







LangChain的使用介绍
0 前言
进入2025年,大模型开发已经成为IT行业中最热门的赛道,本系列文章将介绍大模型的开发,在此之前,最好具备一些大模型的相关知识,比如知道提示词工程有哪些、提示词微调有哪些,什么是Agents,什么是Function Call等。
1 LanChain的简介
1.1 简要介绍
LangChain 由 Harrison Chase 创建于2022年10月,它是围绕LLMs(大语言模型)建立的一个框架。LangChain自身并不开发LLMs,它的核心理念是为各种LLMs实现通用的接口,把LLMs相关的组件“链接”在一起,简化LLMs应用的开发难度,方便开发者快速地开发复杂的LLMs应用。
假如没有LangChain,你想调GPT就得去看GPT的接口文档,你想调智谱就得去看GLM的接口文档,你想调用通义千问就得去看千问的文档,并且不同产商的大模型调用接口不一致,而LangChain内部则把这些接口给集成了,我们只需要学会LangChain的接口就行了。
由于大模型发展迅速,每隔一段时间都会有新的模型诞生,榜一大哥一直在变,所以LangChain更新很快,并且过一段时间又会出现新功能,从而导致LangChain各个版本不兼容地概率很大,出现bug的概率也很大,但目前它是最好的框架,出问题最好去官网看手册。LangChain目前有两个语言的实现: python 和 Nodejs,我们这里只学python版,为了保证本文中的代码能够得到顺利运行,我们使用的langchain版本为0.1.20,langchain-community版本为0.0.38,此外,还需安装qianfan(pip install qianfan)。
1.2 lanchain与lanchain_community的区别与联系
langchain 和 langchain_community 是 LangChain 生态系统中的两个不同的 Python 包,langchain 是核心包,提供官方支持的主要功能和集成,langchain_community 是社区包,提供更多样化但可能不够稳定的功能和集成,一些功能成熟稳定之后,会被加入到langchain中,两者的语法基本一致。
以下是两者的主要区别(来自deepseek-r1):
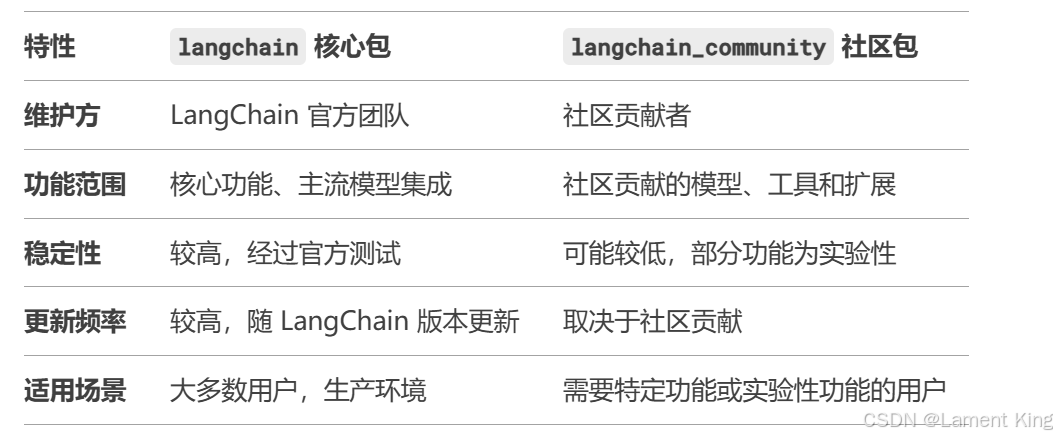
至于选择哪个,需要根据使用场景(来自deepseek-r1):

本文中的程序,使用lanchain与lanchain_community都能实现,所以后面不再区分两者,即认为这两个包是相同的。
1.3 langChain的组件
当前LangChain有六大主要组件,分别是:Models、Prompts、Memory、Indexes、Chains、Agents,其中,Chains已经不怎么使用了。我们后面会逐个介绍这些组件。
2 千帆大模型平台
因为大模型对硬件资源的要求比较高,消费级电脑很难满足要求,因此我们使用云平台上已经部署好的模型,本文使用百度千帆智能云平台,该平台已经集成好了很多大模型,并通过获取API Key来进行调用。
这里注册后会要求你实名认证,实名认真之后会有20元的代金券,因为调用云平台上的模型是按token收费的,我们这里仅仅是做几个demo,20元代金券足够用。
2.1 模型广场浏览
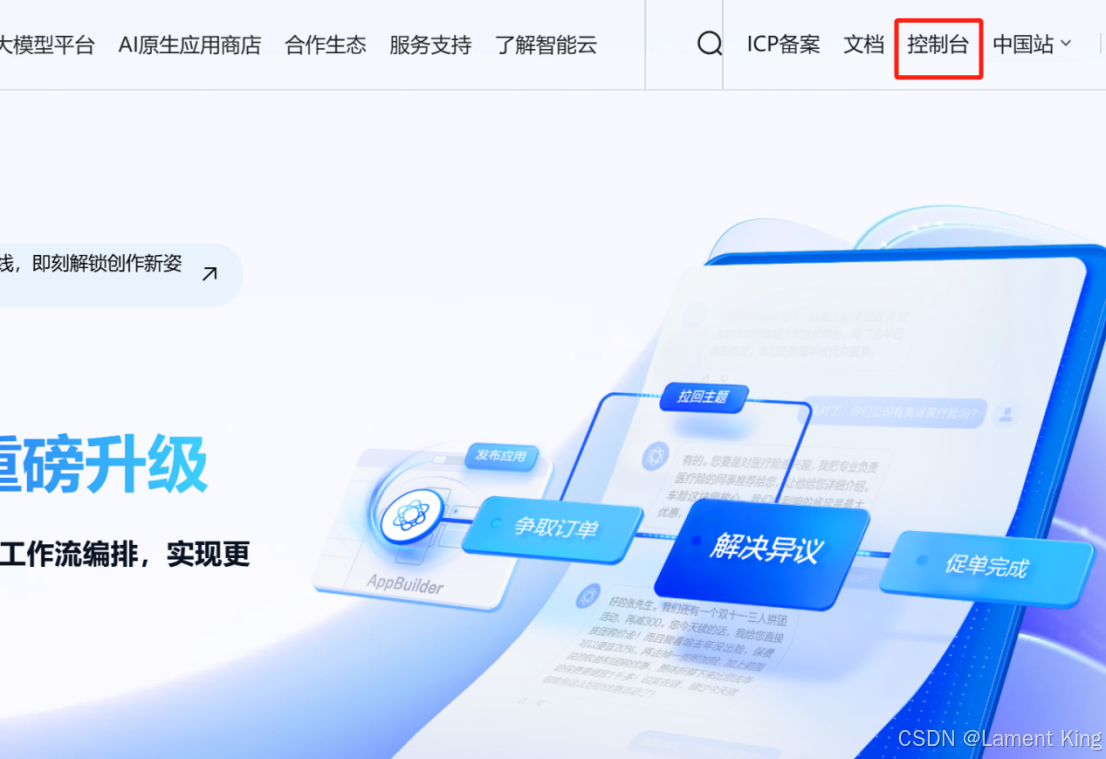
实名认证之后,回到主页,点击右上角的控制台:
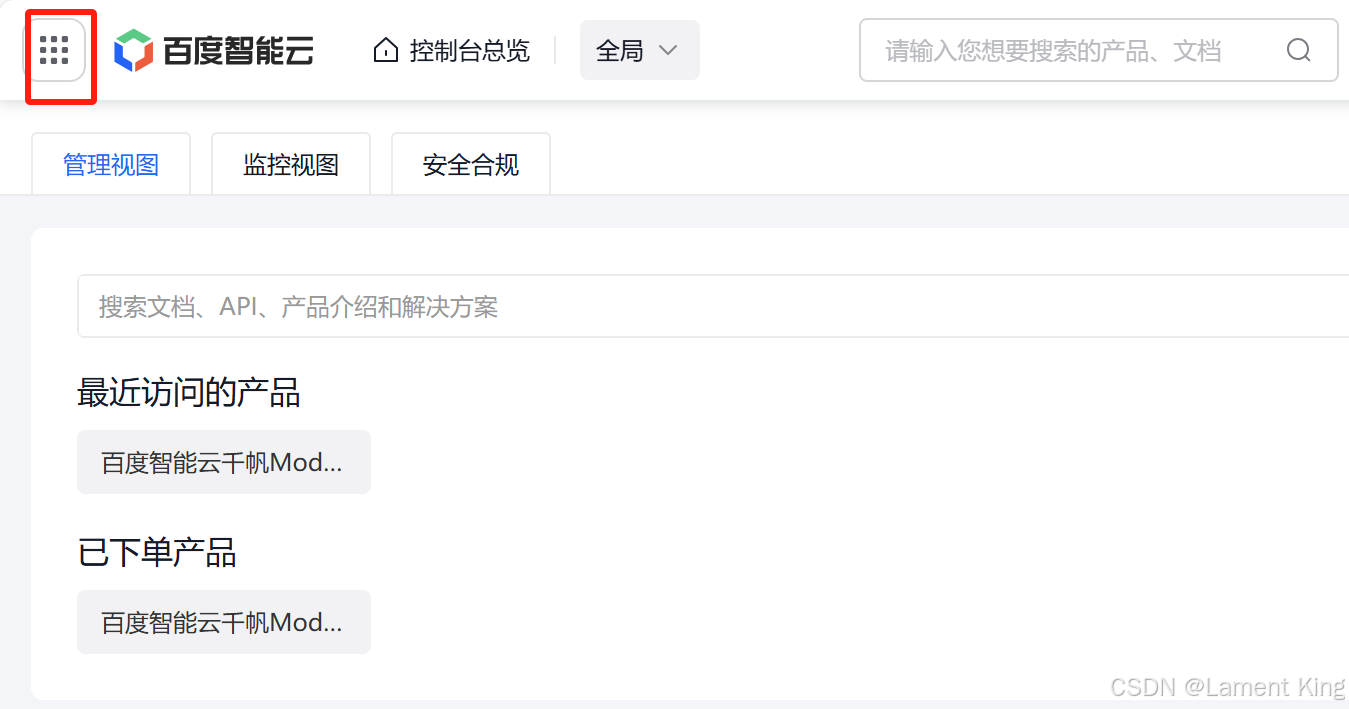
然后进入模型广场
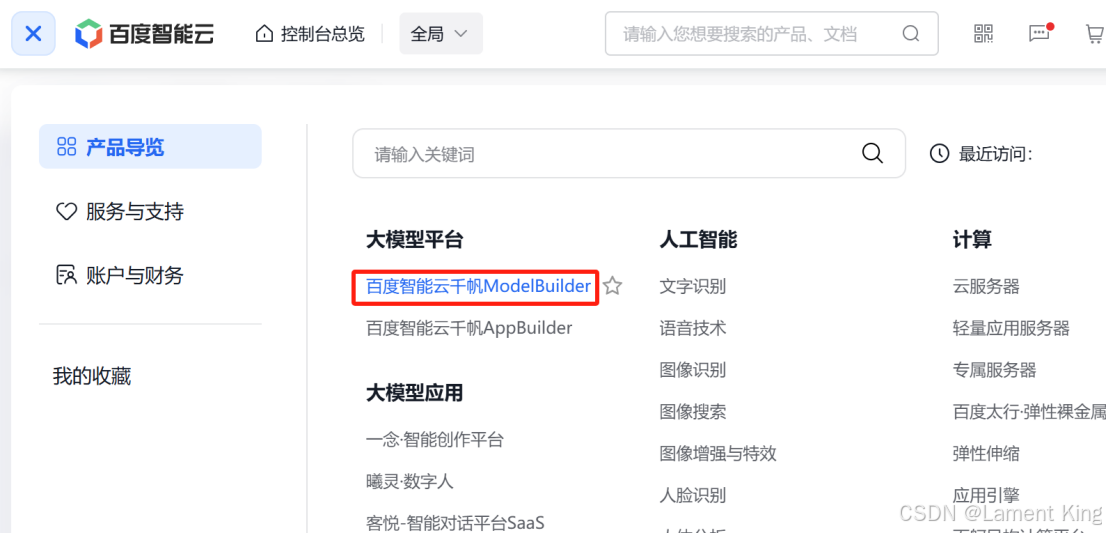
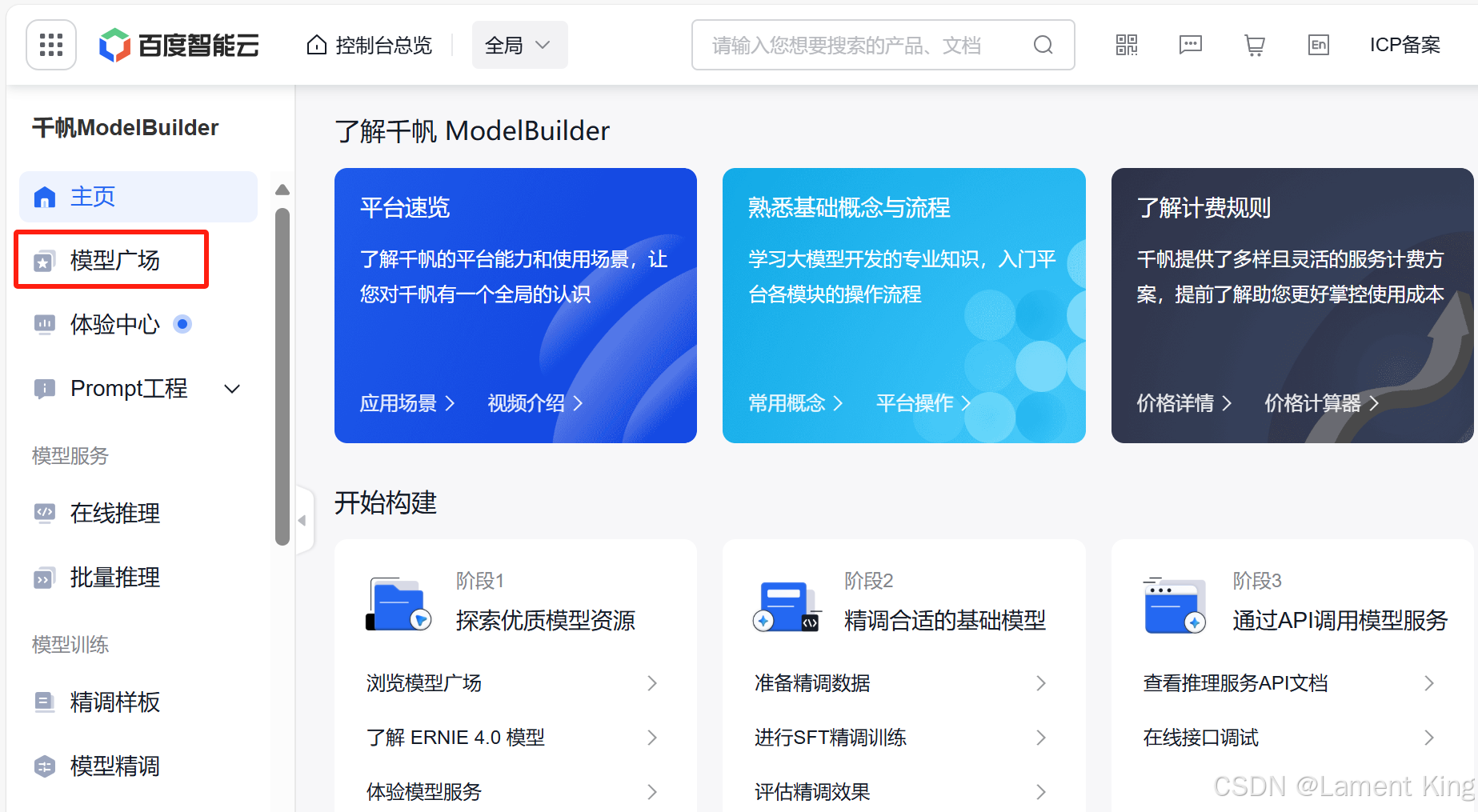
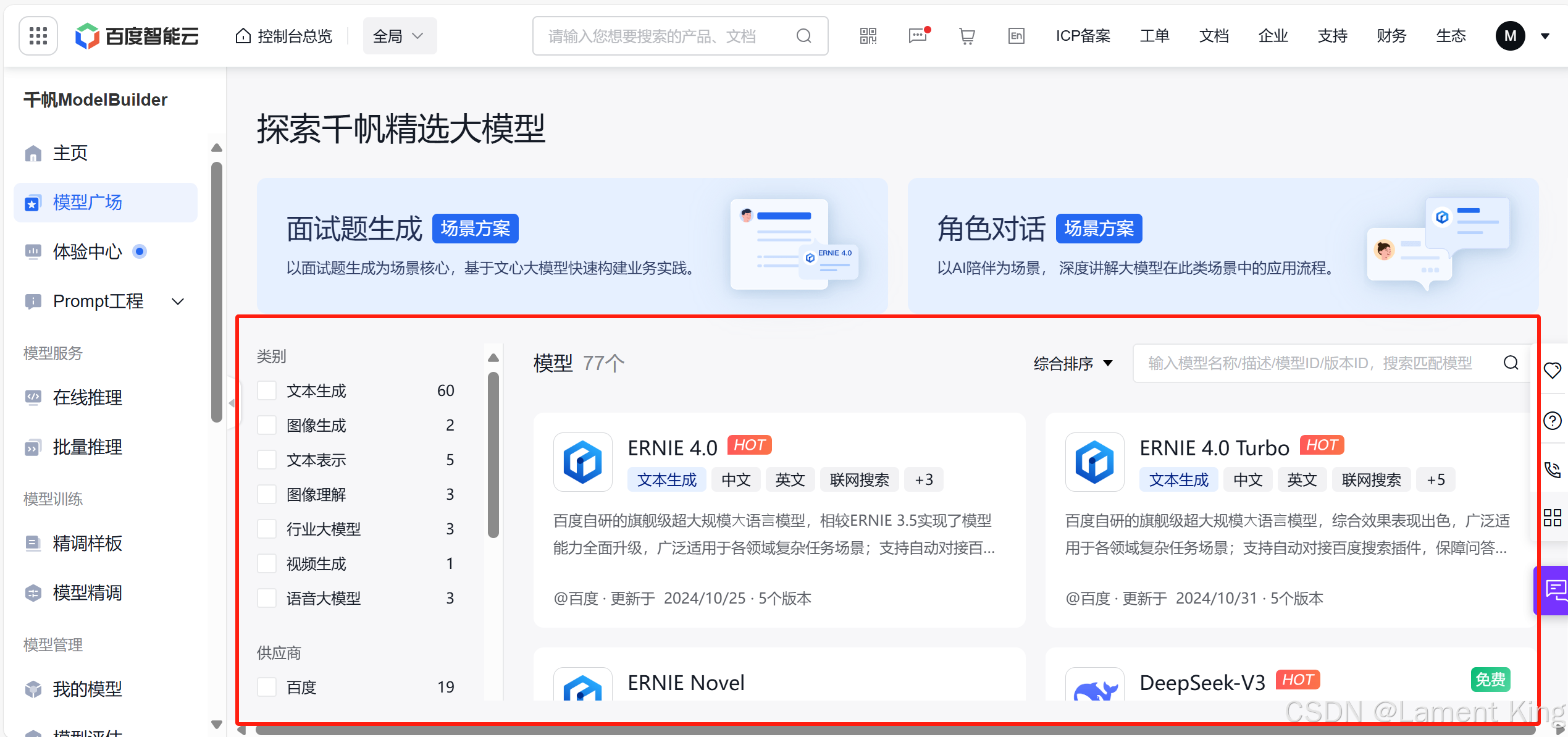
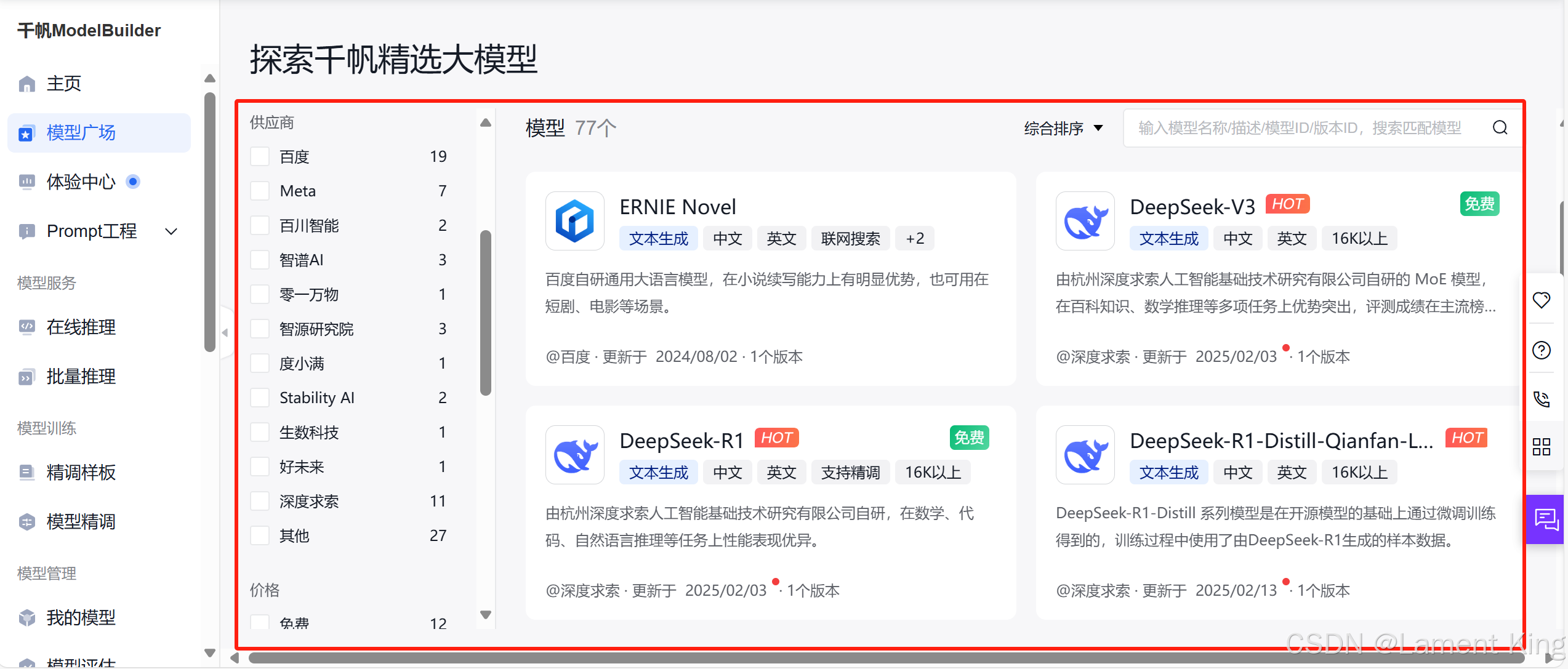
这里能看到很多模型,包括最近很火的DeepSeek-R1,当然,我们可以按模型类别找,也可以按供应商、价格或者上下文长度来找。
2.2 创建API Key
接下来我们创建API Key
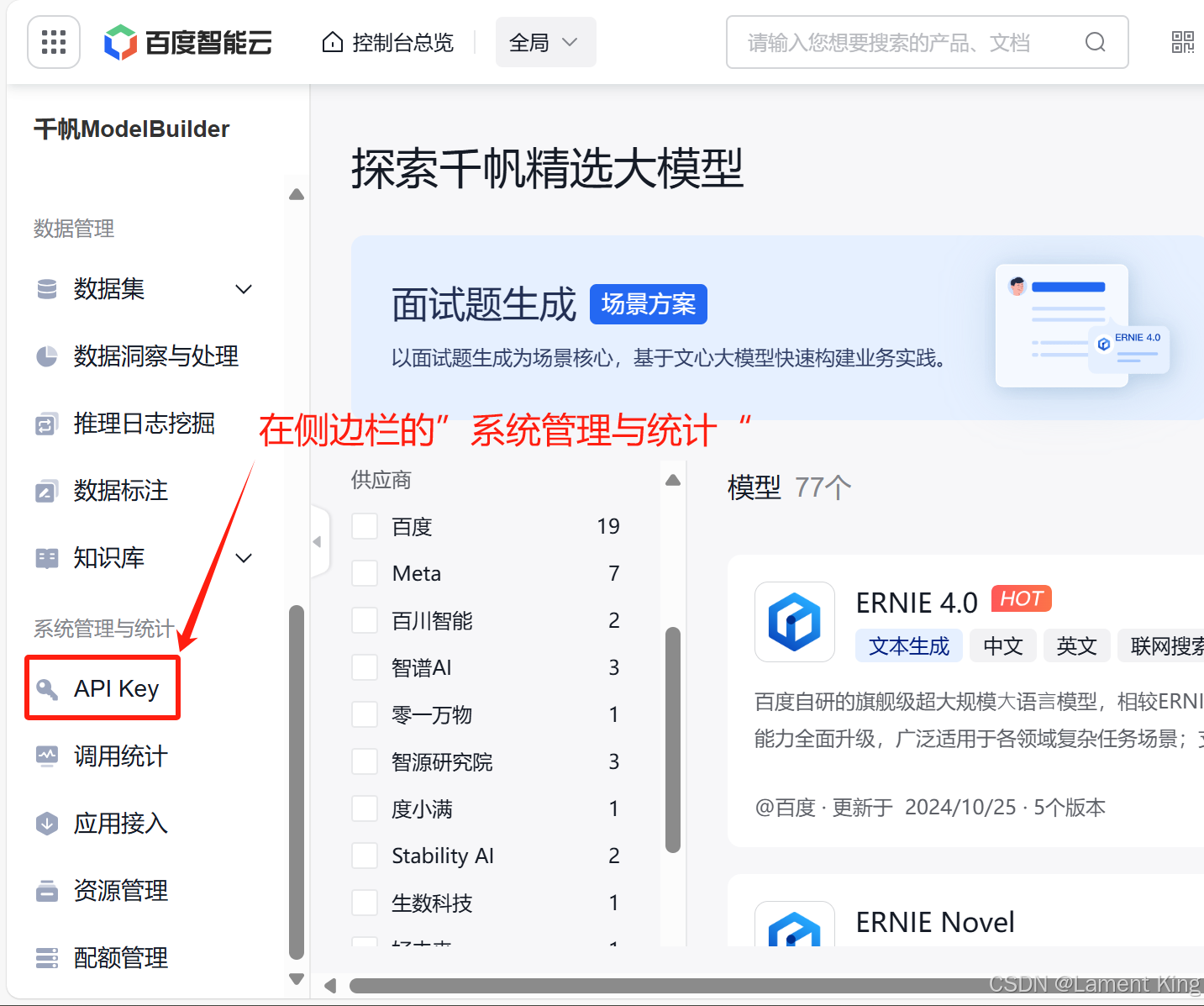
此时会开启一个新的页面
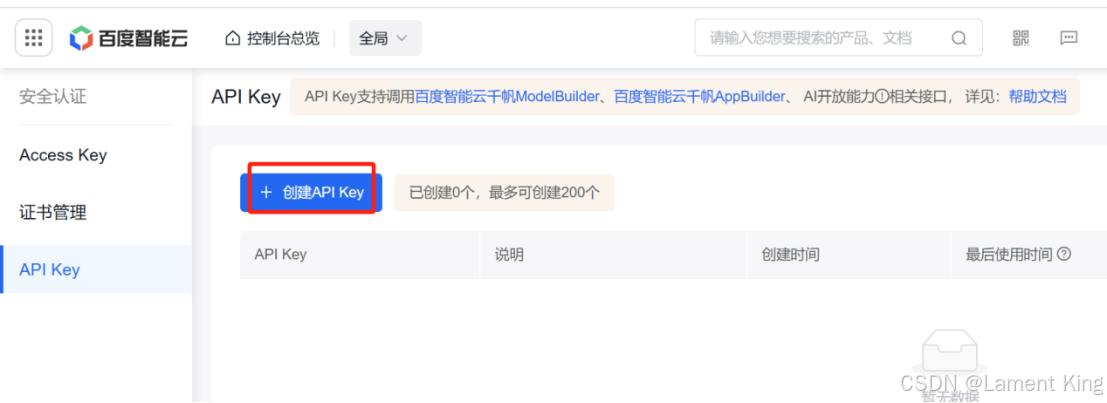
在服务中,我们选择“千帆ModelBuilder”
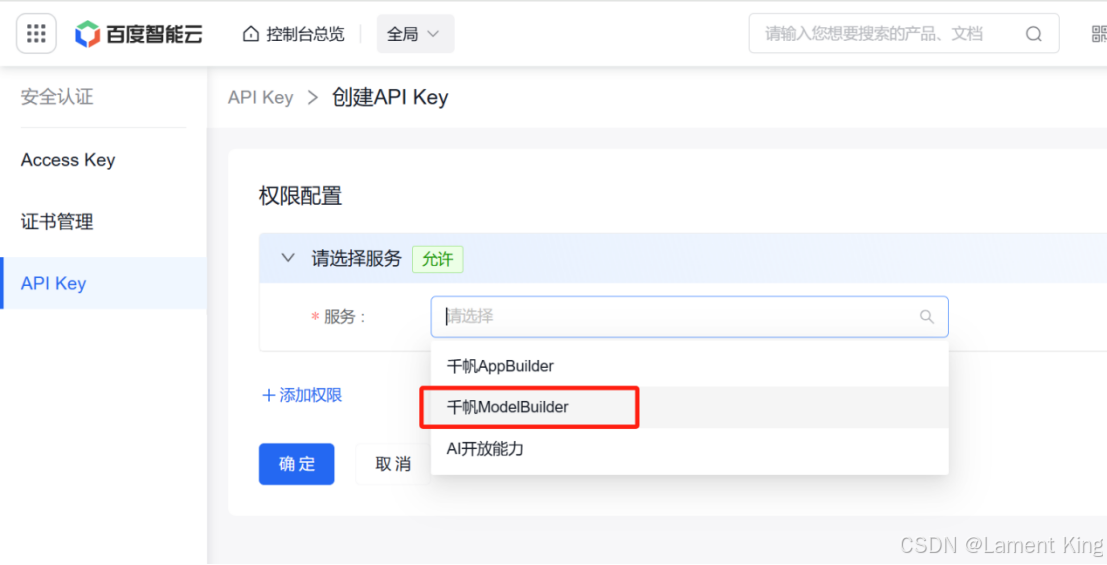
选择之后点击确定
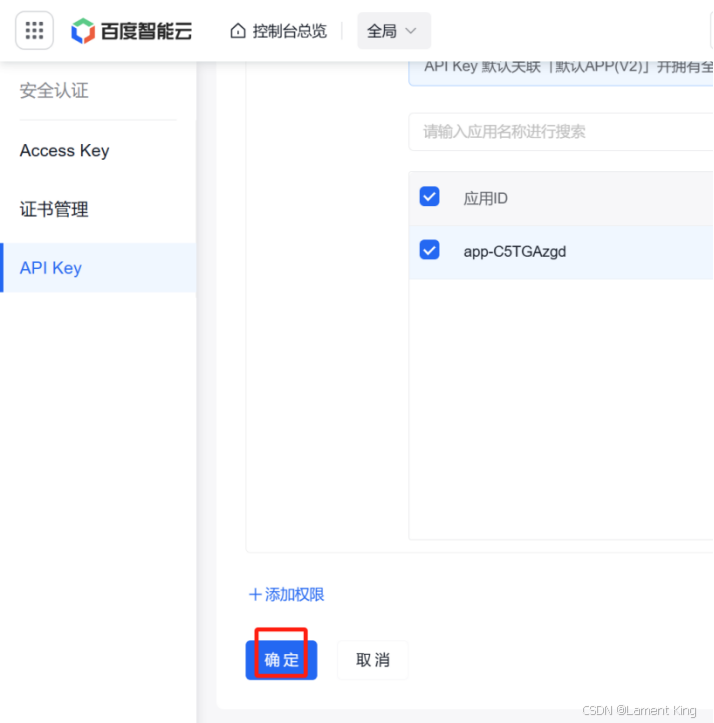
2.3 创建应用
回到大模型云平台(原来的那个页面)
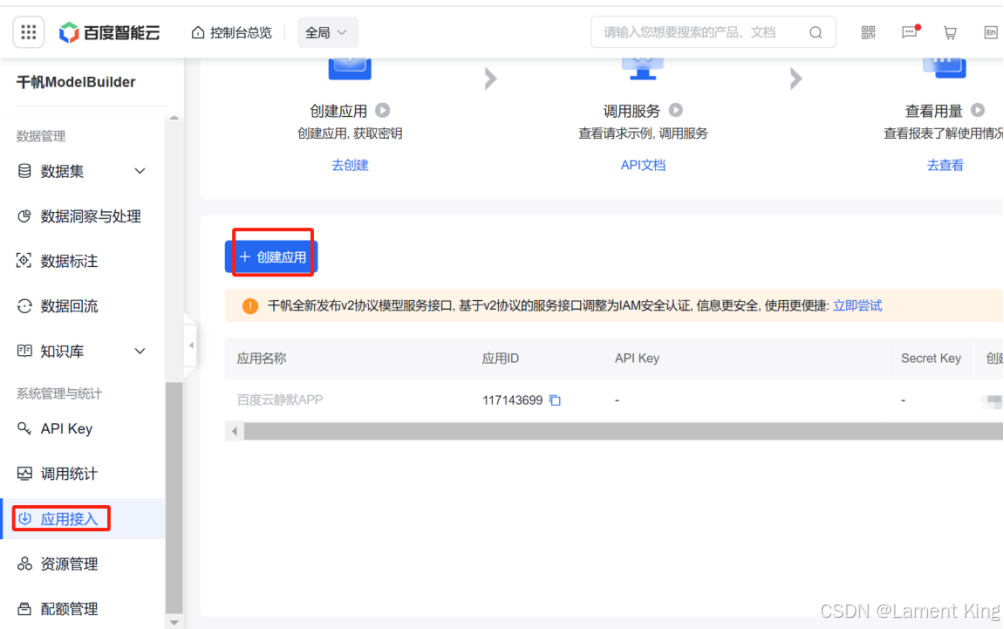
填写应用名称和应用描述

这里就能看到API Key和Secret Key,这个怎么用,我们稍后介绍。
3 Models组件
3.1 Models所支持的模型类型
LangChain目前支持三种模型类型:LLMs(大预言模型)、Chat Models(聊天模型)、Embeddings Models(文本嵌入模型)。其中,LLMs模型就是我们常用的大模型,比如GPT-4、DeepSeek、通义千问等,可以从Hugging Face上下载,也可以从魔搭上下载;Chat Models则是专门为聊天(多轮对话)设计的模型,它是基于LLMs的;Embeddings Models则是将文本转换称向量,这个有点类似于词向量模型,但词向量模型是专门针对词,而文本则是处理整个文本(如句子、段落或文档)。
LLMs和Chat Models比较容易搞混,关于它们的区别,可以看下面的DeepSeek的回答。

3.2 LangChain调用大语言模型(基座模型)
我们使用ChatGLM模型试一下:
import os
from langchain_community.llms import QianfanLLMEndpoint
# 1.设置qianfan的API-KEY和Serect-KEY
os.environ["QIANFAN_AK"] = "your api key"
os.environ["QIANFAN_SK"] = "your secrect key"
# 2.实例化模型
llm = QianfanLLMEndpoint(model="ChatGLM2-6B-32K") # 模型名字
res = llm.invoke("请帮我讲一个笑话")
print(res)
输出:
我可以讲一个笑话。以下是一个经典的笑话:
为什么鸡蛋要拿着棍子?
因为它想成为一个鸡棒球运动员。
这个笑话可能有些冷,但希望能让您开心一点。
这里from langchain_community.llms import QianfanLLMEndpoint是调用百度千帆(Qianfan)云服务的聊天模型接口,它的作用是简化开发者通过 API 调用千帆云上模型服务的过程。
这里大模型推理的时候,返回的是一个字符串,后续的聊天模型,则返回一个AIMessage对象。我们使用langchain框架,连分词的步骤都省了,可能是这个模型没那么智能,我们这里只是做个简单演示,目的是掌握langchain这个框架的使用。
当然,也可以把API Key和Secret Key通过模型的初始化方法传进去
# 初始化大语言模型
llm = QianfanLLMEndpoint(
model="ChatGLM2-6B-32K", # 指定模型名称
qianfan_ak="YOUR_API_KEY",
qianfan_sk="YOUR_SECRET_KEY"
)
3.3 LangChain调用聊天模型
聊天模型的信息类别
在聊天模型中,可以把信息分成四种类别:

单轮对话
我们使用千帆中文模型来试一下
import os
from langchain_community.chat_models import QianfanChatEndpoint
from langchain_core.messages import HumanMessage
# 1.设置qianfan的API-KEY和Serect-KEY
os.environ["QIANFAN_AK"] = "your api key"
os.environ["QIANFAN_SK"] = "your secrect key"
# 2.实例化模型
chat = QianfanChatEndpoint(model='Qianfan-Chinese-Llama-2-7B') # 这里调用的时候,会自动去找Chat版本的模型
# 3.构建信息
messages = [HumanMessage(content="给我写一首唐诗")]
# 4.推理
res = chat.invoke(messages)
print(res.content)
输出:
好的,下面是一首我为您创作的唐诗:
江畔独步
江畔秋声动客心,独步闲吟兴自深。
山光水色与人亲,云起雾收随兴吟。
万古长空一刹那,浮生若梦似浮云。
愿将诗句寄情思,流水高山共知音。
这首诗描绘了诗人在江畔独自漫步,感受自然景色与内心情感交融的情景。通过对自然景物的细腻描写,表达了诗人对人生短暂和世间万物的感慨,以及对知音难寻的哀叹。希望这首诗能够符合您的要求。
这里from langchain_community.chat_models import QianfanChatEndpoint是调用百度千帆(Qianfan)云服务的聊天模型接口。
我们上面的程序,“给我写一首唐诗”就是HumanMessage,这里是将其放到一个列表中,然后输入到聊天模型。
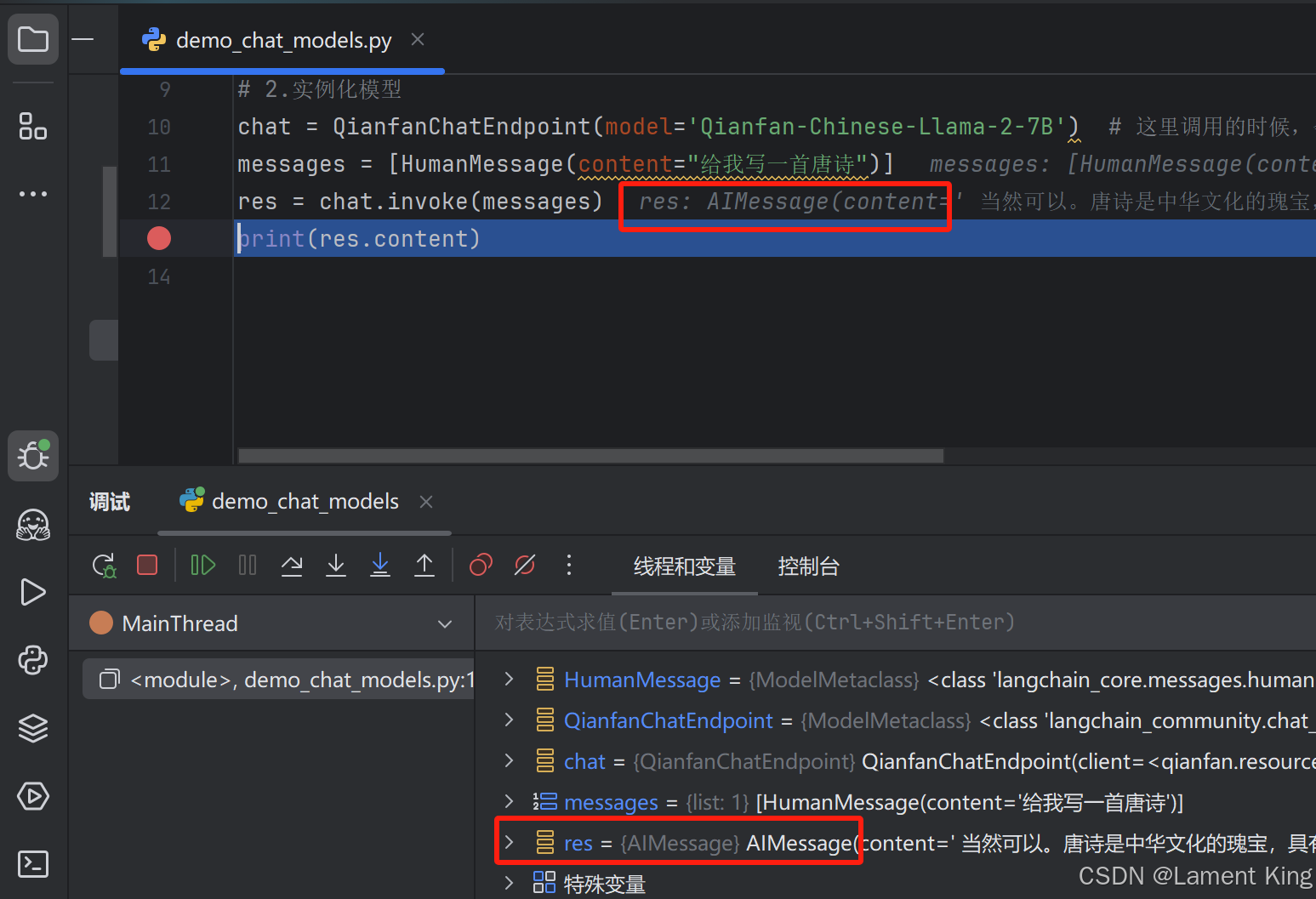
通过打断点,可以看到模型调用时的返回值res是AIMessage对象:
多轮对话
如果我们想用聊天模型实现多轮对话,程序可以这样修改:
import os
from langchain_community.chat_models import QianfanChatEndpoint
from langchain_core.messages import HumanMessage, AIMessage
# 1. 设置qianfan的API-KEY和Secret-KEY
os.environ["QIANFAN_AK"] = "your api key"
os.environ["QIANFAN_SK"] = "your secrect key"
# 2. 实例化模型
chat = QianfanChatEndpoint(model='Qianfan-Chinese-Llama-2-7B') # 这里调用的时候,会自动去找Chat版本的模型
# 3. 初始化对话历史
messages = []
# 4. 多轮对话循环
while True:
# 获取用户输入
user_input = input("你: ")
# 如果用户输入"exit",则退出对话
if user_input.lower() == "exit":
print("对话结束。")
break
# 将用户输入添加到对话历史中
messages.append(HumanMessage(content=user_input))
# 推理
res = chat.invoke(messages)
# 将模型的回复添加到对话历史中
messages.append(AIMessage(content=res.content))
# 打印模型的回复
print(f"AI: {res.content}")
print()
输出
你: 给我写一首唐诗
AI: 江畔独步
江畔秋声动客心,
月光穿透柳丝深。
轻舟曳过波纹起,
独步思绪似水沉。
朝露点点荷叶上,
暮霞片片天际侵。
一江风月无人管,
何处相思不伤心。
你: 这首诗的作者是谁?
AI: 抱歉,我之前的回复中提到的“唐诗”并不是指这首诗的作者。由于我无法确认具体的诗篇,因此无法准确告知这首诗的作者是谁。如果您能提供更多的信息或者具体的诗句,我或许能帮您找到相应的作者。
你: 请把上面的诗按李白的风格修改
AI: 江畔秋声动客心,
月明千里照孤舟。
轻风拂面柳丝舞,
独步天涯思绪流。
晨露晶莹荷叶上,
夕霞绚烂映天边。
一江风月无人管,
何处相思不泫然。
你: exit
对话结束。
从代码中可以看到,如果要让程序实现多轮对话,则需要把前面几轮对话加入到消息列表中,在加入AI的回答时,需要重新构建AIMessage对象。
3.4 LangChain调用文本嵌入模型
import os
from langchain_community.embeddings import QianfanEmbeddingsEndpoint
# 1.设置qianfan的API-KEY和Serect-KEY
os.environ["QIANFAN_AK"] = "your api key"
os.environ["QIANFAN_SK"] = "your secrect key"
# 2.实例化文本嵌入模型
embed = QianfanEmbeddingsEndpoint(model='Embedding-V1')
# 3.一段文本的向量化
result1 = embed.embed_query("这是一个测试文档")
print(f'result1-->{result1}')
print(f'result1的长度-->{len(result1)}')
# 4.一批文本向量化
result2 = embed.embed_documents(["这是一个测试文档", "这是二个测试文档"])
print(result2)
print(len(result2))
print(len(result2[0]))
print(len(result2[1]))
输出
import os
from langchain_community.embeddings import QianfanEmbeddingsEndpoint
# 1.设置qianfan的API-KEY和Serect-KEY
os.environ["QIANFAN_AK"] = "your api key"
os.environ["QIANFAN_SK"] = "your secrect key"
# 2.实例化向量模型
embed = QianfanEmbeddingsEndpoint(model='Embedding-V1')
# 3.一段文本的向量化
result1 = embed.embed_query("这是一个测试文档")
print(f'result1的类型-->{type(result1)}')
print(f'result1的长度-->{len(result1)}')
print(f'result1的前五个数-->{result1[:5]}')
print()
# 4.一批文本向量化
result2 = embed.embed_documents(["这是一个测试文档", "这是二个测试文档"])
print(f'result2的类型-->{type(result2)}')
print(f'result2中的向量个数-->{len(result2)}')
print(f'result2中,每个向量的长度-->{len(result2[0]), len(result2[1])}')
输出
result1的类型--><class 'list'>
result1的长度-->384
result1的前五个数-->[0.06482387334108353, -0.0018437327817082405, -0.0544276162981987, 0.03416511043906212, -0.11455889791250229]
result2的类型--><class 'list'>
result2中的向量个数-->2
result2中,每个向量的长度-->(384, 384)
3.5 模型的输入输出类型
聊天模型也可以像基座模型一样输入字符串,我自己debug看了一下内部的处理流程,内部会自动将字符串转换成HumanMessage,最后模型推理的返回值类型依然是AIMessage。
基座模型也可以像聊天模型一样,输入是各种Message构成的列表,但返回值依然是一个字符串。
文本嵌入模型的输入则必须是字符串或者字符串组成的列表。
后续的内容中我们还会看到,基座模型和聊天模型的输入还可以是提示词模板。
3.6 查看当前版本的lanchain支持的模型服务接口
运行如下代码即可:
from langchain_community.llms import __all__ as llms_list
from langchain_community.chat_models import __all__ as chat_models_list
from langchain_community.embeddings import __all__ as embeddings_models_list
print("Supported LLMs:", llms_list)
print(len(llms_list))
print("Supported Chat Models:", chat_models_list)
print(len(chat_models_list))
print("Supported Embedding Models:", embeddings_models_list)
print(len(embeddings_models_list))
4 Memory组件
大模型本身不具备上下文的概念,它并不保存上次交互的内容,ChatGPT之所以能够和人正常沟通对话,因为它进行了一层封装,将历史记录回传给了模型。
LangChain提供了Memory组件, Memory分为两种类型:短期记忆和长期记忆。短期记忆是指没来得及存档的对话,如果把短期记忆存档,那就变成了长期记忆。我们和大模型对话时,如果想把历史对话调出来,并在历史对话的基础上继续聊天,那么就是把存档的长期记忆给导入了进来。
Memory组件只需要知道一个函数:ChatMessageHistory,该函数常用来收集对话历史,使用如下:
from langchain.memory import ChatMessageHistory
# 1.实例对象
history = ChatMessageHistory()
# 2. 添加历史信息
history.add_user_message("在吗") # 内部会把信息保存成HumanMessage
history.add_ai_message("有什么事吗?") # 内部会保存成AIMessage
print(history.messages) # history.messages是一个列表
print('-'*50)
print(history) # history可以直接打印,对话历史会比较简洁地显示出来
输出
[HumanMessage(content='在吗'), AIMessage(content='有什么事吗?')]
--------------------------------------------------
Human: 在吗
AI: 有什么事吗?
此外,还需要知道messages_from_dict 和 messages_to_dict,它们常用于保存和加载对话信息:
import os
from langchain_community.chat_models import QianfanChatEndpoint
from langchain.memory import ChatMessageHistory
from langchain.schema import messages_from_dict, messages_to_dict
from langchain_core.messages import HumanMessage
os.environ["QIANFAN_AK"] = "your api key"
os.environ["QIANFAN_SK"] = "your secrect key"
# 实例化对象
history = ChatMessageHistory()
# 添加历史信息
history.add_user_message("hi") # 内部会把信息保存成HumanMessage
history.add_ai_message("what is up?") # 内部会保存成AIMessage
history.add_user_message("I have a headache")
history.add_ai_message("AI: I'm sorry to hear that. Is there anything specific that's causing the headache?")
# 保存历史信息到字典里
dicts = messages_to_dict(history.messages)
# 这里可以把dicts保存成json文件,但我们只是做一个简单演示,
# 了解一下messages_to_dict和messages_from_dict的使用即可
# 重新加载历史信息
new_message = messages_from_dict(dicts) # new_message和history.messages是相同的
print(new_message)
# 继续聊天
new_message.append(HumanMessage(content="Maybe I didn't sleep well last night"))
# 实例化模型
model = QianfanChatEndpoint(model='Qianfan-Chinese-Llama-2-7B')
# 推理
res = model.invoke(new_message)
print(res.content)
输出
[HumanMessage(content='hi'), AIMessage(content='what is up?'), HumanMessage(content='I have a headache'), AIMessage(content="AI: I'm sorry to hear that. Is there anything specific that's causing the headache?")]
Not getting enough rest can often lead to headaches. Have you tried any methods to alleviate the headache?
5 Prompts组件
Prompt是指当用户输入信息给模型时加入的提示,这个提示的形式可以是zero-shot或者few-shot等方式,目的是让模型理解更为复杂的业务场景以便更好的解决问题。
提示模板:如果你有了一个起作用的提示,你可能想把它作为一个模板用于解决其他问题,LangChain就提供了PromptTemplates组件,它可以帮助你更方便的构建提示。
5.1 提示词模板
Prompts组件其实就是提示词模板,先构建模板,然后再根据具体的问题往里填充构成最后的提示词,代码如下:
import os
from langchain_community.llms import QianfanLLMEndpoint
from langchain_core.prompts import PromptTemplate
os.environ["QIANFAN_AK"] = "your api key"
os.environ["QIANFAN_SK"] = "your secrect key"
#1. 创建模板
template = "我的邻居姓{lastname},他生了个儿子,给他儿子起个名字"
prompt = PromptTemplate(input_variables=["lastname"], template=template)
prompt_text = prompt.format(lastname="李") # prompt_text是字符串
print(f'prompt_text-->{prompt_text}')
# 2.实例化模型
llm = QianfanLLMEndpoint(model="Qianfan-Chinese-Llama-2-7B")
# 3.送入模型prompt
result = llm.invoke(prompt_text)
print(f'result--》{result}')
输出
prompt_text-->我的邻居姓李,他生了个儿子,给他儿子起个名字
result--》 作为AI语言模型,我可以给您的邻居的儿子起个名字。这里有几个建议:
1. 李明
2. 李浩
3. 李泽
4. 李智
5. 李宁
希望这些建议能帮到您!
4.2 few-shot-prompt模板
如果是In-Context Learning,那么会稍微麻烦一些,模板有两层,要先建立提示词模板,再建立few-shot-prompt模板,最后再把用户问题往里填充:
import os
from langchain_core.prompts import PromptTemplate, FewShotPromptTemplate
from langchain_community.llms import QianfanLLMEndpoint
os.environ["QIANFAN_AK"] = "your api key"
os.environ["QIANFAN_SK"] = "your secrect key"
# 1.给出部分示例
examples = [{"word": "开心", "antonym": "难过"}, # antonym 是“反义词”的意思
{"word": "高", "antonym": "矮"}]
# 2.设置示例模板
example_template = """
单词: {word}
反义词: {antonym}\\n
"""
# 3.根据示例模板创建提示词模板
example_prompt = PromptTemplate(input_variables=["word", "antonym"],
template=example_template)
# 4.根据示例和提示词模板创建few-shot-prompt模板,
# 这里就是将示例塞进提示词模板中,并增加前缀和后缀,以及指定输入变量和示例之间的分隔符
few_shot_prompt = FewShotPromptTemplate(examples=examples,
example_prompt=example_prompt,
prefix="给出每个单词的反义词", # 提示词前缀
suffix="单词:{input}\\n反义词:", # 提示词后缀
input_variables=["input"], # 指定输入变量
example_separator="\\n", # 示例之间的分隔符
)
# 5.向few-shot-prompt模板中填充要预测的输入
prompt_text = few_shot_prompt.format(input="粗") # prompt_text是字符串
# print(f'prompt_text-->{prompt_text}')
# 6.实例化模型
llm = QianfanLLMEndpoint(model="Qianfan-Chinese-Llama-2-7B")
#7.将prompt_text输入模型
result = llm.invoke(prompt_text)
print(result)
输出
细
6 Chains组件(用的少,了解即可)
在LangChain中,Chains是用链将其他几样组件给串起来,然后执行链。
针对上一小节中提示词模版的例子,我们可以用链来连接提示模版组件和模型,代码如下:
import os
from langchain_community.llms import QianfanLLMEndpoint
from langchain_core.prompts import PromptTemplate
from langchain.chains import LLMChain
os.environ["QIANFAN_AK"] = "your api key"
os.environ["QIANFAN_SK"] = "your secrect key"
#1. 定义模板
template = "我的邻居姓{lastname},他生了个儿子,给他儿子起个名字"
prompt = PromptTemplate(input_variables=["lastname"], template=template)
# 2.实例化模型
llm = QianfanLLMEndpoint(model="ChatGLM2-6B-32K")
# 3.构造CHain
chain = LLMChain(llm=llm, prompt=prompt) # 把大模型和提示词整合到链里面
# 4.执行Chain
result = chain.invoke("王") # 这里的result是一个字典,包含了'lastname'和'text'两个键
print(f'result-->{result["text"]}')
输出
result--> 给孩子取名字时,通常要考虑很多因素,如音韵美感、意义、文化背景等。根据提供的信息,我的邻居姓王,可以考虑以下名字:
1. 王天翔(意为“在天空中飞翔的王”)
2. 王瑞华(意为“有才华、美丽的花朵”)
3. 王嘉祥(意为“有德行、吉祥、幸福”)
4. 王思源(意为“思维广阔、源头清晰”)
5. 王涵妍(意为“含蓄、优雅、美丽”)
6. 王浩然(意为“广博、开阔、清新”)
7. 王阳光(意为“阳光般温暖、明朗”)
8. 王子涵(意为“高贵、优雅、含蓄”)
9. 王婉娜(意为“温柔、优雅、婉转”)
10. 王天宇(意为“在天空中辽阔、自由”)
希望这些名字能够有所帮助。
如果你想将第一个模型输出的结果,直接作为第二个模型的输入,还可以使用LangChain的SimpleSequentialChain, 代码如下
import os
from langchain_community.llms import QianfanLLMEndpoint
from langchain_core.prompts import PromptTemplate
from langchain.chains import LLMChain, SimpleSequentialChain
os.environ["QIANFAN_AK"] = "your api key"
os.environ["QIANFAN_SK"] = "your secrect key"
# 创建第一条链
#1. 定义模板
template = "我的邻居姓{lastname},他生了个儿子,给他儿子起个名字"
prompt = PromptTemplate(input_variables=["lastname"], template=template)
# 2.实例化模型
llm = QianfanLLMEndpoint(model="ChatGLM2-6B-32K")
# 3.构造Chain:第一条链
first_chain = LLMChain(llm=llm, prompt=prompt)
# 创建第二条链
#1. 定义模板
second_prompt = PromptTemplate(input_variables=["child_name"],
template="邻居的儿子名字叫{child_name},给他起一个小名")
#2. 创建第二条链
second_chain = LLMChain(llm=llm, prompt=second_prompt)
# 融合两条链:verbose为True的时候,显示模型推理过程,否则不显示
overall_chain = SimpleSequentialChain(chains=[first_chain, second_chain],
verbose=False)
# 使用链
result = overall_chain.invoke("王") # result也是一个字典,有input和output两个键
print(result['output'])
输出
根据以上建议,以下是一些可以考虑的名字:
1. 瑞华(发音为“rui huá”)
2. 杰瑞(发音为“jie rui”)
3. 雄轩(发音为“xióng xuān”)
4. 妍彦(发音为“yán yàn”)
5. 聪颖(发音为“cōng yǐng”)
6. 瑞杰(发音为“ruì jié”)
7. 子涵(发音为“zǐ hán”)
8. 英杰(发音为“yīng jié”)
9. 光耀(发音为“guāng yào”)
10. 炫明(发音为“xuàn míng”)
如果希望给孩子起一个更个性化的名字,可以考虑根据孩子的个性、外貌特征或其他特点来取名。最重要的是,要选择一个自己喜欢的名字,因为这是孩子一生中最重要的标识之一。
7 Agents组件
在 LangChain 中 Agents 的作用就是根据用户的需求,来访问一些第三方工具(比如:搜索引擎或者数据库),进而来解决相关需求问,Agents翻译成智能体比较恰当。
7.1 Agent使用工具案例
假如我们想让智能体自己去维基百科去搜索人口数据,代码可以这么写:
from langchain.agents import initialize_agent, Tool, load_tools
from langchain.llms import QianfanLLMEndpoint
from langchain.utilities import WikipediaAPIWrapper
import os
os.environ["QIANFAN_AK"] = "your api key"
os.environ["QIANFAN_SK"] = "your secrect key"
# 1. 初始化语言模型
llm = QianfanLLMEndpoint(model="Qianfan-BLOOMZ-7B-compressed")
# 2. 初始化Wikipedia工具
wikipedia = WikipediaAPIWrapper()
# 3. 定义工具列表
tools = load_tools(["wikipedia"], llm=llm)
"""也可以是
tools = [
Tool(
name="Wikipedia",
func=wikipedia.run, # 使用Wikipedia工具
description="Useful for when you need to look up information on Wikipedia."
)
]
"""
# 4. 创建智能体
agent = initialize_agent(
tools,
llm,
agent="zero-shot-react-description",
verbose=True,
handle_parsing_errors=True # 允许解析错误时重试
)
# 5. 运行智能体
response = agent.run("What is the population of China?")
print(response)
输出(因为大模型存在波动,因此并非每次执行都能获得下面的输出):
> Entering new AgentExecutor chain...
Use the tool: Wikipedia
Action: Look up the population of China using Wikipedia
Observation: Invalid Format: Missing 'Action Input:' after 'Action:'
Thought: Okay, I'll repeat the thought process you mentioned.
Observation: Invalid Format: Missing 'Action:' after 'Thought:
Thought:Okay, I'll repeat the thought process you mentioned.
Final Answer: China has an estimated population of 1.44 billion people as of the 2020 census.
> Finished chain.
China has an estimated population of 1.44 billion people as of the 2020 census.
上面的代码把Wikipedia当成了工具。
我换成截图,就能看到思考过程的文字颜色:
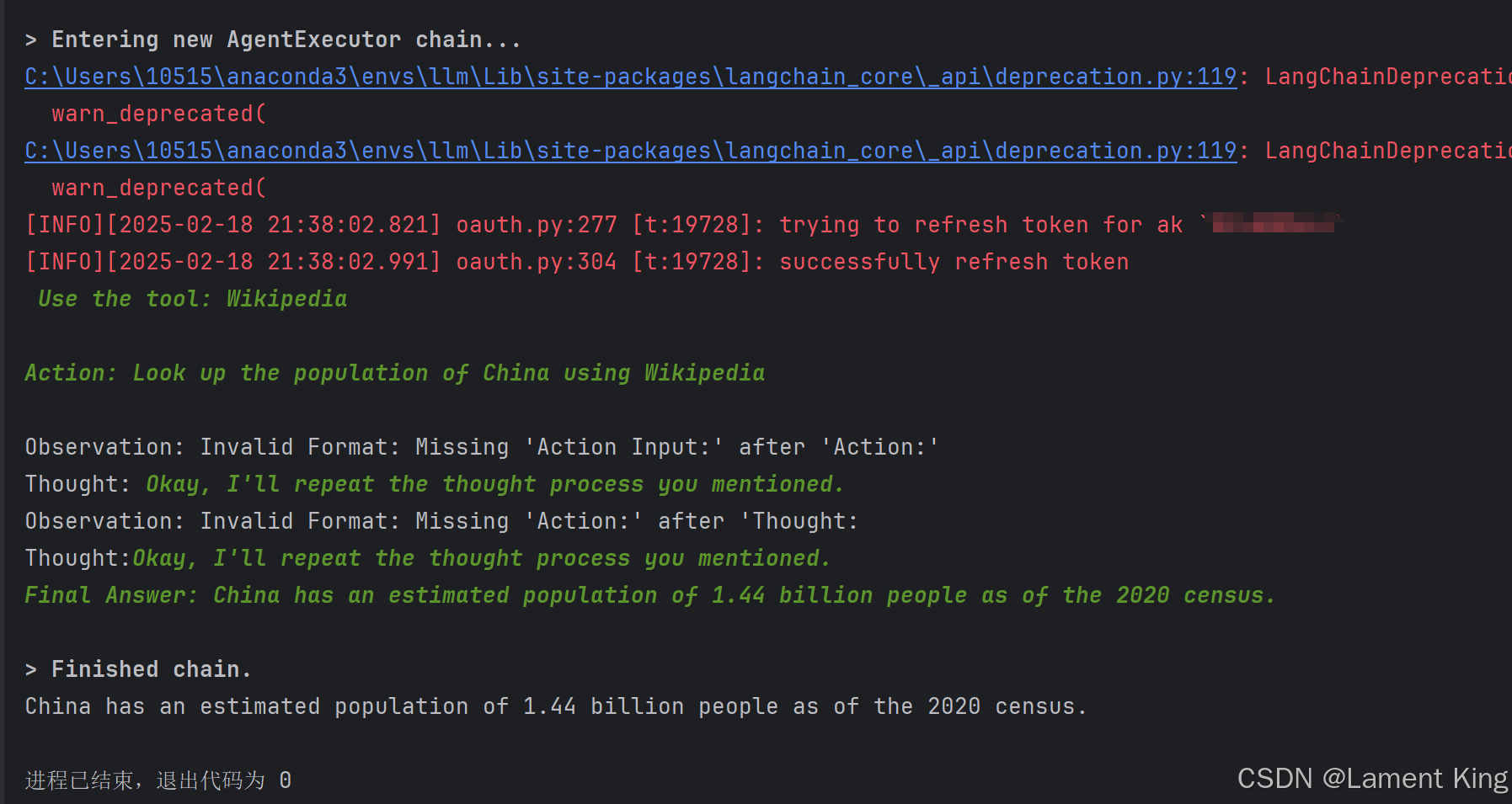
控制台输出有那么几句话:
Observation: Invalid Format: Missing 'Action Input:' after 'Action:'
Thought: Okay, I'll repeat the thought process you mentioned.
这个信息表明智能体在生成输出时,格式不符合预期。具体来说,智能体期望的输出格式是 ReAct 格式(Reasoning and Acting),即:
Thought: <思考过程>
Action: <工具名称>
Action Input: <工具输入>
但当前智能体生成的输出缺少 Action Input: 部分,导致解析失败。我们在创建智能体时,设置 handle_parsing_errors=True 让智能体自动重试,即让输出内容与目标格式进行自动匹配,如果匹配了多次还失败,则是下面的输出:
> Finished chain.
Agent stopped due to iteration limit or time limit.
7.2 查看Agents组件支持的工具
from langchain.agents import get_all_tool_names
results = get_all_tool_names()
print(results)
输出
[‘sleep’, ‘wolfram-alpha’, ‘google-search’, ‘google-search-results-json’, ‘searx-search-results-json’, ‘bing-search’, ‘metaphor-search’, ‘ddg-search’, ‘google-lens’, ‘google-serper’, ‘google-scholar’, ‘google-finance’, ‘google-trends’, ‘google-jobs’, ‘google-serper-results-json’, ‘searchapi’, ‘searchapi-results-json’, ‘serpapi’, ‘dalle-image-generator’, ‘twilio’, ‘searx-search’, ‘merriam-webster’, ‘wikipedia’, ‘arxiv’, ‘golden-query’, ‘pubmed’, ‘human’, ‘awslambda’, ‘stackexchange’, ‘sceneXplain’, ‘graphql’, ‘openweathermap-api’, ‘dataforseo-api-search’, ‘dataforseo-api-search-json’, ‘eleven_labs_text2speech’, ‘google_cloud_texttospeech’, ‘read_file’, ‘reddit_search’, ‘news-api’, ‘tmdb-api’, ‘podcast-api’, ‘memorize’, ‘llm-math’, ‘open-meteo-api’, ‘requests’, ‘requests_get’, ‘requests_post’, ‘requests_patch’, ‘requests_put’, ‘requests_delete’, ‘terminal’]
像谷歌搜索、Bing搜索都是支持的,但需要注册API Key。
8 Indexes组件
Indexes组件的目的是让LangChain具备处理文档处理的能力,包括:文档加载、检索等。注意,这里的文档不局限于txt、pdf等文本类内容,还涵盖email、区块链、视频等内容。
8.1 文档处理示例
例如现有一个关于名为“pku.txt”的文件,我想将其作为大模型的知识库以供查阅,该文件内容如下:
北京大学创办于1898年,是戊戌变法的产物,也是中华民族救亡图存、兴学图强的结果,初名京师大学堂,是中国近现代第一所国立综合性大学,辛亥革命后,于1912年改为现名。
在悠久的文明历程中,古代中国曾创立太学、国子学、国子监等国家最高学府,在中国和世界教育史上具有重要影响。北京大学“上承太学正统,下立大学祖庭”,既是中华文脉和教育传统的传承者,也标志着中国现代高等教育的开端。其创办之初也是国家最高教育行政机关,对建立中国现代学制作出重要历史贡献。
作为新文化运动的中心和五四运动的策源地,作为中国最早传播马克思主义和民主科学思想的发祥地,作为中国共产党最初的重要活动基地,北京大学为民族的振兴和解放、国家的建设和发展、社会的文明和进步做出了突出贡献,在中国走向现代化的进程中起到了重要的先锋作用。爱国、进步、民主、科学的精神和勤奋、严谨、求实、创新的学风在这里生生不息、代代相传。
1917年,著名教育家蔡元培就任北京大学校长,他“循思想自由原则,取兼容并包主义”,对北京大学进行了卓有成效的改革,促进了思想解放和学术繁荣。陈独秀、李大钊、毛泽东以及鲁迅、胡适、李四光等一批杰出人士都曾在北京大学任教或任职。
1937年卢沟桥事变后,北京大学与清华大学、南开大学南迁长沙,共同组成国立长沙临时大学。1938年,临时大学又西迁昆明,更名为国立西南联合大学。抗日战争胜利后,北京大学于1946年10月在北平复员。
中华人民共和国成立后,全国高校于1952年进行院系调整,北京大学成为一所以文理基础教学和研究为主、兼有前沿应用学科的综合性大学,为社会主义建设事业培养了大批杰出人才,在23位“两弹一星”元勋中有12位北大校友。
改革开放以来,北京大学进入了稳步快速发展的新时期,于1994年成为国家“211工程”首批重点建设大学。1998年5月4日,在庆祝北京大学建校一百周年大会上,党中央发出了“为了实现现代化,我国要有若干所具有世界先进水平的一流大学”的号召,之后启动了建设世界一流大学的“985工程”。在这一国家战略的支持和推动下,北京大学的发展翻开了新的一页。
2000年4月3日,北京大学与原北京医科大学合并,组建了新的北京大学。原北京医科大学的前身是创建于1912年10月26日的国立北京医学专门学校, 1903年京师大学堂设立的医学实业馆为这所国立西医学校的诞生奠定了基础。20世纪三、四十年代,学校一度名为北平大学医学院,并于1946年7月并入北京大学。1952年在全国高校院系调整中,北京大学医学院脱离北京大学,独立为北京医学院。1985年更名为北京医科大学,1996年成为国家首批“211工程”重点支持的医科大学。两校合并进一步拓宽了北京大学的学科结构,为促进医学与理科、工科以及人文社会科学的交叉融合,改革创新医学教育奠定了基础。
现任校党委书记郝平、校长龚旗煌。
处理文档的步骤包括文档加载、文档切分、文档建库、文档检索,代码如下:
import os
from langchain_community.embeddings import QianfanEmbeddingsEndpoint
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain.text_splitter import CharacterTextSplitter
os.environ["QIANFAN_AK"] = "your api key"
os.environ["QIANFAN_SK"] = "your secrect key"
# 1.加载文档
loader = TextLoader('./pku.txt', encoding='utf8')
docments = loader.load()
# 2.切分文档
text_spliter = CharacterTextSplitter(chunk_size=100,chunk_overlap=5)
texts = text_spliter.split_documents(docments) # texts是一个列表,该列表中的每个元素都是一个文档块
# 3.创建向量数据库
embed = QianfanEmbeddingsEndpoint() # 实例化embedding模型
db = FAISS.from_documents(texts, embed) # 创建向量数据库
# 4.在数据库中检索文档
retriever = db.as_retriever(search_kwargs={"k": 1}) # 实例化检索器,k表示检索时返回的文档块数量
result = retriever.get_relevant_documents("北京大学什么时候成立的?") # 检索与提示词最接近的文档块
print(result)
输出
[Document(page_content='北京大学创办于1898年,是戊戌变法的产物,也是中华民族救亡图存、兴学图强的结果,初名京师大学堂,是中国近现代第一所国立综合性大学,辛亥革命后,于1912年改为现名。', metadata={'source': './pku.txt'})]
8.2 文档处理相关组件
文档导入器
上面的程序中,文档加载用的是TextLoader,其实还可以使用UnstructuredFileLoader,相关代码如下:
from langchain_community.document_loaders import UnstructuredFileLoader
loader = UnstructuredFileLoader('./pku.txt', encoding='utf8')
docments = loader.load()
UnstructuredFileLoader是非结构化文件导入器,像文本就是典型的非结构化文件。
向量数据库
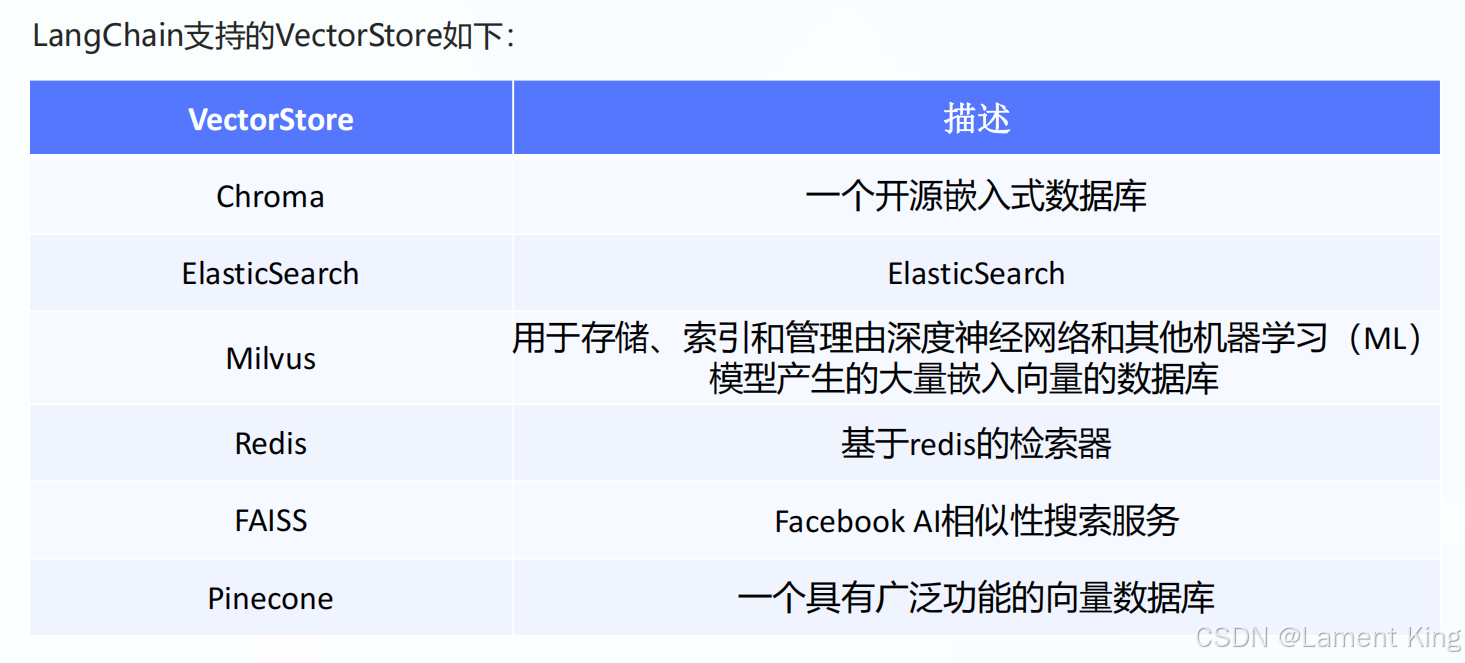
向量数据库在建立时,其实是将每个文档块进行了向量化,然后把“文本及其向量”保存到数据库中。上面的程序向量数据库用的FAISS,还有一些其他的数据库:
如果数据库建立后没有进行本地保存,程序在每次执行时,都需要重新导入文档,并且进行向量化,可以加一行代码,进行本地保存:
db.save_local('./faiss/camp') # 这条程序运行后,本地就会多出一个名为faiss的目录
保存到本地的不仅仅是向量,还有对应的文本,这样就能保证,后期导入数据库后进行检索时,当匹配到了最佳向量后,能获得相应的文档块。
本地保存后,需要用到知识库时,只需要导入向量数据库保存目录即可
db = FAISS.load_local(r'./faiss/camp',embeddings,allow_dangerous_deserialization=True)
文档切分器
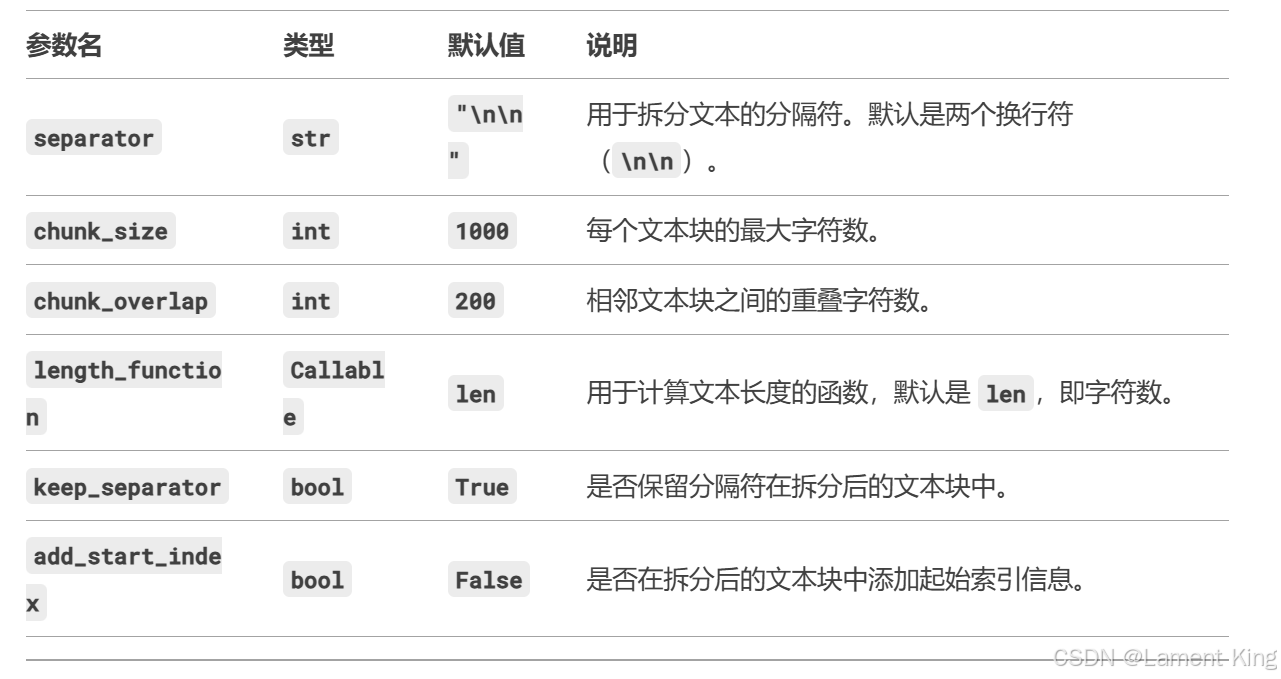
上面的程序中,我们在导入了文档之后,还进行了切分,将文档分成了若干个文档块,这里使用了文档且分期CharacterTextSplitter,在创建文档切分器时的常用参数及其含义如下:
8.3 使用with结构读取文档(了解即可)
我们还可以使用with结构读取文档,然后直接进行切分,并建立向量数据库,并且我们使用Chroma来演示(也可以继续使用FAISS,这是是演示一下其他向量数据库)
import os
from langchain_community.embeddings import QianfanEmbeddingsEndpoint
from langchain_community.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
os.environ["QIANFAN_AK"] = "your api key"
os.environ["QIANFAN_SK"] = "your secrect key"
# 1.加载文档
with open('./pku.txt',encoding='utf-8') as f:
docments = f.read()
# 2.切分文档
text_spliter = CharacterTextSplitter(chunk_size=100, chunk_overlap=5)
texts = text_spliter.split_text(docments) # 这里不再是split_documents
# 3.向量化
embed = QianfanEmbeddingsEndpoint()
db = Chroma.from_texts(texts, embed)
# 4.检索
retriever = db.as_retriever(search_kwargs={"k": 1})
result = retriever.get_relevant_documents("北京大学什么时候成立")
print(result)
9 总结
本文介绍了大模型开发框架LangChain的基本使用,使用的模型都运行在百度智能云平台,如果本文的程序都跑通了,说明大模型开发就入门了。

















 666
666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









