







🍨 本文为 [🔗365天深度学习训练营] 中的学习记录博客
一、 前期准备
1. 设置GPU
import torch
import torchvision
import torch.nn as nn
import os,PIL,pathlib,warnings
import torchvision.transforms as transforms
from torchvision import transforms,datasets
warnings.filterwarnings("ignore")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
2. 导入数据
data_dir = '/content/drive/MyDrive/Colab Notebooks/data'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeName = [str(path).split('/')[-1] for path in data_paths]

train_transforms = transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize(
mean = [0.485,0.456,0.406],
std = [0.229,0.224,0.225])
])
test_transforms = transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize(
mean = [0.485,0.456,0.406],
std = [0.229,0.224,0.225])
])
total_data = datasets.ImageFolder('/content/drive/MyDrive/Colab Notebooks/data',transform=train_transforms)
total_data
 3. 划分数据集
3. 划分数据集
train_size = int(len(total_data)*0.8)
test_size = len(total_data) - train_size
train_dataset,test_dataset = torch.utils.data.random_split(total_data,[train_size,test_size])
train_dataset,test_dataset
batch_size = 4
train_dl = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,batch_size=batch_size,shuffle=True,num_workers=1)for X, y in test_dl:
print("Shape of X [N,C,H,W]: ", X.shape)
print("Shape of y: ",y.shape,y.dtype)
break
二、搭建包含Backbone模块的模型
1. 搭建模型
import torch.nn.functional as F
def autopad(k,p=None):
if p is None:
p = k // 2 if isinstance(k,int) else [x // 2 for x in k]
return p
class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k,p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self,x):
return self.act(self.bn(self.conv(x)))
class Bottleneck(nn.Module):
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5):
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self,x):
out = self.cv2(self.cv1(x))
return x + out if self.add else out
class C3(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 *c_, c2, 1)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0)for _ in range(n)))
def forward(self,x):
return self.cv3(torch.cat((self.m(self.cv1(x)),self.cv2(x)),dim=1))
class SPPF(nn.Module):
def __init__(self, c1, c2, k=5):
super().__init__()
c_ = c1 // 2
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self,x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter("ignore")
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)],1))
class YOLOv5_backbone(nn.Module):
def __init__(self):
super(YOLOv5_backbone,self).__init__()
self.Conv_1 = Conv(3, 64, 3, 2, 2)
self.Conv_2 = Conv(64, 128, 3, 2)
self.C3_3 = C3(128, 128)
self.Conv_4 = Conv(128, 256, 3, 2)
self.C3_5 = C3(256, 256)
self.Conv_6 = Conv(256, 512, 3, 2)
self.C3_7 = C3(512, 512)
self.Conv_8 = Conv(512, 1024, 3, 2)
self.C3_9 = C3(1024, 1024)
self.SPPF = SPPF(1024, 1024)
self.classifier = nn.Sequential(
nn.Linear(in_features=65536, out_features=100),
nn.ReLU(),
nn.Linear(in_features=100, out_features=4)
)
def forward(self,x):
x = self.Conv_1(x)
x = self.Conv_2(x)
x = self.C3_3(x)
x = self.Conv_4(x)
x = self.C3_5(x)
x = self.Conv_6(x)
x = self.C3_7(x)
x = self.Conv_8(x)
x = self.C3_9(x)
x = self.SPPF(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = YOLOv5_backbone().to(device)
modelUsing cuda device
YOLOv5_backbone(
(Conv_1): Conv(
(conv): Conv2d(3, 64, kernel_size=(3, 3), stride=(2, 2), padding=(2, 2), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(Conv_2): Conv(
(conv): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(C3_3): C3(
(cv1): Conv(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(Conv_4): Conv(
(conv): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(C3_5): C3(
(cv1): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(Conv_6): Conv(
(conv): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(C3_7): C3(
(cv1): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(Conv_8): Conv(
(conv): Conv2d(512, 1024, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(C3_9): C3(
(cv1): Conv(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv3): Conv(
(conv): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
)
)
)
(SPPF): SPPF(
(cv1): Conv(
(conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(cv2): Conv(
(conv): Conv2d(2048, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): SiLU()
)
(m): MaxPool2d(kernel_size=5, stride=1, padding=2, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Linear(in_features=65536, out_features=100, bias=True)
(1): ReLU()
(2): Linear(in_features=100, out_features=4, bias=True)
)
)2.查看模型详细
import torchsummary as summary
summary.summary(model,(3,224,224))----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 113, 113] 1,728
BatchNorm2d-2 [-1, 64, 113, 113] 128
SiLU-3 [-1, 64, 113, 113] 0
Conv-4 [-1, 64, 113, 113] 0
Conv2d-5 [-1, 128, 57, 57] 73,728
BatchNorm2d-6 [-1, 128, 57, 57] 256
SiLU-7 [-1, 128, 57, 57] 0
Conv-8 [-1, 128, 57, 57] 0
Conv2d-9 [-1, 64, 57, 57] 8,192
BatchNorm2d-10 [-1, 64, 57, 57] 128
SiLU-11 [-1, 64, 57, 57] 0
Conv-12 [-1, 64, 57, 57] 0
Conv2d-13 [-1, 64, 57, 57] 4,096
BatchNorm2d-14 [-1, 64, 57, 57] 128
SiLU-15 [-1, 64, 57, 57] 0
Conv-16 [-1, 64, 57, 57] 0
Conv2d-17 [-1, 64, 57, 57] 36,864
BatchNorm2d-18 [-1, 64, 57, 57] 128
SiLU-19 [-1, 64, 57, 57] 0
Conv-20 [-1, 64, 57, 57] 0
Bottleneck-21 [-1, 64, 57, 57] 0
Conv2d-22 [-1, 64, 57, 57] 8,192
BatchNorm2d-23 [-1, 64, 57, 57] 128
SiLU-24 [-1, 64, 57, 57] 0
Conv-25 [-1, 64, 57, 57] 0
Conv2d-26 [-1, 128, 57, 57] 16,384
BatchNorm2d-27 [-1, 128, 57, 57] 256
SiLU-28 [-1, 128, 57, 57] 0
Conv-29 [-1, 128, 57, 57] 0
C3-30 [-1, 128, 57, 57] 0
Conv2d-31 [-1, 256, 29, 29] 294,912
BatchNorm2d-32 [-1, 256, 29, 29] 512
SiLU-33 [-1, 256, 29, 29] 0
Conv-34 [-1, 256, 29, 29] 0
Conv2d-35 [-1, 128, 29, 29] 32,768
BatchNorm2d-36 [-1, 128, 29, 29] 256
SiLU-37 [-1, 128, 29, 29] 0
Conv-38 [-1, 128, 29, 29] 0
Conv2d-39 [-1, 128, 29, 29] 16,384
BatchNorm2d-40 [-1, 128, 29, 29] 256
SiLU-41 [-1, 128, 29, 29] 0
Conv-42 [-1, 128, 29, 29] 0
Conv2d-43 [-1, 128, 29, 29] 147,456
BatchNorm2d-44 [-1, 128, 29, 29] 256
SiLU-45 [-1, 128, 29, 29] 0
Conv-46 [-1, 128, 29, 29] 0
Bottleneck-47 [-1, 128, 29, 29] 0
Conv2d-48 [-1, 128, 29, 29] 32,768
BatchNorm2d-49 [-1, 128, 29, 29] 256
SiLU-50 [-1, 128, 29, 29] 0
Conv-51 [-1, 128, 29, 29] 0
Conv2d-52 [-1, 256, 29, 29] 65,536
BatchNorm2d-53 [-1, 256, 29, 29] 512
SiLU-54 [-1, 256, 29, 29] 0
Conv-55 [-1, 256, 29, 29] 0
C3-56 [-1, 256, 29, 29] 0
Conv2d-57 [-1, 512, 15, 15] 1,179,648
BatchNorm2d-58 [-1, 512, 15, 15] 1,024
SiLU-59 [-1, 512, 15, 15] 0
Conv-60 [-1, 512, 15, 15] 0
Conv2d-61 [-1, 256, 15, 15] 131,072
BatchNorm2d-62 [-1, 256, 15, 15] 512
SiLU-63 [-1, 256, 15, 15] 0
Conv-64 [-1, 256, 15, 15] 0
Conv2d-65 [-1, 256, 15, 15] 65,536
BatchNorm2d-66 [-1, 256, 15, 15] 512
SiLU-67 [-1, 256, 15, 15] 0
Conv-68 [-1, 256, 15, 15] 0
Conv2d-69 [-1, 256, 15, 15] 589,824
BatchNorm2d-70 [-1, 256, 15, 15] 512
SiLU-71 [-1, 256, 15, 15] 0
Conv-72 [-1, 256, 15, 15] 0
Bottleneck-73 [-1, 256, 15, 15] 0
Conv2d-74 [-1, 256, 15, 15] 131,072
BatchNorm2d-75 [-1, 256, 15, 15] 512
SiLU-76 [-1, 256, 15, 15] 0
Conv-77 [-1, 256, 15, 15] 0
Conv2d-78 [-1, 512, 15, 15] 262,144
BatchNorm2d-79 [-1, 512, 15, 15] 1,024
SiLU-80 [-1, 512, 15, 15] 0
Conv-81 [-1, 512, 15, 15] 0
C3-82 [-1, 512, 15, 15] 0
Conv2d-83 [-1, 1024, 8, 8] 4,718,592
BatchNorm2d-84 [-1, 1024, 8, 8] 2,048
SiLU-85 [-1, 1024, 8, 8] 0
Conv-86 [-1, 1024, 8, 8] 0
Conv2d-87 [-1, 512, 8, 8] 524,288
BatchNorm2d-88 [-1, 512, 8, 8] 1,024
SiLU-89 [-1, 512, 8, 8] 0
Conv-90 [-1, 512, 8, 8] 0
Conv2d-91 [-1, 512, 8, 8] 262,144
BatchNorm2d-92 [-1, 512, 8, 8] 1,024
SiLU-93 [-1, 512, 8, 8] 0
Conv-94 [-1, 512, 8, 8] 0
Conv2d-95 [-1, 512, 8, 8] 2,359,296
BatchNorm2d-96 [-1, 512, 8, 8] 1,024
SiLU-97 [-1, 512, 8, 8] 0
Conv-98 [-1, 512, 8, 8] 0
Bottleneck-99 [-1, 512, 8, 8] 0
Conv2d-100 [-1, 512, 8, 8] 524,288
BatchNorm2d-101 [-1, 512, 8, 8] 1,024
SiLU-102 [-1, 512, 8, 8] 0
Conv-103 [-1, 512, 8, 8] 0
Conv2d-104 [-1, 1024, 8, 8] 1,048,576
BatchNorm2d-105 [-1, 1024, 8, 8] 2,048
SiLU-106 [-1, 1024, 8, 8] 0
Conv-107 [-1, 1024, 8, 8] 0
C3-108 [-1, 1024, 8, 8] 0
Conv2d-109 [-1, 512, 8, 8] 524,288
BatchNorm2d-110 [-1, 512, 8, 8] 1,024
SiLU-111 [-1, 512, 8, 8] 0
Conv-112 [-1, 512, 8, 8] 0
MaxPool2d-113 [-1, 512, 8, 8] 0
MaxPool2d-114 [-1, 512, 8, 8] 0
MaxPool2d-115 [-1, 512, 8, 8] 0
Conv2d-116 [-1, 1024, 8, 8] 2,097,152
BatchNorm2d-117 [-1, 1024, 8, 8] 2,048
SiLU-118 [-1, 1024, 8, 8] 0
Conv-119 [-1, 1024, 8, 8] 0
SPPF-120 [-1, 1024, 8, 8] 0
Linear-121 [-1, 100] 6,553,700
ReLU-122 [-1, 100] 0
Linear-123 [-1, 4] 404
================================================================
Total params: 21,729,592
Trainable params: 21,729,592
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 137.59
Params size (MB): 82.89
Estimated Total Size (MB): 221.06
----------------------------------------------------------------三、训练模型
1.编写训练模型
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
num_batchsize = len(dataloader)
train_acc, train_loss = 0,0
for X, y in dataloader:
X ,y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batchsize
return train_acc, train_loss
2.编写测试函数
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, test_acc = 0, 0
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
3.正式训练
import copy
optimizer = torch.optim.Adam(model.parameters(), lr= 1e-4)
loss_fn = nn.CrossEntropyLoss()
epochs = 60
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_acc = 0
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
lr = optimizer.state_dict()['param_groups'][0]['lr']
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss,
epoch_test_acc*100, epoch_test_loss, lr))
PATH = './best_model.pth'
torch.save(best_model.state_dict(), PATH)
print('Done')
import copy
optimizer = torch.optim.Adam(model.parameters(), lr= 1e-4)
loss_fn = nn.CrossEntropyLoss()
epochs = 60
train_loss = []
train_acc = []
test_loss = []
Epoch: 1, Train_acc:56.3%, Train_loss:1.146, Test_acc:64.0%, Test_loss:0.842, Lr:1.00E-04
Epoch: 2, Train_acc:64.6%, Train_loss:0.864, Test_acc:72.9%, Test_loss:0.637, Lr:1.00E-04
Epoch: 3, Train_acc:70.7%, Train_loss:0.687, Test_acc:79.6%, Test_loss:0.496, Lr:1.00E-04
Epoch: 4, Train_acc:73.9%, Train_loss:0.669, Test_acc:77.3%, Test_loss:0.508, Lr:1.00E-04
Epoch: 5, Train_acc:74.9%, Train_loss:0.587, Test_acc:68.4%, Test_loss:0.615, Lr:1.00E-04
Epoch: 6, Train_acc:79.9%, Train_loss:0.484, Test_acc:80.0%, Test_loss:0.558, Lr:1.00E-04
Epoch: 7, Train_acc:80.3%, Train_loss:0.473, Test_acc:83.1%, Test_loss:0.396, Lr:1.00E-04
Epoch: 8, Train_acc:83.3%, Train_loss:0.420, Test_acc:84.4%, Test_loss:0.349, Lr:1.00E-04
Epoch: 9, Train_acc:83.9%, Train_loss:0.433, Test_acc:85.3%, Test_loss:0.352, Lr:1.00E-04
Epoch:10, Train_acc:85.3%, Train_loss:0.363, Test_acc:84.0%, Test_loss:0.513, Lr:1.00E-04
Epoch:11, Train_acc:89.3%, Train_loss:0.302, Test_acc:85.3%, Test_loss:0.403, Lr:1.00E-04
Epoch:12, Train_acc:87.0%, Train_loss:0.344, Test_acc:84.4%, Test_loss:0.440, Lr:1.00E-04
Epoch:13, Train_acc:87.7%, Train_loss:0.361, Test_acc:89.8%, Test_loss:0.317, Lr:1.00E-04
Epoch:14, Train_acc:88.7%, Train_loss:0.299, Test_acc:88.4%, Test_loss:0.314, Lr:1.00E-04
Epoch:15, Train_acc:91.6%, Train_loss:0.211, Test_acc:82.7%, Test_loss:0.763, Lr:1.00E-04
Epoch:16, Train_acc:92.8%, Train_loss:0.226, Test_acc:87.6%, Test_loss:0.382, Lr:1.00E-04
Epoch:17, Train_acc:91.4%, Train_loss:0.214, Test_acc:90.2%, Test_loss:0.327, Lr:1.00E-04
Epoch:18, Train_acc:94.1%, Train_loss:0.181, Test_acc:89.8%, Test_loss:0.273, Lr:1.00E-04
Epoch:19, Train_acc:93.9%, Train_loss:0.203, Test_acc:89.3%, Test_loss:0.377, Lr:1.00E-04
Epoch:20, Train_acc:95.7%, Train_loss:0.121, Test_acc:92.0%, Test_loss:0.249, Lr:1.00E-04
Epoch:21, Train_acc:96.4%, Train_loss:0.099, Test_acc:91.1%, Test_loss:0.285, Lr:1.00E-04
Epoch:22, Train_acc:97.7%, Train_loss:0.078, Test_acc:89.8%, Test_loss:0.290, Lr:1.00E-04
Epoch:23, Train_acc:95.7%, Train_loss:0.142, Test_acc:91.6%, Test_loss:0.296, Lr:1.00E-04
Epoch:24, Train_acc:97.0%, Train_loss:0.086, Test_acc:90.7%, Test_loss:0.311, Lr:1.00E-04
Epoch:25, Train_acc:95.3%, Train_loss:0.141, Test_acc:88.9%, Test_loss:0.458, Lr:1.00E-04
Epoch:26, Train_acc:97.6%, Train_loss:0.069, Test_acc:92.4%, Test_loss:0.234, Lr:1.00E-04
Epoch:27, Train_acc:96.9%, Train_loss:0.075, Test_acc:90.2%, Test_loss:0.322, Lr:1.00E-04
Epoch:28, Train_acc:96.2%, Train_loss:0.103, Test_acc:87.1%, Test_loss:0.428, Lr:1.00E-04
Epoch:29, Train_acc:96.4%, Train_loss:0.107, Test_acc:89.8%, Test_loss:0.381, Lr:1.00E-04
Epoch:30, Train_acc:96.1%, Train_loss:0.116, Test_acc:90.2%, Test_loss:0.380, Lr:1.00E-04
Epoch:31, Train_acc:96.0%, Train_loss:0.125, Test_acc:86.7%, Test_loss:0.425, Lr:1.00E-04
Epoch:32, Train_acc:98.4%, Train_loss:0.047, Test_acc:81.3%, Test_loss:0.978, Lr:1.00E-04
Epoch:33, Train_acc:96.6%, Train_loss:0.098, Test_acc:90.2%, Test_loss:0.504, Lr:1.00E-04
Epoch:34, Train_acc:98.1%, Train_loss:0.059, Test_acc:91.1%, Test_loss:0.307, Lr:1.00E-04
Epoch:35, Train_acc:98.1%, Train_loss:0.053, Test_acc:88.4%, Test_loss:0.429, Lr:1.00E-04
Epoch:36, Train_acc:99.1%, Train_loss:0.035, Test_acc:87.6%, Test_loss:0.442, Lr:1.00E-04
Epoch:37, Train_acc:99.4%, Train_loss:0.015, Test_acc:88.4%, Test_loss:0.445, Lr:1.00E-04
Epoch:38, Train_acc:99.1%, Train_loss:0.027, Test_acc:88.4%, Test_loss:0.446, Lr:1.00E-04
Epoch:39, Train_acc:98.2%, Train_loss:0.048, Test_acc:86.2%, Test_loss:0.644, Lr:1.00E-04
Epoch:40, Train_acc:97.3%, Train_loss:0.072, Test_acc:84.9%, Test_loss:0.743, Lr:1.00E-04
Epoch:41, Train_acc:94.8%, Train_loss:0.159, Test_acc:88.9%, Test_loss:0.446, Lr:1.00E-04
Epoch:42, Train_acc:96.8%, Train_loss:0.096, Test_acc:87.1%, Test_loss:0.573, Lr:1.00E-04
Epoch:43, Train_acc:99.4%, Train_loss:0.025, Test_acc:88.4%, Test_loss:0.370, Lr:1.00E-04
Epoch:44, Train_acc:99.7%, Train_loss:0.010, Test_acc:90.2%, Test_loss:0.490, Lr:1.00E-04
Epoch:45, Train_acc:99.4%, Train_loss:0.015, Test_acc:87.1%, Test_loss:0.599, Lr:1.00E-04
Epoch:46, Train_acc:99.1%, Train_loss:0.035, Test_acc:86.2%, Test_loss:0.602, Lr:1.00E-04
Epoch:47, Train_acc:98.2%, Train_loss:0.057, Test_acc:89.3%, Test_loss:0.431, Lr:1.00E-04
Epoch:48, Train_acc:98.7%, Train_loss:0.043, Test_acc:89.3%, Test_loss:0.431, Lr:1.00E-04
Epoch:49, Train_acc:98.1%, Train_loss:0.081, Test_acc:91.1%, Test_loss:0.351, Lr:1.00E-04
Epoch:50, Train_acc:97.4%, Train_loss:0.084, Test_acc:84.0%, Test_loss:0.625, Lr:1.00E-04
Epoch:51, Train_acc:97.8%, Train_loss:0.055, Test_acc:92.4%, Test_loss:0.308, Lr:1.00E-04
Epoch:52, Train_acc:98.8%, Train_loss:0.042, Test_acc:91.1%, Test_loss:0.324, Lr:1.00E-04
Epoch:53, Train_acc:99.3%, Train_loss:0.025, Test_acc:91.1%, Test_loss:0.327, Lr:1.00E-04
Epoch:54, Train_acc:98.9%, Train_loss:0.041, Test_acc:89.8%, Test_loss:0.419, Lr:1.00E-04
Epoch:55, Train_acc:98.8%, Train_loss:0.036, Test_acc:89.3%, Test_loss:0.422, Lr:1.00E-04
Epoch:56, Train_acc:99.4%, Train_loss:0.013, Test_acc:92.4%, Test_loss:0.351, Lr:1.00E-04
Epoch:57, Train_acc:99.7%, Train_loss:0.012, Test_acc:89.8%, Test_loss:0.417, Lr:1.00E-04
Epoch:58, Train_acc:99.9%, Train_loss:0.007, Test_acc:88.9%, Test_loss:0.366, Lr:1.00E-04
Epoch:59, Train_acc:99.9%, Train_loss:0.005, Test_acc:89.8%, Test_loss:0.545, Lr:1.00E-04
Epoch:60, Train_acc:98.4%, Train_loss:0.053, Test_acc:92.9%, Test_loss:0.378, Lr:1.00E-04
Done四、结果可视化
1.Loss 与 Accuracy 图
import warnings
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
epochs_range = range(epochs)
plt.figure(figsize=(12,3))
plt.subplot(121)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(122)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show() 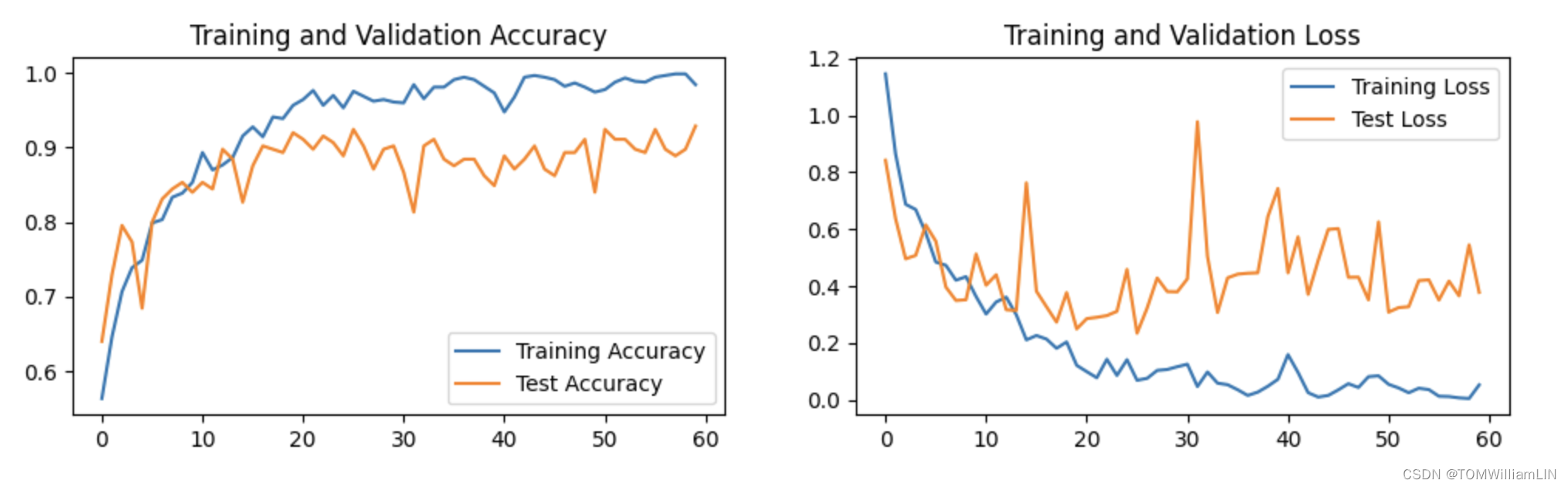
best_model.load_state_dict(torch.load(PATH, map_location=device))
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
epoch_test_acc, epoch_test_loss
5.个人总结
Backbone 模块的作用
Backbone 模块的主要作用是从输入图像中提取丰富的语义特征信息,为后续的目标检测任务提供有价值的特征表示。在 YOLOv5 中,Backbone 模块将输入图像映射到一个高维的特征空间,捕捉图像中的低级特征(如边缘、纹理等)和高级语义特征(如物体部件等)。这些特征信息对于准确检测和识别目标物体至关重要。
Backbone 模块的内部结构
YOLOv5 的 Backbone 模块采用了广泛使用的 CSPDarknet53 网络架构,它是基于 DarkNet-53 网络演变而来。CSPDarknet53 包含以下几个主要部分:
1.卷积层(Convolutional Layers) : 一系列标准卷积层用于提取低级特征,如边缘、纹理等。这些层通过卷积操作从输入图像中学习局部图案和特征。
• Conv 模块 :包含卷积层、BN 层和激活函数(SiLU 或 LeakyReLU)
2.残差连接(Residual Connections): 残差连接是 CSPDarknet53 的一个关键部分,它们允许梯度在训练过程中更容易地流动,从而缓解了梯度消失/爆炸问题。残差连接将低层特征与高层特征进行融合,增强了特征的表达能力。
• Bottleneck 模块 : 包括两个卷积层和一个残差连接
3.CSP模块(Cross Stage Partial Connections) : CSP 模块是 CSPDarknet53 的核心创新,它将主干网络分为两个部分:一部分用于捕获富有语义信息的特征,另一部分用于捕获低级细节特征。这两部分特征在后面会进行融合,提高了特征的判别能力(Discriminative Power)。
• C3模块 :是CSP模块的实习之一,包括多个Bottleneck层
4.下采样层(Downsampling Layers): 下采样层通常由最大池化或卷积 stride 完成,用于逐步减小特征图的空间尺寸,扩大感受野,捕获更大范围的上下文信息。
• 在YOLOv5 中, 下采样通过卷积步长实习的
5.SPPF模块(Spatial Pyramid Pooling - Fast):
- 输入特征图 SPPF 模块的输入是一个来自 backbone 网络的特征图(feature map)。
- 空间金字塔池化(Spatial Pyramid Pooling) 特征图被分割为多个尺度的空间金字塔(spatial pyramid)。每个金字塔级别对应一个池化窗口(pooling bin),窗口大小不同。通常使用的金字塔级别有 1x1, 2x2, 3x3 和 6x6。
- 池化操作 在每个池化窗口中,执行最大池化操作,生成一个对应尺度的特征图。因此,对于每个尺度级别,都会输出一个相应的池化特征图。
- 特征图拼接 来自不同尺度的池化特征图被沿着通道维度拼接(concatenate)在一起,形成一个新的特征图。
- 通过这种方式,SPPF 模块可以从单个特征图中提取多尺度的特征信息。不同尺度的特征对应不同大小的目标物体,有助于检测不同尺寸的目标。















 7109
7109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









