







这里写目录标题
1 ChatGLM简介
ChatGLM是由中国智谱AI(Zhipu AI)与清华大学知识工程实验室(KEG)联合开发的一系列开源双语(中英文)对话大语言模型。该系列模型基于GLM(General Language Model)架构,针对对话场景进行了针对性改进,使其专注于高效推理和自然对话能力,适用于多种实际场景,如智能客服、内容生成、知识问答等,是国内目前的主流大模型之一。
1.1 核心技术特点
-
GLM架构
• 基础框架为自回归填空(Autoregressive Blank Infilling),结合了自编码(BERT)和自回归(GPT)的优势:通过随机遮盖输入文本的片段(称为“空白”),利用双向上下文预测被遮盖内容,兼具理解与生成能力。
• 支持长文本生成和复杂逻辑推理。 -
高效推理
• 采用量化技术(如INT4低精度量化)和模型压缩,显著降低硬件资源需求(例如ChatGLM-6B可在消费级显卡上运行)。 -
对齐优化
• 通过监督微调(SFT)和人类反馈强化学习(RLHF)对齐人类偏好,生成内容更安全、合理。
1.2 主要应用场景
• 智能对话:多轮对话、情感陪伴、个性化交互。
• 知识服务:百科全书式问答、法律/医疗/科技领域专业咨询。
• 内容创作:文案生成、摘要提取、代码编写。
• 企业服务:客服自动化、文档分析、数据分析。
1.3 版本演进
-
ChatGLM-6B(2023年3月)
• 首个开源版本,62亿参数,支持中英双语,可在单张消费级显卡(如RTX 3060)部署。
• 特点:轻量化、低资源需求。 -
ChatGLM2-6B(2023年6月)
• 上下文窗口从2K扩展到8K tokens,推理速度提升42%。
• 引入FlashAttention优化,支持更高效的并行计算。 -
ChatGLM3系列(2023年10月)
• 新增工具调用(Function Call)和代码解释器(Code Interpreter)功能,支持复杂任务执行。
• 推出ChatGLM3-6B(开源)和更大规模的闭源版本(如32B、130B)。 -
ChatGLM4(2024年1月)
• 最新一代模型,支持更长上下文(128K tokens)、多模态输入(图像/语音)和更强的逻辑推理能力(需以官方信息为准)。
• 增强了智能体(Agent)和Retrieval(检索)功能。
• 更快推理速度,更多并发
1.4 总结
ChatGLM系列以高效、实用、安全为核心目标,通过GLM架构的创新和持续迭代,在双语对话场景中展现了强大的竞争力。其开源策略也推动了开发者社区的广泛参与,成为中文大模型领域的重要标杆之一。
本文只介绍原理,不会去复现。
2 GLM的自回归填空机制
要搞明白ChatGLM的原理,那么必须先知道GLM(General Language Model)及其自回归填空机制。
2.1 GLM模型的设计思路
在GLM出来之前,NLP领域主流的预训练模型可以分为三类:
- 自回归模型,代表是GPT,本质上是一个从左到右的语言模型,常用于无条件生成任务(unconditional generation)。
- 自编码模型,代表是BERT,通过某个降噪目标(如消除序列中的掩码)训练的语言编码器,这种模型擅长自然语言理解任务(natural language understanding tasks),常被用来生成句子的上下文表示(即对文本提取特征)。
- 编码器-解码器模型, 代表是T5、BART,拥有完整的Transformer结构,包含一个编码器和一个解码器,常用于有条件的生成任务 (conditional generation),例如翻译、文本摘要、生成回答等。
当时这三类模型各有优缺点,没有一种框架能够在所有的自然语言处理任务中都表现出色。清华大学的研究人员试图设计出一种模型,将上述三种模型统一起来,于是诞生了GLM。
三种结构最大的区别是注意力:GPT的注意力是单向的,所以无法利用到下文的信息;BERT的注意力是双向的,可以同时感知上文和下文,因此在自然语言理解任务上表现很好,但是不适合生成任务。T5的编码器中的注意力是双向,解码器中的注意力是单向的,因此可同时应用于自然语言理解任务和生成任务。但T5为了达到和RoBERTa和DeBERTa相似的性能,往往需要更多的参数量。
要让GLM中同时兼容上述三种结构,只需要让GLM同时存在单向注意力和双向注意力即可。在原本的Transformer模型中,这两种注意力机制是通过修改 attention_mask 实现的。当 attention_mask 是全1矩阵的时候,这时注意力是双向的;当 attention_mask 是三角矩阵的时候(如下图),注意力就是单向。
因此,我们可以在只使用Transformer编码器的情况下,自定义 attention_mask 来兼容三种模型结构,你可以认为它是一个带 Mask 机制的 BERT。
2.2 自回归填充任务
假设原始的文本序列为 x1, x2, x3, x4, x5, x6,采样的两个文本片段为 x3 和 x5、x6,那么掩码后的文本序列为 x1, x2, [M], x4, [M](以下简称Part A)。接下来,我们要根据第一个 [M] 解码出 x3,根据第二个 [M] 依次解码出 x5、x6 ,也就是说,我们的任务是从 [M] 处解码出变长的序列(被称为Part B)。
接下来我们用把遮盖掉的 tokens 拼接起来,为了能将这些变长的 token 序列区别开来,可以在每一个被遮挡的序列前用 [S] 标记,因此,Part B 可以整理成:[S], x3, [S], x5, x6。
随后把 Part A 和 Part B 拼接起来,得到:x1, x2, [M], x4, [M], [S], x3, [S], x5, x6。
在GLM中,位置向量有两个,一者用来记录Part A中的相对顺序,二者用来记录被掩的文本片段内部(简称为Part B)中的相对顺序。例如,[S], x5, x6 的 position1 都是5,因为它们对应的 [M] 在Part A中的位置为5,它们的 position 2 则是 1, 2, 3,这是它们在片段内部的顺序。Part A中的词,其position 2都是0,而 Part B 的词,它们则从1开始计数。
此外,还需要通过自定义 attention mask 来达到以下目的:
- Part A中的词彼此可见(下图(d)中蓝色框中的区域)
- Part B中的词单向可见(图(d)淡黄色的区域)
- Part B可见Part A(图(d)中红色框中的区域)
- 其余不可见(图(d)中灰色的区域)
需要说明的是,Part B包含所有被掩码的文本片段,但是文本片段的相对顺序是随机打乱的,这似乎非常奇怪,但是实验结果表明这样做非常有必要。我个人认为,通过打乱 Part B,可以通过 position 1 和 position 2 控制哪一部分内容先生成,进而提高模型的泛化性。无论怎么排序,都是可以通过 position 1 与 position 2 恢复成原文。
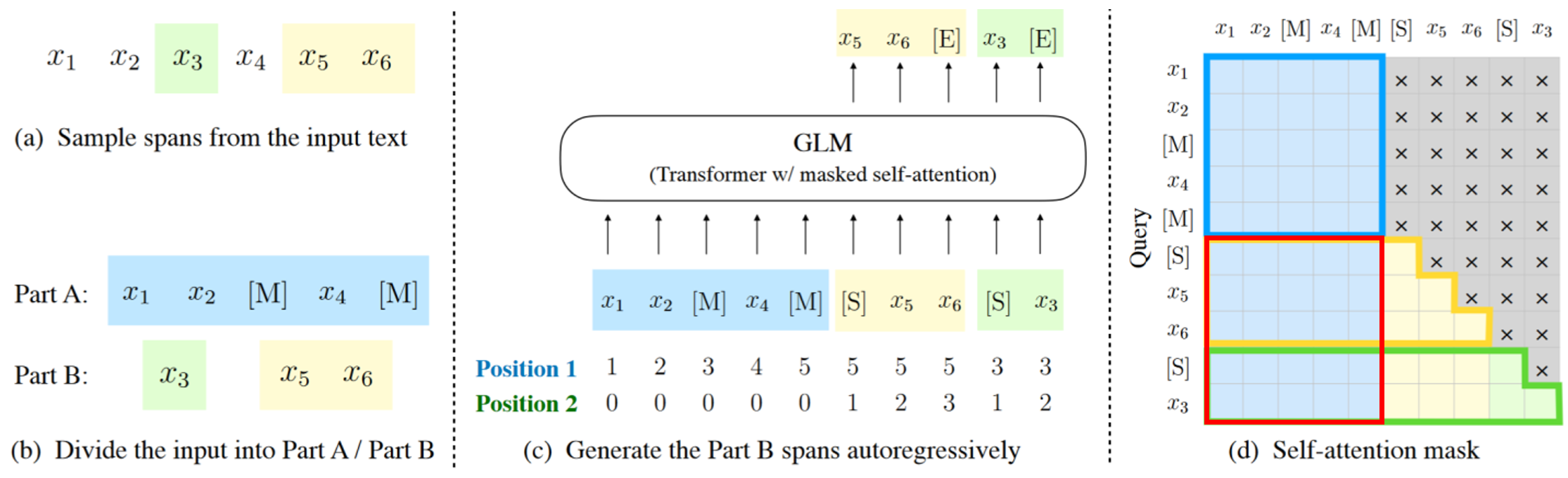
在图©中的右半边,它其实就是错位预测,比如根据输入的 [S] 和位置编码(position 1、position 2)去预测 x5,然后用 x5 和输入的位置编码,去预测 x6,再用 x6 和输入的位置编码去预测片段的截止符 [E]。两个位置编码的使用,并不会限制生成的文本片段的长度,因为生成的时候,你是一个个词喂进去的,即你预测得到 [E] 之后,你要预测下一个单词的时候,position 2 才会重置为1,同时 position 1 的值需要根据你根据要生成的位置来提供。
从图(d)中可以看到,Part A是在做自注意力机制,模型在这些token上面发挥的是编码器的功能,而Part B则做自注意力+交叉注意力,模型在这些token上面发挥的是解码器的功能,但这两部分其实用的是同一个模型,只是用的 attention mask 不一样。
2.3 GLM的简易实现
我们先来实现一下如何根据 Part A 和 Part B 生成 attention mask:
import torch
def create_mask(part_a_lens, part_b_lens, max_len=512):
"""
创建自回归填空的注意力掩码
part_a_lens: Part A 长度,句子的数量是 batch_size
part_b_lens: Part B 长度
max_len: 输入的最大句子长度
"""
batch_size = len(part_a_lens)
mask = torch.zeros(batch_size, max_len, max_len, dtype=torch.bool)
for batch_i in range(batch_size):
part_a_len = part_a_lens[batch_i]
part_b_len = part_b_lens[batch_i]
# 允许所有位置关注 Part A 部分
mask[batch_i, :, :part_a_len] = True
# 生成一个与 Part B 相同的下三角矩阵
ones = torch.ones(part_b_len, part_b_len)
part_b_tril = torch.tril(ones, diagonal=0).type(torch.bool)
# 将 Part B 部分换成下三角矩阵
start = part_a_len
end = part_a_len + part_b_len
mask[batch_i, start: end, start: end] = part_b_tril
# 允许填充部分关注所有位置(不包括自己)
mask[batch_i, end:, :] = True
mask[batch_i, :, end:] = False
return mask
if __name__ == "__main__":
part_a_lens = [6, 5]
part_b_lens = [5, 5]
mask = create_mask(part_a_lens, part_b_lens, max_len=12)
print(mask.type(torch.int8))
输出:
tensor([[[1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0]],
[[1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0]]], dtype=torch.int8)
剩下是模型
import torch
import torch.nn as nn
class GLMPositionalEncoding(nn.Module):
def __init__(self, d_model=512, max_len=512, d_pos1=64, d_pos2=64):
super().__init__()
# position1 位置编码
self.pos1_embed = nn.Embedding(max_len, d_pos1)
# position2 位置编码
self.pos2_embed = nn.Embedding(max_len, d_pos2)
# 将拼接后的位置编码投影到词向量维度
self.pos_projection = nn.Linear(d_pos1 + d_pos2, d_model)
def forward(self, pos1, pos2):
# pos1: [batch_size, seq_len]
# pos2: [batch_size, seq_len]
# 获取两种位置编码
pos1_embed = self.pos1_embed(pos1) # [batch, seq, d_pos_source]
pos2_embed = self.pos2_embed(pos2) # [batch, seq, d_pos_target]
# 拼接并投影到d_model维度
combined = torch.cat([pos1_embed, pos2_embed], dim=-1) # [batch, seq, d_pos_source + d_pos_target]
projected = self.pos_projection(combined) # [batch, seq, d_model]
return projected
class SimpleGLM(nn.Module):
def __init__(self, vocab_size=10000, d_model=512, nhead=8, num_layers=6):
super().__init__()
self.d_model = d_model
# 词向量层
self.token_embed = nn.Embedding(vocab_size, d_model)
# 二维位置编码层
self.pos_encoder = GLMPositionalEncoding(d_model=d_model, max_len=12)
# 简化Transformer编码层(实际GLM使用自定义结构)
encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead, batch_first=True) # 添加 batch_first=True
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
# 线性层,用于输出词概率
self.fc = nn.Linear(d_model, vocab_size)
def forward(self, input_ids, pos1, pos2, mask):
# 输入处理
token_embed = self.token_embed(input_ids) # [batch, seq, d_model]
pos_embed = self.pos_encoder(pos1, pos2) # [batch, seq, d_model]
# 融合词向量与位置编码
embeddings = token_embed + pos_embed # [batch, seq, d_model]
# Transformer处理
hidden_state = self.transformer(embeddings, mask) # [batch, seq, d_model]
# 获取logits
output = self.fc(hidden_state)
return output
# 示例使用
if __name__ == "__main__":
# 参数设置
vocab_size = 10000
batch_size = 2
seq_len = 3
d_model = 512
max_len = 12
# 模型初始化
model = SimpleGLM(vocab_size=vocab_size, d_model=d_model)
# 构造虚拟输入(假设输入为两个样本,一个长为11,另一个长为10)
part_a_lens = [6, 5]
part_b_lens = [5, 5]
mask = create_mask(part_a_lens, part_b_lens, max_len)
input_ids = [[101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 101],
[101, 102, 103, 104, 105, 106, 107, 108, 109, 110]]
position1 = [[0, 1, 2, 3, 4, 5, 5, 5, 5, 3, 3], # Part A:0, 1, 2, 3, 4, 5,PartB:5, 5, 5, 3, 3
[0, 1, 2, 3, 4, 2, 2, 4, 4, 4]] # Part A:0, 1, 2, 3, 4,PartB:2, 2, 4, 4, 4
position2 = [[0, 0, 0, 0, 0, 0, 1, 2, 3, 1, 2],
[0, 0, 0, 0, 0, 1, 2, 1, 2, 3]]
# 填充或者截断
for batch_i in range(batch_size):
if len(input_ids[batch_i]) > max_len:
input_ids[batch_i] = input_ids[batch_i][:max_len]
position1[batch_i] = position1[batch_i][:max_len]
position2[batch_i] = position2[batch_i][:max_len]
elif len(input_ids[batch_i]) < max_len:
pad_len = max_len - len(input_ids[batch_i])
input_ids[batch_i].extend([9999] * pad_len) # 用9999填充
position1[batch_i].extend([max_len - 1] * pad_len) # 用max_len-1填充
position2[batch_i].extend([max_len - 1] * pad_len) # 用max_len-1填充
# print(input_ids)
# 两个样本的mask不同,若打包成一个batch,则无法通过 nn.TransformerEncoderLayer
for batch_i in range(batch_size):
# 转Torch.Tensor
token_ids = torch.tensor(input_ids[batch_i]).unsqueeze(0)
pos1 = torch.tensor(position1[batch_i]).unsqueeze(0)
pos2 = torch.tensor(position2[batch_i]).unsqueeze(0)
# 前向传播
outputs = model(token_ids, pos1, pos2, mask[batch_i])
print("Output shape:", outputs.shape)
输出:
Output shape: torch.Size([1, 12, 10000])
Output shape: torch.Size([1, 12, 10000])
原版的GLM如何让 batch 打包的 mask 通过nn.TransformerEncoderLayer模块,我没去看代码,因此也不知道是怎么操作的,不过已经不重要了,因为本文目的是理解大致过程,具体怎么做的不重要,我们不是复现。
2.4 多任务训练
从上面的代码来看,其实GLM做的事情,仍然是完形填空,只不过填的不仅仅是单个词了,还有可能是句子。如果我们遮盖掉的文本片段较长,那么模型就会有较强的文本生成能力。
作者使用了两个预训练目标来优化GLM,两个目标交替进行,以便同时增强文本理解与文本生成能力:
- 文档级别:从文档中随机采样一个文本片段进行掩码,片段的长度为文档长度的50%-100%。(遮盖掉的多,增强的是文本生成能力)
- 句子级别:从文档中随机掩码若干文本片段,每个文本片段必须为完整的句子,被掩码的词数量为整个文档长度的15%。(遮盖掉的少,增强的是语言理解能力)
2.5 下游任务微调
对于文本分类任务,则遵循 PET。具体来说,给定一个标记的示例 (x, y) ,将输入文本 x 转换为单个 mask token 的填空问题。例如,情感分类任务可以表述为 “{SENTENCE}。这真的是 [M]”,候选标签 y 也映射到填空的答案,称为v(x) 。在情感分类中,标签 “positive” 和“negative” 分别映射到单词 “good” 和 “bad”。
对于文本生成任务,给定的上下文构成了输入的 Part A,末尾附加了一个 [M] 符号,模型自回归地生成 Part B 的文本。可以直接应用预训练的 GLM 进行无条件的生成,或者在下游的条件生成任务上对其进行微调。
2.6 与BERT、GPT的对比
| 机制 | GLM自回归填空 | BERT(自编码) | GPT(自回归) |
|---|---|---|---|
| 任务类型 | 遮盖部分文本并按顺序生成 | 随机遮盖并独立预测 | 从左到右生成全文 |
| 注意力方向 | 双向(允许利用全部已知上下文) | 完全双向 | 单向(仅左侧上下文) |
| 生成能力 | 支持长文本生成 | 仅支持短文本补全 | 支持长文本生成 |
| 训练效率 | 单阶段训练,统一理解和生成 | 需额外微调生成任务 | 仅支持生成任务 |
2.7 局限性
• 计算复杂度:生成时需要多次迭代预测多个空白,推理速度略慢于纯自回归模型。
• 遮盖策略依赖:性能受遮盖比例和长度的影响,需根据任务调整超参数。
3 GLM与ChatGLM的区别
GLM与ChatGLM是同一系列的自然语言处理模型,但它们在设计目标、应用场景和技术细节上存在差异。以下是两者的主要关系与区别:
3.1 基础架构的继承
• GLM:是一个通用的预训练语言模型,由清华大学团队提出,采用自回归空白填充(Autoregressive Blank Infilling)的训练目标。它结合了自回归(如GPT)和自编码(如BERT)模型的优势,支持多种下游任务(文本生成、分类、问答等)。
• ChatGLM:是基于GLM架构优化而来的对话专用模型,继承了GLM的核心技术(如双向注意力机制),但针对对话场景进行了针对性改进,例如调整模型结构、训练数据和生成策略。
3.2 训练目标与数据的差异
• GLM:
• 训练目标:通过随机遮盖文本片段(Blank)并让模型按顺序填充,同时学习上下文理解和生成能力。
• 数据:使用通用大规模文本(如书籍、网页等),覆盖广泛领域的知识。
• ChatGLM:
• 训练目标:在GLM的基础上增加对话相关的优化目标,例如多轮对话一致性、情感理解和指令跟随能力。
• 数据:引入高质量对话数据(如人工标注的对话、客服记录),并可能通过强化学习(RLHF)对齐人类偏好。
3.3 模型结构与技术改进
• ChatGLM的改进点:
• 对话历史处理:优化对长对话上下文的建模,例如通过位置编码扩展或记忆机制增强多轮对话连贯性。
• 生成策略:采用更严格的重复抑制和话题引导技术,减少无效回复。
• 效率优化:可能通过模型量化或动态批处理提升推理速度,适应实时对话需求。
3.4 应用场景
• GLM:适合通用NLP任务(文本生成、摘要、翻译等),例如作为基座模型适配不同领域。
• ChatGLM:专注于对话场景,如智能客服、社交聊天机器人、个性化助手等,强调交互流畅性和意图理解。
3.5 总结
• 关系:ChatGLM是GLM在对话领域的垂直扩展,两者共享底层架构,但ChatGLM通过场景化适配提升了对话效果。
• 选择建议:若需通用文本处理,选择GLM;若需人机交互,优先使用ChatGLM。

















 966
966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









