






C++ STL string :深入浅出 从入门到实战
你好,这里是新人 Sunfor
这篇是我最近对于C++ STL string的学习心得和错题整理
有任何错误欢迎指正,欢迎交流!
会持续更新,希望对你有所帮助,我们一起学习,一起进步

前言 : 为什么需要字符串类?
在C语言时代,开发者需要手动管理字符数组,容易遇到缓冲区溢出和内存泄漏等问题,这些问题使得处理文本数据变得复杂且危险。为了解决这些问题,C++标准库中的std::string 应运而生,成为现代C++开发中处理文本数据的核心开发工具。接下来,本文将介绍如何掌握这一强大的容器类,帮助大家更好地管理和操作字符串数据。
一、string的本质
1.1 什么是string
string 是C++ 标准模板库 — STL 提供的动态字符串类,定义于头文件中,实质是basic_string 模板类的特化版本,它封装了字符序列的存储与管理,是传统C风格字符数组 — char[ ]的现代化替代方式
1.2 与C语言中字符串对比
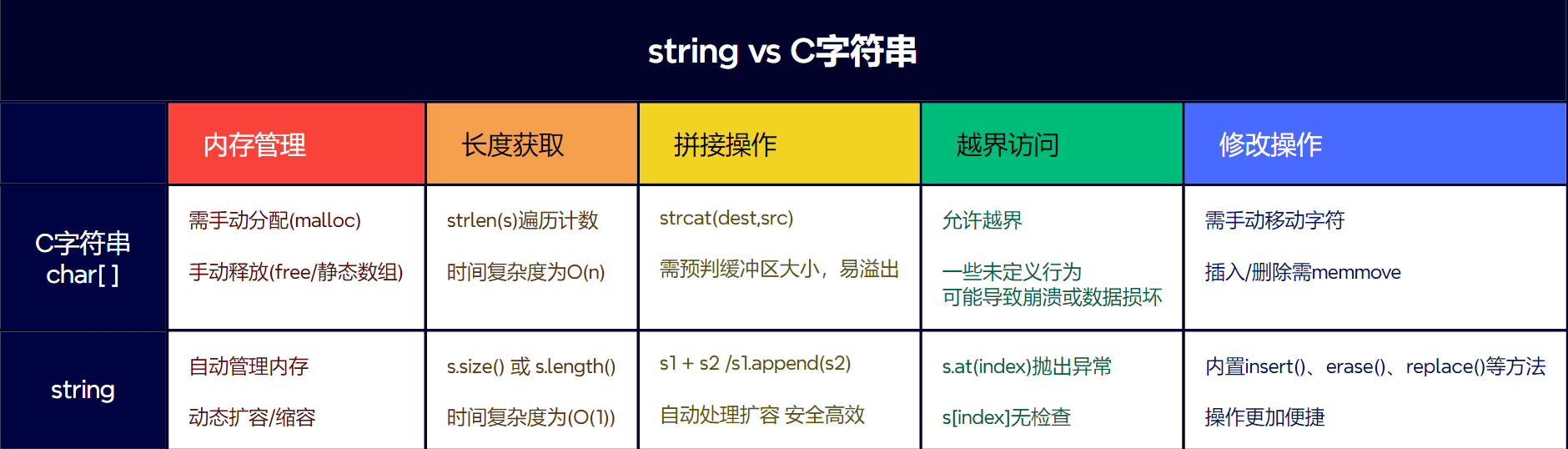
1.2.1 什么时候使用C字符串?
- 嵌入式开发: 内存极度受限且需避免动态分配
- 跨语言交互:与纯C库API直接交互,需注意生命周期管理
- 性能敏感场景:固定小文本的极高频操作,需充分测试验证
二、使用string的五大核心优势
2.1 安全性保障:构建代码防护屏障
- 自动扩容机制
问题背景:C语言中strncat等函数需手动计算目标缓冲区剩余空间,极易因计算错误导致缓冲区溢出
string如何解决:append()方法自动检测容量,若空间不足,则触发动态扩容,完全避免溢出风险- 边界安全防护
at()方法:提供带异常的安全访问,越界时抛出
std::out_of_range异常,便于错误捕获与处理
operator[ ] 对比:直接下标访问无检查,性能高,但需要开发者自行确保索引合法
2.2 开发效率提升:代码简洁之道
- 操作符重载
if(s1 == s2){...} //替代 strcmp()
s1 += s2; //替代strcat()
s3 = s1 + " "+ s2;//链式拼接
全面支持:包括 ==、!=、<、>、+、+=等运算符,代码可读性显著提高
- 链式调用
方法设计:成员函数返回string& 支持连续操作,简化多步骤修改:
s.append("World");
.erase(0,5);
.insert(0,"Hello");
2.3 功能高度集成:一站式解决方案
- 常用操作内置
查找与替换:
size_t pos = s.find("bug");
if(pos != string::npos)
{
s.replace(pos,3,"feature");//找到具体的位置进行替换
}
子串提取:
string sub = s.substr(2,5);//从索引2截取到索引5
- 正则表达式
#include<regex>
regex pattern(R"(\d{3}-\d{8})");
if(regex_search(s,pattern))
{
cout << "找到电话号码";
}
2.4 内存优化机制:性能与资源的平衡
- 短字符串优化
实现多数编译器 将长度 <= 15 的字符串直接存储在对象内部栈空间,避免堆分配开销 使短字符串操作效率接近静态数组- 容量精细控制
使用reserve() 提前分配足够容量 减少扩容次数
使用shrink_to_fit() 释放多余内存
string s;
s.reserve(1000);
s = "Hello";
s.shrink_to_fit();//收缩至实际大小
2.5 生态兼容性:无缝衔接C++
- 流式交互
直接与标准流对象协作,支持格式化输入输出
string name;
cout << "请输入姓名:" ;
cin >> name ;
cout << name << "你好" << endl;
- SLT算法兼容
泛式编程支持:暴露迭代器接口,可以直接使用中的100+算法;
sort(s.begin(),s.end());
auto it = find(s.begin(),s.end(),'x');
- 跨API桥梁
通过c_str()和data() 与C接口兼容
void legacy_print(const char* str);
legacy_print(s.c_str());
三、从零开始使用string
3.1 基础操作
- 初始化方式:灵活构建字符串
//基础初始化
string s1;//默认构造 空字符串 不分配堆内存
string s2("Hello");//C风格字符串构造 自动计算长度
string s3(5, 'A');//重复字符构造 5个'A' "AAAAA"
string s4(s2, 1, 3);//子串构造 从索引1取3字符 长度超限则截断
//s4(s2,start,length) start > s2.size 则触发out_of_range异常
string s5 = "happy everyday"sv; //sv表示一个轻量级的只读字符串视图
//将s2的资源转移到s6 s6接管了原本属于s2的堆内存 避免拷贝操作 提高性能
string s6(move(s2));//移动后 s2的状态变为空字符串
string s7{"trying you best"};// 用大括号统一初始化
- 字符串拼接:多策略与性能优化
//运算符重载
string greeting = "Hello, " + name + "!";//隐式构造临时对象
s2.append("World")
.push_back('!');
//高性能拼接
s2.reserve(50);
.push_back('!')
s2 += "Welcome";
s2.append(3, '!');
ostringstream oss;
oss << "Value:" << 42 <<",PI: " << 3.1415;
string complex_str = oss.str;
- 元素访问 : 安全与效率的权衡
//快速访问
char first = s2[0];
char last = s2[s2.size() - 1];
try
{
char c = s2.at(100);
}
catch (const exception& e)
{
cerr << "ERROR:" << e.what();
}
修改内容
s2.front() = 'h';
s2.back() = '?';
- 长信息获取: 深入理解容量管理
//基础信息
if(!s1.empty())
{
cout << "Length:" << s1.size( << endl;)
}
//容量管理
s2.reserve(100);
cout << "Capacity:" << s2.capacity() << endl;
s2.shrink_to_fit();
3.2 进阶操作
- 查找与替换:精确的文本操作
//单次查找替换
string s1 = "hello world";
size_t pos = s1.find("world");
if(pos != string::npos)
{
s2.replace(pos,5,"C++");
}
//全局替换
string text = "apple,apple,apple";
size_t start = 0;
while(pos = text.find("apple",start) != string::npos)
{
text.replace(pos,5,"orange");
start = pos + 6;//跳过被替换的部分
}
//高级替换
replace_if(text.begin(),text.end(),[](char c){return isdigit(c);},'#');
- 子串提取分割:结构化数据处理
//基础子串提取
string s = "Welcome to C++ world!";
string sub = s.substr(6,3);
//分割字符串
vector<string> tokens;
size_t pos = 0;
while((pos = s.find(' ',start)) != string::npos)
{
tokens.push_back(s2.substr(start,pos-start));
start = pos + 1;
}
tokens.push_back(s.substr(start));
//使用stringstream分割
istringstream iss("data1,data2,data3");
string item;
while(getline(iss,item,','))
{
//处理每个分割后的数据
}
- 修改操作:精细控制内容
//插入与删除
string s = "Hello C++!";
s.insert(5,"Dear");
s.erase(0,6)
//批量修改
s.replace(s.begin(),s.begin()+4,"####");
//清空与重置
s.clear();
s = "New string";
//交换内容
string s_temp = "Temp";
s2.swap(s_temp);
- 迭代器遍历:兼容STL算法
//传统迭代器
for(auto it = s.begin();it!=s.end();)
{
if(*it == ' ');
{
it = s2.erase(it);
}
else
{
++it;
}
}
//反向迭代器
for(auto rit = s.rbegin();rit!=s.rend();++rit)
{
cout << *rit;
}
//结合算法库
sort(s2.begin(),s2.end());
auto uniq_end = unique(s2.begin(),s2.end());
s2.erase(uniq_end,s2.end());
- C字符串转换:兼容传统接口
//安全转换
const char* cstr = s2.c_str();//只读
//可写缓冲区拷贝
char buffer[50];
size_t copied = s2.copy(buffer,sizeof(buffer)-1);//避免溢出
buffer[copied] = '\0';//手动添加终止符
//风险操作
strcpy(buffer,s2.data());
四、实践中的注意事项
- 1.短字符串优化:通过union实现栈内存与堆内存的自动切换
使用条件如下:
if(length <= 15)
{
store_in_local_buffer();//栈存储
}
else
{
allocate_dynamic_memory();//堆存储
}
常见误区:
string s(1000,'x');
s.clear();//仅清空数据 capacity仍为1000
如何正确处理:
s.shrink_to_fit();//请求释放内存
assert(s.capacity() <= s.size());//验收收缩结果
- 2.reserve()预分配
使用条件:
- 已知或可估算字符串最终长度
- 涉及连续大量追加操作
常见误区:
str.reserve(10000);//盲目预分配导致内存浪费
for(int i = 0;i < le6;i++) str += data;//未预分配 导致多次扩容
正确处理:
//动态计算预分配量
size_t estimated_len = base_len * 1.3;
str.reserve(estimated_len);
//监控扩容次数验证效果
auto old_cap = str.capacity();
str.append(data);
if(str.capacity()!= old_cap)
{
cout << "发生扩容,需调整预估值";
}
- 3.c_str() C接口交互
使用条件:
- 需要向C语言传递字符串
- 临时获取不可变字符指针
常见误区
const char* p = str.c_str();
str += "修改内容";//可能导致p失效
fprintf(file,p);//未定义行为
char buf[10];
strcpy(buf,str.c_str());//未检查长度导致溢出
正确处理
//安全生命周期
{
string tmp = get_data();
legacy_api(tmp.c_str());//限制tmp的作用域
}
//带长度检查拷贝
if(str.size()< buf_size)
{
str.copy(buf,str.size());
buf[str.size()] = '\0';
}
- 4.substr()子串操作
使用条件:
- 截取已知安全范围的子串
- 处理单字节编码文本
常见误区
//mistake:多字节字符截断
string cn = "桑芙芙酱";
cout << cn.substr(1, 2);//输出乱码
//mistake:越界访问
string s = "abc";
s.substr(5, 2);
正确处理
//使用ICU库处理Unicode
UnicodeString ustr = UnicodeString::fromUTF8(cn);
ustr.tempSubString(1,2).toUTF8String(result);
//安全边界检查
size_t start = std::min(pos,s.length());
size_t count = std::min(len,s.length()-start);
s.substr(start,count);
- 5.append()高效拼接
使用条件:
- 需要连续追加多个数据片段
- 涉及不同类型数据转换
常见误区
str += "A" + to_string(num) + "B";
//类型混淆风险
str.append(100,'X');
str.append(100,65);//添加了100个'A'
正确处理
//批量化操作
str.reserve(total_len);
str.append(datal).append(data2).append(data3);
//类型安全转换
ostringstream oss;
oss << fixed << setprecision(2) << 3.1415;
str.append(oss.str());
五、例题解析
(1) c_str()理解运用
//关于代码输出的正确结果是
#include<iostream>
#include<string.h>
using namespace std;
int main(int argc, char *argv[])
{
string a="hello world";
string b=a;
if (a.c_str()==b.c_str())
{
cout<<"true"<<endl;
}
else cout<<"false"<<endl;
string c=b;
c="";
if (a.c_str()==b.c_str())
{
cout<<"true"<<endl;
}
else cout<<"false"<<endl;
a="";
if (a.c_str()==b.c_str())
{
cout<<"true"<<endl;
}
else cout<<"false"<<endl;
return 0;
}
分析:
c_str()比较的是指针地址,而非字符串的内容
a和b的值虽然相同,但是a和b是两个不同的对象,内部数据存储的位置也不相同,所以第一次比较输出false
c="“只改变c的内容,不改变c的地址,更不改变b,所以第二次比较输出的还是false
a=”"也同理可得,第三次比较同样输出false
(2) 字符串查找及npos使用
//下面程序的输出结果正确的是
int main(int argc, char *argv[])
{
string strText = "How are you?";
string strSeparator = " ";
string strResult;
int size_pos = 0;
int size_prev_pos = 0;
while((size_pos=strText.find_first_of(strSeparator, size_pos)) != string::npos)
{
strResult = strText.substr(size_prev_pos, size_pos-size_prev_pos);
cout<<strResult<<" ";
size_prev_pos = ++size_pos;
}
if(size_prev_pos != strText.size())
{
strResult = strText.substr(size_prev_pos, size_pos-size_prev_pos);
cout<<strResult<<" ";
}
cout<<endl;
return 0;
}
分析:

(3)string运用
字符串相加:
给定两个字符串形式的非负整数 num1 和num2 ,计算它们的和并同样以字符串形式返回。
你不能使用任何內建的用于处理大整数的库(比如 BigInteger), 也不能直 接将输入的字符串转换为整数形式。
分析:
不能将字符串转换为整形 所以我们就需要逐位相加 管理进位 从而实现两个长整数的字符串相加
最后返回的结果还是字符串 所以要注意将进位后的字符串进行反转
class Solution {
public:
string addStrings(string num1, string num2) {
int i = num1.size() - 1;//初始化为num1的最后一个索引
int j = num2.size() - 1;//初始化为num2的最后一个索引
int carry = 0;//用于存储进位
string result;//存储最后的和
result.reserve(max(num1.size(), num2.size()) + 1);//预先为结果分配内存,用于提高性能
while(i >= 0|| j >= 0|| carry >0)
{
int sum = carry;
if (i >= 0) sum += num1[i--] - '0';
//将字符转换为数字加到sum中
if (j >= 0) sum += num2[j--] - '0';
carry = sum / 10;//整除10得到下一个进位
sum = sum % 10;//取模10得到当前位的和
result += ('0' + sum);
}
if(carry == 1)
{
result += '1';//如果处理完所有位后还有进位 则将其添加到结果中
}
reverse(result.begin(),result.end());//反转最终的结果
return result.empty() ? "0" : result;
}
};
找出字符串中的第一个唯一字符
给定一个字符串 s ,找到 它的第一个不重复的字符,并返回它的索引 。如果不存在,则返回 -1
分析:
因为给定的字符串都是字母 所以可以开辟一个数组 统计数组中字符出现的次数 再遍历一次数组 将统计后值为1的字符输出
class Solution {
public:
int firstUniqChar(string s) {
//因为对应的都是小写字母 所以开辟一个26个字符的数组
int count[26] = {0};
//统计次数
for(auto ch : s)
{
//出现就++
count[ch - 'a']++;
}
//怎么找只出现一次的字符
//再用下标去遍历
for(size_t i = 0;i < s.size();++i)
{
if(count[s[i] - 'a'] == 1)
return i;
}
return -1;
}
};
字符串相乘
给定两个以字符串形式表示的非负整数 num1 和 num2,返回 num1 和 num2 的乘积,它们的乘积也表示为字符串形式。
注意:不能使用任何内置的 BigInteger 库或直接将输入转换为整数。
分析:
逐位相乘,从低位到高位遍历两个数的每一位,计算乘积并累加到结果字符串的对应位置,实时更新进位,确保每一位的值不超过9,乘积的位置符合手工计算的规则,最后要去除前导零,确保格式的正确
class Solution {
public:
string multiply(string num1, string num2) {
if (num1 == "0" || num2 == "0") return "0";
const int n = num1.size(), m = num2.size();
string res(n + m, '0');
// 预处理为数字数组(避免重复转换)
int* pre_num1 = new int[n]; // 动态数组替代vector
int* pre_num2 = new int[m];
for (int i = 0; i < n; i++) pre_num1[i] = num1[i] - '0';
for (int j = 0; j < m; j++) pre_num2[j] = num2[j] - '0';
// 主计算逻辑
for (int i = n-1; i >= 0; i--) {
int carry = 0; // 实时进位追踪
int x = pre_num1[i];
for (int j = m-1; j >= 0; j--) {
int y = pre_num2[j];
int pos = i + j + 1;
// 单次计算包含当前乘积和进位
int total = x * y + (res[pos] - '0') + carry;
res[pos] = (total % 10) + '0';
carry = total / 10; // 更新进位
}
res[i] += carry; // 处理每行最后的进位
}
delete[] pre_num1; // 释放内存
delete[] pre_num2;
// 去除前导零
size_t pos = res.find_first_not_of('0');
return (pos != string::npos) ? res.substr(pos) : "0";
}
};

















 1290
1290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









