







1.正则表达式介绍
1.1.什么是正则表达式
Regular Expression, 正则表达式, 一种使用表达式的方式对字符串进行匹配的语法规则.
说人话就是通过写一串表达式的方式从文本中拿到你想要的内容。对应爬虫中的应用就是从页面源代码中提取我们想要的数据。
在线测试正则表达式在线正则表达式测试
1.2.正则表达式的语法
-
直接匹配
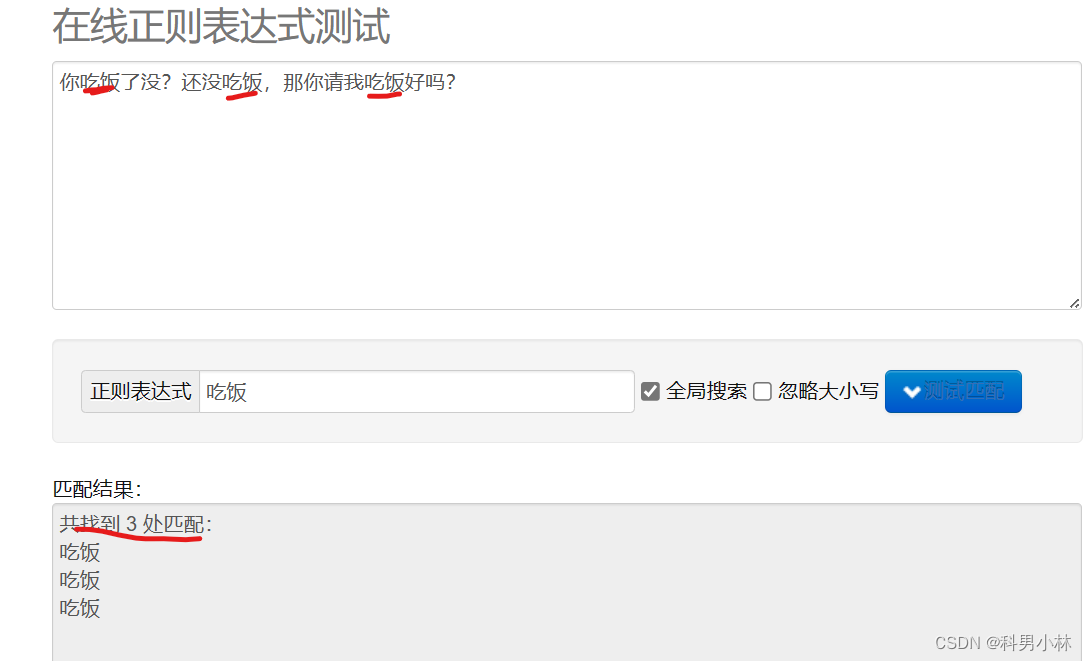
通过直接给定文本可以找到全部的匹配
-
元字符:具有固定含义的特殊符号
常用元字符:
. √匹配除换行符以外的任意字符. \w √匹配字母或数字或下划线. \s 匹配任意的空白符 \d √匹配数字 \n 匹配一个换行符 \t 匹配一个制表符 ^ 匹配字符串的开始 $ 匹配字符串的结尾 \W 匹配非字母或数字或下划线 \D 匹配非数字 \S 匹配非空白符 a|b 匹配字符a或字符b () √匹配括号内的表达式,也表示一个组 [...] √匹配字符组中的字符 [^...] 匹配除了字符组中字符的所有字符这里介绍一下在爬虫中使用较多的一些元字符:
str: 你吃饭了没?还没吃饭,那你请我吃饭好吗? reg: .吃饭 匹配过程:从文本开头找,因为.匹配任意字符(除换行符),所以找后面吃饭,最终找到3处结果 匹配结果:3处匹配,分别为:你吃饭,没吃饭,我吃饭 str: 我的名字是ab_cd,我的电话是12345654321,你记住了吗? reg: \w\w\w 匹配过程:从文本开头找,因为\w匹配字母或数字或下划线,所以找到第一个ab_,继续往后走,cd只有连个字符,不满足要求,后面同理 匹配结果:4处匹配,分别为:ab_,123,456,543 str: 我的名字是ab_cd,我的电话是12345654321,你记住了吗? reg: \d\d\d\d\d\d\d\d\d\d\d 匹配过程:文本中只有电话是11位数字 匹配结果:1处匹配,12345654321 -
量词: 控制前面的元字符出现的次数
* 重复零次或更多次 + 重复一次或更多次 ? 重复零次或一次 {n} 重复n次 {n,} 重复n次或更多次 {n,m} 重复n到m次贪婪匹配和惰性匹配(重点)
.* 贪婪匹配, 尽可能多的去匹配结果 .*? 惰性匹配, 尽可能少的去匹配结果这两个要着重的说一下. 因为我们写爬虫用的最多的就是这个惰性匹配.
先看案例
str: 玩儿吃鸡游戏, 晚上一起上游戏, 干嘛呢? 打游戏啊 reg: 玩儿.*?游戏 此时匹配的是: 玩儿吃鸡游戏 reg: 玩儿.*游戏 此时匹配的是: 玩儿吃鸡游戏, 晚上一起上游戏, 干嘛呢? 打游戏 str: <div>胡辣汤</div> reg: <.*> 结果: <div>胡辣汤</div> str: <div>胡辣汤</div> reg: <.*?> 结果: <div> </div> str: <div class="abc"><div>胡辣汤</div><div>饭团</div></div> reg: <div>.*?</div> 结果: <div>胡辣汤</div> <div>饭团</div> 所以我们能发现这样一个规律: .*? 表示尽可能少的匹配, .*表示尽可能多的匹配, 暂时先记住这个规律. 后面写爬虫会用到
1.3.在Python中使用正则表达式
re模块
re模块中我们只需要记住这么几个功能就够我们使用了.
-
findall 查找所有. 返回list
lst = re.findall("m", "mai le fo len, mai ni mei!") print(lst) # ['m', 'm', 'm'] lst = re.findall(r"\d+", "5点之前. 你要给我5000万") print(lst) # ['5', '5000'] -
search 会进行匹配. 但是如果匹配到了第一个结果. 就会返回这个结果. 如果匹配不上search返回的则是None
ret = re.search(r'\d', '5点之前. 你要给我5000万').group() print(ret) # 5 -
match 只能从字符串的开头进行匹配(再见)
ret = re.match('a', 'abc').group() print(ret) # a -
finditer 和findall差不多. 只不过这时返回的是迭代器(重点)
it = re.finditer("m", "mai le fo len, mai ni mei!") for el in it: print(el.group()) # 依然需要分组 -
compile() 可以将一个长长的正则进行预加载. 方便后面的使用
obj = re.compile(r'\d{3}') # 将正则表达式编译成为一个 正则表达式对象, 规则要匹配的是3个数字 ret = obj.search('abc123eeee') # 正则表达式对象调用search, 参数为待匹配的字符串 print(ret.group()) # 结果: 123 -
正则中的内容如何单独提取?
单独获取到正则中的具体内容可以给分组起名字
s = """ <div class='西游记'><span id='10010'>中国联通</span></div> """ obj = re.compile(r"<span id='(?P<id>\d+)'>(?P<name>\w+)</span>", re.S) result = obj.search(s) print(result.group()) # 结果: <span id='10010'>中国联通</span> print(result.group("id")) # 结果: 10010 # 获取id组的内容 print(result.group("name")) # 结果: 中国联通 # 获取name组的内容这里可以看到我们可以通过使用分组. 来对正则匹配到的内容进一步的进行筛选.
-
正则表达式本身是用来提取字符串中的内容的. 也可以用作字符串的替换
import re r = re.split(r"\d+", "我今年19岁了, 你知道么, 19岁就已经很大了. 周杰伦20岁就得奖了") print(r) # ['我今年', '岁了, 你知道么, ', '岁就已经很大了. 周杰伦', '岁就得奖了'] # 替换 r = re.sub(r"\d+", "18", "我今年19岁了, 你知道么, 19岁就已经很大了. 周杰伦20岁就得奖了") print(r) # 我今年18岁了, 你知道么, 18岁就已经很大了. 周杰伦18岁就得奖了
哦了. 正则. 这些东西够用了.
2.应用正则表达式在爬虫
我们去笔趣阁任意找一本小说,这里我以十日终焉(杀虫队队员) 最新章节 无弹窗 全文免费阅读 - 笔趣阁这个网址为例,
思路剖析:访问网页,打开页面源代码,看其中是否有我们需要的内容。如果有,通过正则解析拿取数据,如果没有,进入抓包工具找数据。
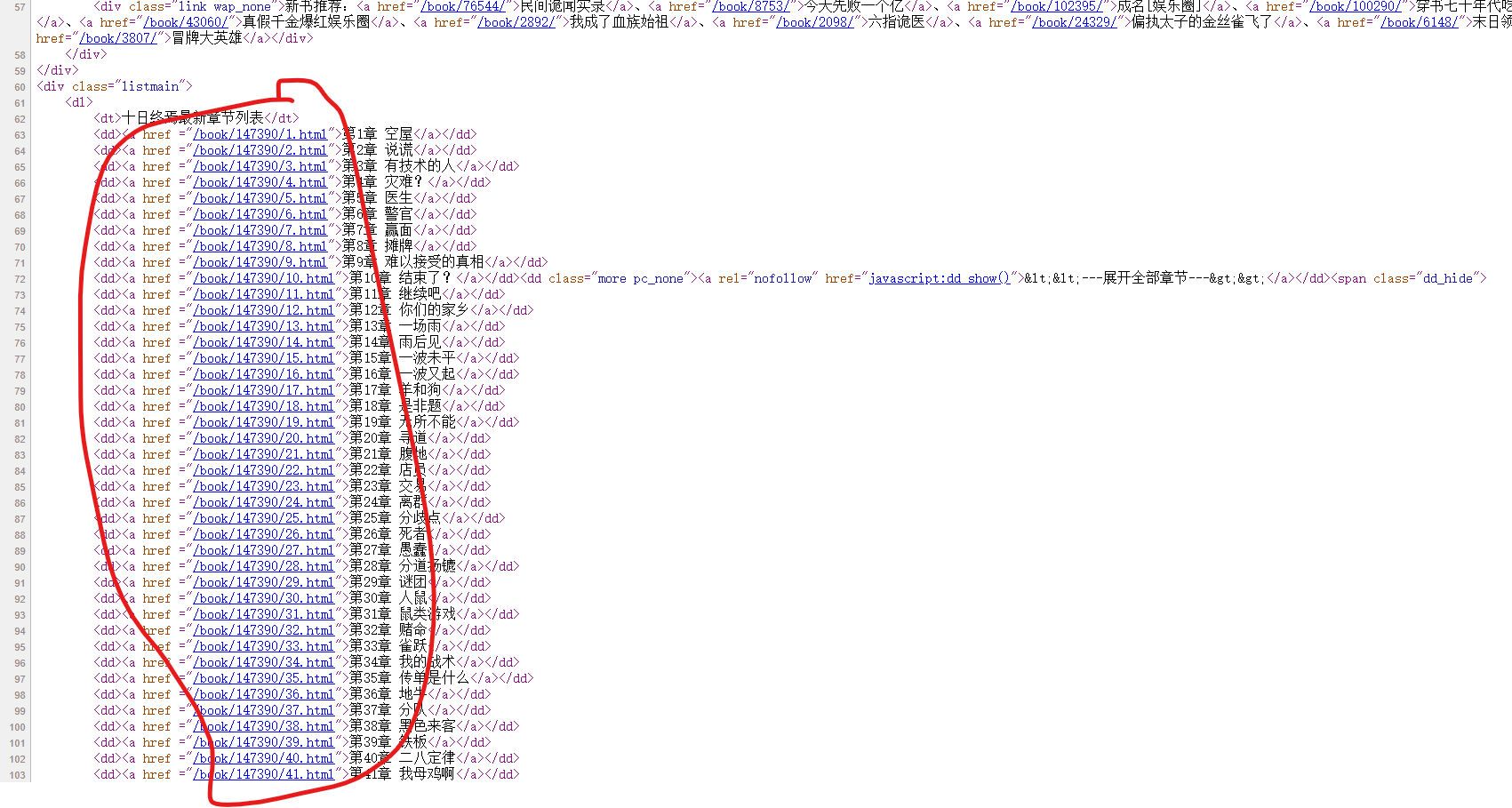
通过访问页面源代码我们可以看见每一章节的url确实在源代码中,那么我们考虑用正则将页面源代码提取出来,正则表达式为:
'<dd><a href ="(?P<url>.*?)"'通过正则我们拿到了章节的url,通过和原始域名拼接我们可以拿到完整的章节url,进入章节爬取小说正文:

同样通过正则拿到正文,正则表达式为:
<div id="chaptercontent" class="Readarea ReadAjax_content">(?P<content>.*?)请收藏本站对于拿下来的文本,<br /><br />这种我们不希望看到的内容,我们可以通过字符串操作将它替换掉,最后将内容写入本地,就完成的这本小说的爬取。
全部代码如下:
import requests
import re
from urllib.parse import urljoin
# 笔趣阁十日终焉地址
url = "https://www.biqg.cc/book/147390/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"
}
resp = requests.get(url, headers=headers)
main_page_source = resp.text
# print(main_page_source)
contents_url_re = re.compile(r'<dd><a href ="(?P<url>.*?)"',re.S)
# 通过正则表达式提取所有章节的url
all_url_match = contents_url_re.finditer(main_page_source)
all_url_list = []
# 拼接所有章节的url
for sub_url in all_url_match:
all_url_list.append(urljoin(url,sub_url.group("url")))
# print(urljoin(url,sub_url.group("url")))
# 事先定义好章节内容的正则表达式
contents_re = re.compile(r'<div id="chaptercontent" class="Readarea ReadAjax_content">(?P<content>.*?)请收藏本站',re.S)
# 通过变量控制爬取的章节数
count = 0
for url in all_url_list:
content_resp = requests.get(url, headers=headers)
# print(content_resp.text)
# 拿到章节内容页面的源码
page_source = content_resp.text
# 通过正则表达式提取章节内容
content_match = contents_re.search(page_source)
content = content_match.group("content")
# 章节内容中有换行符,需要替换成\r\n
content = re.sub(r"<br /><br />", "\r\n", content)
print(content)
count += 1
with open(f"第{count}章.txt", "w", encoding="utf-8") as f:
f.write(content)
# 控制爬取的章节数
if count == 10:
break
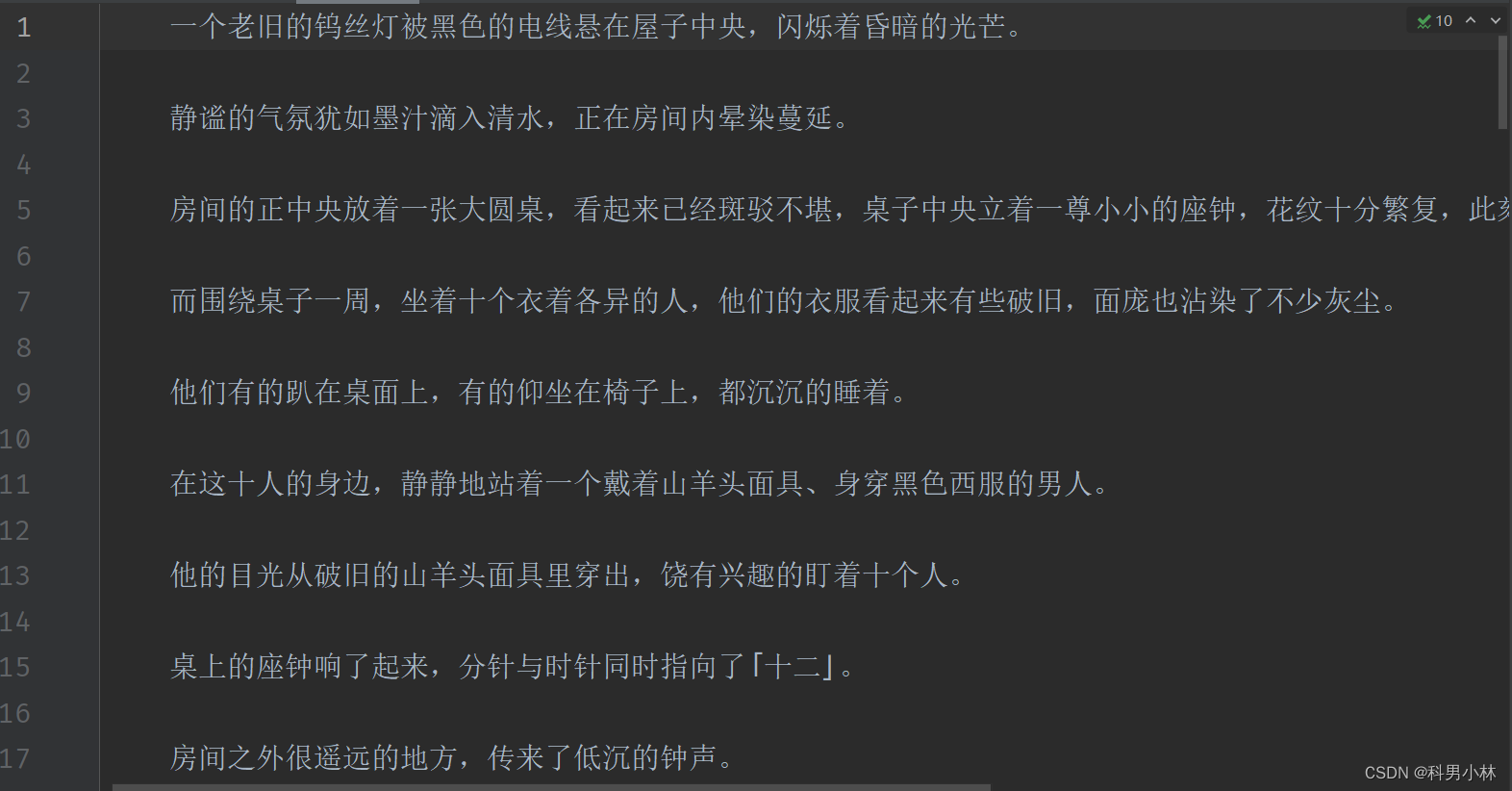
最终爬取到本地的效果:
3.总结
今天学习了正则表达式,通过正则表达式对网页进行解析拿到数据。练习爬笔趣阁的小说加深了对正则表达式的理解。
参考文章:
















 218
218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











