







文章目录
1. in和exists的区别
in:确定给定的值是否与子查询或列表中的值相匹配,in在查询的时候,首先查询子查询的表,然后和外表做一个笛卡尔积,再按照条件进行筛选。
exist:指定一个子查询,检测行的存在。遍历循环外表,然后看外表中的记录有没有和内表的数据一样的。匹配上就将结果放入结果集中。
not exist比not in快。
子查询的表很大时,用exist。
表user:
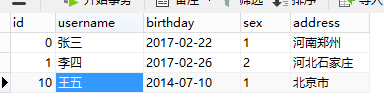
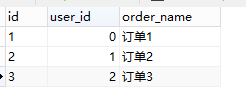
表order:
SELECT
`user`.*
FROM
`user`
WHERE
EXISTS (
SELECT
`order`.user_id
FROM
`order`
WHERE
`user`.id = `order`.user_id
)
2. count()
count(列名),count(*),count(1)
count(*),count(1)统计的是行数。
count()是SQL92定义的标准统计行数的语法,所以用count()。所以会有一些优化,比如在没有where和group by时,MyISAM引擎会直接把表的总行数单独记录下来供count(*)查询,
3. 常用日期函数
datediff(expr1, expr2)返回两个日期相减(expr1 − expr2 )相差的天数:datediff('2019-01-14 14:32:59','2019-01-02')--> 12。time_diff(time1, time2)返回时间差,格式为hh:mm:ss。可利用hour返回时间差的小时值。date_add(date,INTERVAL expr type)date参数是合法的日期表达式。expr参数是您希望添加的时间间隔。type参数是增加的类型,比如day, hour, week:date_add('2008-12-29 16:25:46.635', interval 2 day)--> 2008-12-31 16:25:46.635。date_sub(date,INTERVAL expr type)是相减。date_format(date,format)函数用于以不同的格式显示日期/时间数据:date_format('2021-09-07', '%Y%m%d')--> 20210907
4. 常用字符串函数
-
concat(str1, str2, ……):concat('My', 'S', 'ql')--> MySql -
concat_ws(sep, str1, str2, ……):concat_ws('-', '2019', '09', '07')--> ‘2019-09-07’ -
substr(str, pos, n)从源字符串str中的指定位置pos开始取一个长度为n的字串并返回,如果n省略,则一直到末尾,如果pos为负值表示从源字符串的尾部开始取起:substr('hello world',5)--> ‘o world’;substr('hello world',5,3)--> ‘o w’;substr('a@b.com', -6, 4)--> @b.c -
left(str, len)返回最左边的len长度的子串:left('chinaitsoft',5)--> china。同理,right(str, len)返回最右边的len长度的子串 -
reverse(str)将字符串str反转后返回:reverse('abcdef')--> fedcba -
repeat(str, count)将字符串str重复count次后返回:repeat('MySQL',3)--> MySQLMySQLMySQL -
replace(str, from_str, to_str)在源字符串str中查找所有的子串from_str(大小写敏感),找到后使用替代字符串to_str替换它,返回替换后的字符串:replace('www.mysql.com','w','Ww')--> WwWwWw.mysql.com -
locate(substr, str)函数返回substr在str中出现的位置,如果包含,则返回 >0 的数,否则返回0。可用于hive on的模糊查询,即on locate(a.str, b.str) > 0
5. 常用计算和统计函数
format(x,y)函数,功能是将一个数字x,保留y位小数,并且整数部分用逗号分隔千分位,小数部分进行四舍五入。format(12345678.12345, 4)--> 12, 345, 678.1235。会变成字符串abs(x)求一个数的绝对值:abs(-3)--> 3sqrt(x)求一个数的平方根:sqrt(9)--> 3mod(x,y)x除数,y被除数。结果是余数:mod(10, 3)--> 1ceil(x)进一取整:ceil(2.3)--> 3floor(x)舍一取整:floor(2.3)--> 2。可结合rand(),生成随机整数。比如floor(rand()*10),可生成0-9内的随机整数。rand()生成随机数:rand()--> 0.948428958298351power(x, y)幂运算:power(2, 3)--> 8sign()返回当前结果的符号,如果是负数,返回-1;如果是0,返回0;如果是正数,返回1。
6. 其它函数
cast(字段名 as 类型)。常用的类型有:CHAR(字符型),DATE(日期型),SIGNED(int)split('abcdef', 'e')--> [abcd, f]。split('abcdef', 'e')[0]--> ‘abcd’coalesce(str1,……,strn):返回第一个不是null的值,如果全为null,就返回null- hive没有
ifnull()函数,可用nvl(expr1, expr2),如果expr1为NULL,返回值为 expr2,否则返回expr1。适用于数字型、字符型和日期型,但是 expr1和expr2的数据类型必须为同类型。
7. 数据倾斜?
原因:
本质上是数据分布不平衡,大量的数据分配到了一个节点,导致整个计算过程过慢。
常见的情况有几种:
- 业务数据本身的特性。比如有些城市的订单要比其它城市多很多
- 某些sql语句会导致倾斜。比如
count(distinct),group by,join on等 - 建表时考虑不全。
解决:
-
设置常用参数。
set hive.map.aggr = true:开启map端combiner聚合功能
hive.groupby.skewindata=true:开启负载均衡。 -
SQL语句调整。
(1)少用count distinct,用sum…group by代替
改写前:
select a, count(distinct b) from table group by a;
改写后:
select a, sum(1) from (select a , b from table group by a, b) as t group by a;
(2)不同数据类型关联产生数据倾斜。利用cast(字段 as string),将关联数据转换为同一种类型。
用户表中user_id字段为int,log表中user_id字段既有string类型也有int类型
select * from user as a left outer join log as b on a.usr_id = cast(b.user_id as string)
(3)大小表join时,小表key集中。可以使用map join让小维度表先进内存,即在map端完成join,不经过reduce。
map端的操作key为两张表on条件的列,value为select列+表tag
将同一key分配到reduce端,然后根据表tag进行笛卡尔积join
B表有30亿行记录,A表只有100行记录,而且B表中数据倾斜特别严重,有一个key上有15亿行记录。
select /*+ mapjoin(A)*/ f.a, f.b from A as t join B as f on (f.a=t.a and f.ftime=20110802)
(4)如果两个表连接时,使用的连接条件有很多空值,会造成有 null 关联的那个分区数据特别多。
方法一:空值不参与连接,在连接条件中增加过滤,去除空值
select * from log a
join users b
on a.user_id is not null
and a.user_id = b.user_id
方法二:赋与空值新的key值,且由于是无效数据无法关联上,因此不会出现在结果表中。
select *
from log a
left outer join users b
on case when a.user_id is null then concat(‘hive’,rand() ) else a.user_id end = b.user_id;
Hadoop?
Hadoop是存储并分析海量数据的框架,它的核心部件是HDFS与MapReduce。
HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
HDFS是一个分布式文件系统,通过存放文件 元数据信息的服务器Namenode( 接收客户端的请求;管理DataNode上的数据块)和实际存放数据的服务器Datanode(保存数据块;负责客户端对数据块的IO请求,即输入输出请求),对数据进行分布式储存和读取。
MapReduce是一个面向大数据的计算框架,主要由三个阶段构成:Map、shuffle、Reduce。map是映射,将原始数据映射为键值对;reduce是合并,将具有相同key值的value处理后再输出新的键值对作为最终结果。将Map输出进行进一步整理并交给Reduce的过程就是Shuffle
Spark?
Spark提供了多种高级工具,如: Spark SQL + DataFrame应用于查询、Streaming应用于流式计算、 MLlib/ML应用于机器学习、Graphx应用于图处理。但在数据分析工作上,一般只会用到Spark SQL和MLlib/ML。
在计算速度上,Spark SQL要比Hive SQL快的多。
原因:spark基于内存计算,而hive基于磁盘计算,内存的读取速度远超过磁盘读取速度
在接口上,Spark要丰富的多。
8. HIVE?
- 不支持笛卡尔乘积。
select * from a join b on 1=1
-
不等值连接?
hive2.2版本之后支持。
如果连接条件是不等于,可以用左连接+等于,然后where 右表为null。 -
hive不支持in加子查询,可用exists。 原因是hive不支持笛卡尔乘积,而in加子查询本质上是先进行笛卡尔乘积,再进行筛选。
-
hive与MySQL的区别?
(1)查询语言不同:hive用的hql语句查询,MySQL用的是sql语句查询。hql不支持in加子查询。sql有复杂的索引。
(2)数据存储位置不同:hive是把数据存储在hdfs上,而mysql数据是存储在自己的系统中
(3)数据规模:hive存储的数据量超级大,而mysql只是存储一些少量的业务数据
(4)执行延迟:hive执行延迟高,MySQL执行延迟低
(5)数据更新:hive不支持数据更新,只可以读,不可以写,而sql支持数据更新 -
order by和sort by?
order by是全局排序,sort by是部分排序,即在每一个reduce节点内进行排序。
sort by常和distribute by一起使用,和group by类似,但是它不需要配合聚合函数使用,也就不影响原数据的函数,这点和开窗函数有点类似。
被distribute by设定的字段为KEY,数据会被HASH分发到不同的reducer机器上,然后sort by会对同一个reducer机器上的每组数据进行局部排序。 -
行列转换?
行转列:max(case when then else 0 end)
列转行:lateral view explode(split(str, ',')) lv as col1
9. MySQL?
- 索引。
优点:
(1)索引可以大大提高MySQL的查询速度。
(2)理论上可以给任意字段设置索引,但往往要确保该索引是应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件)。
缺点:
(1)创建索引需要时间和空间,所以当数据量不大时,不用创建索引。
(2)当对表中的数据进行增加、删除、修改时,索引也需要动态的维护,降低了数据的维护速度,所以对经常更新的表就避免对其进行过多的索引
(3)在一同值少的列上(字段上)不要建立索引,比如在学生表的"性别"字段上只有男,女两个不同值。相反的,在一个字段上不同值较多时可建立索引。
创建方式:索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引,单列索引又包含普通索引(纯粹为了查询数据更快一点),唯一索引(索引列中的值必须是唯一的,但是允许为空值),主键索引(特殊的唯一索引,不允许有空值)。组合索引,即一个索引包含多个列。
(1)普通索引:
直接创建:CREATE INDEX indexName ON table_name (column_name)
修改表结构(添加索引):ALTER table tableName ADD INDEX indexName(columnName)
创建表的时候指定索引:
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX [indexName] (username(length))
);
删除索引:DROP INDEX [indexName] ON mytable
(2)唯一索引:
直接创建:CREATE UNIQUE INDEX indexName ON mytable(username(length))
修改表结构:ALTER table mytable ADD UNIQUE [indexName] (username(length))
同样也可以在创建表的时候指定:
- 调优:
(1)考虑在 where 及 order by 涉及的列上建立索引
(2)应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描。可以先用ifnull(字段,0),将null转化为0
(3)应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描
(4)应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描。可使用union all来代替
(5)对于连续的数值,能用 between 就不要用 in 。用 exists 代替 in 是一个好的选择,select num from a where num in(select num from b)可替换为select num from a where exists(select 1 from b where num=a.num)
(6)应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:select id from t where num/2=100
(7)应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:select id from t where substring(name,1,3)='abc'应改为select id from t where name like 'abc%'
10. 列、行互转
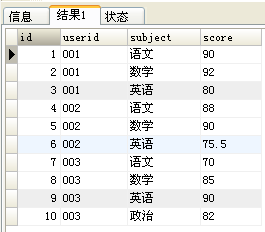
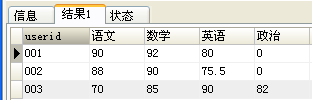
要想从上图转化为下图,可使用:
SELECT userid,
SUM(CASE `subject` WHEN '语文' THEN score ELSE 0 END) as '语文',
SUM(CASE `subject` WHEN '数学' THEN score ELSE 0 END) as '数学',
SUM(CASE `subject` WHEN '英语' THEN score ELSE 0 END) as '英语',
SUM(CASE `subject` WHEN '政治' THEN score ELSE 0 END) as '政治'
FROM tb_score
GROUP BY userid
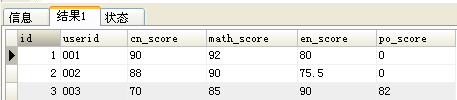
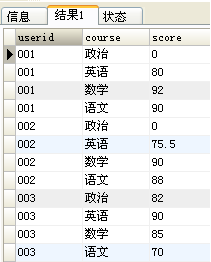
要想从上表转化为下表,可使用:
SELECT userid,'语文' AS course,cn_score AS score FROM tb_score1
UNION ALL
SELECT userid,'数学' AS course,math_score AS score FROM tb_score1
UNION ALL
SELECT userid,'英语' AS course,en_score AS score FROM tb_score1
UNION ALL
SELECT userid,'政治' AS course,po_score AS score FROM tb_score1
ORDER BY userid
11. Union和Union All的区别
1.对重复结果的处理:UNION会去掉重复记录,UNION ALL不会;
2.对排序的处理:UNION会排序,UNION ALL只是简单地将两个结果集合并;
3.效率方面的区别:因为UNION 会做去重和排序处理,因此效率比UNION ALL慢很多;
12. with rollup的用法
在group分组字段的基础上再进行统计数据
案例一:

-
使用不带聚合函数的结果:

上图所测部分箭头所指右侧部分的数据是对应的,右侧部分方框中的数据是对上面该组数据的汇总,由于没有使用聚合函数,所以用NULL表示,最后一个是对所测所有查询结果的汇总。 -
使用聚合函数的结果:

上图所测部分箭头所指右侧部分的数据是对应的,右侧部分方框中的数据是对上面该组数据的汇总,由于使用了聚合函数SUM,所以对其上面每个分组求和,最后一个是对所测所有查询结果的汇总。
案例二:

-
在每一个最小分组(year/country/product)后会给出一个以year/country分组的数据汇总,该数据行中的product会被设置成NULL。(第3、6、9、12、16行)
-
在每个year/country小组后会给出一个以year分组的数据汇总,该数据行中country/product列都会被设置为NULL。(第10、17行)
-
最后一行是对所有数据的汇总,该数据行中year/country/product都被设置为NULL。
注意:
- 只能在SELECT列表或HAVING子句中使用这些NULL,不能在JOIN条件或者WHERE子句中通过使用NULL来筛选结果集。
- 在使用ROLLUP时,不能使用ORDER BY子句对结果进行排序,即ROLLUP与ORDER BY在MySQL中是互相排斥的。可以利用子表进行筛选。















 6381
6381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









