







1.xpath解析
一、基本介绍
XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言。XPath 最初设计是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索。
二、常用规则
-
nodename :选取此节点的所有子节点
-
/:表示找当前节点的下一层级所有符合要求的节点
-
//:表示找当前节点下所有层级所有符合要求的节点
-
.:表示当前的节点
-
..: 选取当前节点的父节点
-
@: 选取属性
-
*: 匹配所有节点
三、在Python中的使用
示例HTML代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Title</title>
</head>
<body>
<div>
<p>真的吗<span>一个很厉害的人</span></p>
<ol>
<li id="10086" class="name">周大强</li>
<li id="10010" class="name">周芷若</li>
<li class="name">周杰伦</li>
<li class="name">蔡依林</li>
<ol>
<li>阿信</li>
<li>信</li>
<li>信不信</li>
</ol>
</ol>
</div>
<hr />
<ul>
<li><a href="http://www.baidu.com">百度</a></li>
<li><a href="http://www.google.com">谷歌</a></li>
<li><a href="http://www.sogou.com">搜狗</a></li>
</ul>
<ol>
<li><a href="feiji">飞机</a></li>
<li><a href="dapao">大炮</a></li>
<li><a href="huoche">火车</a></li>
</ol>
<div class="job">李嘉诚</div>
<div class="common">胡辣汤</div>
</body>
</html>在Python中使用xpath对HTML进行解析。
示例代码:
from lxml import etree
f = open("测试用html.html", "r", encoding="utf-8")
html = f.read()
f.close()
tree = etree.HTML(html)
# 通过标签名直接查找
test1 = tree.xpath('//ol/li/text()')
for i in test1:
print(i, end=" ") # 结果: 周大强 周芷若 周杰伦 蔡依林 阿信 信 信不信
print(end="\n")
# 通过添加属性查找
test2 = tree.xpath('//ol/li[@class="name"]/text()')
for i in test2:
print(i, end=" ") # 结果: 周大强 周芷若 周杰伦 蔡依林
print(end="\n")
# 写多个条件查找,用"|"分隔,两个表达式互不影响
test3 = tree.xpath('//ol/li[@class="name"]/text() | //a[@href="feiji"]/text()')
for i in test3:
print(i, end=" ") # 结果: 周大强 周芷若 周杰伦 蔡依林 飞机
print(end="\n")
# 多条件匹配or/and
test4 = tree.xpath('//ol/li[@class="name" or @class="age"]/text()')
for i in test4:
print(i, end=" ") # 结果: 周大强 周芷若 周杰伦 蔡依林
print(end="\n")
test5 = tree.xpath('//ol/li[@class="name" and @id="10086"]/text()')
for i in test5:
print(i, end=" ") # 结果: 周大强
print(end="\n")
# not:非
test6 = tree.xpath('//ol/li[not(@class="name")]/text()')
for i in test6:
print(i, end=" ") # 结果: 阿信 信 信不信
print(end="\n")
# 拿列表里的某个元素
# 第一种方式:直接在xpath中使用索引,但是需要注意索引从1开始
test7 = tree.xpath('//ol/li[1]/text()')
print(test7[0]) # 结果: 周大强
# 第二种方式:直接对列表进行索引
test8 = tree.xpath('ol/li[1]/text()')[0]
print(test8) # 结果: 周大强在爬虫中了解上述几种表达式完全足够了,更多xpath表达式的写法见:解析库xpath高级使用(超全) - 知乎 (zhihu.com)
注意:
-
使用xpath提取到的数据始终是一个列表,所以我们需要通过遍历的方式来拿到数据,所以我们可能常常会遇到Index out of Range的错误,这个时候我们需要返回检查表达式是否写正确,是否拿到正确的数量。
-
区别于bs4中的拿到标签里的文本,xpath只能拿到当前标签里的文本,而bs4是拿到标签里面的所有文本。
2.爬猪八戒网站
查看页面确定拿取的信息:
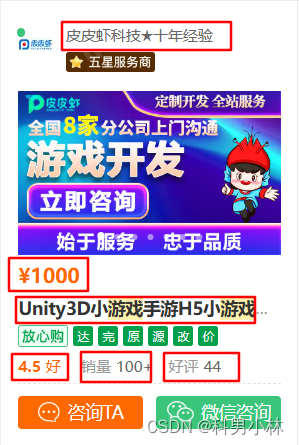
查看页面源代码看我们需要的信息是否存在:

显然信息在页面源代码中。那么我们开始进行爬虫:
首先我们通过class="search-result-list-service"这个属性定位到整个表,然后分别解析所有的数据。
完整代码:
import requests
from lxml import etree
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
}
url = "https://www.zbj.com/fw/?k=%E6%B8%B8%E6%88%8F%E5%BC%80%E5%8F%91"
response = requests.get(url, headers=header)
# print(response.text)
# 解析数据
tree = etree.HTML(response.text)
element_lst = tree.xpath('//div[@class="search-result-list-service"]/div')
# print(len(element_lst))
with open("猪八戒.csv", "w", encoding="utf-8") as f:
f.write("项目名称,价格,评价星级,好评数量,销量,公司名称\n")
for element in element_lst:
# 项目名称
title = element.xpath('.//a[@class="serve-name text-overflow-line-two oneline"]/text()')[0]
# 价格
price = element.xpath('.//div[@class="price"]/span/text()')[0]
# 评价星级
evaluate_lst = element.xpath('.//div[@class="fraction"]//span/text()')
evaluate = " ".join(evaluate_lst)
# 好评数量
feedback_score = element.xpath('.//div[@class="comment"]/span[2]/text()')[0]
# 销量
sales = element.xpath('.//div[@class="sale"]/span[2]/text()')[0]
# 公司名称
company_name = element.xpath('.//div[@class="shop-info text-overflow-line"]/text()')[0]
f.write(f"{title},{price},{evaluate},{feedback_score},{sales},{company_name}\n")运行结果:
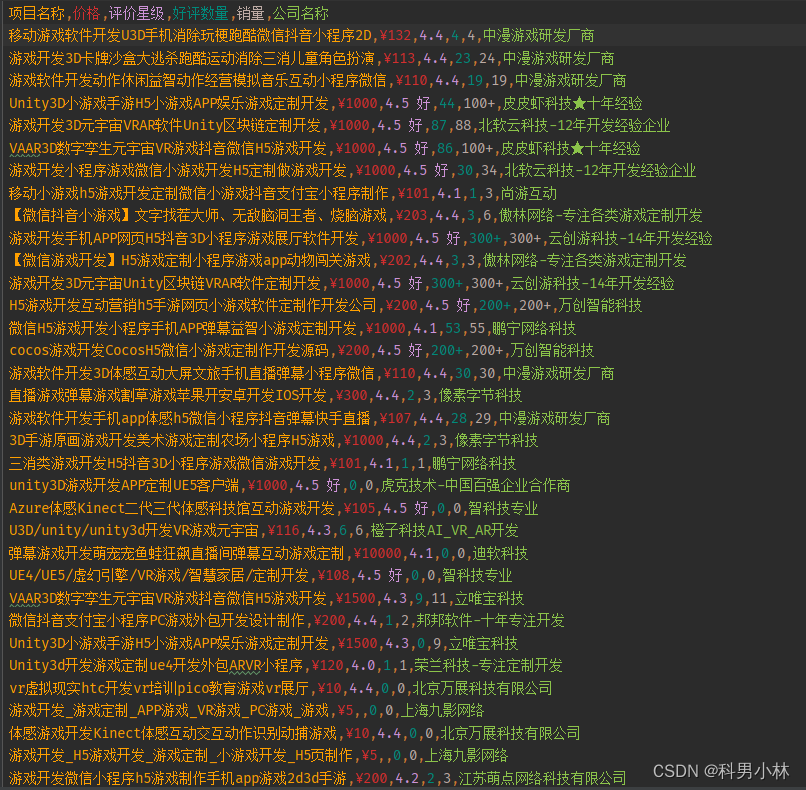
成功拿到了目标数据。
3.总结
今天学习了xpath解析网页,学习了如何写xpath表达式,使用xpath成功爬取了猪八戒网站上的信息。
















 867
867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











