







 这篇博客介绍了生成学习算法中的高斯判别分析(GDA),包括其模型和与Logistic模型的关系。通过例子展示了GDA如何处理连续特征值的分类问题,并探讨了GDA的后验分布与逻辑分布的联系。
这篇博客介绍了生成学习算法中的高斯判别分析(GDA),包括其模型和与Logistic模型的关系。通过例子展示了GDA如何处理连续特征值的分类问题,并探讨了GDA的后验分布与逻辑分布的联系。
《Andrew Ng 机器学习笔记》这一系列文章文章是我再观看Andrew Ng的Stanford公开课之后自己整理的一些笔记,除了整理出课件中的主要知识点,另外还有一些自己对课件内容的理解。同时也参考了很多优秀博文,希望大家共同讨论,共同进步。
网易公开课地址:http://open.163.com/special/opencourse/machinelearning.html
本篇博文涉及课程五:生成学习算法
本课主要内容有:
(1)生成学习算法
(2)高斯判别分析(GDA)
生成学习算法
在线性回归和Logistic回归这些学习算法中我们探讨的模型都是p(y|x;θ),即给定x的情况探讨y的条件概率分布。
例如二分类问题,我们之前的都是在解空间中寻找一条直线,从而把两种类别的样例分开,对于新的样例,只要判断在直线的哪一侧即可;这种直接对问题求解的方法可以称为判别学习方法。
例如二分类问题,我们之前的都是在解空间中寻找一条直线,从而把两种类别的样例分开,对于新的样例,只要判断在直线的哪一侧即可;这种直接对问题求解的方法可以称为判别学习方法。
而生成学习算法则是先对两个类别分别进行建模,然后用新的样例去匹配两个模板,匹配度较高的作为新样例的类别。
也就是说,判别学习方法是直接对p(y|x)进行建模或者直接学习输入空间到输出空间的映射关系,其中,x是某类样例的特征,y是某类样例的分类标记。
而生成学习算法是对p(x|y)(条件概率)和p(y)(先验概率)进行建模,然后按照贝叶斯法则求出后验概率p(y|x):
而生成学习算法是对p(x|y)(条件概率)和p(y)(先验概率)进行建模,然后按照贝叶斯法则求出后验概率p(y|x):
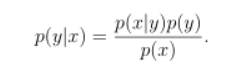
使得后验概率最大的类别y即是新样例的预测分类:
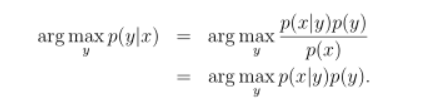
事情还没有发生,要求这件事情发生的可能性的大小,是先验概率。
事情已经发生,要求这件事情发生的原因是由某个因素引起的可能性的大小,是后验概率。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1846
1846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









