







鸣谢:该项目基于刘焕勇老师、IrvingBei这两位的代码启发下,才有了我这么一个辣鸡项目。期间我的学业导师,给了我很多指导帮助。站在前人的肩膀上,我们可以看得更远
摘要:知识图谱与自然语言的处理技术的结合使用愈发广泛,已经成为各大搜索引擎公司所重视的领域之一。尽管目前科技创新和普及中医药知识工作的稳步推进,但对于中医药领域中复杂的中药信息数据如何可视化分析与检索仍然是一个难以解决的问题。为此本研究立足中药领域,以垂直型中医药网站的本草纲目开源数据为数据来源,搭建了一个包含9类规模为7k的知识实体,7种关系的中药知识图谱。并在该知识图谱的基础上实现了中药知识自动问答和辅助开药方的功能。该系统的实现对于提升中医药知识在大众中的普及、为中医药临床实践、科研及教学提供决策支持上都有着重要意义和参考价值。
什么是知识图谱?
知识图谱是一种描述真实世界客观存在的实体、概念及它们之间关联关系的语义网络。它充分釆用了可视化的技术,不仅能够对知识资源和载体进行描述,同时还可以对知识以及知识之间的联系进行分析和描绘。在大数据存储技术支持下,大规模的知识图谱与数据挖掘、机器学习、信息分析等技术相结合,可以实现利用图形将复杂的知识领域绘制并展现出来。Google 早在 2012 年就发布了“知识图谱”,增强了其搜索结果的智能性,将互联网的信息表达成了更接近人类认知世界的形式,这标志着大规模知识在互联网语义搜索中的成功应用,知识图谱提供了一种更好的组织、管理和理解互联网海量信息的能力,它与大数据和深度学习一起,成为推动人工智能发展的核心驱动力[1]。知识图谱分为通用知识图谱和行业知识图谱,典型的通用知识图谱包括:面向语言的WordNet,大规模开放的知识图谱Yago、DBPedia和Freebase等[2-7];典型的行业知识图谱包括:描述人物亲属关系的Kinships、医疗领域图谱UMLS及中国中医科学院中医药信息所研制的中医药学语言系统(Traditional Chinese Medicine Language System,TCMLS)。
其中,TCMLS是以中医药学科体系为核心,遵循中医药语言学特点,借鉴语义网络的理念,建立的一个中医药学语言集成系统。它共收录约10万个概念、30万个术语及127万条语义关系[8]。近年来,已经有部分学者以TCMLS为骨架,开发了一些中医知识图谱的智能应用。
项目流程
本研究以垂直网站中药网和A+医学网站为主要数据来源,使用爬虫脚本爬取并对网站数据进行结构化处理,再利用Neo4j图数据库构建了中药知识图谱,并利用基于规则匹配算法、关键词匹配以及对问句进行分类等关键步骤实现了中药知识问答和辅助开方。为了提高用户体验与系统可视化程度,本研究又利用web.py框架设计搭建前端问答界面。
总体设计
基于中医药知识图计分为中医药知识图谱的构建和智能问答的搭建
中医药知识图谱的构建
- 数据获取与预处理- 基于Neo4j构建中医药知识图
数据获取与预处理
对于通用知识图谱搭建而言,最主要数据来源于互联网网页上的开源数据。本研究采用自底向上的模式,先从网页中识别出知识实体,再将知识实体归出合适的数据模式。对于通用知识图谱搭建而言,最主要数据来源于互联网网页上的开源数据。本研究采用自底向上的模式,先从网页中识别出知识实体,再将知识实体归纳出合适的数据模式。且这两个网站的数据以结构化数为主,基于这一特点,我们在爬取数据的时候,很容易通过网站结构化的信息抽取出相关实体和属性概念。对网页的结构化数据进行xpath解析,赋予相应的标签,得到的数据以excel表形式存储,然后将这些表格数据导入Neo4j数据库。
import requests
from lxml import html
import pandas
from openpyxl import Workbook
import re
class zhongyao():
def __init__(self):
self.text_all = dict()
self.url="http://www.a-hospital.com/w/%E6%9C%AC%E8%8D%89%E7%BA%B2%E7%9B%AE"
self.headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36"}
def get_parse_html(self,url): #将网页源代码转换成xpath对象的函数
res=requests.get(url,headers=self.headers)
res.encoding = "utf-8"
html_text = res.text
parse_html = html.etree.HTML(html_text)#将网页源代码转换成xpath对象
return parse_html
def get_url(self):
res=requests.get(self.url,headers=self.headers)
res.encoding="utf-8"
en = html.etree.HTML(res.text)
text_title=en.xpath('//h3/span[@class="mw-headline"]/text()')
text_url1 = en.xpath('//*[@id="bodyContent"]/p[5]/a/@href')
self.get_nate(text_url1)
text_url2 = en.xpath('//*[@id="bodyContent"]/p[6]/a/@href')
text_url3 = en.xpath('//*[@id="bodyContent"]/p[7]/a/@href')
# self.get_nate(text_url3)
text_url4 = en.xpath('//*[@id="bodyContent"]/p[8]/a/@href')
#self.get_nate(text_url4)
text_url5 = en.xpath('//*[@id="bodyContent"]/p[9]/a/@href')
#self.get_nate(text_url5)
text_url6 = en.xpath('//*[@id="bodyContent"]/p[10]/a/@href')
# self.get_nate(text_url6)
text_url7 = en.xpath('//*[@id="bodyContent"]/p[11]/a/@href')
# self.get_nate(text_url7)
text_url8 = en.xpath('//*[@id="bodyContent"]/p[12]/a/@href')
# self.get_nate(text_url8)
text_url9 = en.xpath('//*[@id="bodyContent"]/p[13]/a/@href')
# self.get_nate(text_url9)
text_url10 = en.xpath('//*[@id="bodyContent"]/p[14]/a/@href')
#self.get_nate(text_url10)
text_url11 = en.xpath('//*[@id="bodyContent"]/p[15]/a/@href')
# self.get_nate(text_url11)
text_url12 = en.xpath('//*[@id="bodyContent"]/p[16]/a/@href')
# self.get_nate(text_url12)
text_url13 = en.xpath('//*[@id="bodyContent"]/p[17]/a/@href')
# self.get_nate(text_url13)
text_url14 = en.xpath('//*[@id="bodyContent"]/p[18]/a/@href')
# self.get_nate(text_url14)
text_url15 = en.xpath('//*[@id="bodyContent"]/p[19]/a/@href')
# self.get_nate(text_url15)
def get_text_alias(self,parse_html_text):
try:
alias_data=""
text_alias = parse_html_text.xpath('//*[@id="bodyContent"]/p[1]/text()')
text_alias = ''.join(text_alias)
alias_data = text_alias.split('」')[1]
except:
return ""
return alias_data
def get_text_smell(self, parse_html_text):
try:
smell_data = ""
text_smell = parse_html_text.xpath('//*[@id="bodyContent"]/p[2]/text()')
text_smell = ''.join(text_smell)
smell_data = text_smell.split('」')[1]
except:
return ""
return smell_data
def get_text_cure(self, parse_html_text):
try:
new_cure = ""
text_cure1 = parse_html_text.xpath('//*[@id="bodyContent"]/p[3]/text()')
text_cure2 = parse_html_text.xpath('string(//*[@id="bodyContent"]/p[4])')
text_cure3 = parse_html_text.xpath('string(//*[@id="bodyContent"]/p[5])')
text_cure4 = parse_html_text.xpath('string(//*[@id="bodyContent"]/p[6])')
text_cure1 = ''.join(text_cure1)
text_cure2 = ''.join(text_cure2)
text_cure3 = ''.join(text_cure3)
text_cure4 = ''.join(text_cure4)
new_cure = text_cure1 + text_cure2 + text_cure3 + text_cure4
new_cure = new_cure.split('」')[1]
except:
return ""
return new_cure
# def save(self,row):
# for i in row:
# with open('土部.xlsx', "") as f:
# f.write(i)
def get_nate(self,text_url):
count=0
rows=[]
for link in text_url:#对所有帖子的站内链接进行遍历 拼接完整的帖子链接
t_url="http://www.a-hospital.com"+link#拼接得到帖子的url
parse_html_text=self.get_parse_html(t_url)
text_name = parse_html_text.xpath('//*[@id="firstHeading"]/text()')
text_name = ''.join(text_name)
text_name = text_name.split('/')[1] # 取‘/’右边的
text_alias=self.get_text_alias(parse_html_text)
text_smell=self.get_text_smell(parse_html_text)
text_cure=self.get_text_cure(parse_html_text)
# try:
# text_alias = parse_html_text.xpath('//*[@id="bodyContent"]/p[1]/text()')
# text_alias = ''.join(text_alias)
# text_alias = text_alias.split('」')[1]
# except:
# return text_alias
# try:
# text_smell = parse_html_text.xpath('//*[@id="bodyContent"]/p[2]/text()')
# text_smell = ''.join(text_smell)
# text_smell = text_smell.split('」')[1]
# except:
# text_smell=""
#
#
# try:
# text_cure1 = parse_html_text.xpath('//*[@id="bodyContent"]/p[3]/text()')
# text_cure2 = parse_html_text.xpath('string(//*[@id="bodyContent"]/p[4])')
# text_cure3 = parse_html_text.xpath('string(//*[@id="bodyContent"]/p[5])')
# text_cure4 = parse_html_text.xpath('string(//*[@id="bodyContent"]/p[6])')
# text_cure1=''.join(text_cure1)
# text_cure2=''.join(text_cure2)
# text_cure3=''.join(text_cure3)
# text_cure4=''.join(text_cure4)
# new_cure = text_cure1 + text_cure2 + text_cure3 + text_cure4
# new_cure = new_cure.split('」')[1]
# except Exception:
# return new_cure #对于某些没有主治的异常处理
wb = Workbook()
ws = wb.active
ws['A1'] = 'name'
ws['B1'] = 'alias'
ws['C1'] = 'smell'
ws['D1'] = 'cure'
row=[text_name,text_alias,text_smell,text_cure]
rows.append(row)
#self.save(row)
# print(row)
# ws.append(row)
for new_row in rows:
ws.append(new_row)
count+=1
print(count)
wb.save('草部.xlsx')
# frame = pandas.DataFrame(columns=['name','alias', 'smell','cure'])
# frame['name'] = text_name
# frame['alias'] = text_alias
# frame['smell'] = text_smell
# frame['cure'] = new_cure
# frame.to_excel('./data/草部.xlsx')
# text_cure3= parse_html_text.xpath('string(//*[@id="bodyContent"])')
# a="""「主治」"""
# b="""参考"""
# new_cure = re.search('^1.*?b$',text_cure3,re.S)
#print(row)
zhongyao = zhongyao()
zhongyao.get_url()
获取A+医学百科的数据
from lxml import html
from openpyxl import Workbook
import re
import requests
class zhongyao():
def __init__(self):
self.text_all = dict()
self.url="https://www.zhzyw.com/zyts/pfmf/Index.html"
self.basic_url="https://www.zhzyw.com/"
self.headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36"}
def get_parse_html(self,url): #将网页源代码转换成xpath对象的函数
res=requests.get(url,headers=self.headers)
res.encoding = "gb2312"
html_text = res.text
parse_html = html.etree.HTML(html_text)#将网页源代码转换成xpath对象
return parse_html
def get_one(self,url):#拼接并得到xpath解析的网页
text_url1one = self.basic_url + ''.join(url)
en = self.get_parse_html(text_url1one)
return en
def get_url(self):
en = self.get_parse_html(self.url)
text_url1 = en.xpath('//*[@id="title"]/ul/li[1]/a/@href')
text_url2 = en.xpath('//*[@id="title"]/ul/li[2]/a/@href')
text_url3 = en.xpath('//*[@id="title"]/ul/li[3]/a/@href')
text_url4 = en.xpath('//*[@id="title"]/ul/li[4]/a/@href')
text_url5 = en.xpath('//*[@id="title"]/ul/li[5]/a/@href')
text_url6 = en.xpath('//*[@id="title"]/ul/li[6]/a/@href')
text_url7 = en.xpath('//*[@id="title"]/ul/li[7]/a/@href')
enone = self.get_one(text_url7)
text_urltwo = enone.xpath('//*[@id="left"]/div[4]/ul/li/a/@href') # 获取某一科下面所有秘方
self.get_nate(text_urltwo)
def get_text_part(self,parse_html_text):
try:
text_alias = parse_html_text.xpath('//*[@id="wzdh"]/a[5]/text()')
text_alias = ''.join(text_alias)
except:
return "没找到"
return text_alias
def get_text_drug(self, parse_html_text):
try:
text_smell = parse_html_text.xpath('//*[@id="left"]/h1/text()')
text_smell = ''.join(text_smell)
except:
return "找不到"
return text_smell
def get_text_cure(self, parse_html_text):
try:
text_cure1 = parse_html_text.xpath('//*[@id="left"]/div[2]/text()')
text_cure1 = ''.join(text_cure1)
except:
return "找不到"
return text_cure1
def get_nate(self,text_url):
count = 0
rows = []
for link in text_url:#对所有帖子的站内链接进行遍历 拼接完整的帖子链接
t_url=self.basic_url+link#拼接得到帖子的url
parse_html_text=self.get_parse_html(t_url)
text_name = parse_html_text.xpath('//*[@id="left"]/div[3]/ul/li/a/@href')
for t_link in text_name:
all_url=self.basic_url+t_link
all_html_text=self.get_parse_html(all_url)
text_part=self.get_text_part(all_html_text)
text_drug=self.get_text_drug(all_html_text)
text_prescript=self.get_text_cure(all_html_text)
#print(text_part+"\n"+text_drug+"\n"+text_prescript)
wb = Workbook()
ws = wb.active
ws['A1'] = 'drug'
ws['B1'] = 'prescript'
ws['C1'] = 'part'
row=[text_drug,text_prescript,text_part]
rows.append(row)
for new_row in rows:
ws.append(new_row)
count+=1
print(count)
wb.save(text_part+'.xlsx')
zhongyao = zhongyao()
zhongyao.get_url()
获取中医药网数据
由于代码是去年写的,网站代码修改有些出入,再加上当时写代码水平也不强,有能力的好兄弟可以重构这部分代码。(现在再看这些代码,内心就在想:wc,这代码谁写的)
我们将数据保存以xlsx的数据表形式保存,其实可以以mysql去保存更方便。数据表形式如下
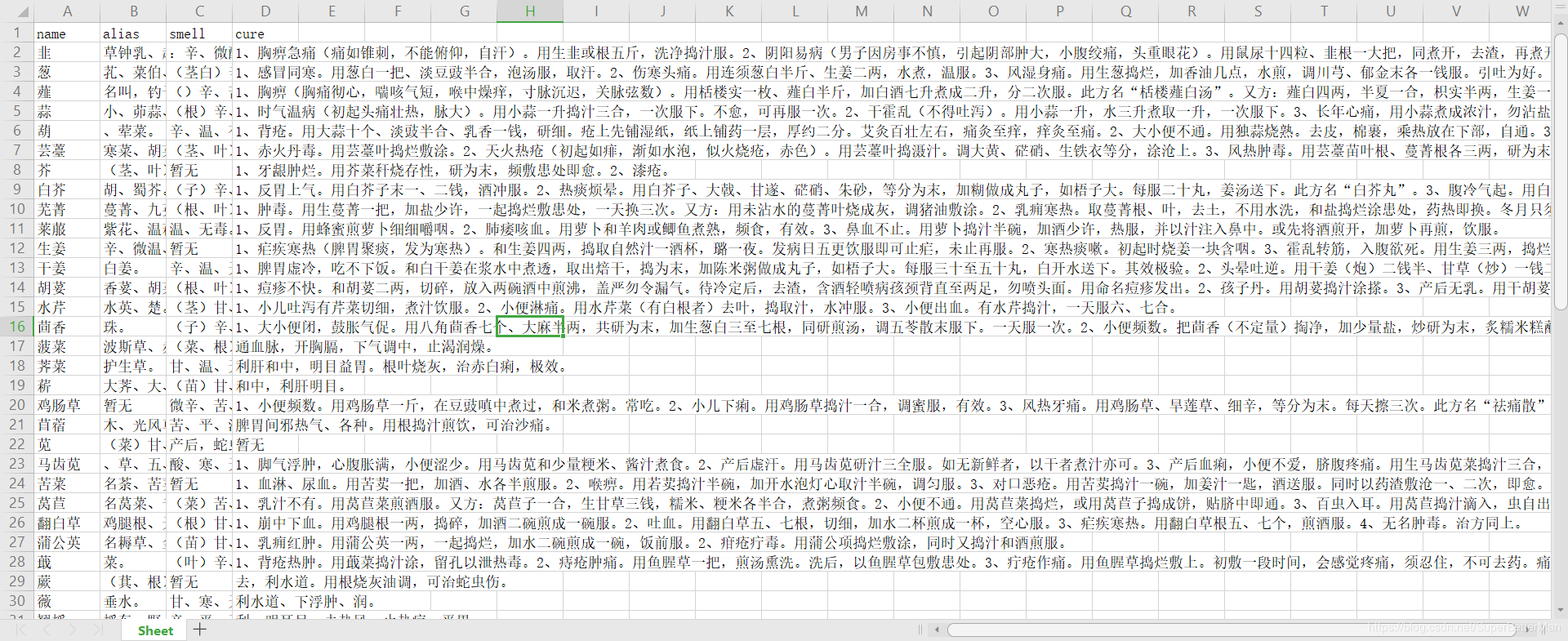
保存的excel表格形式(部分)
基于Neo4j构建中医药知识图谱
为什么要用neo4j
Neo4j是一个高性能的NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。Neo4j的主要优点有:
1)Neo4j图数据库以图的形式来存储数据,能够直接表达数据的关联特性。
2)因为Neo4j图数据库采用非结构化数据格式,具有良好的扩展性。可以任意对数据进行修改,利于后期维护。
3)相比于其他传统关系型数据库,Neo4j图数据库支持图论的常用算法,比如:图的广度遍历、深度遍历算法、A*算法等。
因此本研究采用Neo4j存储数据,通过Python的扩展库py2neo将整理好的excel文件导入到Neo4j图数据库中,即完成了中医药知识图谱的构建。
该部分可查看我之前写过的博客:如何通过python将excel表导入到neo4j
因为是过去的代码,里面有一些方法可能以前过时了。比如说有朋友私信说没有get_value()方法,我说不可能呀。后来我用到的时候才发现pandas库版本更新了,更新后把这个方法舍去了,我们可以用at[i,‘标签’]去代替
基于设计初衷,中医药知识图谱由中药知识图谱和症状药方知识图谱这两个子图谱构成。
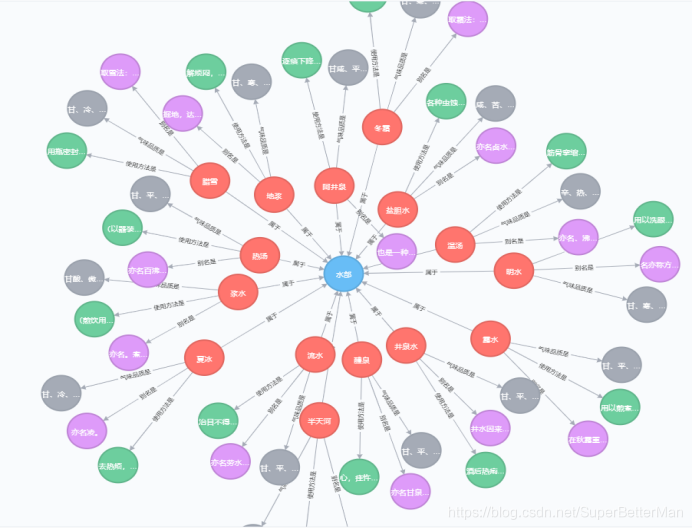
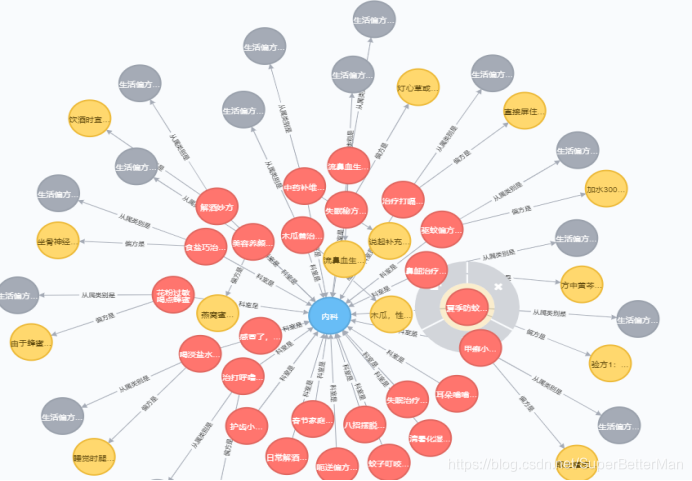
该项目已经上传到我的github,还是老样子,别忘了给我点star,点star,点star(重要的事说三边)
另:上传的是1.0版本,今年我又修改了web框架,由web.py框架修改为flask框架,并且已经部署到我的个人网站上,域名还在备案中,相信很快就可以和大家见面;我和我那优秀的学业导师在这此项目基础上进行了深度研究,研究成果已成功被CCC2020录用,等EI收录后我会把论文上传,供大家学习

















 934
934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









