







机器学习中的参数优化算法中梯度下降法用的比较多,此处就转载了一篇写的通俗易懂的文章。转自:http://blog.csdn.net/zbc1090549839/article/details/38149561
一、误差准则函数与随机梯度下降:
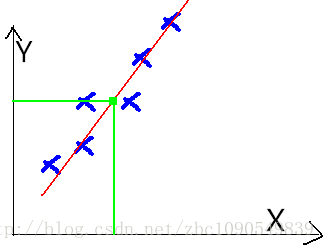
数学一点将就是,对于给定的一个点集(X,Y),找到一条曲线或者曲面,对其进行拟合之。同时称X中的变量为特征(Feature),Y值为预测值。
如图:
一个典型的机器学习的过程,首先给出一组输入数据X,我们的算法会通过一系列的过程得到一个估计的函数,这个函数有能力对没有见过的新数据给出一个新的估计Y,也被称为构建一个模型。
我们用X1、X2...Xn 去描述feature里面的分量,用Y来描述我们的估计,得到一下模型:
我们需要一种机制去评价这个模型对数据的描述到底够不够准确,而采集的数据x、y通常来说是存在误差的(多数情况下误差服从高斯分布),于是,自然的,引入误差函数:
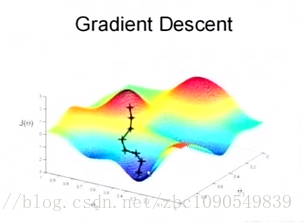
关键的一点是如何调整theta值,使误差函数J最小化。J函数构成一个曲面或者曲线,我们的目的是找到该曲面的最低点:
假设随机站在该曲面的一点,要以最快的速度到达最低点,我们当然会沿着坡度最大的方向往下走(梯度的反方向)
用数学描述就是一个求偏导数的过程:
这样,参数theta的更新过程描述为以下:
(α表示算法的学习速率)
二、不同梯度下降算法的区别:
梯度下降:梯度下降就是我上面的推导,要留意,在梯度下降中,对于θθ的更新,所有的样本都有贡献,也就是参与调整θθ.其计算得到的是一个标准梯度。因而理论上来说一次更新的幅度是比较大的。如果样本不多的情况下,当然是这样收敛的速度会更快啦~
随机梯度下降:可以看到多了随机两个字,随机也就是说我用样本中的一个例子来近似我所有的样本,来调整θθ,因而随机梯度下降是会带来一定的问题,因为计算得到的并不是准确的一个梯度,容易陷入到局部最优解中
批量梯度下降:其实批量的梯度下降就是一种折中的方法,他用了一些小样本来近似全部的,其本质就是我1个指不定不太准,那我用个30个50个样本那比随机的要准不少了吧,而且批量的话还是非常可以反映样本的一个分布情况的。
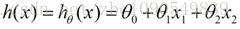
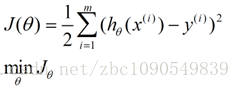
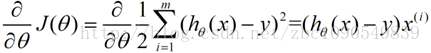
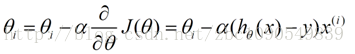















 761
761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









