




文章目录
目前学术界一般将NLP任务的发展分为四个阶段,即NLP四范式:
- 第一范式:基于「传统机器学习模型」的范式,如TF-IDF特征+朴素贝叶斯等机器算法;
- 第二范式:基于「深度学习模型」的范式,如word2vec特征+LSTM等深度学习算法,相比于第一范式,模型准确有所提高,特征工程的工作也有所减少;
- 第三范式:基于「预训练模型+fine-tuning」的范式,如Bert+fine-tuning的NLP任务,相比于第二范式,模型准确度显著提高,模型也随之变得更大,但小数据集就可训练出好模型;
- 第四范式:基于「预训练模型+Prompt+预测」的范式,如Bert+Prompt的范式相比于第三范式,模型训练所需的训练数据显著减少。
在整个NLP领域,整个发展历程是朝着精度更高、少监督,甚至无监督的方向发展的。而 Prompt-Tuning是目前学术界向这个方向进军最新也是最火的研究成果。
而在进行大模型的Prompt-Tuning微调的过程中,又涉及多种微调方法,这里按照模板的构造方式及工作原理简单做个分类:
- Hard Promp:离散模板
- Soft Prompt:连续模板
- Prefix Tuning:斯坦福,2021.01
- Prompt Tuning:Google,2021.04
- P-tuning v1:清华,2021.03
- P-tuning v2:清华,2021.10
- LoRA方法:2022
- Qlora方法:2023.05
一、Fine-Tuning:微调
Fine-Tuning是我们上面提到的第三范式,即基于「预训练模型+fine-tuning」的范式。其属于一种迁移学习方式,在自然语言处理(NLP)中,Fine-Tuning是用于将预训练的语言模型适应于特定任务或领域。Fine-Tuning的基本思想是采用已经在大量文本上进行训练的预训练语言模型,然后在小规模的任务特定文本上继续训练它。
经典的Fine-Tuning方法包括将预训练模型与少量特定任务数据一起继续训练。在这个过程中,预训练模型的权重被更新,以更好地适应任务。所需的Fine-Tuning量取决于预训练语料库和任务特定语料库之间的相似性。如果两者相似,可能只需要少量的Fine-Tuning,如果两者不相似,则可能需要更多的Fine-Tuning.
但是,在大多数下游任务微调时,下游任务的目标和预训练的目标差距过大导致提升效果不明显(过拟合),微调过程中需要依赖大量的监督语料等等。
至此,以GPT3、PET等为首的模型提出一种 基于预训练语言模型的新的微调范式–Prompt-Tuning . 该方法的目的是通过添加模板的方法来避免引入额外的参数,从而让模型可以在小样本(few-shot)或者零样本(zero-shot)场景下达到理想的效果。
Prompt-Tuning的动机旨在解决目前传统Fine-tuning的两个痛点问题:
-
降低语义差异 (Bridge the gap between Pre-training and Fine-tuning): 预训练任务主要以 Masked Language Modeling (MLM)为主, 而下游任务则重新引入新的训练参数, 因此两个阶 段的目标通常有较大差异。 因此需要解决如何缩小Pre-training和Fine-tuning两个阶段目标差距过大的问题;
-
避免过拟合(Overfitting of the head): 由于在Fine-tuning阶段需要新引入额外的参数以适配相应的任务需要, 因此在样本数量有限的情况容易发生过拟合, 降低了模型的泛化能力。 因此需要面对预训练语言模型的过拟合问题。
二、Prompt-Tuning:提示调优
关于Prompt-Tuning的核心内容,主要参考综述型博客(强烈推荐):Prompt-Tuning——深度解读一种新的微调范式
这里我们在第二部分先介绍Prompt-Tuning,是因为Prompt-Tuning本身可以看作是Prefix-Tuning的一个简化版本。Prompt-Tuning可以认为是一个比较范围比较广的概念,其主要思想是通过调整模板来实现对模型的微调。
具体在论文中,给每个任务定义了自己的Prompt,然后拼接到数据上作为输入,但只在输入层加入prompt tokens,并且不需要加入 MLP 进行调整来解决难训练的问题。

2.1 工作原理
Prompt的目的是将Fine-tuning的下游任务目标转换为Pre-training的任务。那么具体如何工作呢?
我们以二分类的情感分析作为例子,描述Prompt-tuning的工作原理。给定一个句子 [CLS] I like the Disney films very much. [SEP], 传统的Fine-tuning方法是将其通过BERT的Transformer获得 [CLS] 表征之后再喂入新增加的MLP分类器进行二分类,预测该句子是积极的(positive)还是消极的(negative),因此需要一定量的训练数据来训练。
而Prompt-Tuning则执行如下步骤:
- 构建模板(Template Construction):通过人工定义、自动搜索、文本生成等方法,生成与给定句子相关的一个含有
[MASK]标记的模板。例如It was [MASK],并拼接到原始文本中,获得Prompt-Tuning的输入:[CLS] I like the Disney films very much. [SEP] It was [MASK]. [SEP]。将其喂入BERT模型中,并复用预训练好的MLM分类器(在huggingface中为 BertForMaskedLM),即可直接得到[MASK]预测的各个token的概率分布; - 标签词映射(Label Word Verbalizer):因为
[MASK]部分我们只对部分词感兴趣,因此需要建立一个映射关系。例如如果 [MASK] 预测的词是“great”,则认为是positive类,如果是“terrible”,则是negative类。
此时会有读者思考,不同的句子应该有不同的template和label word,没错,因为每个句子可能期望预测出来的label word都不同,因此如何最大化的寻找当前任务更加合适的template和label word是Prompt-tuning非常重要的挑战。
• 训练:根据Verbalizer,则可以获得指定label word的预测概率分布,并采用交叉信息熵进行训练。此时因为只对预训练好的MLM head进行微调,所以避免了过拟合问题。
其实,引入的模板和标签词本质上也属于一种数据增强,通过添加提示的方式引入先验知识。
2.2 PET (Pattern-Exploiting Training)
PET (Pattern-Exploiting Training) 出自《Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference》(EACL2021)。Prompt-Tuning启发于文本分类任务,并且试图将所有的分类任务转换为与MLM一致的完形填空。PET详细地设计了Prompt-Tuning的重要组件—Pattern-Verbalizer-Pair (PVP),并描述了Prompt-tuning如何实现Few-shot/Zero-shot Learning,如何应用在全监督和半监督场景(iPET)。PET的详细讲解可参考PET的论文解读:https://wjn1996.blog.csdn.net/article/details/120788059
PET设计了两个重要的组件:
-
Pattern (Template): 记作T, 即上文提到的Template, 其为额外添加的带有
[mask]标记的短文本,通常一个样本只有一个Pattern (因为我们希望只有1个让模型预测的[mask]标记)。上文也提到了,不同的任务、不同的样本可能会有其更合适的pattern,因此如何构建合适的pattern是Prompt-Tuning的研究点之一; -
Verbalizer: 记作 V, 即标签词的映射,对于具体的分类任务,需要选择指定的标签词(label word)。例如情感分析中,我们期望Verbalizer可能是 V ( p o s i t i v e ) = g r e a t , V ( n e g a t i v e ) = t e r r i b l e V(positive)= great, V(negative)= terrible V(positive)=great,V(negative)=terrible (positive和negative是类标签)。同样,不同的任务有其相应的label word,但需要注意的是,Verbalizer的构建需要取决于对应的Pattern。因此如何构建Verbalizer是另一个研究挑战。
上述两个组件被称为Pattern-Verbalizer-Pair (PVP),一般记作 P = ( T , V ) P=(T,V) P=(T,V),在后续的大多数研究中均采用这种PVP组件。
因此基于PVP的训练目标可以形式化描述:

2.3 Prompt-Tuning集成
在上面一节中,我们介绍了PET (Pattern-Exploiting Training)模型。通常而言,一个句子只能有一个PVP(因为我们只需要一个 [mask] 来预测),但是这并不是最优的。实际上,可以为一个句子设计多个不同的PVP,这就属于Prompt-Tuning的集成。集成的类型主要由以下几种:
-
Patterns Ensembling:同一个句子设计多个不同的pattern,例如
It was [mask]. , I think it is [mask].,及This comment denotes as [mask].等。此时,原先只有一个句子,却可以生成多个不同的样本,也变相起到数据增强的作用。在训练时,可以当单独的样本进行训练,推断时,则可以对所有Pattern的结果进行投票或加权。如下图所示:

-
Verbalizers Ensembling:同样,在给定的某个Pattern下,并非只有1个词可以作为label word。例如positive类,则可以选择“great”、“nice”、“wonderful”。当模型预测出这三个词时,均可判定为positive类。在训练和推理时,可以对所有label word的预测概率进行加权或投票处理,并最后获得概率最大的类。如下图所示:

- PVPs Ensembling (Prompt Ensembling):Pattern和Verbalizer均进行集成,此时尚同一个句子有多个Pattern,每个Pattern又对应多个label word。如下图所示(以2个PVP集成为例),在训练时可以采用加权,在推理时可以采用加权或投票法:

2.4 模板构建方式
可以说,PET为Prompt-Tuning提供了比较成熟的框架——PVP。基于这套框架,目前的研究开始关注如何选择或构建合适的Pattern和Verbalizer。
目前比较成熟的Pattern (Template)构建方式包括:
- 人工构建(Manual Template): 根据特定任务的性质和先验知识人工设计模板。例如在情感分类任务中,我们常常构建
It was [mask].作为模板。人工构建的方法虽然直观简单,但是致命问题也很突出。
有相关工作在实验中发现,在同样的数据集和训练条件下,选择不同的Pattern和Verbalizer会产生差异极大的结果,如下图所示(一般情况下,Template等于Pattern,Verbalizer等于Label word);

根据上图可发现,在相同Pattern时,选择不同的label word对结果影响很大,同理,不同的Pattern对结果影响也很明显。在真正应用中,调参者需要尝试多个不同的模板和标签词以穷举出最好的结果,并不能充分发挥Prompt简单快捷的优势。总结人工设计方法的缺陷:
- 采用人工构建的方法成本高,需要与领域任务相关的经验知识;
- 人工设计的Pattern和Verbalizer并不能保证获得最优化解,训练不稳定,不同的PVP对结果产生的差异明显,方差大;
- 在预训练阶段MLM任务并非完全按照PVP的模式进行训练的(比如MLM训练通常都是长文本,mask的数量也并非只有一个,预测的概率分布也并非是有限的),因此人工构建的Pattern和Verbalizer使得Prompt-Tuning与MLM在语义和分布上依然存在差异。
- 启发式法(Heuristic-based Template):通过规则、启发式搜索等方法构建合适的模板;
- 生成(Generation):根据给定的任务训练数据(通常是小样本场景),生成出合适的模板;
- 词向量微调(Word Embedding):显式地定义离散字符的模板,但在训练时这些模板字符的词向量参与梯度下降,初始定义的离散字符用于作为向量的初始化;
- 伪标记(Pseudo Token):不显式地定义离散的模板,而是将模板作为可训练的参数;
前面3种也被称为离散的模板构建法(记作Hard Template、Hard Prompt、Discrete Template、Discrete Prompt),其旨在直接与原始文本拼接显示式离散的字符,并且在训练过程中始终保持不变。这里的保持不变是指这些离散字符的词向量(Word Embedding)在训练过程中保持固定。通常情况下,离散法则不需要引入任何参数。
后面2种则被称为连续的模板构建法(记作Soft Template、Soft Prompt、Continuous Template、Continuous Prompt),其旨在让模型在训练过程中根据具体的上下文语义和任务目标对模板参数进行连续可调。这套方案的动机则是认为离散不变的模板无法参与模型的训练环节,容易陷入局部最优,而如果将模版变为可训练的参数,那么不同的样本都可以在连续的向量空间中寻找合适的伪标记,同时也增加模型的泛化能力。因此,连续法则需要引入少量的参数并让模型在训练时进行参数更新。
Prompt-Tuning其实是一个比较范围比较广的概念,其实我们后面具体介绍的 prefix tuning、P-tuning v1、P-tuning v2都属于Prompt-Tuning的连续的模板构建,通过把传统人工设计模版中的真实token替换成可微的virtual token,转换为模型中可以学习的参数进行更新,只是他们的工作原理存在一些差别。
三、Prefix Tuning:连续提示模板
3.1 提出动机
不论是启发式方法,还是通过生成的方法,都存在如下局限性:
- 需要为每一个任务单独设计对应的模板,因为这些模板都是可读的离散的token(这类模板我们称作Discrete Prompt或Hard Prompt。),这导致很难找到最佳的模板。
- 即便是同一个任务,不同的句子也会有其所谓的最佳模板,而且有时候,即便是人类理解的相似的模板,也会对模型预测结果产生很大差异。
3.2 工作原理
prefix-tuning:Optimizing Continuous Prompts for Generation
斯坦福的研究人员Xiang Lisa Li, Percy Liang等人于2021年年初通过此论文《Prefix-Tuning:Optimizing Continuous Prompts for Generation》提出Prefix Tuning方法。这是一种新的 “连续提示模板”方法,称作Continuous Prompt或Soft Prompt,其使用连续的virtual token embedding来代替离散的token,它在微调模型的过程中只优化加入的一小段可学习的向量(virtual tokens)作为Prefix,而不需要优化整个模型的参数(训练的时候只更新Prefix部分的参数,而PLM中的其他部分参数固定)。
这样,不同的任务、数据可以自适应地在语义空间中寻找若干合适的向量,来代表模板中的每一个词,相较于显式的token,这类token称为 伪标记(Pseudo Token)。下面给出基于连续提示的模板定义:

如下图所示:Fine-tuning是会更新Transformer中所有的参数,而P-tuning只需要更新Prefix处的参数。

- 该方法是在输入token之前构造一段任务相关的virtual tokens作为Prefix。(对于不同的任务和模型结构需要不同的prefix)
相当于对于transformer的每一层 (不只是输入层,且每一层transformer的输入不是从上一层输出,而是随机初始化的embedding作为输入),都在真实的句子表征前面插入若干个连续的可训练的"virtual token" embedding,这些伪token不必是词表中真实的词,而只是若干个可调的自由参数。
为了形象说明,举个例子,对于table-to-text任务,context x x x 是序列化的表格,输出 y y y 是表格的文本描述,使用GPT-2进行生成;对于文本摘要, x x x 是原文, y y y 是摘要,使用BART进行生成。
-
对于自回归(Autoregressive)模型,在句子前面添加前缀,得到:

这是因为合适的上文能够在fixed LM的情况下去引导生成下文(比如GPT3的 in-context learning)。 -
对Encoder-Decoder模型来说,Encoder和Decoder都增加了前缀,得到:

这是因为Encoder端增加前缀是为了引导输入部分的编码 (guiding what to extract from ),Decoder 端增加前缀是为了引导后续token的生成 (influence the generation of by steering the next token distribution)。

- 然后训练的时候只更新Prefix部分的参数,而Transformer中的预训练参数固定。
对于上述这个过程,有以下几点值得注意:
- 该方法其实和构造Prompt类似,只是Prompt是人为构造的“显式”的提示,并且无法更新参数,而Prefix则是可以学习的“隐式”的提示。
同时,为了防止直接更新Prefix的参数导致训练不稳定的情况,特在Prefix层前面加了MLP结构(相当于将Prefix分解为更小维度的Input与MLP的组合后输出的结果),训练完成后,只保留Prefix的参数。 - prefix-prompt的效果优于adapter tuning 和 finetune最上面的两层,最终和全参数finetune差不多,且在低资源情况下,效果优于finetune。
- 更长的前缀意味着更多的可微调参数,效果也变好,不过长度还是有阈值限制的(table-to-text是10,summarization是200)
- 可调参数作为前缀。
四、P-Tuning V1/V2
P-tuning目前有两个版本:
-
P-Tuning v1
-
P-Tuning v2
4.1 P-Tuning V1
P-Tuning V1将自然语言的离散模版转化为可训练的隐式prompt (连续参数优化问题)。
清华大学的研究者于2021年3月通过此篇论文《GPT Understands, Too》提出P-Tuning,其与prefix tuning类似:比如考虑到神经网络本质上是连续的,故离散提示可能不是最优的,从而也采取连续的提示。
总之,P-Tuning成功地实现了模版的自动构建,且借助P-tuning,GPT在SuperGLUE上的成绩首次超过了同等级别的BERT模型,这颠覆了在那年之前“GPT不擅长NLU”的结论,也是该论文命名的缘由
P-tuning和prefix tuning类似,也放弃了“模版由自然语言构成”这一常规要求,从而将模版的构建转化为连续参数优化问题。
下图是一个prompt search针对“The capital of Britain is [MASK]”(英国的首都是哪个城市)的例子。即给定上下文(蓝色区域,“英国”)和目标(红色区域,“[MASK]”),橙色区域指的是提示符号prompt tokens。

- 在(a)中,提示生成器只收到离散的奖励。
- 在(b)中,伪prompt和prompt encoder可以以可微的方式进行优化,有时,在(b)中添加少量与任务相关的anchor tokens(如“capital”)将带来进一步的改进。
换言之,P-tuning做法是用一些伪prompt代替这些显式的prompt (说白了,将自然语言提示的token,替换为可训练的嵌入)。
具体的做法是可以用预训练词表中的unused token作为伪prompt「BERT的vocab里有unused 1 ~ unused99,就是为了方便增加词汇的」,然后通过训练去更新这些token的参数
也就是,P-tuning的prompt Prompt不是显式的,不是我们可以看得懂的字符,而是一些隐式的、经过训练的、模型认为最好的prompt token
但相比prefix-tuning:
- P-Tuning v1加了可微的virtual token,但是仅限于输入层(embedding层),没有在每一层都加;
- virtual token的位置也不一定是前缀,插入的位置是可选的,这里的出发点实际是把传统人工设计模版中的真实token替换成可微的virtual token。
总结来说,P-tuning实际上在两个方向做了优化:
- 需要被MASK的token如何选择:P-tuning v1中通过MLP或者LSTM选择
- 需要参与微调的参数量级:P-tuning v1 中仅更新embedding层中virtual token的部分参数
为什么P-tuning要先经过MLP或者LSTM选择virtual token呢?
论文提到,经过预训练的LM的词嵌入已经变得高度离散,如果随机初始化virtual token,容易优化到局部最优值。因此,作者通过实验发现用一个提示编码器(即用一个LSTM+MLP去编码这些virtual token以后,再输入到模型)来编码会收敛更快,效果更好。
所以说,当预训练模型足够大的时候,可能无法finetune整个模型,而P-tuning可以选择只优化几个Token的参数,因为优化所需要的显存和算力都会大大减少,所以P-tuning实则上给了我们一种在有限算力下调用大型预训练模型的思路。
4.2 P-Tuning V2
P-Tuning V2:在输入前面的每层(所有层)加入可微调的参数(类似于Prefix Tuning)。
然而,P-tuning依然在下面两点上有其对应的局限:
- 规模通用性:在Fixed LM Prompt Tuning并采用全量数据的前提下,Prompt Tuning (The Power of Scale for Parameter-Efficient Prompt Tuning) 被证明能够匹敌Fine-tuning的效果,而只需要很少的参数微调:但是要求是10B以上的参数量的预训练模型,以及特殊的初始化技巧等。
对于普通模型,能不能在Fixed LM Prompt Tuning+全量数据情况下匹敌Fine-tuning? - 任务通用性:尽管P-tuning在SuperGLUE上表现很好,对于一些比较难的token-level的任务表现就差强人意了,比如阅读理解和NER,当然现在也有一些工作在用prompt做序列标注(template-NER,lightNER,template-free NER)。还有一个问题是,不是所有标签都有明确的语义,verbalizer这边映射的label words都是有具体含义的,对于一些没有label语义的分类任务应该怎么办,比如用户评论的聚类等。
为了解决上面两个痛点,发表于2022年的此篇论文《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》提出了P-tuning的V2版本。

其有以下几个特点:
- Deep Prompt Tuning on NLU。
采用Prefix-tuning的做法,在输入前面的每层加入可微调的参数 - 去掉重参数化的编码器。
以前的方法利用重参数化功能来提高训练速度和鲁棒性(例如,用于prefix-tunning的 MLP 和用于 P-tuning的 LSTM)。在 P-tuning v2 中,作者发现重参数化的改进很小,尤其是对于较小的模型,同时还会影响模型的表现 - 可选的多任务学习。
Deep Prompt Tuning的优化难题可以通过增加额外的任务数据或者无标注数据来缓解,同时可微调的prefix continuous prompt也可以用来做跨任务的共享知识。比如说,在NER中,可以同时训练多个数据集,不同数据集使用不同的顶层classifer,但是prefix continuous prompt是共享的 - 回归传统的CLS和token label classifier。
主要是为了解决一些没有语义的标签的问题
五、LoRA:低秩适应
5.1 工作原理
LoRA 是 Low-Rank Adaptation 或 Low-Rank Adaptors的首字母缩写词,它提供了一种高效且轻量级的方法,用于微调预先训练好的的大语言模型。
LoRA的核心思想是用一种低秩的方式来调整这些参数矩阵。LoRA通过保持预训练矩阵(即原始模型的参数)冻结(即处于固定状态),并且只在原始矩阵中添加一个小的增量,其参数量比原始矩阵少很多。
例如,考虑矩阵 W,它可以是全连接层的参数,也可以是来Transformer中计算自注意力机制的矩阵之一:

显然,如果 W o r i g W_{orig} Worig 的维数为 n×m,而假如我们只是初始化一个具有相同维数的新的增量矩阵进行微调,虽然我们也实现类似的功能,但是我们的参数量将会加倍。 LoRA使用的Trick就是通过训练低维矩阵 B 和 A ,通过矩阵乘法来构造 ΔW ,来使 ΔW 的参数量低于原始矩阵。

这里我们不妨定义秩 r,它明显小于基本矩阵维度 r≪n 和 r≪m。则矩阵 B 为 n×r,矩阵 A 为 r×m。将它们相乘会得到一个维度为 nxm的W 矩阵,但构建的参数量减小了很多。
LoRA原理见下图:具体来说就是固定原始模型权重,然后定义两个低秩矩阵作为新增weight参与运算,并将两条链路的结果求和后作为本层的输出,而在微调时,只梯度下降新增的两个低秩矩阵。

此外,我们希望我们的增量ΔW在训练开始时为零,这样微调就会从原始模型一样开始。因此,B通常初始化为全零,而 A初始化为随机值(通常呈正态分布)。
- 扩展问题1:A和B的初始化方式是否可以互换呢?
答:可以互换。LoRA的原作者在Github的issues上进行了回复,这里是可以互换A和B的初始化方式的。- 扩展问题2:为什么A和B里面需要有一个全零的矩阵?
答:为了保证在训练的初始阶段,增量ΔW从零开始。
5.2 微调方式
关于LoRA微调参数的选择,可以参考博客:【大模型】LoRA微调时如何选择参数
(1)选择目标层
首先,在预训练神经网络模型中选择要应用LoRA的目标层。这些层通常是与特定任务相关的,如自注意力机制中的查询Q和键K矩阵。
值得注意的是,原则上,我们可以将LoRA应用于神经网络中权矩阵的任何子集,以减少可训练参数的数量。在Transformer体系结构中,自关注模块(Wq、Wk、Wv、Wo)中有四个权重矩阵,MLP模块中有两个权重矩阵。我们将Wq(或Wk,Wv)作为维度的单个矩阵,尽管输出维度通常被切分为注意力头。
(2)初始化映射矩阵和逆映射矩阵
为目标层创建两个较小的矩阵A和B,然后进行变换。
参数变换过程:将目标层的原始参数矩阵W通过映射矩阵A和逆映射矩阵B进行变换,计算公式为: W ′ = W + A ∗ B W' = W + A * B W′=W+A∗B,这里W’是变换后的参数矩阵。
其中,矩阵的大小由LoRA的秩(rank)和alpha值确定。

(3)微调模型
使用新的参数矩阵替换目标层的原始参数矩阵,然后在特定任务的训练数据上对模型进行微调。
(4)梯度更新
在微调过程中,计算损失函数关于映射矩阵A和逆映射矩阵B的梯度,并使用优化算法(如Adam、SGD等)对A和B进行更新。
注意:在更新过程中,原始参数矩阵W保持不变。其实也就是训练的时候固定原始PLM的参数,只训练降维矩阵A与升维矩阵B (W is frozen and does not receive gradient updates, while A and B contain trainableparameters )
(5)重复更新
在训练的每个批次中,重复步骤3-5,直到达到预定的训练轮次(epoch)或满足收敛条件。
且当需要切换到另一个下游任务时,可以通过减去B A然后添加不同的B’ A’来恢复W,这是一个内存开销很小的快速操作。
When we need to switch to another downstream task, we can recover W0 by subtracting BA andthen adding a different B0A0, a quick operation with very little memory overhead.
总之,LoRA的详细步骤包括:选择目标层、初始化映射矩阵和逆映射矩阵、进行参数变换和模型微调。在微调过程中,模型会通过更新映射矩阵U和逆映射矩阵V来学习特定任务的知识,从而提高模型在该任务上的性能。
5.3 DeepSpeed-Chat的LoRA实现
微软DeepSpeed-Chat的实现中,当设置LoRA的低秩维度lora_dim(如lora_dim=128)时,即认为启用了LoRA训练,则将原始模型中名称含有“deoder.layers.”且为线性层修改为LoRA层,具体操作为:
- 将原始结构的weight参数冻结;
- 新引入了2个线性层lora_right_weight和lora_left_weight (分别对应上图中的降维矩阵A、升维矩阵B ),可实现先降维至lora_dim再升维回原维度;
- LoRA层主要实现了两分支通路,一条分支为已被冻结weight参数的原始结构、另一条分支为新引入的降维再升维线性层组
5.4 PEFT库的LoRA实现
Huggingface公司推出的PEFT(Parameter-Efficient Fine-Tuning,即高效参数微调之意) 库也封装了LoRA这个方法,PEFT库可以使预训练语言模型高效适应各种下游任务,而无需微调模型的所有参数,即仅微调少量(额外)模型参数,从而大大降低了计算和存储成本。
Huggingface的PEFT库 (peft/src/peft/peft_model.py at main · huggingface/peft · GitHub)支持以下流行的方法:
- LoRA:PEFT对LoRA的实现封装见:peft/src/peft/tuners/lora.py at main · huggingface/peft · GitHub)
- Prefix Tuning: Prefix-Tuning: Optimizing Continuous Prompts for Generation, P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
- P-Tuning: GPT Understands, Too
- Prompt Tuning: The Power of Scale for Parameter-Efficient Prompt Tuning
六、QLoRA:模型量化Quant + LoRA
6.1 工作原理
QLoRA于今23年5月份通过此篇论文《QLORA: Efficient Finetuning of Quantized LLMs》被提出,本质是对LoRA的改进,相比LoRA进一步降低显存消耗。
QLoRA 同时结合了模型量化 Quant 和 LoRA 参数微调两种方法,因此可以在单张48GB的 GPU 上对一个65B 的大模型做 finetune。QLoRA 的量化方法(由 bitsandbytes 库提供 backend)也是 Transformers 官方的模型量化实现。
- LoRa为LLM的每一层添加了少量的可训练参数(适配器),并冻结了所有原始参数。这样对于微调,只需要更新适配器权重,这可以显著减少内存占用。
- 而QLoRa更进一步,引入了4位量化、双量化和利用nVidia统一内存进行分页。
这些步骤都大大减少了微调所需的内存,同时性能几乎与标准微调相当。下图总结了不同的微调方法及其内存需求,其中的QLoRA通过将模型量化到4位精度并使用分页优化器管理内存峰值来改进LoRA。

6.2 模型量化
具体内容参考博客:https://blog.csdn.net/v_JULY_v/article/details/132116949
七、各微调方法对比分析
参考博客:大模型微调方法对比分析:Prompt Tuning、Prefix-Tuning、P-Tuning、Adapter Tuning
7.1 核心思想对比
(1)Prompt Tuning
- 核心思想:仅修改 输入层(embedding层) 的参数,在输入层添加 可学习的连续提示向量(soft prompts),仅训练这些提示,冻结模型。
- 参数调整方式:仅修改embedding 层的输入。
(2)Prefix Tuning
- 核心思想:在 每一层(或注意力层) 添加 可学习的前缀向量,通过注意力机制影响模型所有层。
- 参数调整方式:插入前缀到每一层的 key/value 序列(所有层)。
(3)P-Tuning
- 核心思想:
- P-Tuning v1:将离散提示替换为可学习的连续向量,并通过prompt encoder(例如BiLSTM+MLP)来优化prompt参数。
- P-Tuning v2:扩展到多层(类似于Prefix Tuning)
- P-Tuning 最大的特点是将通过引入BiLSTM/MLP的方法,使得模型可以更好的完成NLU任务。
- 参数调整方式:
- P-Tuning v1:输入层(embedding层)。
- P-Tuning v2:每一层(所有层,类似于Prefix Tuning)。
(4)LoRA
- 核心思想:通过 低秩分解 模拟权重更新( Δ W = B A \Delta W=BA ΔW=BA),仅训练小矩阵A和B,冻结原始权重。
- 参数调整方式:直接修改特定权重矩阵,如Q/K/V。

7.2 实现方式与参数位置
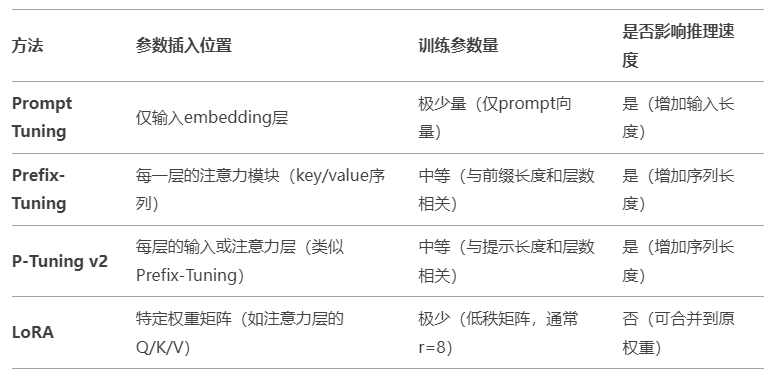
7.3 适用场景与优缺点
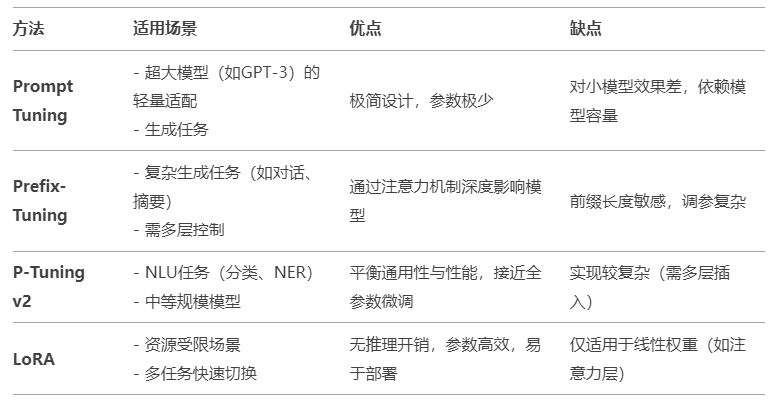
7.4 关键区别总结
-
参数作用范围:
- Prompt Tuning仅修改输入层
- Prefix/P-Tuning v2影响所有层
- LoRA直接调整权重矩阵
-
任务适应性:
- Prefix/P-Tuning更适合生成任务
- LoRA通用性更强
- Prompt Tuning依赖大模型
-
推理效率:
- LoRA唯一无损推理(可合并参数)
- 其他方法会增加序列长度或计算层数

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









