







1.Web请求全过程剖析
一个完整的Web 请求的详细过程,从用户在浏览器中输入 URL 地址说起,然后浏览器如何找到服务器地址的过程,并发起请求;分析请求在达反向代理服务器内部处理过程;最后到请求在服务器端处理完成后,浏览器渲染响应页面过程。
大致过程如下:

Web请求的工作原理可以简单地归纳为:
但是对于学习爬虫而言,我们并不需要了解客户端和服务器之间怎样建立的连接,我们关注的永远只是数据而已。要进行爬虫,我们只需要知道这个网站的网址和怎么拿到我们需要的数据。
下面以访问b站为例,我们访问:哔哩哔哩 (゜-゜)つロ 干杯~-bilibili这个网址,我们就能成功访问了b站的首页。
这个过程具体如下:
在访问b战的时候, 浏览器会把这一次请求发送到b战的服务器(b战的一台电脑), 由服务器接收到这个请求, 然后加载一些数据. 返回给浏览器, 再由浏览器进行显示. 听起来好像是个废话...但是这里蕴含着一个极为重要的东西在里面, 注意, b战的服务器返回给浏览器的不直接是页面, 而是页面源代码(由html, css, js组成). 由浏览器把页面源代码进行执行, 然后把执行之后的结果展示给用户.
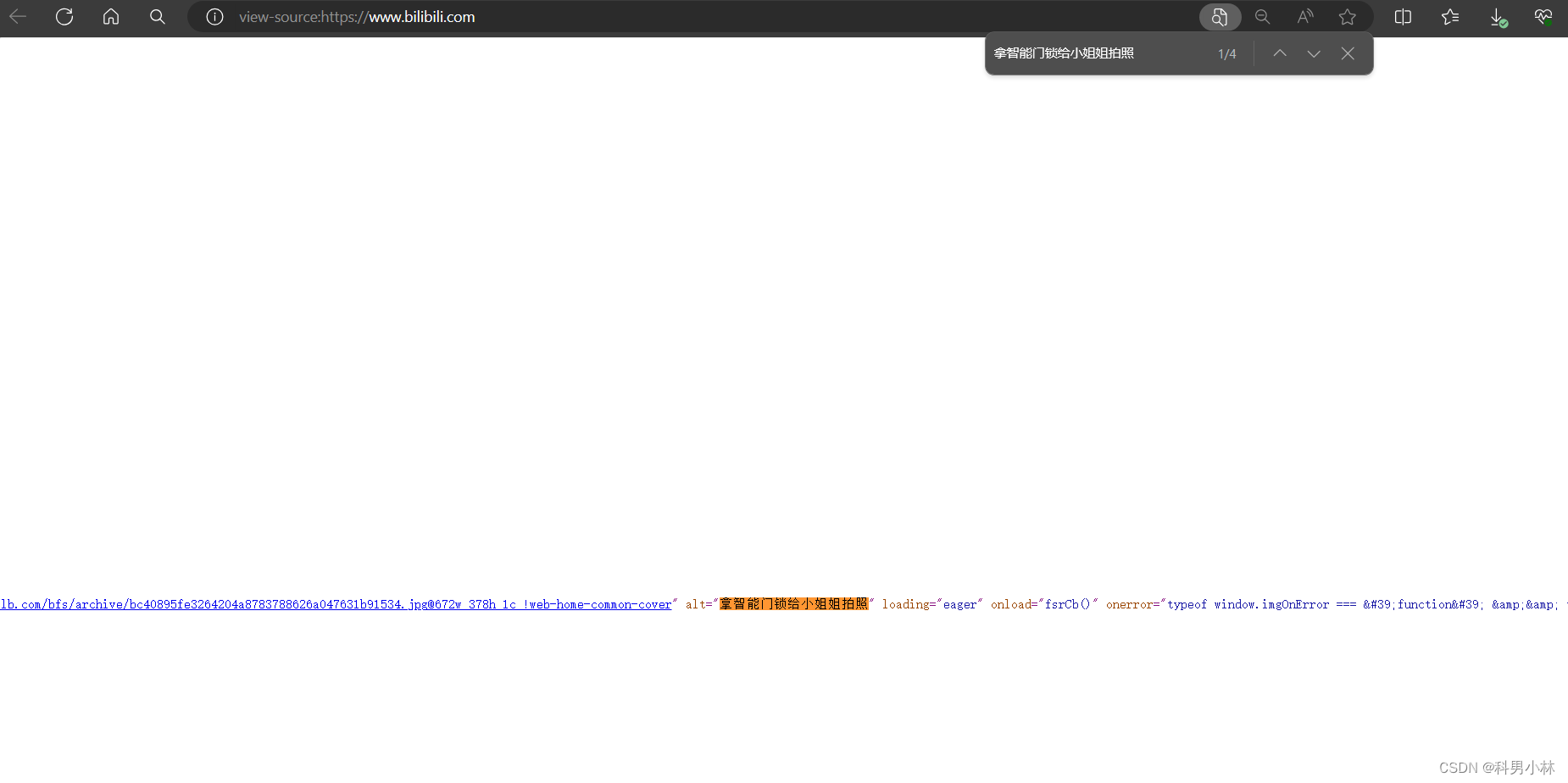
所以我们可以再页面源代码中找到我们需要的数据,点击右键查看页面源代码,利用全局搜索的功能进行搜索当前页面上存在的文字:
-
-
浏览器通过 DNS 把域名解析成对应的IP地址;
-
根据这个 IP 地址在互联网上找到对应的服务器,建立 Socket 连接;
-
客户端向服务器发送HTTP协议请求包,请求服务器里的资源文档;
-
在服务器端,实际上还有复杂的业务逻辑:服务器可能有多台,到底指定哪台服务器处理请求,这需要一个负载均衡设备来平均分配所有用户的请求;
-
还有请求的数据是存储在分布式缓存里还是一个静态文件中,或是在数据库里;
-
当数据返回浏览器时,浏览器解析数据发现还有一些静态资源(如:css,js或者图片)时又会发起另外的请求,而这些请求可能会在CDN上,那么CDN服务器又会处理这个用户的请求。
-
客户端与服务器断开。由客户端解释HTML文档,在客户端屏幕上渲染图形结果。
-
我们可以发现页面源代码中确实可以找到这个内容。但是是不是所有的数据都可以在页面源代码中找到呢?当然不是,回到b站首页,我们发现首页是可以下拉的,而新的内容在重新加载出来:
这时候我们再去页面源代码中去搜索页面上的内容,发现并没有结果
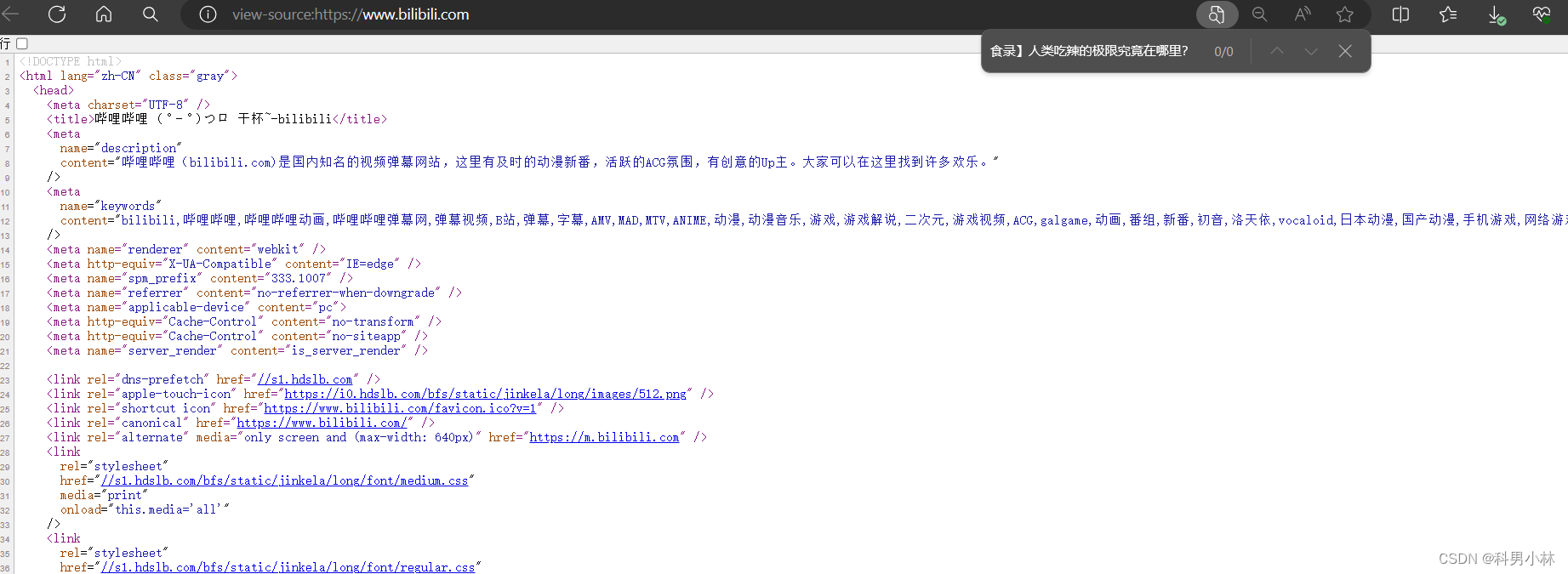
那如果我们想要拿到这种内容应该怎么办呢?这时候就要介绍两种页面渲染方式了:
-
服务器渲染, 你需要的数据直接在页面源代码里能搜到
这个最容易理解, 也是最简单的. 含义呢就是我们在请求到服务器的时候, 服务器直接把数据全部写入到html中, 我们浏览器就能直接拿到带有数据的html内容. 就像我们直接访问b站首页能够在页面源代码中直接找到数据, 由于数据是直接写在html中的, 所以我们能看到的数据都在页面源代码中能找的到的.
-
前端JS渲染, 你需要的数据在页面源代码里搜不到
这种就稍显麻烦了. 这种机制一般是第一次请求服务器返回一部分数据或者一堆HTML框架结构. 然后再次请求到真正保存数据的服务器, 由这个服务器返回数据, 最后在浏览器上对数据进行加载. 就像b站下拉首页那样不能在页面源代码中找到数据,这样做的好处是服务器那边能缓解压力. 而且分工明确. 比较容易维护.
2.浏览器工具的使用
对于一名爬虫工程师而言. 浏览器是最能直观的看到网页情况以及网页加载内容的地方. 我们可以按下F12来查看一些普通用户很少能使用到的工具.
其中, 最重要的Elements, Console, Sources, Network.
1.Elements
Elements是我们实时的网页内容情况, 注意, 很多兄弟尤其到了后期. 非常容易混淆Elements以及页面源代码之间的关系.
注意,
页面源代码是执行js脚本以及用户操作之前的服务器返回给我们最原始的内容
Elements中看到的内容是js脚本以及用户操作之后的当时的页面显示效果.
你可以理解为, 一个是老师批改之前的卷子, 一个是老师批改之后的卷子. 虽然都是卷子. 但是内容是不一样的. 而我们目前能够拿到的都是页面源代码. 也就是老师批改之前的样子. 这一点要格外注意.
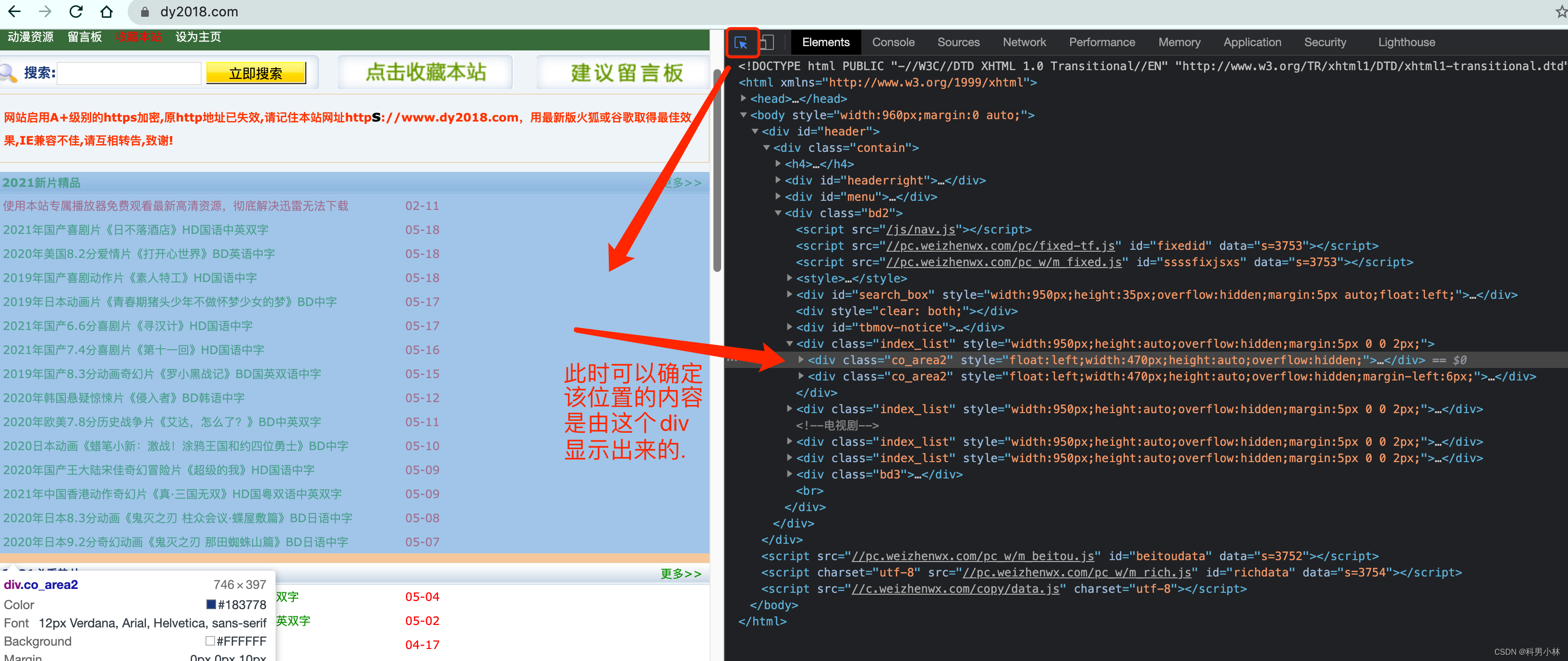
在Elements中我们可以使用左上角的小箭头.可以直观的看到浏览器中每一块位置对应的当前html状况. 还是很贴心的.
2. Console
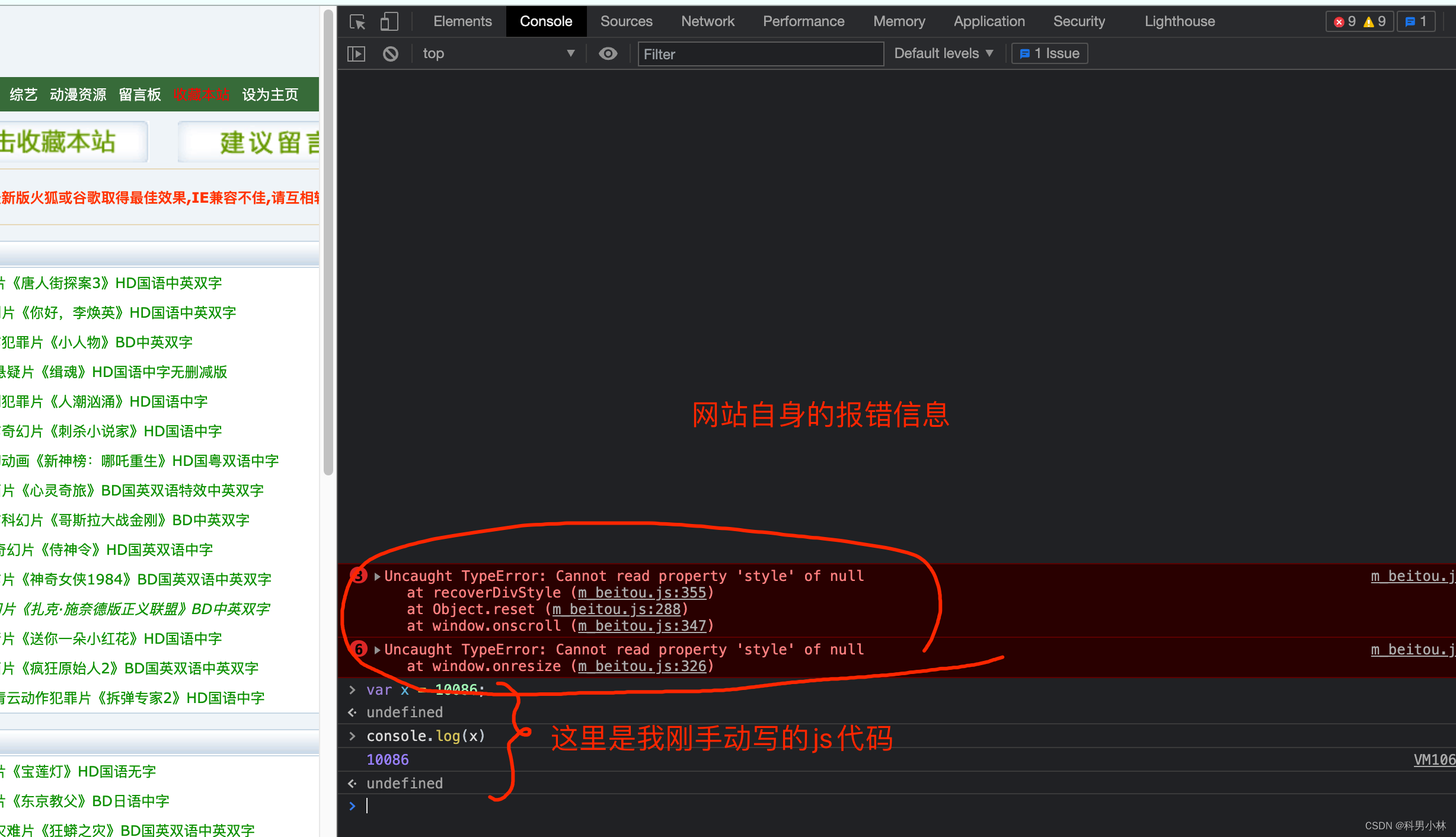
Console是用来查看程序员留下的一些打印内容, 以及日志内容的. 我们可以在这里输入一些js代码自动执行.
3.Source
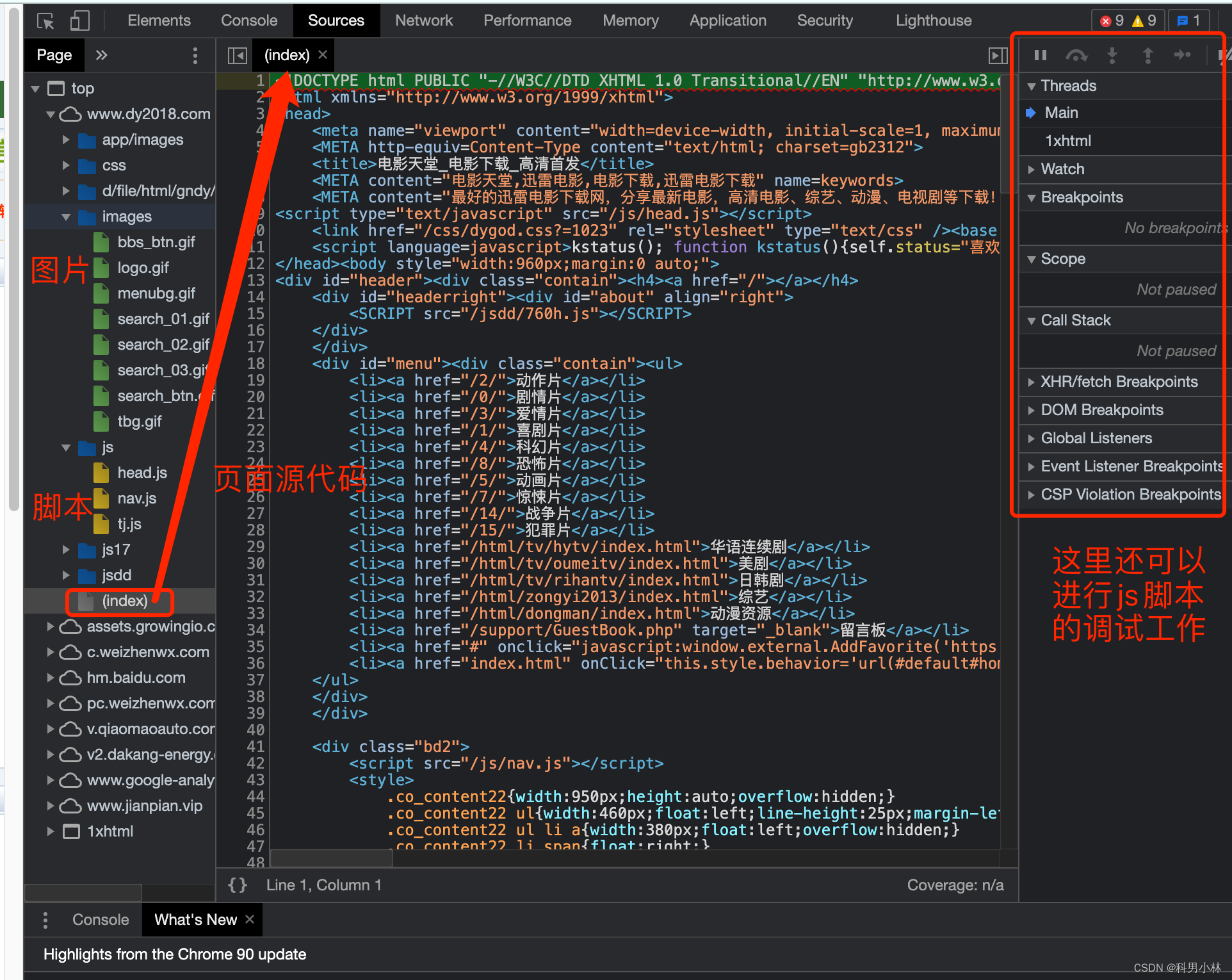
这里能看到该网页打开时加载的所有内容. 包括页面源代码. 脚本. 样式, 图片等等全部内容.
4.Network
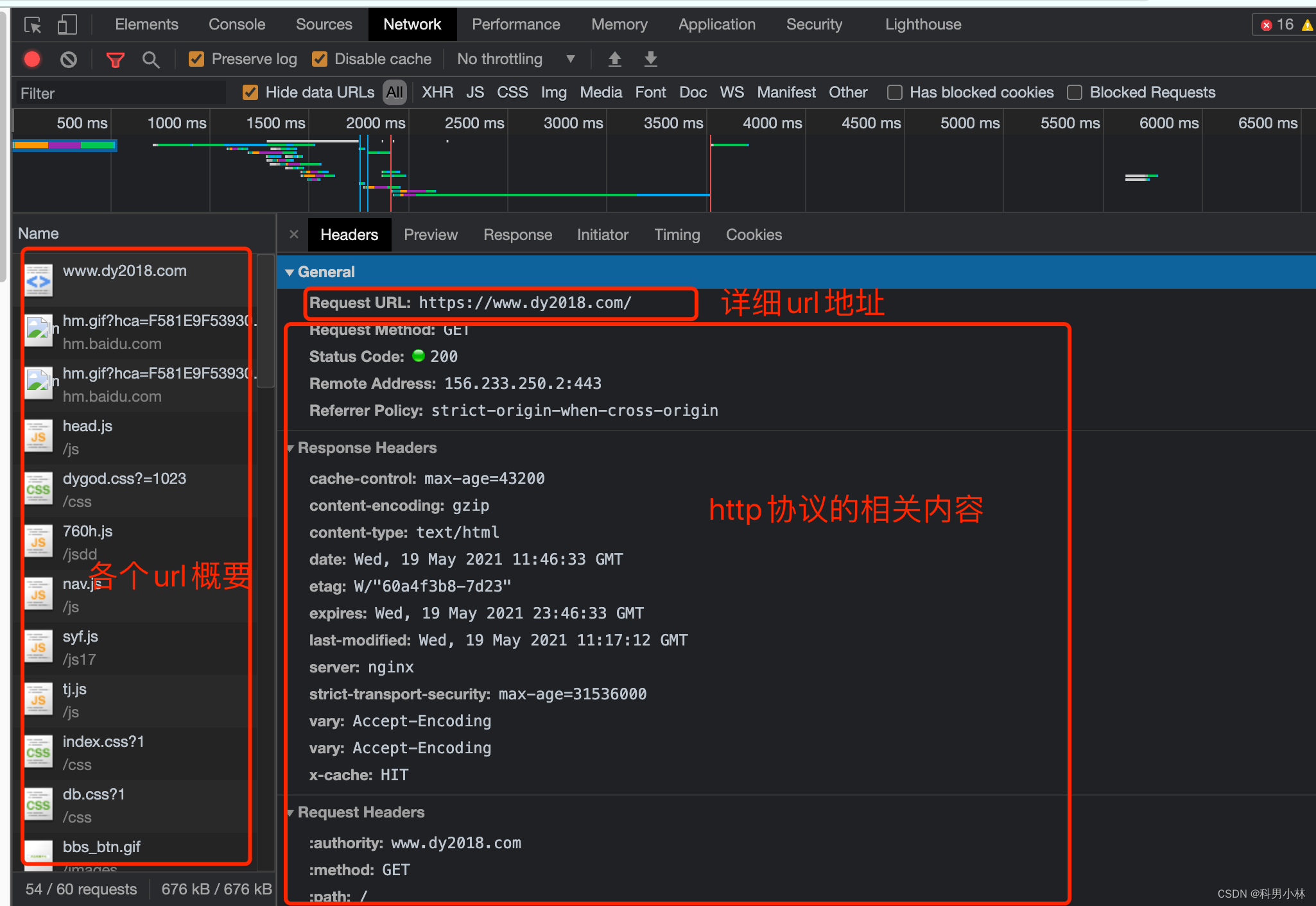
我们一般习惯称呼它为抓包工具. 在这里, 我们能看到当前网页加载的所有网路网络请求, 以及请求的详细内容. 这一点对我们爬虫来说至关重要.
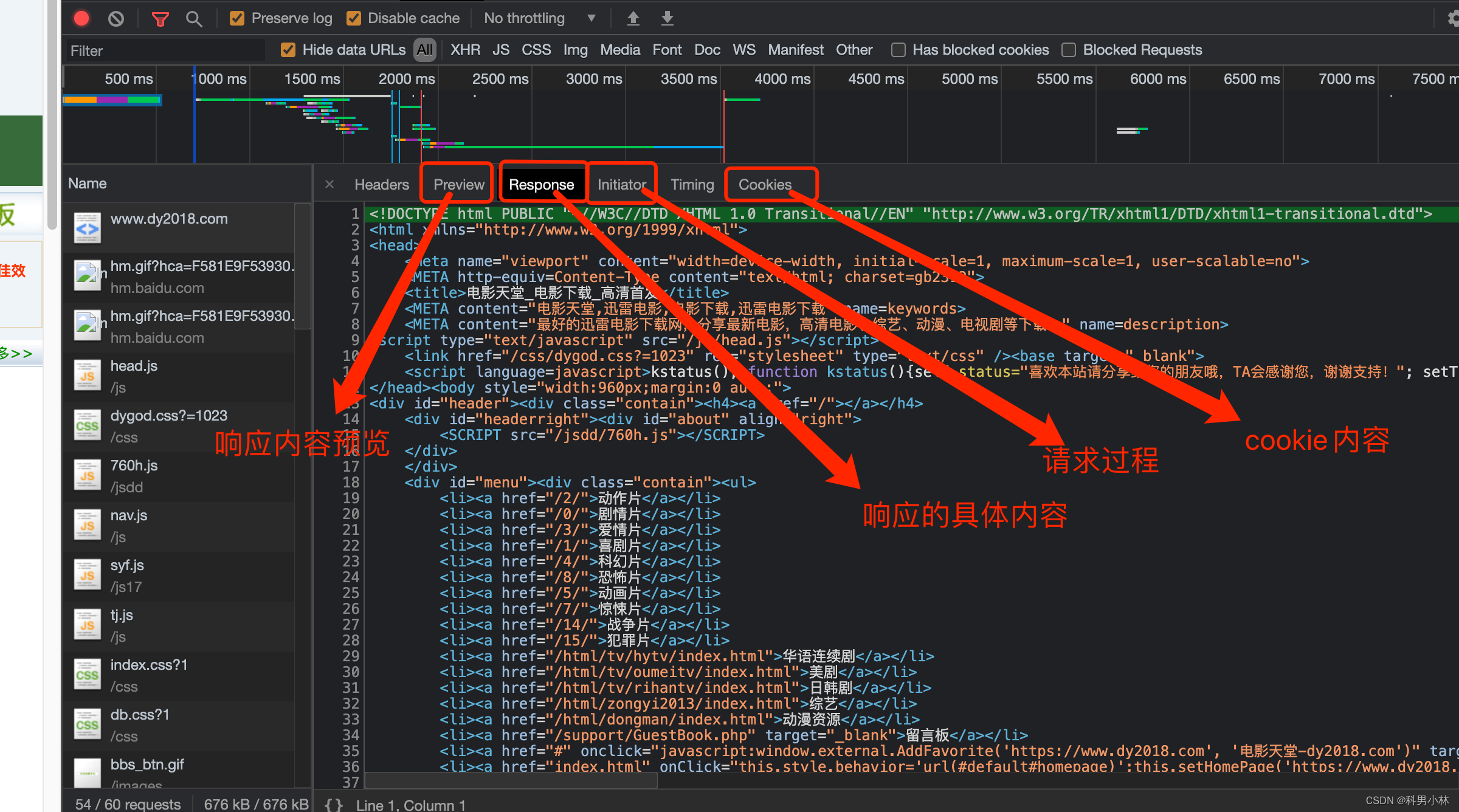
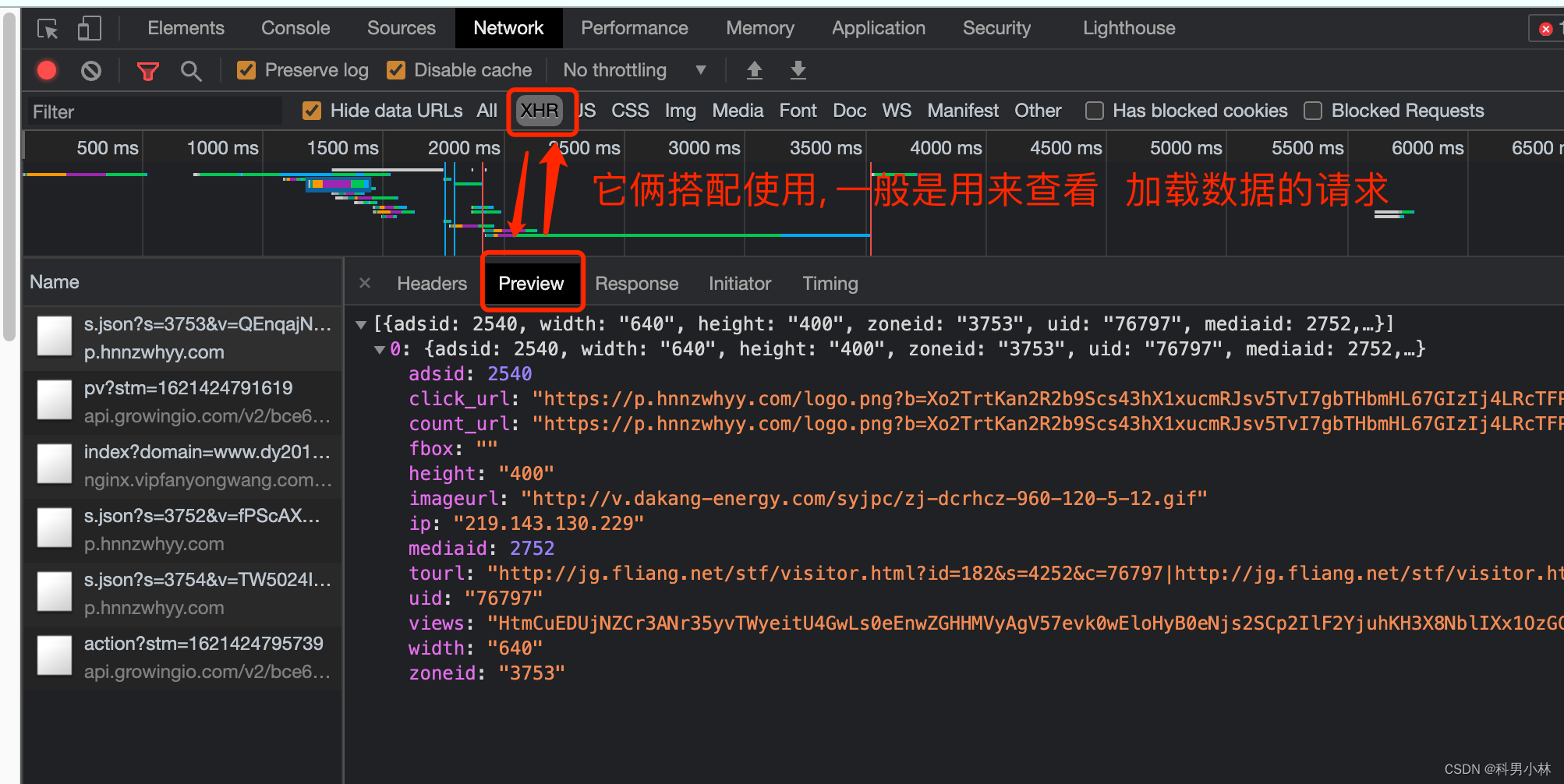
3.HTTP协议
协议: 就是两个计算机之间为了能够流畅的进行沟通而设置的一个协定. 常见的协议有SOAP协议, HTTP协议, SMTP协议等等.....
HTTP协议, Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议. 直白点儿, 就是浏览器和服务器之间的数据交互遵守的就是HTTP协议.
HTTP协议把一条消息分为三大块内容. 无论是请求还是响应都是三块内容
请求:
请求行 -> 请求方式(get/post) 请求url地址 协议 请求头 -> 放一些服务器要使用的附加信息 请求体 -> 一般放一些请求参数
响应:
状态行 -> 协议 状态码 响应头 -> 放一些客户端要使用的一些附加信息 响应体 -> 服务器返回的真正客户端要用的内容(HTML,json)等
请求头中最常见的一些重要内容(爬虫需要):
-
User-Agent : 请求载体的身份标识(用啥发送的请求)
-
Referer: 防盗链(这次请求是从哪个页面来的? 反爬会用到)
-
cookie: 本地字符串数据信息(用户登录信息, 反爬的token)
响应头中一些重要的内容:
-
cookie: 本地字符串数据信息(用户登录信息, 反爬的token)
-
各种神奇的莫名其妙的字符串(这个需要经验了, 一般都是token字样, 防止各种攻击和反爬)
请求方式:
GET: 显示提交
POST: 隐示提交
4.通过今天所学内容爬取b站评论
思路剖析:访问b站任意一个视频,查看页面源代码,在其中全局搜索任意一条评论,看页面源代码中是否存在,如果不存在,我们就需要进入抓包工具中寻找我们需要的数据来源。下面是具体的实操过程:
可以看到页面源代码中并不存在评论内容,接下来我们进入抓包工具去寻找数据,通过寻找最后在https://api.bilibili.com/x/v2/reply/wbi/main?oid=1703020604&type=1&mode=3&pagination_str=%7B%22offset%22:%22%22%7D&plat=1&seek_rpid=&web_location=1315875&w_rid=71c4f6d56259bbbda2b32feede7199e5&wts=1713625045这个网址上找到了我们需要的的评论内容
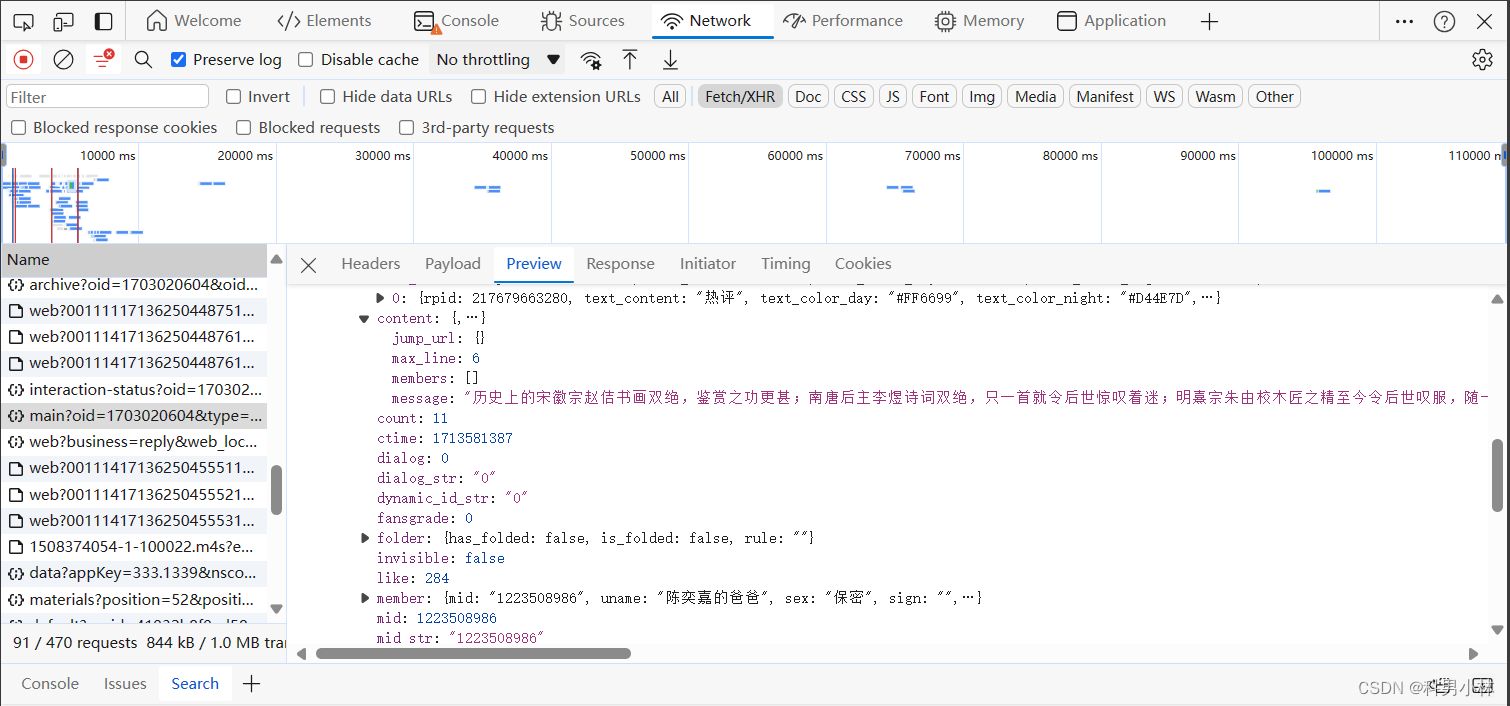
所以我们可以对这个网址进行访问查看它的数据类型
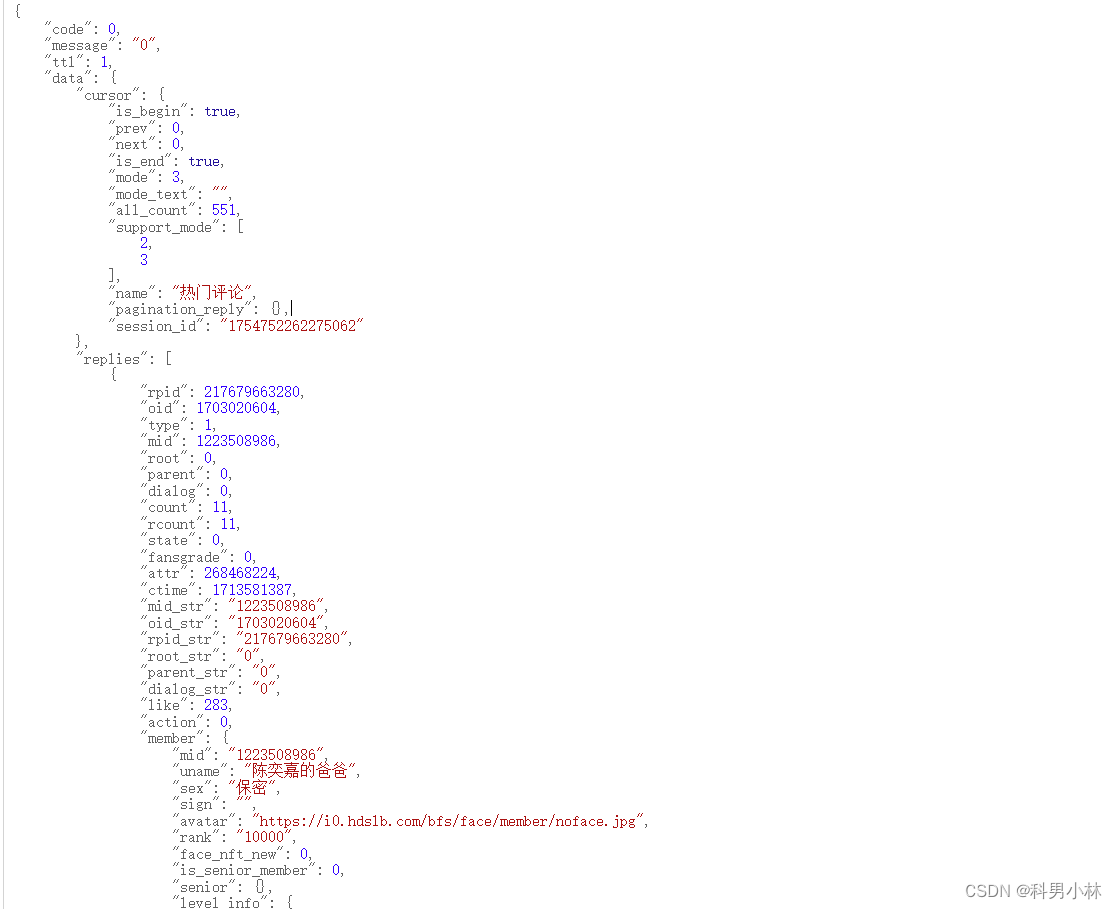
通过观察可以发现它是一个json,所以我们可以再python中对json进行解析拿到我们想要的数据。
以下内容在PyCharm中编写代码实现:
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/000000000 Safari/537.36"
}
url = "https://api.bilibili.com/x/v2/reply/wbi/main?oid=1703020604&type=1&mode=3&pagination_str=%7B%22offset%22:%22%22%7D&plat=1&seek_rpid=&web_location=1315875&w_rid=71c4f6d56259bbbda2b32feede7199e5&wts=1713625045"
resp = requests.get(url,headers=headers)
# print(resp.json())
# 将json格式的数据转换为字典格式
dic = resp.json()
# 拿到评论列表
comments = dic["data"]["replies"]
# print(comments)
for c in comments:
# 通过字典的方式拿到评论内容
comment = c["content"]["message"]
# 通过字典的方式拿到用户名
name = c["member"]["uname"]
# print(name,comment,sep="|")
# 写入文件到本地
with open("b站评论.txt", "a", encoding="utf-8") as f:
f.write(name + "|" + comment + "\n")以下是运行结果:
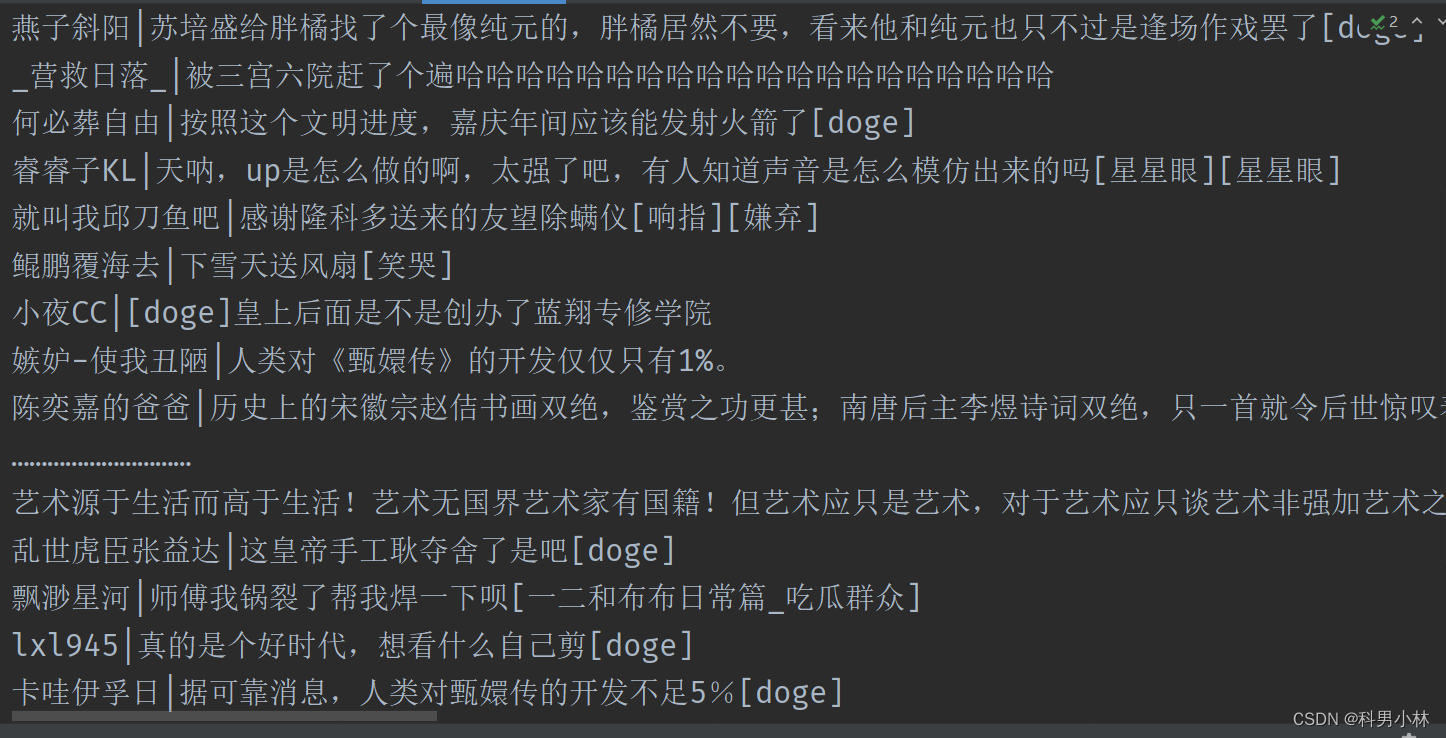
可以看到当前页面上的全部评论被拿到了本地。
5.总结
今天了解了Web请求的全过程,学习了浏览器的使用,了解了HTTP协议,并且通过对学习到了内容进行了实践,成功爬取了b站评论到本地。
参考文章:
















 1152
1152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











