







生成学习算法
判别学习算法(Discriminative learning algorithm)
直接学习
p(y|x)
,或者学习得到一个假设,直接输出0、1,
hθ(x)∈{0,1}
。例如Logistic回归。
该种模型只是通过一条分隔线把两种类别区分开。
生成学习算法(Generative learning algorithm)
根据特征和类别情况,对
p(x|y)
,
p(y)
进行建模。
在计算分析得到其概率后,根据贝叶斯公式(Bayes rule):
可推导出y在给定x的概率。
根据贝叶斯公式可以变化为:
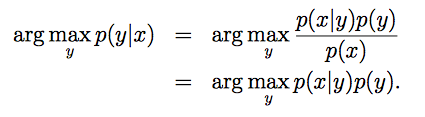
表达式含义为: p(y|x) 取最大值时的y值。
如果 p(y) 是均匀分布(每种类型的概率都相同),那么就等于: argmaxp(x|y) 。
高斯判别分析
GDA(Gaussian discriminative analysis)是我们要学习的第一个生成学习算法。
GDA的两个前提:
- 假设输入特征x∈Rn,并且是连续值
- p(x|y) 满足多维正态分布(multivariate normal distribution)
多维正态分布
期望向量[均值向量](mean vector),
μ∈ℝn
;
协方差矩阵(covariance matrix),
∑∈ℝn∗n
,
∑=[(x−μ)(x−μ)T]
,
∑>0
,矩阵对称并且半正定(symmetric and positive semi-definite)。
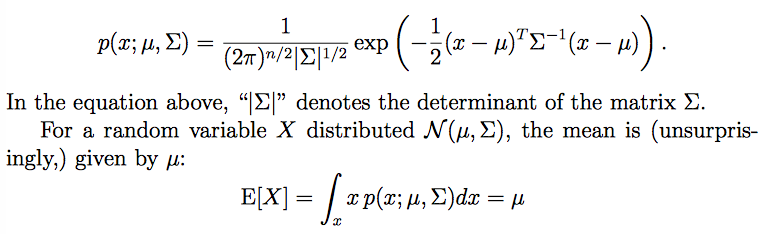
协方差为:
Cov(X)=∑
。
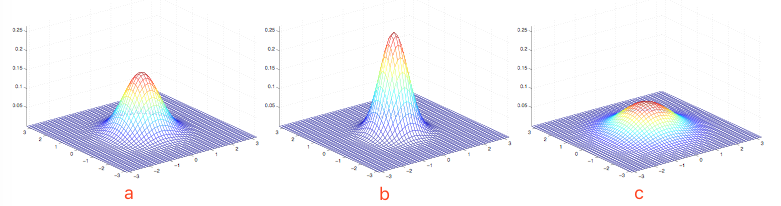
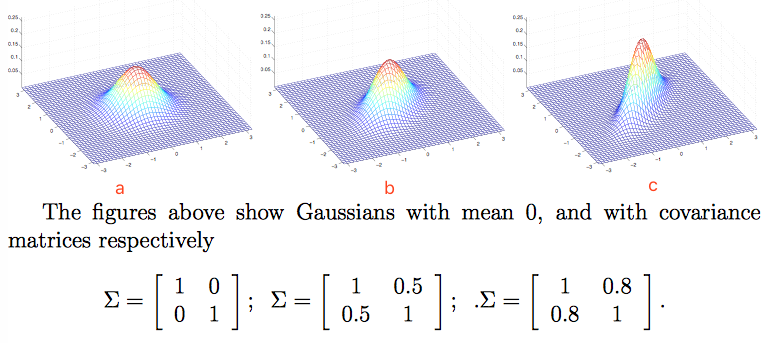
a.均值为0,协方差矩阵为单位矩阵
I
(2*2),成为标准正态分布;
b.均值为0,协方差矩阵
c.均值为0,协方差矩阵
2I
(2*2);

GDA模型

参数ϕ, ∑,
μ0,μ1
的对数似然性:
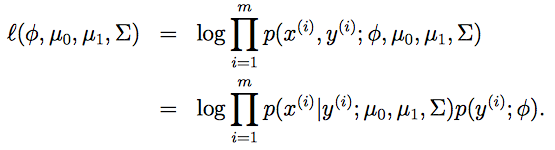
其中考虑的是
p(x(i),y(i))
,联合似然(Joint likelihood);而在logistic回归中考虑的是
p(y(i)|x(i))
,条件似然(Conditional likelihood)。
求出极大似然估计为:

μ0,μ1
的含义是:
分母是对应标签(0/1)的样本数,分子是对应标签(0/1)的
x(i)
的和;整体含义为遍历整个集合,求对应标签(0/1)的
x
的均值。
这个算法工作起来就是这样的:

讨论:GDA和Logistic回归
GDA模型和logistic回归有一个很有趣的关系。
如果把

其中,θ是ϕ, ∑,
μ0,μ1
的函数,这就很像是
p(y=1|x)
的Logistic回归。
讨论:哪个更好?
如果p(x|y)是一个多维的高斯分布,那么p(y|x)必然能推出一个logistic函数;反之则不能。这是因为GDA做了更强的假设,(x| y)服从高斯分布。
如果数据服从或大致服从高斯分布,那么GDA的性能优于Logistic回归;如果你不确定数据的分布情况,那么Logistic回归表现会更好。
GDA因为是强假设,所以对于建模会使用更少的数据;Logistic由于假设相对较弱,所以有着不错的适应性(鲁棒性),但建模时使用更多的数据。
鲁棒性:
p(x|y=1)∼ExpFamily(η1)
p(x|y=0)∼ExpFamily(η0)
能推出
p(y=1|x)
为Logistic回归。
朴素贝叶斯
在GDA模型中,特征向量x是连续的实数向量。如果x是离散值,我们需要不同的学习算法。
举例讲解:垃圾邮件分类(文本分类问题)
首先要输入一封邮件,然后与词典进行比对,如果出现了该词,则设xi=1,否则xi=0,例如:
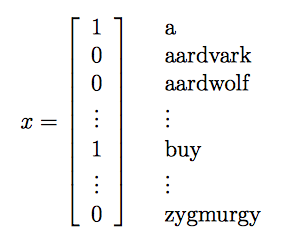
我们要对
p(x|y)
建模,如果使用判别模型,那么在词典包含很多词的情况下(极端50000词),
x∈{0,1}50000
,则我们需要(
250000−1
)维的参数向量,这显然是不可行的。
所以我们要用强假设限定
p(x|y)
,假设给定y的时候,
x′is
是条件独立(conditionally independent)的,这就是朴素贝叶斯假设(Naive Bayes assumption),并且这种解决算法被称为朴素贝叶斯分类器(Naive Bayes classifier)。
根据链式法则和朴素贝叶斯假设得:
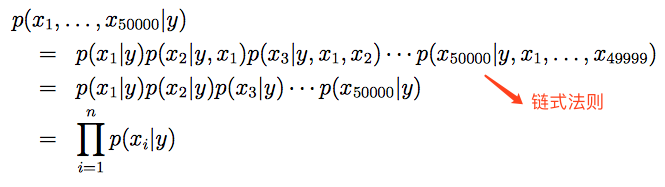
数据的联合似然性(joint likelihood)为:
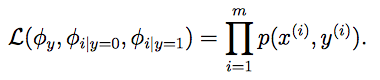
φi|y=1=p(xi=1|y=1)
,
φi|y=0=p(xi=1|y=1)
,
φy=p(y=1)
。
得到极大似然估计:
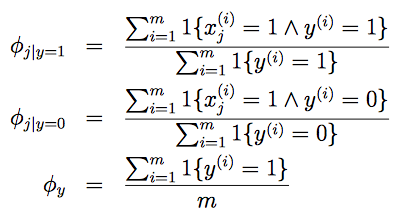
解释
φi|y=1
项:分子,遍历训练样本在标签y=1邮件中词语
xj
出现的次数之和;分母,训练样本中标签y=1邮件的总数;总得来说,在垃圾邮件中见到
xj
词的概率。
m就是训练样本的数量,m封标记着“垃圾“(y=1)和“正常“(y=0)的邮件。
完成上述参数的设置,就可以得到:

存在问题:
假设新邮件出现了一个以前邮件从来没有出现的词,模型会认为这个词在任何一封邮件出现的概率为0,这在统计学中是不科学的。
拉普拉斯平滑(Laplace smoothing)
我们使用Laplace平滑来避免朴素贝叶斯出现上述问题。
一般式:
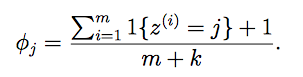
朴素贝叶斯问题,通过Laplace平滑:
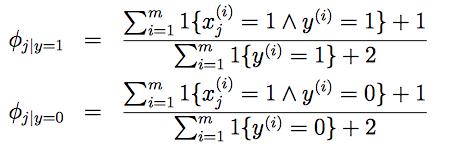
问题解决。















 9916
9916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









