







我这个是可学习的注意力机制,原谅我不会用高级词汇来描述注意力机制。
写在前面,其中的卷积核大小是随着层数改变的,不是一成不变的,只不过我放在后面,然后就把padding写固定了。
ECA代码
CBAM
为了增加表达能力,我这里多加了一个池化来提取特征,SA我也加了,emmm,我是魔改了。你可以改激活函数的,卷积核大小,或者SE和SA混合加来加去看看效果。
ECANet和SA都开源了,GitHub上可以直接搜到。

另一个图是不是更好理解一点,
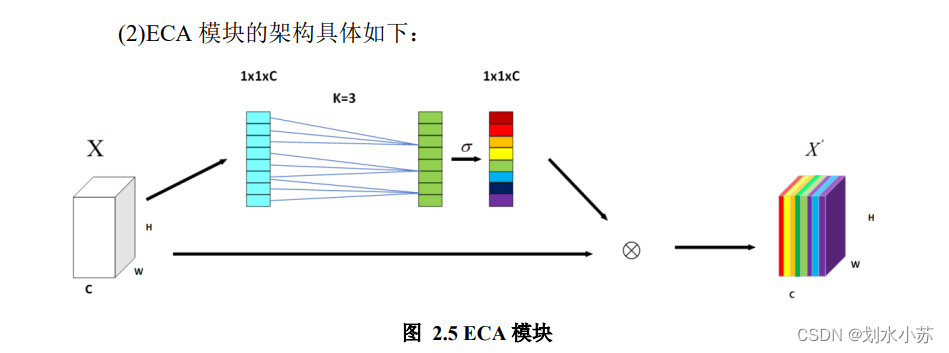
ECA模块
利用conv1d代替全连接,减少维度压缩。
class ECAAttention(nn.Module):
def __init__(self, kernel_size=7):
super().__init__()
self.gap=nn.AdaptiveAvgPool2d(1)
self.maxpool=nn.AdaptiveMaxPool2d(1)
# padding = kernel_size // 2
self.conv=nn.Conv1d(1,1,kernel_size=kernel_size,padding=3)
self.sigmoid=nn.Sigmoid()
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
avp_result =self.gap(x) #bs,c,1,1
max_result = self.maxpool(x)
avp_result=avp_result.squeeze(-1).permute(0,2,1) #bs,1,c
max_result=max_result.squeeze(-1).permute(0,2,1) #bs,1,c
avp_result=self.conv(avp_result) #bs,1,c
max_result=self.conv(max_result) #bs,1,c
y=self.sigmoid(max_result + avp_result) #bs,1,c
y=y.permute(0,2,1).unsqueeze(-1) #bs,c,1,1
return x*y.expand_as(x)
空间注意力SA
emmmmm,通道注意力是把每一个通道最大的块取出来,然后一层层的堆,很高的那种,SA的话铺地砖那种,一个平面。SA你可以不加的,我改搞的时候,emmm,SA去掉效果还好了,玄学。
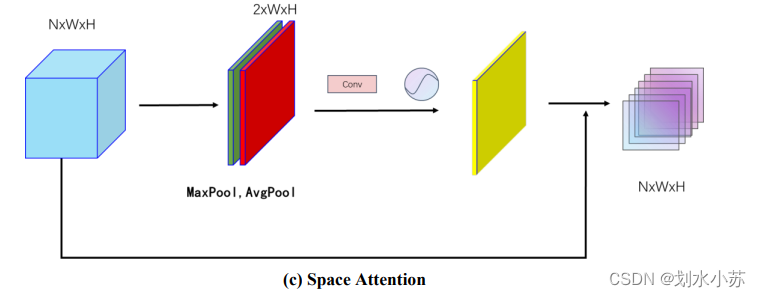
class SpatialAttention(nn.Module):
def __init__(self,kernel_size=7):
super().__init__()
self.conv=nn.Conv2d(2,1,kernel_size=kernel_size,padding=3)
self.sigmoid=nn.Sigmoid()
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x) :
max_result,_=torch.max(x,dim=1,keepdim=True)
avg_result=torch.mean(x,dim=1,keepdim=True)
result=torch.cat([max_result,avg_result],1)
output=self.conv(result)
output=self.sigmoid(output)
return x*output
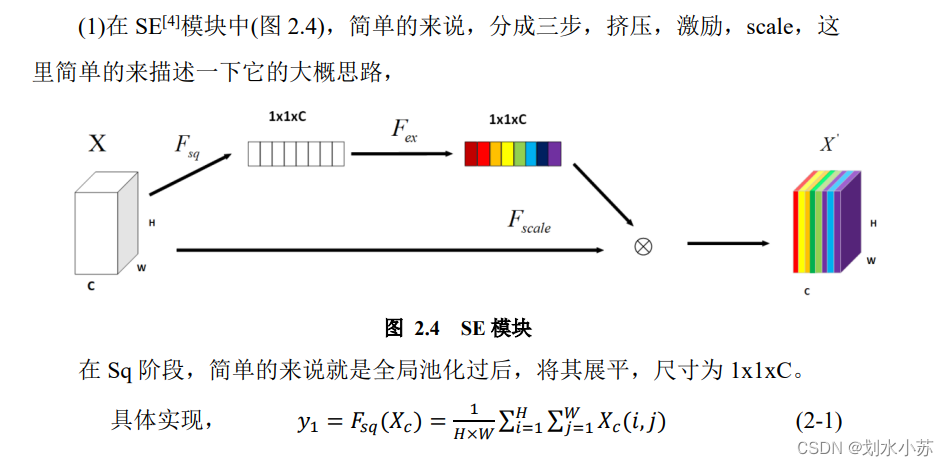
关于通道注意力SE的一些细节描述
















 91
91











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









