






目录
实验目的
熟悉和掌握启发式搜索的定义、估价函数和算法过程
实验要求
熟练掌握A*算法的基本原理。分析不同启发式函数对问题求解的提升效果。
- 实现A*算法的求解,要求设计两种不同的估价函数:设置相同的初始状态和目标状态,针对不同估价函数,求得问题的届,比较它们对搜索算法性能的影响,包括扩展节点数、生成节点数、运行时间等。
- 画出流程图。
- 源程序代码
实验过程 (分析+流程图+代码+运行结果)
-
八数码问题
对于同一问题启发函数h(n)可以有多种设计方法。在本次时实验中,通过选用“将牌不在位数”和“将牌‘不在位’的距离和”两种不同的启发函数,同时还编写了不考虑h值进行搜索,即不采用启发性搜索的算法(按照广度优先搜索的策略)。,我们通过将第一种和第二种启发函数对比,发现第二种启发函数优于第一种启发函数,将采用启发函数与不采用启发性函数对比发现,采用启发性函数远远优于不采用启发性函数。第二种启发函数为h(n)=将牌‘不在位’的距离和,初始时的值为6,将牌1:2,将牌2:1,将牌6:2,将牌7:1,将牌8:2。对于不同启发函数对于实验结果和实验效率的影响较为明显。第三种启发函数是按照广度优先搜索的策略。
2.流程图
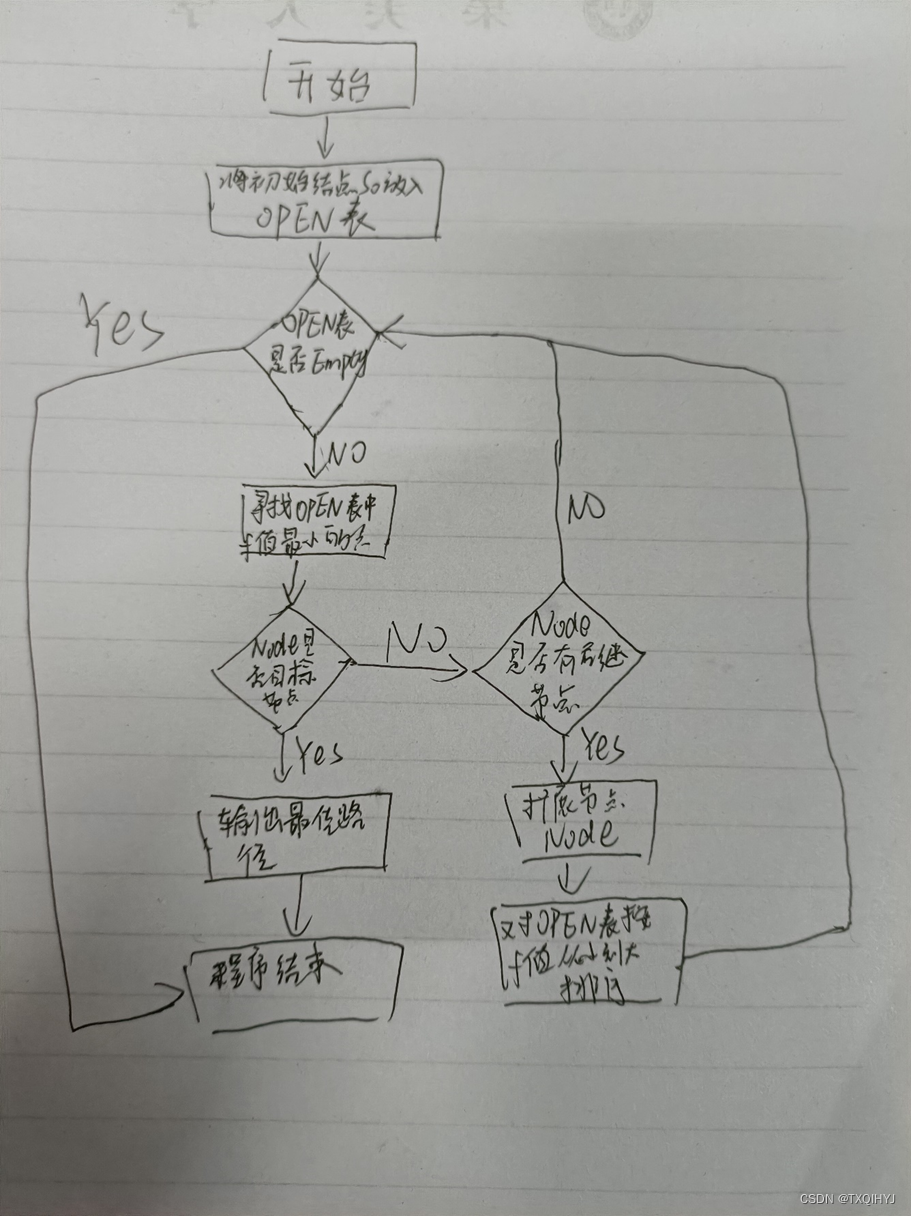
3.源程序代码
class Astar:
def salvePuzzle(self, init, targ):
# 传入初始状态init,目标状态targ,返回移动路径(string形式)
open = [(init, self.calcDistH(init, targ))]
# open表元素(状态,f值)
closed = {}
dict_depth = {init: 0}
# 深度表,用来记录节点是否被访问过及对应的深度
dict_link = {}
# 关系表,用来记录父子关系,孩子-->父亲
dict_dirs = {'u': [-1, 0], 'd': [1, 0], 'l': [0, -1], 'r': [0, 1]}
# 移动方向,对应二维坐标的变化
dirs = ['l', 'r', 'u', 'd']
path = []
# 用来记录移动路径
while (len(open)):
open.sort(key=lambda open: open[1])
# 每循环一次对列表按由小到大排序一次
while (open[0][0] in closed):
open.pop([0])
# 如果表头元素在closed表中,移出open表
if (open[0][0] == targ):
print("Successfully!")
break
top = open[0]
open[0:1] = []
closed[top[0]] = top[1]
# 取表头元素,并将表头元素移出open表,压入closed表
cur_index = top[0].index('0')
for i in range(4):
x = cur_index // 3 + dict_dirs[dirs[i]][0]
y = cur_index % 3 + dict_dirs[dirs[i]][1]
if (x >= 0 and x < 3 and y >= 0 and y < 3):
next_index = x * 3 + y
next_state = self.moveMap(top[0], cur_index, next_index)
depth = dict_depth[top[0]] + 1
# 当前节点不在深度表中,压入深度表和open表,并建立父子关系
if ((next_state in dict_depth) == False):
dict_depth[next_state] = depth
open.append(
(next_state, depth + self.calcDistH(next_state, targ)))
dict_link[next_state] = top[0]
else:
# 当前节点在深度表中且当前深度小于深度表中的值,更新深度表,建立父子关系
if (depth < dict_depth[next_state]):
dict_depth[next_state] = depth
dict_link[next_state] = top[0]
# 如果当前节点在closed表中,将其移出closed表,将更新后的节点移入open表
if (next_state in closed):
del closed[next_state]
open.append(next_state, depth +
self.calcDistH(next_state, targ))
# 循环结束,路径关系全部在dict_link中,从目标状态出发寻找路径
s = targ
while (s != init):
move = s.index('0') - dict_link[s].index('0')
if (move == -1):
path.append('l ')
elif (move == 1):
path.append('r ')
elif (move == -3):
path.append('u ')
else:
path.append('d ')
s = dict_link[s]
path.reverse()
# 将path逆序(如果想要打印出路径每一步的状态,只需要按照path和init就能实现)
print("SearchPath->", "".join(path))
return "".join(path)
def calcDistH(self, src_map, dest_map):
# 采用曼哈顿距离作为估值函数
cost = 0
for i in range(len(src_map)):
if (src_map[i] != '0'):
cost += abs(int(src_map[i]) // 3 - i // 3) + \
abs(int(src_map[i]) % 3 - i % 3)
return cost
def moveMap(self, cur_map, i, j):
cur_state = [cur_map[i] for i in range(9)]
cur_state[i] = cur_state[j]
cur_state[j] = '0'
return "".join(cur_state)
# 本程序实现了Astar类,可通过创建Astar对象来调用相关方法
# 以下仅为测试用例
test = Astar()
test.salvePuzzle("724506831", "012345678")
运行结果

-
5*5迷宫寻路问题
- 不同的估价函数对搜索算法性能的影响
估价函数:从当前节点移动到目标节点的预估费用;这个估计就是启发式的。在寻路问题和迷宫问题中,我们通常用曼哈顿(manhattan)估价函数预估费用。选取最小估价:对于每次都要选取最小估价的节点,应该用到最小优先级队列(也叫最小二叉堆)。在C++的STL里有现成的数据结构priority_queue,可以直接使用。当然不要忘了重载自定义节点的比较操作符。
2.流程图
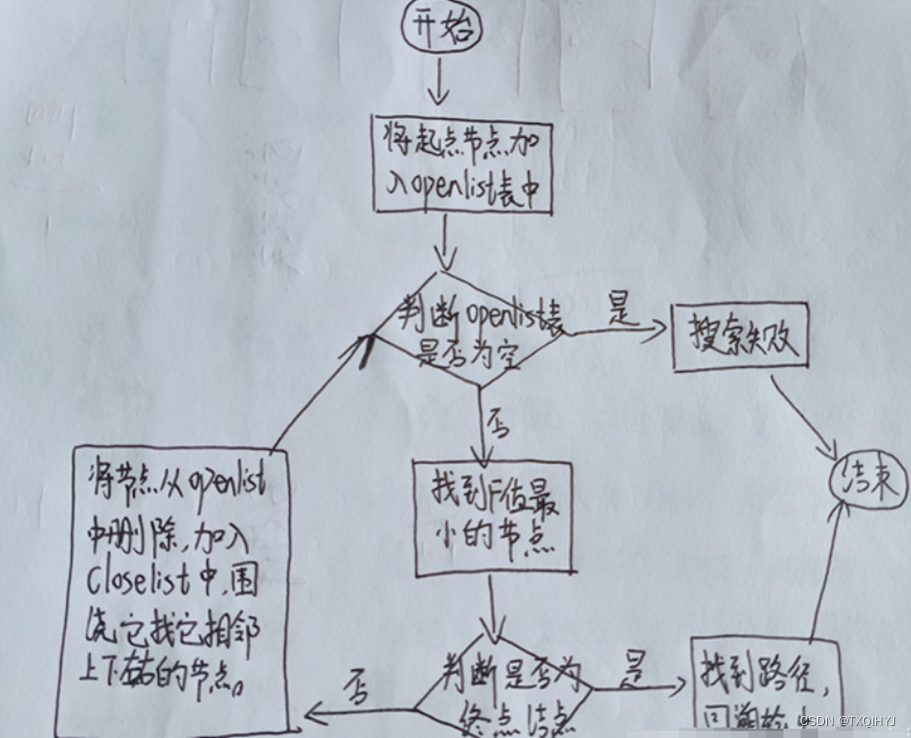
3.源程序代码
import numpy as np
import time
a = np.mat([[0, 0, 0, 0, 0],
[1, 0, 1, 0, 1],
[0, 0, 1, 1, 1],
[0, 1, 0, 0, 0],
[0, 0, 0, 1, 0]])
def gs(i, j):
return abs(i - startx) + abs(j - starty)
def h1(i, j):
return 10*(abs(i - endx) + abs(j - endy))
def h2(i, j):
return pow(i - endx, 2) + pow(j - endy, 2)
print("地图为:(1表示墙,0表示路)")
for l in range(len(a)):
for m in range(a[0].size):
print(a[l,m], end=' ')
print('')
print('')
startx, starty = 1, 1
endx, endy = 5, 5
if a[startx - 1, starty - 1] == 1:
print("起点%s位置为墙,最短路径寻找失败!" % ([startx, starty]))
else:
# 存储已扩展结点,即所有寻找的节点
Close = [[startx, starty]]
# 存储已生成节点,即最终走过的节点
Opens = [[startx, starty]]
# 存储未走的分叉节点
crossings = []
# 设置在原地图行走的路径值
road = 100
start = time.time()
rows, cols = a.shape
while True:
# 判断最后走过的节点是否为终点
if Close[-1] != [endx, endy]:
Open = []
# 减1得到数组下标值
i, j = Close[-1][0] - 1, Close[-1][1] - 1
# 对当前节点上下左右四个节点进行判断
for ni, nj in [(i - 1, j), (i + 1, j), (i, j - 1), (i, j + 1)]:
if [ni + 1, nj + 1] not in Opens and 0 <= ni < rows and 0 <= nj < cols and a[ni, nj] == 0:
Open.append([ni + 1, nj + 1])
# 将已走过的节点值修改为路径值,并将路径值加1
a[i, j] = road
road = road + 1
if Open:
# 对所有扩展到的节点进行排序,reverse=True 结果从大到小,即尾部存储代价最小的节点
Open = sorted(Open, key=lambda x: gs(x[0], x[1]) + h2(x[0], x[1]), reverse=True)
Opens.extend(Open)
# 将代价最小的节点存储到 Close 表
Close.append(Open.pop())
# 如果 pop 后 Open 表不为空,说明存在岔路,将岔路存储到 crossings 中
if Open:
crossings.extend(Open)
# 判断是否存在未走过的分叉节点
elif crossings:
next_way = crossings.pop()
# 实现路径回退,循环条件为回退节点与分叉节点不相邻
while sum((np.array(Close[-1]) - np.array(next_way)) ** 2) != 1:
# 当一条路径寻找失败后,是否将该路径岔路后的部分恢复为原地图
# i, j = Close[-1]
# a[i-1, j-1] = 0
# 每次 while 循环路径值 road 减1,并弹出 Close 表中的节点
road -= 1
Close.pop()
# 将 crossings 中最后一个节点添加到 Close 表
Close.append(next_way)
else:
print("最短路径寻找失败,失败位置为:%s,路径为:" % Close[-1])
break
else:
a[endx - 1, endy - 1] = road
print("最短路径寻找成功,路径为:")
break
for r in range(rows):
for c in range(cols):
# 0表示format中第一个元素,>表示右对齐输出,4表示占四个字符
print("{0: >4}".format(a[r, c]), end='')
print('')
end = time.time()
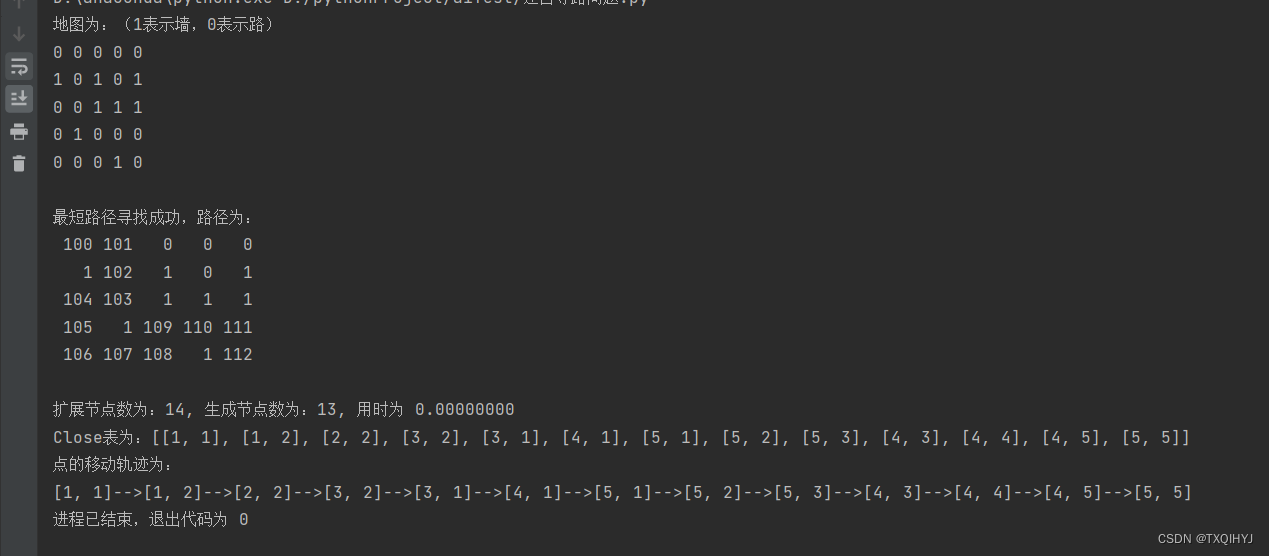
print("\n扩展节点数为:%d, 生成节点数为:%d, 用时为 %.8f" % (len(Opens), len(Close), float(end - start)))
print('Close表为:%s' % Close)
print("点的移动轨迹为:")
for k in range(len(Close)):
print(Close[k], end='')
if k < len(Close) - 1:
print("-->", end='')
运行结果
总结
通过本次实验,发现选用不同的启发函数,对于实验的结果有较大的影响。选用第一或第二种(也就是采用A*算法)远远优于普通的广度优先搜索,同时,明显的感觉到第二种启发函数效率更高,更快的找到最优解。但是,在实验过程中,也遇到了一些问题,比如初始值的八数码初始值的选择对于实验结果的影响很大,在选取一些样例时,比如1,3,0,2,8,4,7,6,5,实验结果达到20000次依然没有停止,无法比较两种启发函数的优越性,鉴于时间原因,选取一些迭代次数较小就可以达到目标状态的样例进行验证,发现第二种结果优于第一种启发函数的结果。A*算法在地图寻路问题中具有很好的优势,相比宽度优先搜索,效率更高,所耗时间更少,相比深度优先搜索,可以解决其不能找到最优解的不足,具有较高的应用价值。该算法的重点及难点就是启发式函数的选择,通过上述实验,可以发现启发式函数h2相比h1效果更好,但仍存在一些问题,需要继续找寻更优的启发式函数。总的来说,实践出真知,只有把书上的理论知识运用到实践,才是真正地掌握。
A算法是一种有效的搜索算法,用于解决路径查找和图遍历问题。它结合了最佳优先搜索的高效性和Dijkstra算法的准确性,通过评估函数来预测从当前节点到目标节点的最佳路径。A算法的评估函数通常表示为:f(n) = g(n) + h(n),其中g(n)是从起始点到当前节点n的实际成本,而h(n)是当前节点n到目标节点的估计成本(启发式)。在解决八数码问题和55迷宫寻路问题时,A算法的表现通常取决于启发式函数h(n)的选择。八数码问题是一个经典的滑动拼图问题,目标是通过滑动数字来从初始状态移动到目标状态。而5*5迷宫寻路问题则需要在迷宫中找到从起点到终点的最短路径。
对以上做一个归纳:
-
启发式函数的选择:对于八数码问题,常见的启发式函数包括曼哈顿距离、欧几里得距离和不在位的数码数量等。对于迷宫寻路问题,通常使用曼哈顿距离作为启发式函数。合适的启发式函数能够显著提高搜索效率。
-
性能分析:A*算法的性能很大程度上取决于启发式函数的准确性。一个好的启发式函数可以减少搜索空间,从而加快搜索速度。在实验中,我们可以比较不同启发式函数对解决问题所需时间和空间的影响。
-
优化与改进:在实验过程中可能会发现A*算法在某些情况下效率不高,这可能是由于启发式函数过于乐观或者过于悲观。在这种情况下,可以尝试调整启发式函数,或者引入其他技术,如迭代加深、双向搜索等,以提高算法的效率。
-
数据结构的选用:A*算法中通常使用优先队列来存储待探索的节点,这样可以保证每次都能从队列中取出具有最小f(n)值的节点进行扩展。合理的数据结构可以减少算法的时间复杂度。
-
实验结果:实验结果通常显示A算法能够有效地找到解决方案。对于八数码问题,A算法能够找到最优解;对于5*5迷宫问题,它也能找到一条最短路径。然而,算法的效率会受到启发式函数选择和问题实例难度的影响。
-
结论:A*算法是解决八数码问题和迷宫寻路问题的强大工具,但其性能依赖于合适的启发式函数和高效的实现。通过实验,可以发现适当的优化和启发式函数的选择对于提高算法效率至关重要。














 3217
3217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









