






 这段代码使用GPT生成的代码处理简历文本,包括分词、生成词云、绘制图表和创建Word文档。它利用jieba进行分词,然后用wordcloud展示词云图,接着绘制简历数据的条形图,并最终将简历内容保存到Word文档中。
这段代码使用GPT生成的代码处理简历文本,包括分词、生成词云、绘制图表和创建Word文档。它利用jieba进行分词,然后用wordcloud展示词云图,接着绘制简历数据的条形图,并最终将简历内容保存到Word文档中。
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from docx import Document
# 分词
def segment_resume(resume_text):
seg_list = jieba.cut(resume_text)
segmented_text = ' '.join(seg_list)
return segmented_text
# 生成词云
def generate_word_cloud(segmented_text):
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(segmented_text)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
# 绘制图表
def draw_chart(data):
categories = data.keys()
values = data.values()
plt.bar(categories, values)
plt.xlabel('Category')
plt.ylabel('Value')
plt.title('Resume Data')
plt.show()
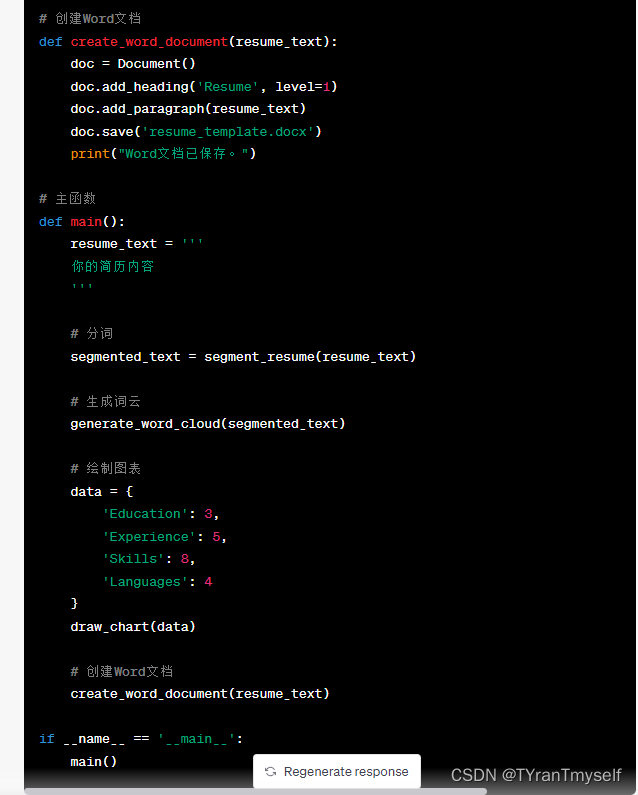
# 创建Word文档
def create_word_document(resume_text):
doc = Document()
doc.add_heading('Resume', level=1)
doc.add_paragraph(resume_text)
doc.save('resume_template.docx')
print("Word文档已保存。")
# 主函数
def main():
resume_text = '''
你的简历内容
'''
# 分词
segmented_text = segment_resume(resume_text)
# 生成词云
generate_word_cloud(segmented_text)
# 绘制图表
data = {
'Education': 3,
'Experience': 5,
'Skills': 8,
'Languages': 4
}
draw_chart(data)
# 创建Word文档
create_word_document(resume_text)
if __name__ == '__main__':
main()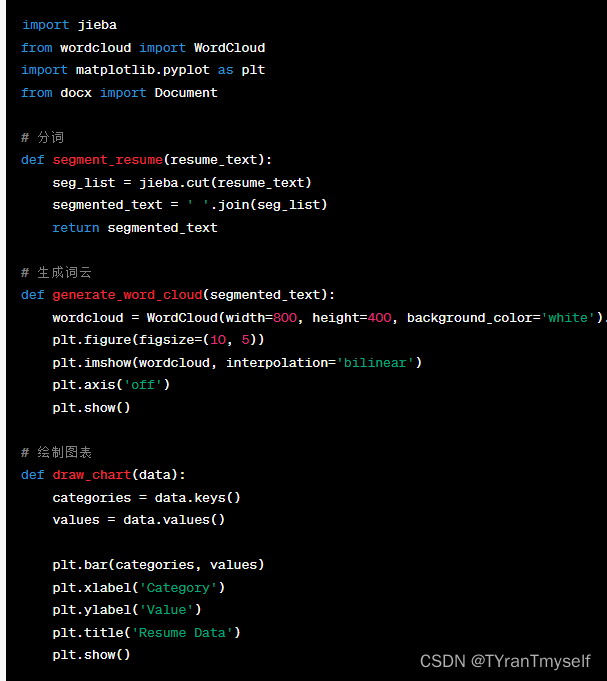

















 876
876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









