训练中出现了这一时刻,模型在某次训练中发现某一种思考方式可以大幅提升回答的正确率。

这一刻,再次提醒我们“把大模型当人看”,而不是机器!
一句话总结:通过在预训练生成的基模型之上进行监督微调(SFT)与强化学习(RL),一个可以面向用户的大模型便诞生了。嗯,一位博览群书的学子,在老师的循循善诱之下,通过不断的刷题,终于掌握了世间大部分的知识,可以出山做牛马了。
4. 一些个人感想
以下是一些个人感想,想到哪里写到哪里,有些乱,也未必正确,看看就好。
过去两年火热的AI大模型的出现不是一蹴而就的,人工智能这个领域实际上经过了几十年的积累与发展才到达了今天的高度。Open AI也好,深度求索也罢,都是站在前人的肩膀上继续向上攀登。以它们为代表的人工智能公司足够伟大,大模型对于人类社会进步的推动作用毋庸置疑。
只不过,我们也必须却魅。大模型与人工智能在今天还达不到蒸汽机推动工业革命,电脑推动信息革命的高度(未来也许可以),人类期望中的AGI(通用人工智能)时代没有那么快到来。现阶段的大模型本身只是一个没有记忆的、有损压缩的全样本知识库,它并没有自我意识,也没有创造力。
那么大模型在将来会不会有自我意识与创造力呢?个人观点是:运行在遵循冯诺依曼体系的电脑中的AI系统(包含大模型)很难具备自我意识与创造力,在存储、运算、输入输出三个硬件结构之外,还有一个重要的类人脑硬件结构,我们并未发现。而这个未知结构正是构成具备自我意识AI系统的关键。
大模型突破了传统软件的设计,即软件的运行步骤需要人类程序员提前设计好,软件程序的计算与运行完全按照提前设计好的逻辑进行,分毫不差;而大模型的运算结果则超出了人类的掌控,变得不可预知。
目前,大模型的应用并没有当初的蒸汽机、电力、电脑那样普遍,还需要时间找到对的应用场景。当下比较成功的是在编程领域,大模型可以帮助程序员提升编码效率,并替代部分初级程序员的工作。个人看好大模型在教育与医疗领域的应用,尤其在人口众多而优质资源相对缺乏的国家,大模型可以打破地区资源分配不均匀的不平等,有助于教育与医疗平权。也即同样的人才无论在任何地域均可获得同等的教育,一个病患无论身处何地都可以得到同等的诊断与治疗。
大模型不是工作岗位收割机,机械的应用把人们从千年以来赖以生存的耕地上解放出来,促成了工业与信息化革命;同样的,大模型可以把人类从重复的脑力劳动中解放出来,去做更具备创造性的工作,从而推动人类社会的加速进步。虽然,长远来看硅基生命迟早会取代碳基生命……
人类社会是一体的,以历史角度来回溯,人类始终在往统一成同一个部落与国度的方向在演进,无论中间出现什么倒退,这个历史发展的方向不可逆,除非在统一前人类自我毁灭。所以,以长远的角度来看,人类命运是一个共同体。如果全世界携手致力于人工智能的发展,可以极大的推进社会进步。于当下的人们来说,至少可以治愈一些以前无法治愈的疾病,并相对延长寿命,提高老年的生存质量;而于未来的人们,星辰与大海才是征途。
5.零基础入门AI大模型必看
陆陆续续也整理了不少资源,希望能帮大家少走一些弯路!
无论是学业还是事业,都希望你顺顺利利 !
1️⃣ 大模型入门学习路线图(附学习资源)
2️⃣ 大模型方向必读书籍PDF版
3️⃣ 大模型面试题库
4️⃣ 大模型项目源码
5️⃣ 超详细海量大模型LLM实战项目
6️⃣ Langchain/RAG标题一/Agent学习资源
7️⃣ LLM大模型系统0到1入门学习教程
8️⃣ 吴恩达最新大模型视频+课件


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









