







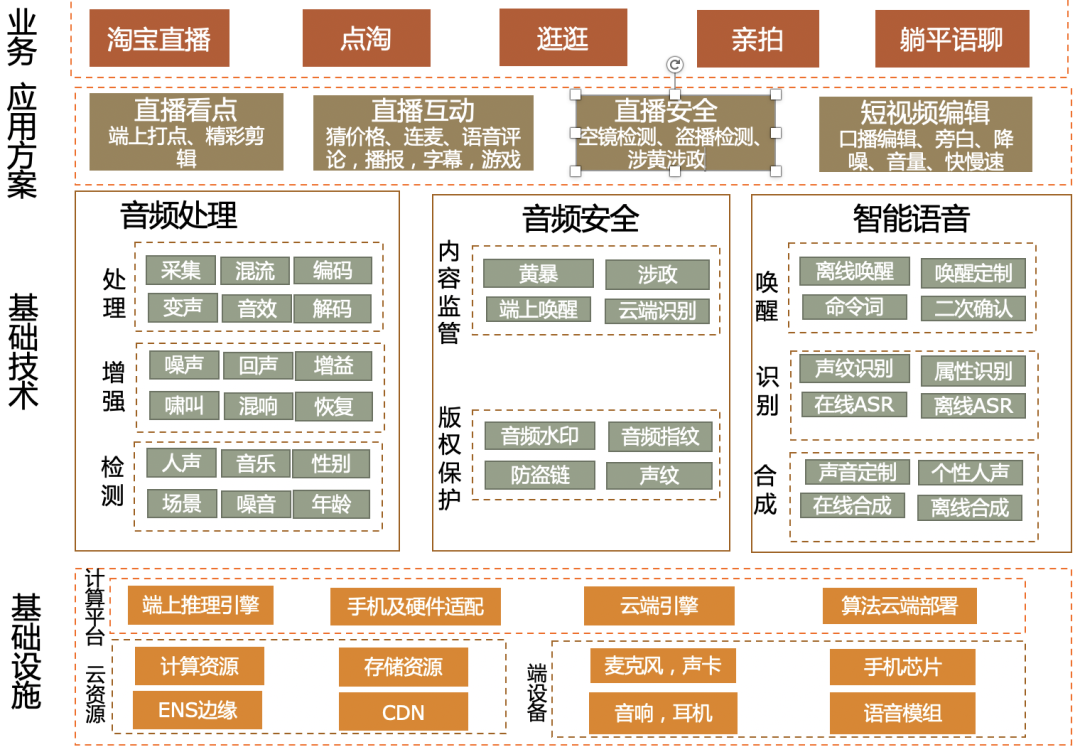
背景介绍
2019年是电商直播爆发的一年,被称为电商直播元年,2020年电商直播持续发展,越来越多的平台开始发力直播带货业务。淘宝直播作为电商直播第一平台,成为连接上亿主播和粉丝的桥梁。
直播传递信息的途径,不外乎声音和画面两种。其中声音作为“第一媒介”,需求主要包含以下两个部分:第一是音质,好的音质能让人产生“声临其境”的感觉,而声音刺耳,断续,音量过大或过小,都会让人听起来不舒服,从而影响购物体验;第二是互动体验,视觉互动已广为人们熟悉,但声音互动其实更加自然,比如主播通过语音控制发红包,上货,粉丝通过语音消息与主播互动,或通过语音连麦与主播沟通;除此以外,语音在安全管控方面也显得尤为重要,在防盗播,涉黄涉政方面,都可通过语音来识别异常。


在短视频上,声音的需求也越来越多。随着2020年底点淘,逛逛等新业务的推出,短视频成为内容业务发展的新引擎,为了帮助商家达人更加便捷的生产高质量内容,“亲拍”APP随即推出,大幅提高编辑效率,成为淘系商家,达人生产优秀短视频的有力工具。与此同时,“亲拍”APP的深度编辑功能还提出了大量音频需求,比如变速,混音,快速播放,语音降噪,自动字幕,语音旁白等等。


音频业务解决方案TaoAudio
TaoAudio是面向直播和短视频声音需求的完整解决方案。其分成三个主要模块,分别是音频处理,音频安全,语音交互。TaoAudio支持端云一体化部署,部分模块部署在端侧,比如音频编解码、降噪、场景检测、水印等,可充分利用端上算力,以低成本方式实现实时处理,另一部分模块部署在云上,比如语音识别,语音合成,确保算法的精度和效果。同时,TaoAudio还具备友好的部署方式,通过JNI和Object-C实现跨平台调用,上层只需配置模板和送入音频数据,即可源源不断的拿到处理后的声音或标签,实现极低成本的接入。
直播短视频音频技术架构
▐ 直播业务
直播业务对音频的的三个核心需求是实时,安全,交互。面对众多的音频需求,如果只是提供算法原子能力给业务层调用,集成和联调成本会非常高,并且业务层不可避免会碰到一些音频专业相关问题,解决难度大,TaoAudio抽象了需求共性,实现了对实时音频流的检测和处理,如下图所示,在直播场景中TaoAudio起到连接上层业务和推流底层的作用,让业务音频需求和底层推流解耦合,业务音频相关的需求和问题全部收口到TaoAuido里面,这对提升音频类需求实现效率和加快迭代优化速度有非常大的帮助。
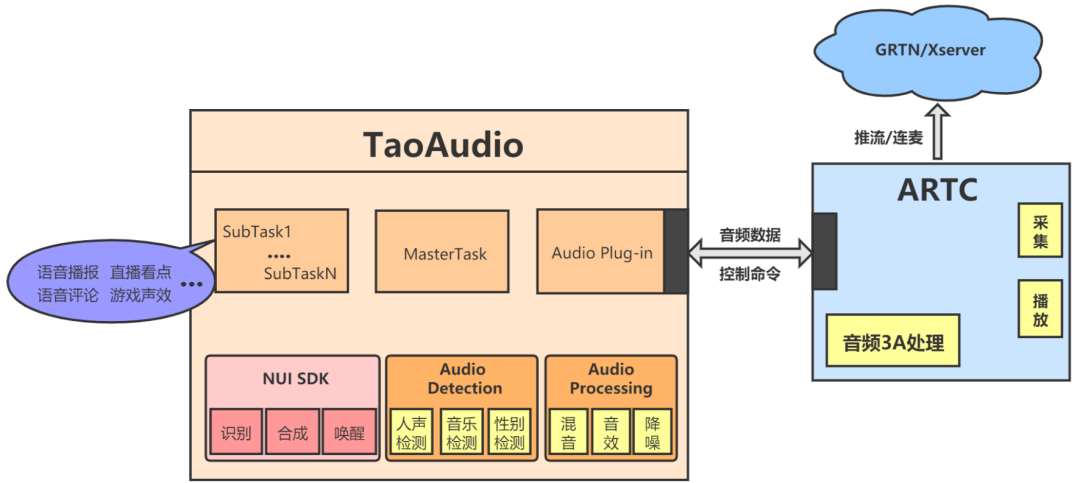
NUI SDK
NUI SDK提供了智能语音交互能力,包括:语音合成、语音识别和关键词检测等功能。
音频检测
音频检测模块实现了直播声学场景和声学事件检测功能,具体算法包括:人声检测、噪声检测、音乐场景检测、性别识别等,整体算法思想基于深度学习和信号处理相结合进行。
音频处理
音频处理模块包括声音自适应混音、语音重采样、语音变调变速,音效处理、语音降噪等。其中较为核心的是自研的智能降噪Alidenoise和音效处理Soundmod SDK,能够很好的满足上述需求。
▐ 短视频业务
在非实时通讯业务中,由于不存在实时音频采集和回声消除等场景,TaoAudio可以以一种更加单纯的形式存在,这种形式我们叫做智能数字音频工作站(intelligent digital audio workstation,以下简称iDAW)。如下图所示,在iDAW里面,我们可以有多个音轨(track),每个音轨的源头(source)可以是一个音频片段(audio clip),一个音频流(audio stream),或者一个符号序列(symbol sequence)。每个track的结构如下图:
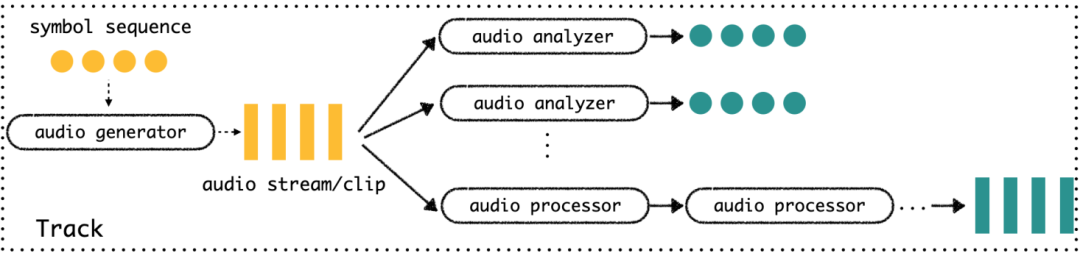
其中,黄色代表输入,绿色代表输出,虚线表示可有可无。每个track里面有三种围绕audio的变换。
一种是“符号-音频”的变换,可以理解成是audio generator,输入符号序列,输出音频,例如TTS便属于这种变换;
第二种是“音频-符号”的变换,可以理解成是audio analyzer,输入音频,输出符号序列,例如VAD、ASR便属于这种变换;
第三种是“音频-音频”的变换,可以理解成是audio processor,输入音频,输出音频,例如上述soundmod里面的所有变换,以及3A里面的ANS、AGC等。
每个track可以通过重采样,进行混音,输出混音后的音频,如下图:

在TaoAudio里面,一个iDAW对应一个TaoAudioWorker(TAW)实例。整个TaoAudio的基础架构是用C++实现,目前支持的audio generator有NUI SDK里面的语音合成,audio analyzer有NUI SDK里面的语音识别、唤醒词识别和文件极速转写,还有我们整个音频检测系统,audio processor有soundmod和alidenoise等。
TaoAudio把恰当的的连接能力和处理能力提供给调用者,不同的业务方能各取所需,通过TaoAudio定制出自己的整个音频工作链路。例如在短视频生产工具中,利用TaoAudio可以做到无缝的对接几乎所有音频相关的业务,比如自动生成旁白(TTS)、字幕提取(ASR)、自动去除空白(VAD)、原声增强(soundmod)、变速变调(soundmod)、降噪(alidenoise)、声音美化(soundmod)、背景音乐生成(chord-arranger)等等,每一个功能都可以以track为单位进行添加和连接。
TaoAudio音频核心技术
TaoAudio作为一套音频业务解决方案,底层核心技术主要涉及两块:一块是音频处理技术,另一块是语音交互技术。其中,音频处理包括:智能语音降噪、智能声学场景检测、音效处理、回声消除,以及音频指纹和音频水印技术等;语音交互技术主要包括:语音识别、唤醒、语音合成、敏感词识别等;
▐ 音频处理技术
智能语音降噪
传统语音降噪算法速度较快,计算消耗较低,能在多种多样的低端设备上运行,但面对复杂且多变的非平稳噪声和低信噪比环境,传统方法的效果不尽如人意。基于学习的、数据驱动的降噪算法,通过对大量数据的学习,在真实的噪声环境中展现出了较为突出的优势,取得了较好的效果。
但是这类“基于学习的”方法,由于参数多、模型大,较为复杂,因此可解释性欠佳,稳定性不易受控,泛化能力不易保障,缺陷不易排查。这些问题的存在,导致基于学习的方法常被称为“无法观察”且“不易调整”的“黑箱”。同时,基于学习的算法虽听感效果出众,但相比传统算法,复杂度偏高,运算速度较低、电量消耗较多,更容易导致硬件发热、系统降频、程序卡顿等问题。
为将最好的音频体验带给用户,淘系技术音视频算法团队基于深度学习和信号处理相结合的思路,在反复的研发、试错、创新中,针对降噪的效果、质量、算法的速度、能耗、延迟与泛化的稳定性等诸多方面,应用了一系列技术,对模型结构、框架、约束等进行了研发改进,最终研发了智能语音降噪算法Alidenoise。
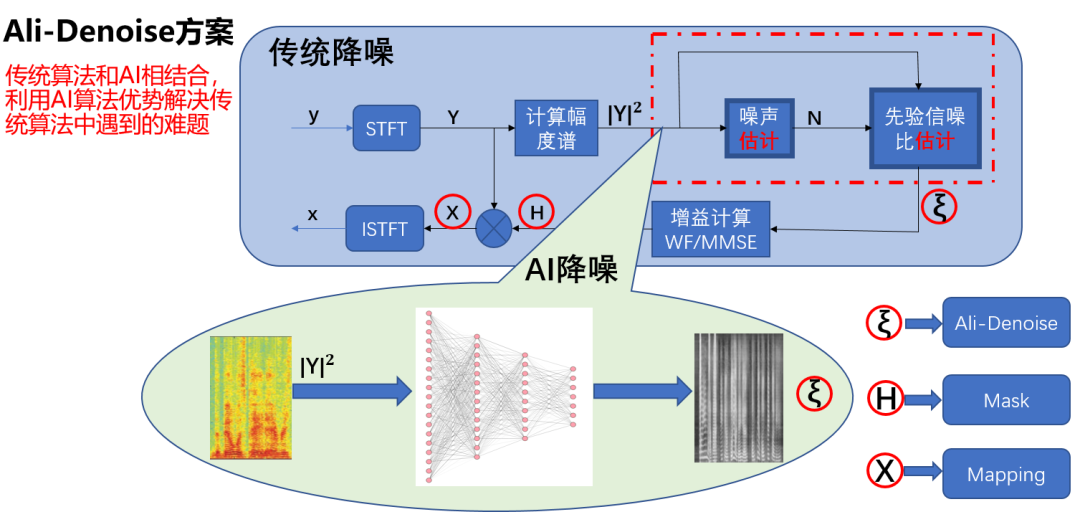
Alidenoise技术特性
1)传统信号处理方法与深度学习类方法相结合,兼具可处理非平稳类噪声和算法复杂度低的特点
2)在神经网络的设计上,结合训练目标,以人声的语谱纹路作为主要学习对象,噪声泛化性强语音保真度高
3)采用Cache buffer技术,实现流式处理
4)轻量小模型, 支持移动端实时增强,覆盖低、中、高设备
5)灵活的网络模型配置,支持降噪算法延时可调
智能声学场景检测
淘宝直播、短视频的多媒体需求日益增长,在基础通讯链路与上层业务需求中,声音与音频需求层出不穷。
需求的增长与基础技术的发展成为了主要矛盾。因此我们提出多任务的智能声学场景检测项目,并逐步实现。
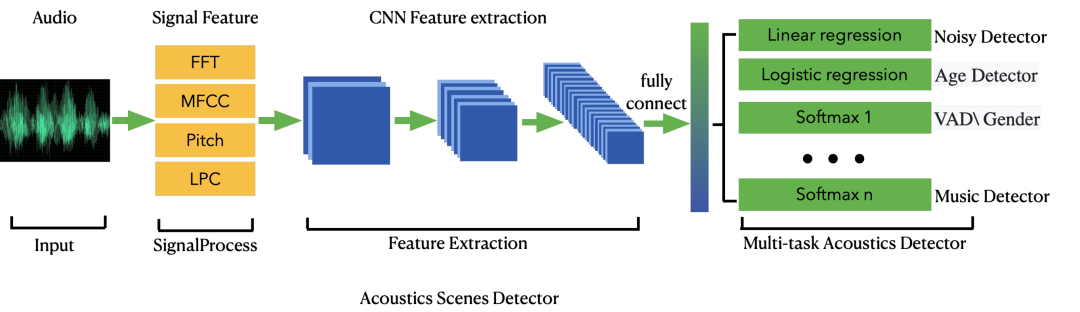
1)信号处理:为了提升声学场景检测的泛化性,我们对音频进行声学信号处理的特征提取,比如fft频域、mfcc、lpc系数、基音周期等经典有效的特征,来表征声音信号,同时也对声音向量有效降维。
2)端侧AI:端上轻量化模型,是声学场景检测的主要关键之处,我们借鉴了经典的MobileNet、ShuffleNet中轻量化模型技巧,采用矩阵分解、分组卷积、小卷积核等卷积优化,全局池化替代繁重的全连接,同时尝试空洞卷积对于模型轻量化的优势。为了在端侧取得更高的适配能力,模型使用了量子化来进一步降低算耗,并使用短时记忆单元提高上文信息量,在提速的同时保障算法效果。
3)多任务联动:在声学场景自适应的多任务中,我们共享卷积特征权重,有效增加任务的泛化性。同时在相关任务设置一级分类与二级分类关联设计,不断的有效提升二级分类的准确度,比如是否人声检测为一级分类、性别检测是二级分类,两者联动可以让性别检测更加准确。
4)能力迭代扩容:随着场景检测算法与上层玩法之间的相互促进与丰富,检测类目的需求会动态地、甚至敏捷地变迁。为了在此业务场景下保证检测能力与需求俱进,我们将借助迁移学习与增量学习技术,敏捷升级识别能力,快速反应逐步扩充的检测需求。
5)业务承载:多任务的智能声学场景检测,承载着两大类业务。第一类淘宝直播通讯场景的自适应增强业务,比如检测不同的嘈杂程度、是否音乐来进行配置不同的算法参数,利用不同性别年龄检测来配置不同的美声需求。第二类是业务需求,比如轻直播的人声检测需求,空镜检测的人声检测需求,音乐可视化的音乐检测需求等。
音效处理
我们有一套完整的从音频到音频的变换工具Soundmod SDK,它支持对音频进行实时的和离线的处理,Soundmod支持的处理包括了最常用的“三大件处理”(动态压缩、均衡、混响)、变速不变调、变调不变速、男变女女变男,也包括了其他常用的效果,比如合唱效果、颤音效果、延时效果、哇音效果、声码器效果等等:
phaser vocoder类音效:time-stretching、pitch-shifting、vocoder、robotic、whispering
delay类效果:delay、chorus、flanger、vibrato
dynamics类效果:compressor、limiter
filter类效果:equalizer、autowah、phaser
modulation类效果:ring-modulation、tremolo
spatial类效果:reverb
下面是一个音效处理Demo视频:
▐ 智能语音交互技术NUI
NUI SDK(Natural User Interaction)是阿里巴巴达摩院语音实验室全自主研发的语音全链路方案。
方案聚合端和云的核心算法能力,包括信号处理,语音唤醒,语音识别,自然语言理解,语音合成,声纹识别等,具备完整端云一体语音能力。
方案通过能力可插拔组合的方式,实现一套SDK满足不同产品的语音需求。
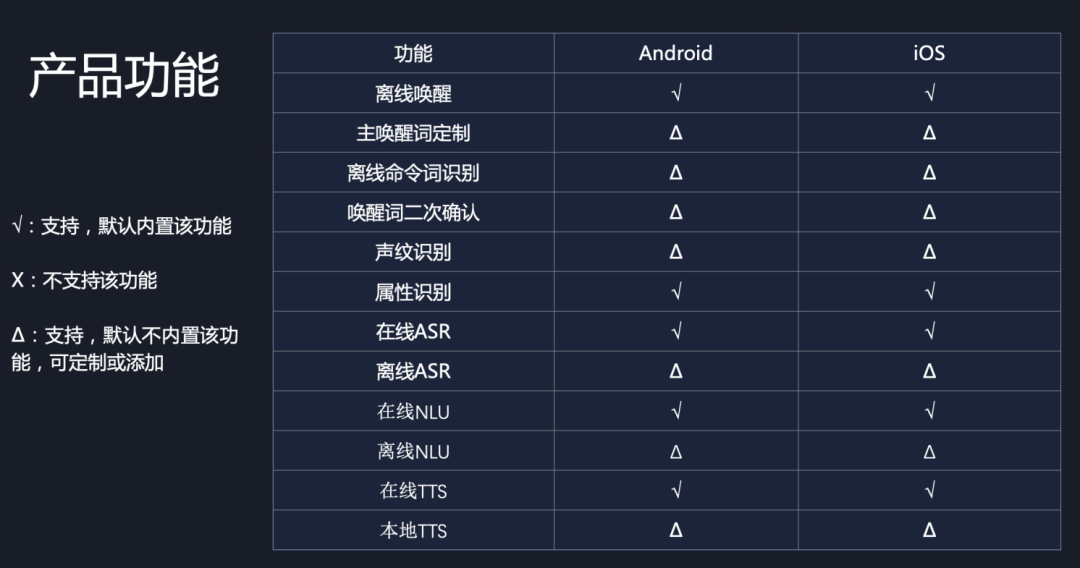
方案支持iOS/Android操作系统,集团内外累计激活设备3.7亿+。
淘宝直播场景作为丰富的语音技术使用场景,在应用内存在多种对语音能力的使用。例如“CRO敏感词检测”使用了“离线命令词识别”,“评论播报”使用了“在线语音合成”,“直播看点”使用了“在线语音识别”,以及后续还可能上线的其他功能会有更多能力的扩展。这就要求我们的SDK具备多实例并行的能力,能够使得不同调用业务之间可以并行不受影响。因此在本次淘宝直播和达摩院的共建中,语音实验室完成了NUI SDK的全面升级,将原有的面对交互场景的SDK扩展为更加灵活,可支持多种原子场景独立使用的版本。
直播场景是算法技术使用非常密集的场景,信号处理,RTC,敏感词检测,视觉算法等等都在这个场景下全速运行,这意味着对于CPU的消耗非常大,同时App对包大小有着严格要求。语音实验室全面升级命令词检测技术方案,采用MNN推理框架,并同MNN进行了深度优化,在实时率上提升明显。通过“PAI模型压缩”技术将唤醒模型量化到INT8计算,进一步减少模型大小,相对对上一代方案减小50%。再者通过直播端侧的模型下发链路,能够将模型进行云化,进一步减小App包大小。
应用案例
▐ 直播评论和提示音播报
语音播报功能给主播提供的是直播间用户意图的声音提醒能力,该功能是通过语音,将粉丝进入直播间、粉丝评论和粉丝连麦申请等行为在主播手机中播报出来,目的是提醒主播当前直播间的实时动态,做好接待客户的准备。语音播报功能直接涉及到的语音技术点,主要包括:文字转语音TTS、语音混音、信号重采样以及语音数据流管理和控制等。
除此之外,播报声音要在一边推流的情况下一边播报,所以还涉及到播报声回声消除,防止播报的声音被粉丝听到。另外,语音播报具体实现在业务上层,回声消除是音频底层技术,如何协调好两者之前的关系,相互配合好达到好的效果体验,具有一定的挑战性。
TTS是语音评论播报的基础,评论在主播端播报之后会被推流的麦克风采集,如果不进行处理会导致直播间所有粉丝都听到播报声。消除本地播报的声音,可以使用回声消除技术,ARTC底层有回声消除算法,但是不支持本地播放消除,经过对ARTC层系统的改造,实现了播报声消除的功能。
但是,当主播讲话时进行播报,会形成回声消除“Double Talk”抑制过大问题,导致主播声音损伤严重。为了解决该问题,从两个角度出发,一个是播报时优化回声消除算法,另外一个通过主播说话智能检测控制播报声音减小或者不播报。最终通过算法优化,解决了播报消除导致主播语音损伤的问题,使评论语音播报功能体验更佳。
▐ 短视频智能编辑
在短视频领域,口播类的短视频在商品介绍的短视频里面占了绝大多数。口播编辑能让短视频生产者很轻松的剪掉不必要的长停顿,多余的字句,以及字与字时间的琐碎的停顿。这个功能的核心技术是语音识别和字幕转写对齐的服务,如下图所示:
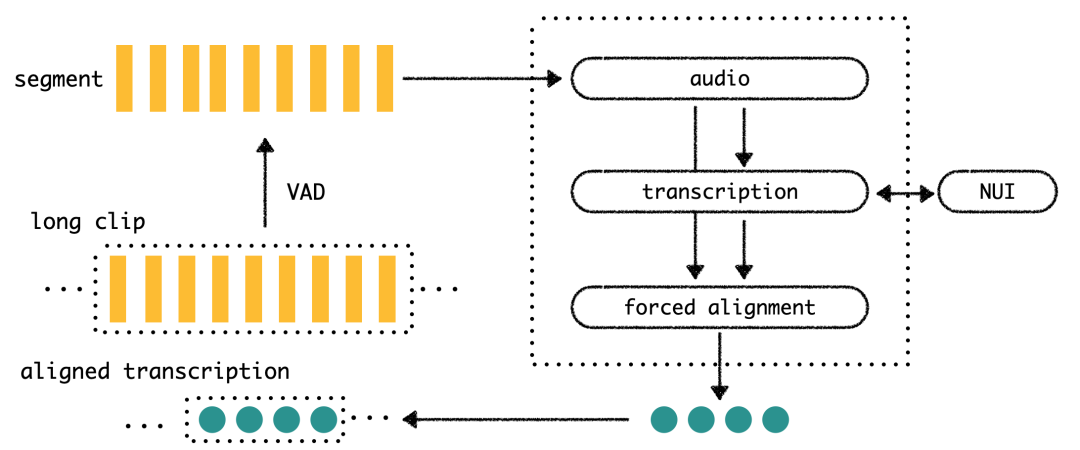
一段长音频通过在端上的分片分成以1分钟为单位的音频切割文件(segment),传输到服务端,服务端拿到文件之后先进行一次极速文件转写(transcription),这个转写的过程需要与NUI服务进行交互,拿到结果转写结果之后,把结果和原音频一起送到强对齐算法(forced alignment),输出带时间戳的逐字转写结果(aligned transcription)。使用了该功能之后,能让这一类口播视频的生产达效率大幅提升。
▐ 短视频语音降噪
在口播的短视频里面,人声是前景声,其他声音一般都是背景声。背景声有时是有用的声音,比如背景音乐,或者和讲解场景或物品相关的关键性声音;有时是无用的声音,比如商场内的嘈杂声音,或者马路上的噪音。业务上通常有一种需求是去除无用的背景声音,以让前景声音变得更加突出,让短视频里面所呈现的信息更加清晰。淘宝音视频算法团队自研的智能降噪算法Alidenoise已经集成到TaoAaudio中,经过和竞品降噪能力对比表明Alidenoise降噪效果优于竞品,且处理的实时率能达到1%,目前智能降噪能力已经输出给短视频编辑业务使用。
下面展示一组对比音频:
原始音频:
竞品降噪:
Alidenoise降噪:
▐ 直播看点ASR和推荐
为了提升直播时宝贝转化的效率,优化用户观看直播时的购物体验,淘宝直播向所有商家主播、达人主播,提供了“直播看点”的功能。直播看点有两种形式,一种是主播手动打点,另外一种是智能打点。智能打点主要根据直播视频中的目标识别进行自动打点,主播口播为智能看点提供了另外一个维度的信息,使用语音识别技术把口播语音全部转成文字信息,再使用语义理解技术提取主播所介绍的商品信息。
直播看点ASR完整的功能实现涉及到语音识别、信号重采样、语音降噪等技术,其中语音降噪的选择对识别的准确性有较大的影响。除了把声音内容作为打点的特征,还可以从声音类型的角度出发,检测当前主播是否在说话、直播间是否有音乐,或者处于哪种声学环境,把声音作为一个维度信息进行直播间的推荐。当前TaoAudio已经具备上述技术能力,能够快速辅助业务实现对应的功能。
▐ 直播语音评论
评论区作为直播间的核心互动功能,可以通过评论提升直播间互动率和用户直播间停留时长。直播评论如果只有文字的话,形态比较单一,语音评论可以让粉丝在观看直播的时候用语音进行评论,使粉丝和主播的互动更加有趣。
语音评论技术链比较长,涉及到客户端语音采集、编解码、播放、语音识别转文字和服务端语音存储、内容审核,在主播端,主播播放出语音评论,还涉及到声音的控制和回声消除算法。语音评论链路上所涉及到音频相关的需求,TaoAudio均能很好的满足。
▐ 短视频旁白生成和音效处理
短视频里面需要有旁白,这些旁白可以是机器生成的人声,或者真实录制的人声。很多时候用户不希望自己的真实声音出现在短视频中,便会选择生成的声音作为旁白,或者对自己录制的声音进行各种音效处理以隐藏自己的真实声音。
在淘系的短视频制作工具MAI编辑器和亲拍APP中均都接入了TaoAudio的文字转语音的功能,这些功能可以很方便的生成不同音色、不同语速、不同语调的人声。在有人声的基础上,用户可以很自由的对人声进行各种变换,包括变速、变调、变声、美声等等,这些技术均可通过TaoAudio内集成的Soundmod实现。
总结&展望
总的来说,当前TaoAudio作为内容平台的音频解决方法,支持了多种音频相关的业务需求,从刚开始遇到的各种问题,到现在问题逐步的收敛,SDK的功能越来越稳健。淘系技术音视频团队会继续丰富算法能力,比如AI结合的语音增强、智能音频检测、短视频自动配乐,音乐理解和生成,同时达摩院语音技术团队在不断优化升级语音交互性能,例如和MNN共建的端上唤醒技术、离线语音识别等也都相继要上线来满足直播业务的需求。
未来,TaoAudio将基于现有的功能继续打磨,保证稳定性的同时进一步提升体验,并且将朝以下几个方向继续发展:
1)算法能力扩展:丰富直播互动音频类算法,从音频层面支持更多业务玩法和功能需求
2)端侧AI:结合传统信号处理和AI,提升算法效果,基于MNN框架提升算法效率,实现大部分音频AI算法端上部署,比如端上ASR技术,智能VAD技术,智能PLC技术等;
3)云端一体:端云相互配合,实现云端部署复杂算法和功能的能力
欢迎业内专家朋友们前来交流:zhuangshu.wlb@alibaba-inc.com
✿ 拓展阅读



作者|庄恕,虫娃,屠零,远至
编辑|橙子君
出品|阿里巴巴新零售淘系技术




















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









