








前面也介绍了tools工具,今天来试着自己跑一下图像分类的实例
1、下载数据
我没有用imagenet的数据,因为太大了不想下,而且反正也只是当作例程跑一下而已,所以我用的是另一位博主分享的网盘上的数据,共有500张图片,分为大巴车、恐龙、大象、鲜花和马五个类,每个类100张。需要的同学,可到网盘下载: http://pan.baidu.com/s/1nuqlTnN,然后顺便帖一发这个博主的那页博客以示尊重版权:
http://www.cnblogs.com/denny402/p/5083300.html,
他那个网盘里的数据似乎重复了以便,其实里面的那个re文件夹内容是一样的,删掉就可以,所以就是re里面的train和test文件夹留着用就行。

然后我把这个图像数据放在了caffe/data/mytest 文件夹中,至于怎么拷过去,无非就是用linux的cp或者scp,命令了,百度之。
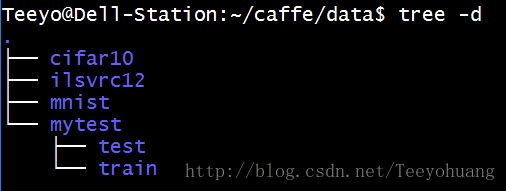
如图所示
2、转换图像格式
我在caffe/examples/中新建了一个文件夹mytest,mkdir examples/myfile,文件夹用来存放配置和脚本文件。
那么现在开始来创建一个脚本,生成图像文件名的脚本清单txt
vim examples/mytest/create_filelist.sh
#!/usr/bin/env sh
DATA=./data/mytest
MYTEST=./examples/mytest
echo "create train.txt ..."
rm -rf $MYTEST/train.txt
for i in 3 4 5 6 7
do
find $DATA/train -name $i*.jpg | cut -d '/' -f4-5 |sed "s/$/ $i/">>$MYTEST/train.txt
done
echo "create test.txt..."
rm -rf $MYTEST/test.txt
for i in 3 4 5 6 7
do
find $DATA/test -name $i*.jpg | cut -d '/' -f4-5 | sed "s/$/ $i/">>$MYTEST/test.txt
done
echo "All done"
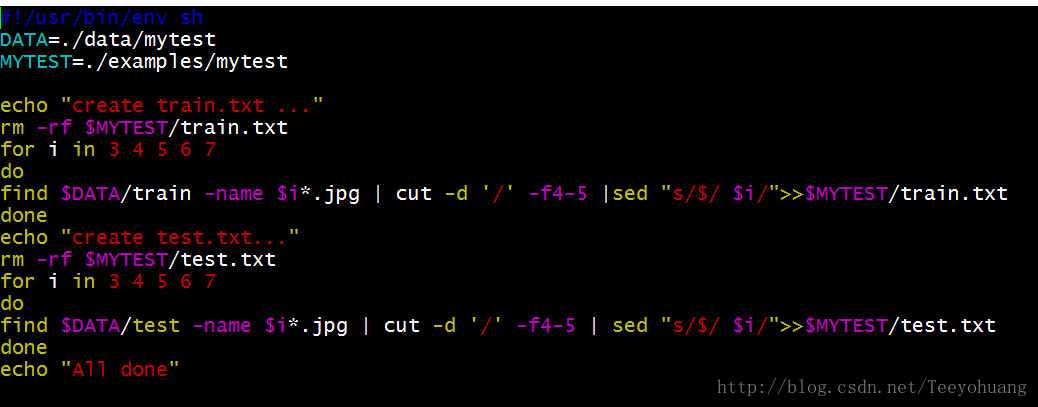
chmod u+x create_filelist.sh
这个其实就是改一下权限什么的,使得在caffe根目录能够执行
然后回到 caffe 根目录执行:
./build/examples/mytest/create_filelist.sh

如果之前那个脚本没有出现什么问题,就会成功得到两个txt文件,打开看一下,我截取了部分内容如下:
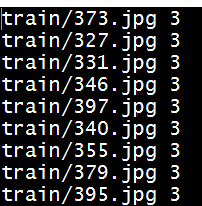
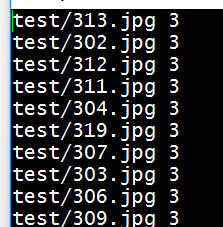
然后就又编写一个脚本文件vimcreate_lmdb.sh 来调用tools中的工具进行转换:
#!/usr/bin/env sh
MYTEST=examples/mytest
echo "create train lmdb..."
rm -rf $MYTEST/my_train_lmdb
build/tools/convert_imageset \
-shuffle \
-resize_height=256 \
-resize_width=256 \
/home/Teeyo/caffe/data/mytest/ \
$MYTEST/train.txt \
$MYTEST/my_train_lmdb
echo "train done"
echo "create test lmdb..."
rm -rf $MYTEST/my_test_lmdb
build/tools/convert_imageset \
-shuffle \
-resize_height=256 \
-resize_width=256 \
/home/Teeyo/caffe/data/mytest/ \
$MYTEST/test.txt \
$MYTEST/my_test_lmdb
echo "All done."

然后同样来一下chmod u+x create_lmdb.sh使得在caffe目录下能直接调用
在caffe根目录下执行:
./build/examples/mytest/create_lmdb.sh
如果脚本没有问题的话,显示如下内容

看一下我们的mytest文件夹
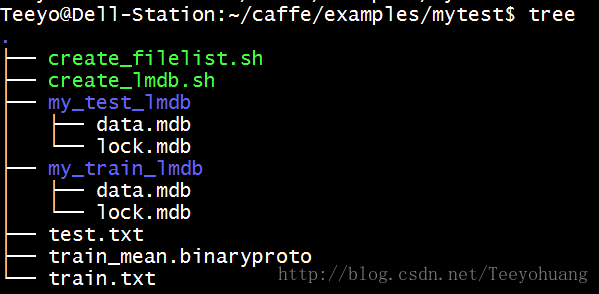
那个.binaryproto 的文件本来是没有的,因为我写博文的时候已经执行了下面一个步骤所以才有的。
3、计算均值并保存
这个工具在上一篇博文我也讲过了,直接来用吧
然后就会顺利得到我上幅图中所说的train_mean.binaryproto

4、模型和配置文件
模型我们就用caffenet,这个模型的描述是在caffe/models目录下:
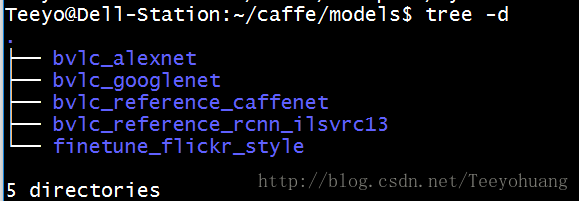
就是第三个文件夹bvlc_reference_caffenet,来进去看一下有什么东西
vim打开 readme.md,如下所示:
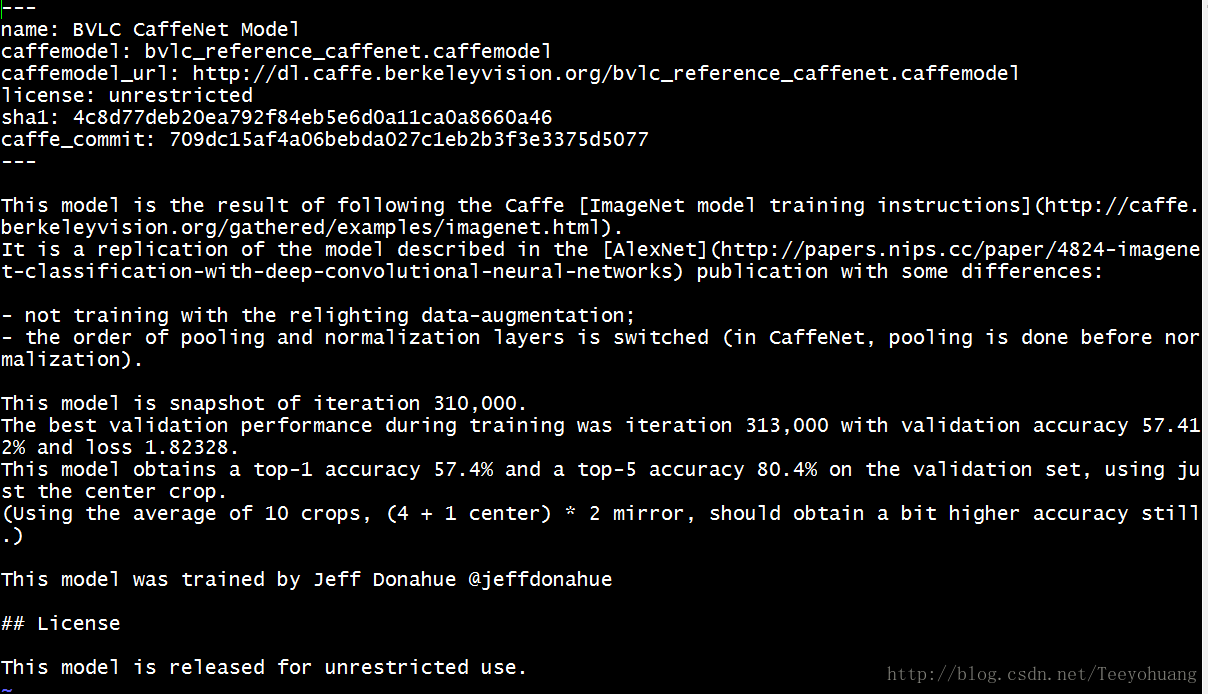
这里面主要就是提供了caffemodel下载链接:
caffemodel_url: http://dl.caffe.berkeleyvision.org/bvlc_reference_caffenet.caffemodel,
然后简述了一下caffenet,这个caffenet其实就是由Alnexnet做了一点小小改动得来,
这几个改动的细节在里面详细描述了,这里我就略过了,各位自行阅读
主要是把我需要的solver.prototxt 和train_val.prototxt复制到我的mytest文件夹中去,
cp models/bvlc_reference_caffenet/solver.prototxt examples/mytest/
cp models/bvlc_reference_caffenet/train_val.prototxt examples/mytest/
然后到我的mytest文件夹中去修改,不要把别人model里的修改了哦。
net: "examples/mytest/train_val.prototxt" //模型网络改了
test_iter: 5 //test迭代次数改了
test_interval: 20 //迭代间隔改了
base_lr: 0.001
lr_policy: "step"
gamma: 0.1
stepsize: 100
display: 10
max_iter: 600 //最大迭代次数改了
momentum: 0.9
weight_decay: 0.005
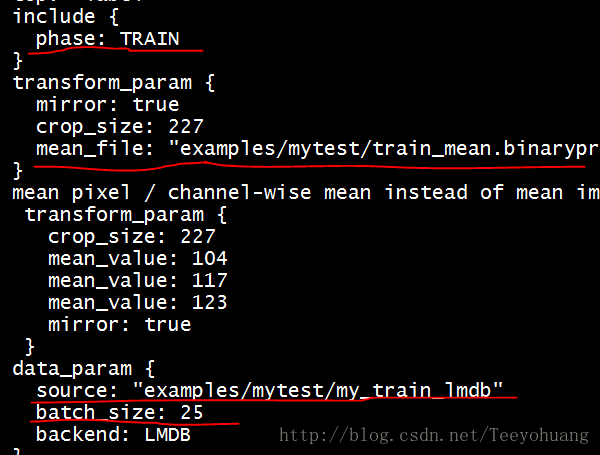
solver_mode: GPU再修改train_val.prototxt
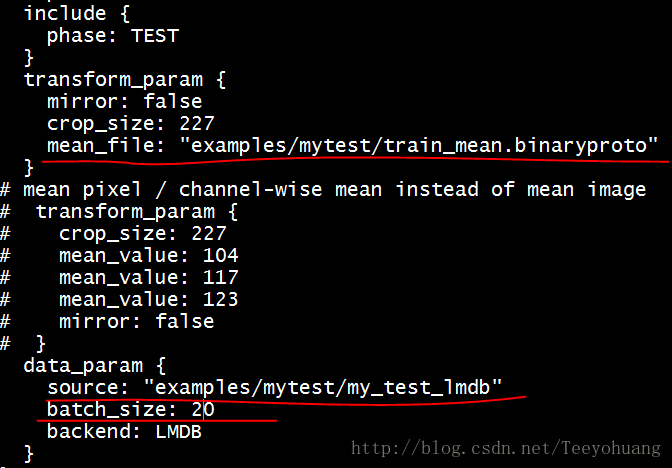
这里主要修改两个datalayer 中的meanfile和source两个路径
以及train和test的两个batch_size!!!
-----------------------------------------------------------------------------------------------------这些参数的详细解读------------------------------------------------------------------------------------------------------
之前我本来按照提供数据的那个博主的博文来设置的参数。
他的train的batch_size是256,然后我第一次跑的时候就提示了out of memory!
这一般就是batch_size设置大了的问题,跟GPU的性能已经是否在同时跑其他的程序有关,
我那个时候服务器还有别人在跑另一个很大的例程,所以就只能把batch_size调小一些了、
我的train net的batch_size = 25,考虑到我这里一共有500个train数据,所以我就把solver 中的 test_interval 设置为20
这样就刚好能跑完20*25=500张train图片,这样就称为1个epoch
然后我的test net 是 batch_size = 20,考虑到我这里一共有100个test数据,所以把solver 中的test_iter设置为 5
这样5*20=100张train图片,这样我在1个epoch之内也刚好覆盖完了所有的test数据
我的max_iter = 500,这样就一共经过了 500÷20 =25个epoch
这个max_iter 其实是一个需要自己试的参数,过大或者过小都不好,
这个例子中你可以设置为400或者600分别对应20或者30个epoch。区别不是特别大
5、训练和测试
最后一步就只有一个命令,也是我在之前讲过的caffe.bin工具./build/tools/caffe train --solver=examples/mytest/solver.prototxt
然后就开始训练和测试了
先把solver中的配置打印出来

然后就是打印train网络和test网络,这个我就不往外贴了,太长了
然后贴一下迭代过程:
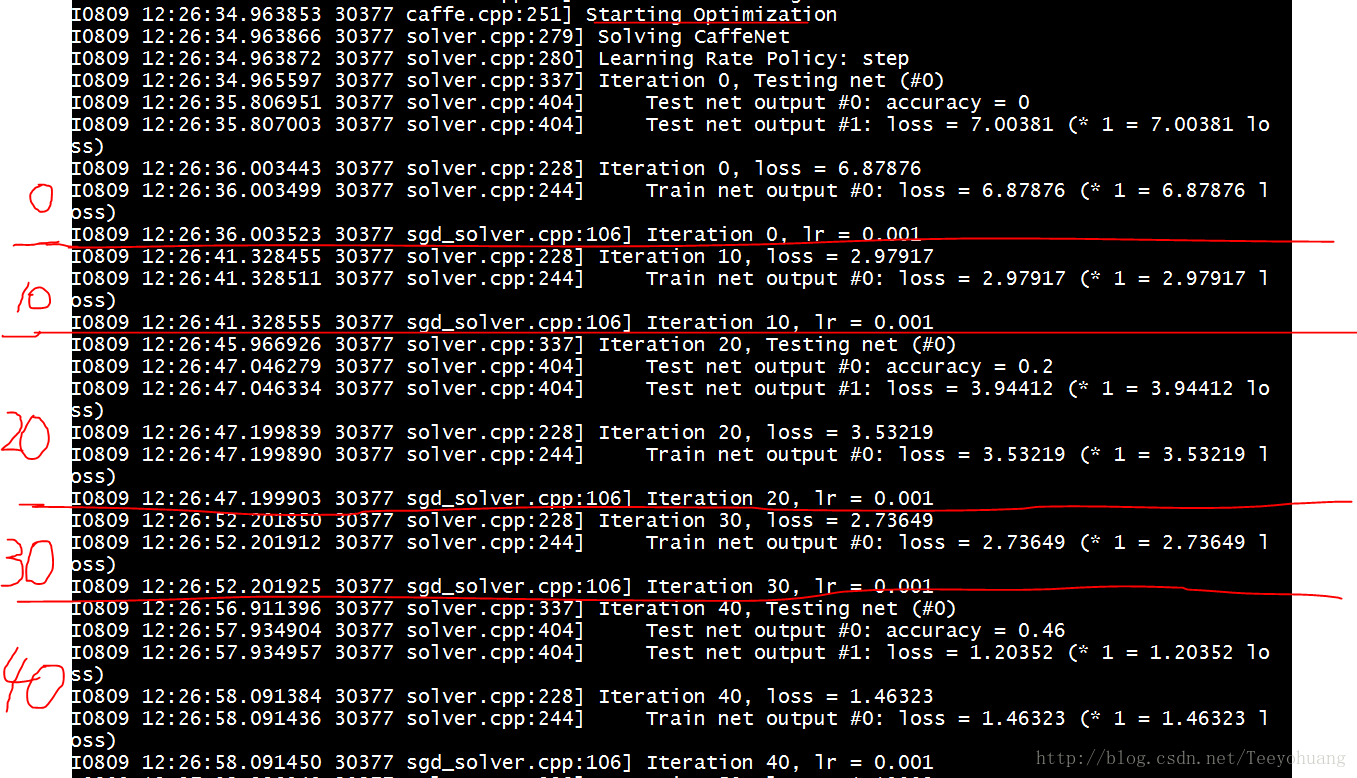
可以看到,每隔10次Iteration它打印一次,因为我的solver中的display参数设置的是10
然后只要是20的倍数就会多上几行,仔细看是Test net的输出,会输出 accuracy,因为我的test_interval=20,就是每20次train迭代就要进行test
最后500次之后结束

得到caffemodel和sovlerstate















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









