






3.1 单应性变换
单应性变换是将一个平面内的点映射到另一个平面内的二维投影变换,平面是指图像或三维中的平面表面,单应性变换在图像配准、图像纠正、纹理扭曲和创建全景图像等具有很强的变换性,单应性变换如下矩阵变换定义。
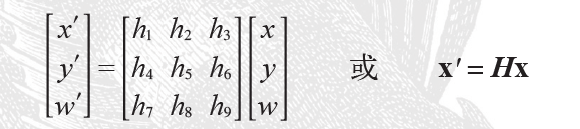
对于图像平面内(甚至是三维中的点,后面我们会介绍到)的点,齐次坐标是个非常有用的表示方式。点的齐次坐标是依赖于其尺度定义的,所以,x=[x,y,w]=[ax,ay,aw]=[x/w,y/w,1]都表示同一个二维点。因此,单应性矩阵H也仅依赖尺度定义,所以,单应性矩阵具有8个独立的自由度。我们通常使用w=1来归一化点,这样,点具有唯一的图像坐标x和y。这个额外的坐标是的我们可以简单地使用一个矩阵来表示变换。
下面的函数可以实现对点进行归一化和转换齐次坐标的功能:
def normalize(points):
""" 在齐次坐标意义下,对点集进行归一化,使最后一行为 1 """
for row in points:
row /= points[-1]
return points
def make_homog(points):
""" 将点集(dim×n 的数组)转换为齐次坐标表示 """
return vstack((points,ones((1,points.shape[1]))))3.1.1 直接线性变换算法

if fp.shape != tp.shape:
raise RuntimeError('number of points do not match')
# 对点进行归一化(对数值计算很重要)
# --- 映射起始点 ---
m = mean(fp[:2], axis=1)
maxstd = max(std(fp[:2], axis=1)) + 1e-9
C1 = diag([1/maxstd, 1/maxstd, 1])
C1[0][2] = -m[0]/maxstd
C1[1][2] = -m[1]/maxstd
fp = dot(C1,fp)
# --- 映射对应点 ---
m = mean(tp[:2], axis=1)
maxstd = max(std(tp[:2], axis=1)) + 1e-9
C2 = diag([1 / maxstd, 1 / maxstd, 1])
C2[0][2] = -m[0] / maxstd
C2[1][2] = -m[1] / maxstd
tp = dot(C2, tp)
# 创建用于线性方法的矩阵,对于每个对应对,在矩阵中会出现两行数值
nbr_correspondences = fp.shape[1]
A = zeros((2 * nbr_correspondences, 9))
for i in range(nbr_correspondences):
A[2*i] = [-fp[0][i], -fp[1][i],-1,0,0,0,
tp[0][i]*fp[0][i],tp[0][i]*fp[1][i],tp[0][i]]
A[2*i+1] = [0,0,0,-fp[0][i],-fp[1][i],-1,
tp[1][i]*fp[0][i],tp[1][i]*fp[1][i],tp[1][i]]
U,S,V = linalg.svd(A)
H = V[8].reshape((3,3))
#反归一化
H = dot(linalg.inv(C2),dot(H,C1))
#归一化,然后返回
return H / H[2,2]
3.1.2 仿射变换
def Haffine_from_points(fp, tp):
"""计算H仿射变换,使得tp是fp经过仿射变换H得到的"""
if fp.shape != tp.shape:
raise RuntimeError('number of points do not match')
# 对点进行归一化(对数值计算很重要)
# --- 映射起始点 ---
m = mean(fp[:2], axis=1)
maxstd = max(std(fp[:2], axis=1)) + 1e-9
C1 = diag([1/maxstd, 1/maxstd, 1])
C1[0][2] = -m[0]/maxstd
C1[1][2] = -m[1]/maxstd
fp_cond = dot(C1,fp)
# --- 映射对应点 ---
m = mean(tp[:2], axis=1)
C2 = C1.copy() # 两个点集,必须都进行相同的缩放
C2[0][2] = -m[0]/maxstd
C2[1][2] = -m[1]/maxstd
tp_cond = dot(C2,tp)
# 因为归一化后点的均值为0,所以平移量为0
A = concatenate((fp_cond[:2],tp_cond[:2]), axis=0)
U,S,V = linalg.svd(A.T)
# 如Hartley和Zisserman著的Multiplr View Geometry In Computer,Scond Edition所示,
# 创建矩阵B和C
tmp = V[:2].T
B = tmp[:2]
C = tmp[2:4]
tmp2 = concatenate((dot(C,linalg.pinv(B)),zeros((2,1))), axis=1)
H = vstack((tmp2,[0,0,1]))
# 反归一化
H = dot(linalg.inv(C2),dot(H,C1))
return H / H[2,2]
3.2 图像扭曲
from scipy import ndimage
from PIL import Image
from pylab import *
im=array(Image.open('pic/empire.jpg').convert('L'))
H=array([[1.4,0.05,-100],[0.05,1.5,-100],[0,0,1]])
im2=ndimage.affine_transform(im,H[:2,:2],(H[0,2],H[1,2]))
figure()
gray()
imshow(im2)
axis('off')
show()

3.2.3 图像配准
图像配准是对图像进行变换,使变换后的图像能够在常见的坐标系中对齐,让我们一起看一个对多个人脸图像进行严格配准的例子,使得计算的平均人脸和人脸表现的变化具有意义,这类配准中,实际上是寻找一个相似变换,在对应点之间建立映射。
使用xml.dom模块中的minidom来读取XML文件。
def read_points_from_xml(xmlFileName):
""" Reads control points for face alignment. """
xmldoc = minidom.parse(xmlFileName)
facelist = xmldoc.getElementsByTagName('face')
faces = {}
for xmlFace in facelist:
fileName = xmlFace.attributes['file'].value
xf = int(xmlFace.attributes['xf'].value)
yf = int(xmlFace.attributes['yf'].value)
xs = int(xmlFace.attributes['xs'].value)
ys = int(xmlFace.attributes['ys'].value)
xm = int(xmlFace.attributes['xm'].value)
ym = int(xmlFace.attributes['ym'].value)
faces[fileName] = array([xf, yf, xs, ys, xm, ym])
return faces
文件中的标记点会以字典的形式返回,字典的键值为图像的文件名,值为:xf 、yf(左眼);xs、ys(右眼);xm、ym(嘴),参数使用最小二乘解,这些点被映射到目标位置
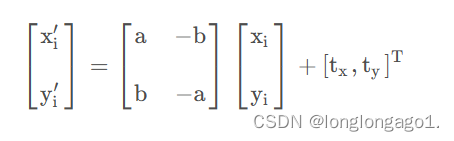
使用linalg.listsq()函数来计算最小二乘解
def write_points_to_xml(faces, xmlFileName):
xmldoc = minidom.Document()
xmlFaces = xmldoc.createElement("faces")
keys = faces.keys()
for k in keys:
xmlFace = xmldoc.createElement("face")
xmlFace.setAttribute("file", k)
xmlFace.setAttribute("xf", "%d" % faces[k][0])
xmlFace.setAttribute("yf", "%d" % faces[k][1])
xmlFace.setAttribute("xs", "%d" % faces[k][2])
xmlFace.setAttribute("ys", "%d" % faces[k][3])
xmlFace.setAttribute("xm", "%d" % faces[k][4])
xmlFace.setAttribute("ym", "%d" % faces[k][5])
xmlFaces.appendChild(xmlFace)
xmldoc.appendChild(xmlFaces)
fp = open(xmlFileName, "w")
fp.write(xmldoc.toprettyxml(encoding='utf-8'))
fp.close()
def compute_rigid_transform(refpoints,points):
""" Computes rotation, scale and translation for
aligning points to refpoints. """
A = array([ [points[0], -points[1], 1, 0],
[points[1], points[0], 0, 1],
[points[2], -points[3], 1, 0],
[points[3], points[2], 0, 1],
[points[4], -points[5], 1, 0],
[points[5], points[4], 0, 1]])
y = array([ refpoints[0],
refpoints[1],
refpoints[2],
refpoints[3],
refpoints[4],
refpoints[5]])
# least sq solution to mimimize ||Ax - y||
a,b,tx,ty = linalg.lstsq(A,y)[0]
R = array([[a, -b], [b, a]]) # rotation matrix incl scale
return R,tx,ty
返回具有尺度地旋转矩阵,以及x和y方向上的平移量
对每个颜色通道进行仿射变换,直接使用第一幅图像中的标记位置作为参考坐标系,来进行配准操作
def rigid_alignment(faces,path,plotflag=False):
""" Align images rigidly and save as new images.
path determines where the aligned images are saved
set plotflag=True to plot the images. """
# take the points in the first image as reference points
refpoints = faces.values()[0]
# warp each image using affine transform
for face in faces:
points = faces[face]
R,tx,ty = compute_rigid_transform(refpoints, points)
T = array([[R[1][1], R[1][0]], [R[0][1], R[0][0]]])
im = array(Image.open(os.path.join(path,face)))
im2 = zeros(im.shape, 'uint8')
# warp each color channel
for i in range(len(im.shape)):
im2[:,:,i] = ndimage.affine_transform(im[:,:,i],linalg.inv(T),offset=[-ty,-tx])
if plotflag:
imshow(im2)
show()
# crop away border and save aligned images
h,w = im2.shape[:2]
border = (w+h)/20
# crop away border
# 组合路径后返回并裁剪边界
imsave(os.path.join(path, 'aligned/'+face),im2[border:h-border,border:w-border,:])
配准算法的主要方法
(1) 基于点:
a. SIFT算法
SIFT特征匹配算法包括两个阶段:SIFT特征的生成与SIFT特征向量的匹配。
SIFT特征向量的生成算法包括四步:
1.尺度空间极值检测,以初步确定关键点位置和所在尺度。
2.拟和三维二次函数精确确定位置和尺度,同时去除低对比度的关键点和不稳定的边缘响应点。
3.利用关键点领域像素的梯度方向分布特性为每个关键点指定参数方向,使算子具备旋转不变性。
4.生成SIFT特征向量。
SIFT特征向量的匹配
对图像1中的某个关键点,找到其与图像2中欧式距离最近的前两个关键点的距离NN和SCN,如果NN/SCN小于某个比例阈值,则接受这一对匹配点。
b.ASIFT算法
通过原始图像来模拟得到场景在各个视角下的图像,再对这些得到的图像提起SIFT特征点,然后进行匹配。其放射性要好于SIFT,具有全仿射不变性。
c.SUFR算法
特征点提取:
1.计算原图像的积分图像
2.用不同尺寸的框状滤波器来计算不同阶以及不同层上的每个点图像点的行列式。一般计算4阶4层
3.在3维(x,y,S)尺度空间中,在每个3x3x3的局部区域里,进行非最大值抑制。只有比邻近的26个点的响应值都大的点才被选为兴趣点。
特征匹配:
对图像1中的某个关键点,找到其与图像2中欧式距离最近的前两个关键点的距离NN和SCN,如果NN/SCN小于某个比例阈值,则接受这一对匹配点。
(2)基于边缘:
基本思想:用边缘检测算子提取出边缘
边缘匹配:
1.根据边缘的相似度
2.提取边缘上的控制点,如曲率比较大的点等,然后用这些点来进行匹配。
3.将边缘拟合成直线,然后匹配直线。
估计变换参数:用边缘上的控制点或直线的端点,中点等等。
基于SIFT算法的图像配准的代码:
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 读取待配准的图像和参考图像
img1 = cv2.imread('7.jpg', cv2.IMREAD_GRAYSCALE)
img2 = cv2.imread('8.jpg', cv2.IMREAD_GRAYSCALE)
# 创建 SIFT 检测器和描述符.
sift = cv2.SIFT_create()
# 检测关键点和计算描述符
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# 使用 FLANN 匹配器进行特征点匹配
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(des1, des2, k=2)
# 筛选匹配点
good_matches = []
for m, n in matches:
if m.distance < 0.7 * n.distance:
good_matches.append(m)
# 获取匹配点的坐标
src_pts = np.float32([kp1[m.queryIdx].pt for m in good_matches]).reshape(-1, 1, 2)
dst_pts = np.float32([kp2[m.trainIdx].pt for m in good_matches]).reshape(-1, 1, 2)
# 估计变换矩阵
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0)
# 对待配准图像进行变换
h, w = img1.shape
aligned_img = cv2.warpPerspective(img1, M, (w, h))
# 显示输入的两张图片和配准结果
fig, ax = plt.subplots(nrows=1, ncols=3, figsize=(15, 5))
ax[0].imshow(cv2.cvtColor(img1, cv2.COLOR_BGR2RGB))
ax[0].set_title('Input Image 1')
ax[1].imshow(cv2.cvtColor(img2, cv2.COLOR_BGR2RGB))
ax[1].set_title('Input Image 2')
ax[2].imshow(cv2.cvtColor(aligned_img, cv2.COLOR_BGR2RGB))
ax[2].set_title('Aligned Image')
plt.show()
基于ASIFT算法的图像配准
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 读取待配准的图像和参考图像
img1 = cv2.imread('img1.jpg', cv2.IMREAD_GRAYSCALE)
img2 = cv2.imread('img2.jpg', cv2.IMREAD_GRAYSCALE)
# 创建 ASIFT 检测器
asift = cv2.AKAZE_create(descriptor_type=cv2.AKAZE_DESCRIPTOR_MLDB)
# 检测关键点和计算描述符
kp1, des1 = asift.detectAndCompute(img1, None)
kp2, des2 = asift.detectAndCompute(img2, None)
# 使用 FLANN 匹配器进行特征点匹配
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(des1, des2, k=2)
# 筛选匹配点
good_matches = []
for m, n in matches:
if m.distance < 0.7 * n.distance:
good_matches.append(m)
# 获取匹配点的坐标
src_pts = np.float32([kp1[m.queryIdx].pt for m in good_matches]).reshape(-1, 1, 2)
dst_pts = np.float32([kp2[m.trainIdx].pt for m in good_matches]).reshape(-1, 1, 2)
# 估计变换矩阵
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0)
# 对待配准图像进行变换
h, w = img1.shape
aligned_img = cv2.warpPerspective(img1, M, (w, h))
# 显示输入的两张图片和配准结果
fig, ax = plt.subplots(nrows=1, ncols=3, figsize=(15, 5))
ax[0].imshow(img1, cmap='gray')
ax[0].set_title('Input Image 1')
ax[1].imshow(img2, cmap='gray')
ax[1].set_title('Input Image 2')
ax[2].imshow(aligned_img, cmap='gray')
ax[2].set_title('Aligned Image')
plt.show() 3.3、创建全景图
在同一位置(即图像的照相机位置相同)拍摄的两幅或者多幅图像是单应性相关的 。我们经常使用该约束将很多图像缝补起来,拼成一个大的图像来创建全景图像。
3.1.1 RANSAC
RANSAC(RANdom SAmple Consensus)是一种基于随机采样的迭代算法,用于估计数学模型参数,从而通过对数据集进行拟合来提高模型的鲁棒性。RANSAC 可以有效地处理存在噪声、离群点和误差的数据集,是许多计算机视觉和机器学习领域的重要工具。
RANSAC 的基本思想是随机从数据集中选择一小部分数据,根据这些数据估计模型参数,并将其应用于整个数据集。然后,根据模型的拟合程度和数据点是否符合模型,将数据点分为“内点”和“外点”。内点是与模型拟合良好的数据点,而外点则是与模型拟合不良的数据点。接下来,RANSAC 通过迭代随机采样和拟合模型来最大化内点数量,从而提高模型的鲁棒性。
在计算机视觉中,RANSAC 常用于图像配准、物体检测、三维重建等任务中。例如,在图像配准中,RANSAC 可以估计两幅图像之间的变换矩阵,从而将它们对齐。在物体检测中,RANSAC 可以估计物体的位置和姿态,从而提高检测的准确性。在三维重建中,RANSAC 可以估计点云中的平面或直线,从而提高重建的精度。
需要注意的是,RANSAC 算法的性能取决于内点比例和迭代次数。内点比例越高,算法的鲁棒性越好,但计算成本也越高。迭代次数越多,算法的准确性越高,但计算成本也越高。因此,在应用 RANSAC 算法时,需要平衡准确性和计算成本,并根据具体情况调整参数。
RANSAC原理
RANSAC目的是找到最优的参数矩阵使得满足该矩阵的数据点个数最多,通常令h33=1来归一化矩阵。由于单应性矩阵有8个未知参数,至少需要8个线性方程求解,对应到点位置信息上,一组点对可以列出两个方程,则至少包含4组匹配点对。
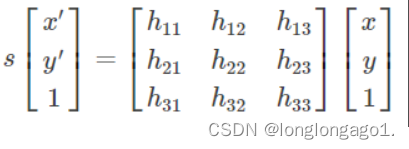
其中(x,y)表示目标图像角点位置,(x’,y’)为场景图像角点位置,s为尺度参数。
RANSAC算法从匹配数据集中随机抽出4个样本并保证这4个样本之间不共线,计算出单应性矩阵,然后利用这个模型测试所有数据,并计算满足这个模型数据点的个数与投影误差(即代价函数),若此模型为最优模型,则对应的代价函数最小。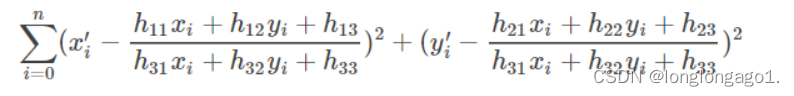
RANSAC 的标准例子:用一条直线拟合带有噪声数据的点集。简单的最小二乘在该 例子中可能会失效,但是 RANSAC 能够挑选出正确的点,然后获取能够正确拟合的直线。
import numpy as np
import random
import matplotlib.pyplot as plt
# 生成一组带有噪声的数据
n = 100
x = np.linspace(0, 10, n)
y = 2 * x + 1 + np.random.normal(scale=2, size=n)
# 定义 RANSAC 算法函数
def ransac(data, model, n, k, t, d, debug=False, return_all=False):
"""
RANSAC 算法函数
data: 输入数据点
model: 估计模型函数
n: 选取样本点的个数
k: 迭代次数
t: 阈值
d: 内点比例
debug: 是否输出调试信息
return_all: 是否返回所有估计模型的参数
"""
best_model = None
best_error = np.inf
best_inliers = None
for i in range(k):
# 1. 随机选取n个数据点
sample = random.sample(list(data), n)
# 2. 估计模型参数
model_params = model(np.array(sample))
# 3. 计算所有数据点到模型的距离
distances = np.abs(model_params.dot(data.T))
# 4. 将距离小于阈值的数据点视为内点
inliers = np.where(distances < t)[0]
# 5. 如果内点比例大于阈值d,重新估计模型参数
if len(inliers) > d * n:
model_params = model(data[inliers])
# 6. 计算内点的平均误差
error = np.mean(np.abs(model_params.dot(data[inliers].T) - y[inliers]))
# 7. 如果平均误差小于当前最小误差,更新最优模型
if error < best_error:
best_model = model_params
best_error = error
best_inliers = inliers
else:
error = np.inf
if debug:
print('Iteration %d: model: %s, error: %.3f, inliers: %d' % (i, str(model_params), error, len(inliers)))
if return_all:
return best_model, best_error, best_inliers
return best_model, best_error, best_inliers
# 定义线性模型函数
def linear_model(data):
x = data[:, 0]
y = data[:, 1]
A = np.vstack([x, np.ones(len(x))]).T
return np.linalg.lstsq(A, y, rcond=None)[0]
# 调用 RANSAC 算法函数估计线性模型参数
model, error, inliers = ransac(np.column_stack((x, y)), linear_model, n=2, k=100, t=1, d=0.5, debug=True)
# 输出估计结果
print('Estimated model: y = %.3fx + %.3f' % (model[0], model[1]))
print('Error: %.3f' % error)
print('Inliers: %d' % len(inliers))
# 绘制散点图和估计直线
plt.scatter(x, y, marker='.', color='b', label='Data')
plt.plot(x, model[0] * x + model[1], color='r', label='RANSAC Model')
plt.legend()
plt.show()
3.3.2 稳健的单应性矩阵估计
稳健的单应性矩阵估计是指在存在噪声和异常值的情况下,通过一组二维图像点对计算出单应性矩阵的方法。在计算机视觉和图像处理中,单应性矩阵通常用于图像配准、相机标定和三维重建等任务中。
import cv2
import numpy as np
import matplotlib.pyplot as plt
def compute_homography(x1, x2):
"""使用 SVD 分解计算单应性矩阵"""
A = []
for i in range(x1.shape[0]):
xi, yi = x1[i, :]
xip, yip = x2[i, :]
A.append([-xi, -yi, -1, 0, 0, 0, xi * xip, yi * xip, xip])
A.append([0, 0, 0, -xi, -yi, -1, xi * yip, yi * yip, yip])
A = np.array(A)
_, _, vt = np.linalg.svd(A)
H = vt[-1, :].reshape(3, 3)
H = H / H[2, 2]
return H
def apply_homography(H, x):
"""将点坐标变换到新的坐标系"""
x = np.hstack([x, np.ones((x.shape[0], 1))])
proj_x = np.dot(H, x.T)
proj_x = proj_x / proj_x[2, :]
return proj_x[:2, :].T
def ransac_homography(x1, x2, num_iter=1000, inlier_thresh=1.0):
best_H = None
best_num_inliers = 0
for i in range(num_iter):
# 1. 随机选取一组匹配点,计算对应的单应性矩阵
idx = np.random.choice(x1.shape[0], 4, replace=False)
H = compute_homography(x1[idx], x2[idx])
# 2. 计算所有匹配点到估计的单应性矩阵的投影误差
proj_x2 = apply_homography(H, x1)
dist = np.linalg.norm(proj_x2 - x2, axis=1)
# 3. 选取一部分投影误差较小的匹配点,作为内点集合
inliers = dist < inlier_thresh
num_inliers = np.sum(inliers)
# 4. 如果内点集合的大小大于等于某个预先设定的值,重新估计单应性矩阵,并计算内点集合的投影误差
if num_inliers >= 4:
new_H = compute_homography(x1[inliers], x2[inliers])
new_proj_x2 = apply_homography(new_H, x1)
new_dist = np.linalg.norm(new_proj_x2 - x2, axis=1)
# 5. 如果估计得到的内点集合的大小大于前一次估计得到的内点集合的大小,则更新内点集合,并重新估计单应性矩阵
if np.sum(new_dist < inlier_thresh) > num_inliers:
best_H = new_H
best_num_inliers = np.sum(new_dist < inlier_thresh)
return best_H
# 读取两张测试图像
img1 = cv2.imread('7.jpg')
img2 = cv2.imread('8.jpg')
# 使用 SIFT 特征检测器和描述子提取器提取特征点和描述子
sift = cv2.SIFT_create()
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# 使用暴力匹配器计算匹配关系
bf = cv2.BFMatcher()
matches = bf.match(des1, des2)
# 选取前100个匹配关系
matches = sorted(matches, key=lambda x: x.distance)[:100]
# 从匹配关系中提取对应的点坐标
x1 = np.array([kp1[m.queryIdx].pt for m in matches])
x2 = np.array([kp2[m.trainIdx].pt for m in matches])
# 使用 RANSAC 算法估计稳健的单应性矩阵
H = ransac_homography(x1, x2)
# 将图像2进行单应性变换,拼接到图像1上
h, w, _ = img2.shape
dst = cv2.warpPerspective(img2, H, (w, h))
merged = cv2.addWeighted(img1, 0.5, dst, 0.5, 0)
# 在 Matplotlib 中展示拼接结果
fig, ax = plt.subplots(figsize=(12, 6))
ax.imshow(cv2.cvtColor(merged, cv2.COLOR_BGR2RGB))
ax.set_axis_off()
plt.tight_layout()
plt.show()
3.3.3 拼接图像
图像拼接是指将多张部分重叠的图像拼接成一张全景图像的过程。在图像拼接中,常用的方法是基于特征点的拼接方法,其基本步骤如下:
使用特征点检测算法(如 SIFT、SURF 等)在所有图像中提取特征点,并计算每个特征点的描述子。
使用特征点匹配算法(如暴力匹配、FLANN 匹配等)计算不同图像之间的匹配关系。
使用稳健的单应性矩阵估计方法(如 RANSAC 算法)估计不同图像之间的单应性变换关系。
将每个图像根据估计得到的单应性变换关系进行变换,使其对齐到全景图像的坐标系中。
根据变换后的图像,计算全景图像的大小和位置。
将变换后的图像拼接到全景图像中。
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 读取两张测试图像
img1 = cv2.imread('7.jpg')
img2 = cv2.imread('8.jpg')
# 显示输入的两张图像
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(12, 6))
ax1.imshow(cv2.cvtColor(img1, cv2.COLOR_BGR2RGB))
ax1.set_axis_off()
ax1.set_title('Image 1')
ax2.imshow(cv2.cvtColor(img2, cv2.COLOR_BGR2RGB))
ax2.set_axis_off()
ax2.set_title('Image 2')
plt.tight_layout()
plt.show()
# 使用 SIFT 特征检测器和描述子提取器提取特征点和描述子
sift = cv2.SIFT_create()
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# 使用暴力匹配器计算匹配关系
bf = cv2.BFMatcher()
matches = bf.match(des1, des2)
# 选取前100个匹配关系
matches = sorted(matches, key=lambda x: x.distance)[:100]
# 从匹配关系中提取对应的点坐标
x1 = np.array([kp1[m.queryIdx].pt for m in matches])
x2 = np.array([kp2[m.trainIdx].pt for m in matches])
# 使用 RANSAC 算法估计稳健的单应性矩阵
H, _ = cv2.findHomography(x2, x1, cv2.RANSAC, 5.0)
# 将图像2进行单应性变换,拼接到图像1上
h, w, _ = img2.shape
dst = cv2.warpPerspective(img2, H, (w, h))
merged = cv2.addWeighted(img1, 0.5, dst, 0.5, 0)
# 显示拼接后的图像
fig, ax = plt.subplots(figsize=(12, 6))
ax.imshow(cv2.cvtColor(merged, cv2.COLOR_BGR2RGB))
ax.set_axis_off()
ax.set_title('Merged Image')
plt.tight_layout()
plt.show()
# 将输入的两张图像和拼接后的图像一起输出
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize=(12, 8))
ax1.imshow(cv2.cvtColor(img1, cv2.COLOR_BGR2RGB))
ax1.set_axis_off()
ax1.set_title('Image 1')
ax2.imshow(cv2.cvtColor(img2, cv2.COLOR_BGR2RGB))
ax2.set_axis_off()
ax2.set_title('Image 2')
ax3.imshow(cv2.cvtColor(merged, cv2.COLOR_BGR2RGB))
ax3.set_axis_off()
ax3.set_title('Merged Image')
ax4.set_axis_off()
plt.tight_layout()
plt.show()
















 3449
3449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









