






贝叶斯网络
动机
NB的条件(非条件关联)对于大多数情况来说都是太过严苛了。
但是如果没有这些假设在很多情况下贝叶斯学习将难以进行(需要的训练集太大)
贝叶斯网络可以用来描述变量的子集以及变量之间的条件关联和非条件关联
(Erlauben somit die Kombination von a priori Wissen über bedingte (Un-)Abhängigkeiten von Variablen mit den beobachteten Trainingsdaten.???)
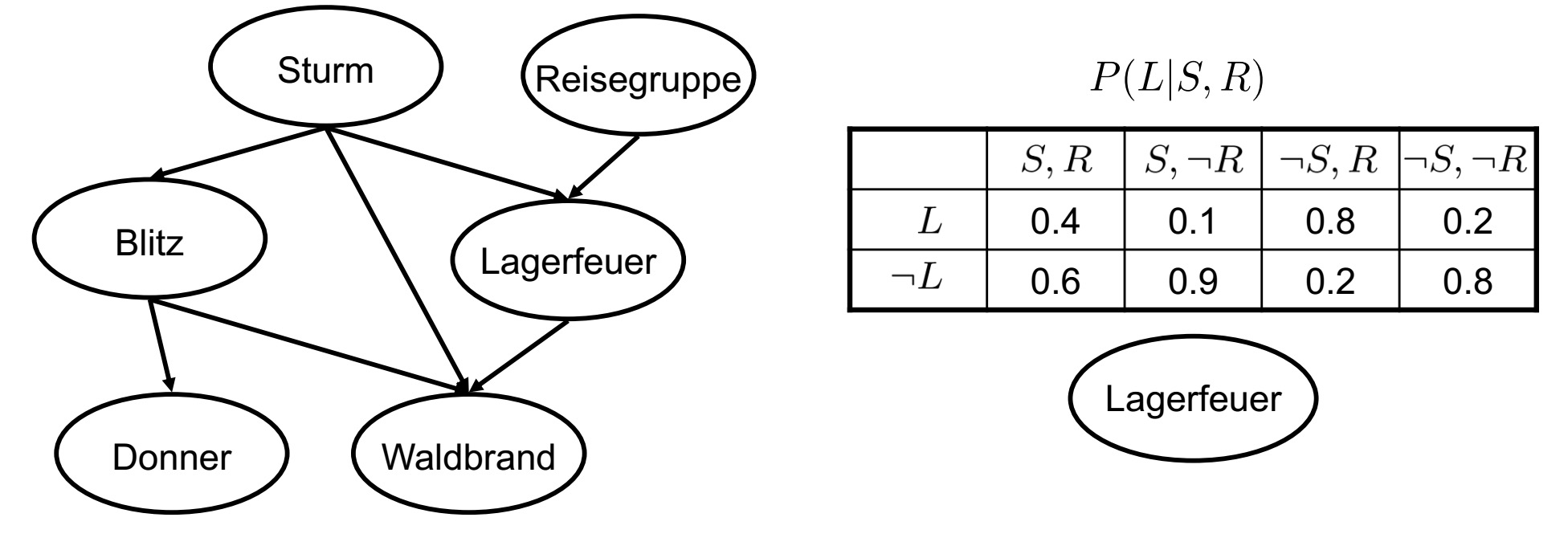
贝叶斯网络
贝叶斯网络呈现了所有随机变量的一个总得概率分布:
1.他是一个非循环的有向图
2.图中的每一个节点表示一个随机变量
3.我们说X是Y的后续(Nachfolger),当从Y出发有一条指向X的线存在。
4.图中的边保证了:一个变量在给定了他的直接前置的条件下与他所有的非后续变量非条件关联。
//只包括直接后续吗???还是???
5.每一个节点都含有一个本地表格,表格中记录了该变量在给定前置的条件下的条件概率(对图入座)。
因此我们可以通过下面的式子,计算对应的
P(y1,...,yn)
:
/*
把n项分为两项:第1项和后面n-1项,然后化简可以得到上式,但是这个P不是一个整数吗,求他有意思吗??关键的不应该是 P(y1,...,yn|vj) 吗???不会说其实上面这个图针对不是整个训练集的而只是针对特定类的训练数据吧??
*/
构建贝叶斯网络
那么在给定观察值的条件下,要如何确定网络中的各个值呢(其实还应该考虑结构不是吗???)???
网络中包括了需要的所有的信息,确定一个变量对应的数据比较简单,但是确定所有的变量对应的数据确是一个NP完备性问题
在实践中我们一般是这么做得:
1.Einige Netztopologien erlauben exakte Inferenz???
//这里的Inferenz没有理解,是说有些网络的拓扑结构可以直接引用现成的吗????
2.使用Monte Carlo方法随机模拟网络,从而求出一个近似值
贝叶斯网络:学习
问题设置:
1.网络的结构师已知的或者是未知的
2.所有的变量可以直接观察到或者只有一部分是可以直接观察到的
*对于网络结构已知,所有变量可以直接观察到的状况:
学习方法和幼稚的贝叶斯分类器的学习方法是一样的。
//是指直接数吗
*对于网络结构已知,但是只有一部分变量是可以直接观察到的的状况:
使用梯度下降,EM
*对网络结构未知的状况:
使用启发式学习方法
EM算法
EM=Expectation Maximization
问题设置:
1.只有一部分的数据是可以观察到的
2.非监督聚类(无法观察到目标值)
3.监督学习(只有实例的一些属性是无法观察到的)
实际应用:
1.可以用于贝叶斯网络的训练
2.可以用于HMM(Hidden Markov Modell)的学习
//学习和训练有差吗???
用EM确定高斯分布中值
K个高斯分布的混合
//这节就是介绍一下生成实例的方法,在下面会被用到
用一下方法生成每一个实例:
1.等概率的从k个高斯分布中选出其中的一个
2.根据这个高斯分布的概率分布随机生成一个实例
用EM确定高斯分布的中值
已知:
1.实例集X,且这个实例集是通过上面一节刚讲到的方法生成的。
2.未知的中值
<μ1,...,μk>
<script type="math/tex" id="MathJax-Element-1117"><\mu_1,...,\mu_k></script>
3.对于所有的实例
xi
并不知道他是属于那个高斯分布的
目标:
找到最接近的中值的近似值
h=<μ1,...,μk>
对已知进行一点扩展:
用一下方式描述实例:
yi=<xi,zi1,zi2>
当
xi
属于第j个高斯分布时,对应的
zij
的值为1,否则为0
→
xi
是可以观察到的,而
zij
是不可以观察到的。
总上我们可以得出:
1.当已知x和h的时候我们可以推出对应的z
2.而当知道z和x的时候我们又可以推出对应的h
在k=2的情况下对应的EM过程为:
随机初始化
h=<μ1,μ2>
E步骤:
在假定中点为h的条件下,计算对应的隐藏变量
zij
的期望
E[zij]
M步骤:
在假定隐藏变量的值为E步骤中得到的值的条件下,计算新的最可能的中点
h′=<μ′1,μ′2>
,并用得到的新的值代替原来的h。
重复EM
比如可以用下面式子计算对应的值:
EM算法的属性
1.找到局部最优,并对隐藏的数据进行推测
2.找到的最优解h’可以使得E[In P(Y|h’)]最大,其中:
Y有可观察和隐藏数据两部分组成
隐藏变量的期望值可以被计算出来
一般化的EM问题
已知:
1.观察到的数据集
X={x1,...,xm}
2.不能观察到的数据集
Z={z1,...,zm}
3.参数化了的概率分布P(Y|h)
(Parametrisierte Wahrscheinlichkeitsverteilung P(Y|h))
其中:
Y={y1,...,ym}
=X
∪
Z
h是参数
目标:
寻找假设h,并且他满足E[In P(Y|h)] (局部)最大
一般化的EM操作过程
设定:
E步骤:根据观察到的数据和当前的假设计算P(Z|X,h)
M步骤:用新的假设h’代替h,其中h’可以通过下式求出
总结
//我自己看看吧,基本没什么新的东西
1.Bayes-Methoden ermitteln a posteriori Wahrscheinlichkeiten für Hypothesen basierend auf angenommenen a priori Wahrscheinlichkeiten und beobachteten Daten.
2.Mit Bayes-Methoden kann wahrscheinlichste Hypothese(MAP Hypothese)bestimmt werden(“optimale” Hypothese)
3.Der Optimale Bayes-Klassifikator bestimmt die wahrscheinlichste Klassifikation einer neunen Instanz aus den gewichteten Vorhersagen aller Hypothesen
4.Der Naive Bayes-Klassifikator ist ein erfolgreiches Lernverfahren. Annahme:bedingte Unabhängigkeit der Attributwerte
5.Bayes-Methoden erlauben die Analyse anderer Lernalgorithmen, die nicht direkt das Bayes-Theorem anwenden.??
6.Bayes’sche Netze modellieren bedingte Unabhängigkeiten in Untermengen von Variablen.Weniger restriktiv als der Naive Bayes-Klassifikator
7.Der EM-Algorithmus erlaubt den Umgang mit nicht beobachtbaren Zufallsvariablen














 141
141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









