







目录
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
论文标题:CLIPScore: A Reference-free Evaluation Metric for Image Captioning
这一篇是针对Image Caption领域的评价指标,但是有些基于条件的Diffusion模型也使用了这个评价指标来衡量文本和生成图像的匹配程度。
背景
本文提出的CLIPScore(下文简称CLIPS)是不需要推理的评估指标,之前常见的基于推理模型的评价指标有 CIDEr 和 SPICE等(还有一些自检索的方式),类似FID和IS利用到训练好的inceptionv3网络计算图像分布之间相似性的得分。
代码链接:clipscore
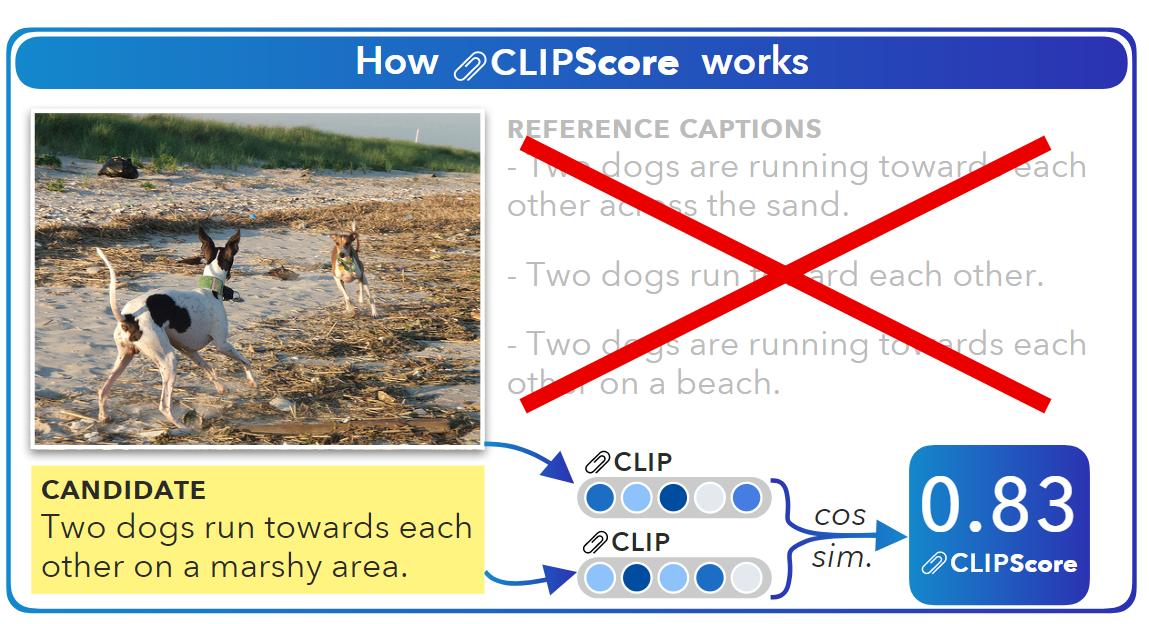
简单的原理图
公式
对于CLIP-S,作者建议使用“A Photo Depicts”作为prompt会提高效果。
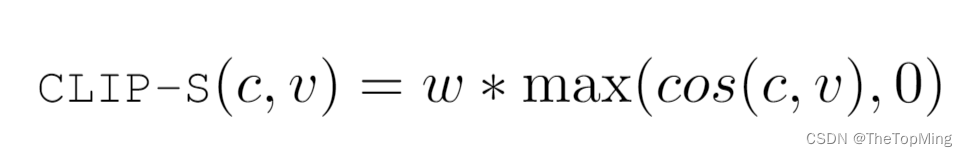
其中,c和v是CLIP编码器对Caption和图像处理输出的embedding,w作者设置为2.5。这个公式不需要额外的模型推理运算,运算速度很快,作者称在消费级GPU上,1分钟可以处理4k张图像-文本对。
CLIP-S也可以包含参考文本进行评估。使用调和平均数(harmonic mean)计算结果:
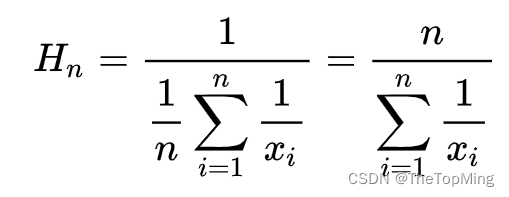
最终公式如下:
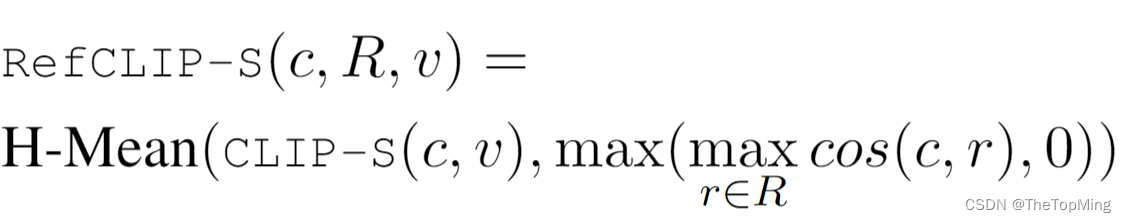
其中,R是图像对应的参考文本描述。
总结
作者建议对图像描述进行评估,一般需要一个图像感知的指标(如CLIP-S)和一个针对参考文本的指标(如SPICE)。本文的实验设置值得学习,作者通过一系列对比和巧妙设计的相关性实验,得到了CLIP-S与人类对图像描述的评估具有较高相似性的结论。
TISE: Bag of Metrics for Text-to-Image Synthesis Evaluation
背景
论文标题:TISE: Bag of Metrics for Text-to-Image Synthesis Evaluation,TISE指的是Text-to-Image Synthesis Evaluation。
这一篇针对IS指标进行了改进,在原先的IS上加入了可调节因子以适应不同数据集;同时引入O-IS和O-FID来保证目标的真实性,PA来评估位置事实,CA来评估计数事实;最后,作者使用新的指标对现有的SOTA方法进行了评估,并提出了AttrGAN++,特别是对多目标场景有更好的效果。
代码链接:TISE
这篇开头讲了好多GAN进行t2i任务的方法,让我又重新回顾了一遍-_-||
文本-图像生成基本评价指标
图像质量和多样性
首先上一个IS的计算公式,计算的是KL散度:

计算类的边缘分布p(y)和生成图像的类条件分布p(y|x)之间的KL散度。经过作者验证发现,IS的分数是不一致的,一些生成的不切实际的图像却依然有较高的得分。
然后是FID,计算的是Frechet distance:
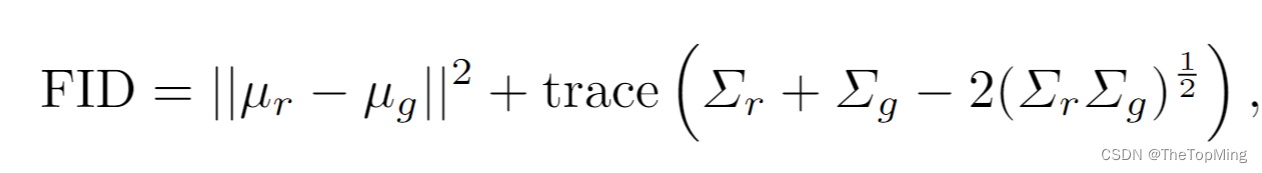
其中,Trace表示矩阵的迹。
图像和文本相关性
R-precision (RP)可以是图像和100条候选描述(只有一条正确)中判断正确的占比,也可以是图像和文本经过Encoder进行cos计算得到的相似度。
创新点1:IS*
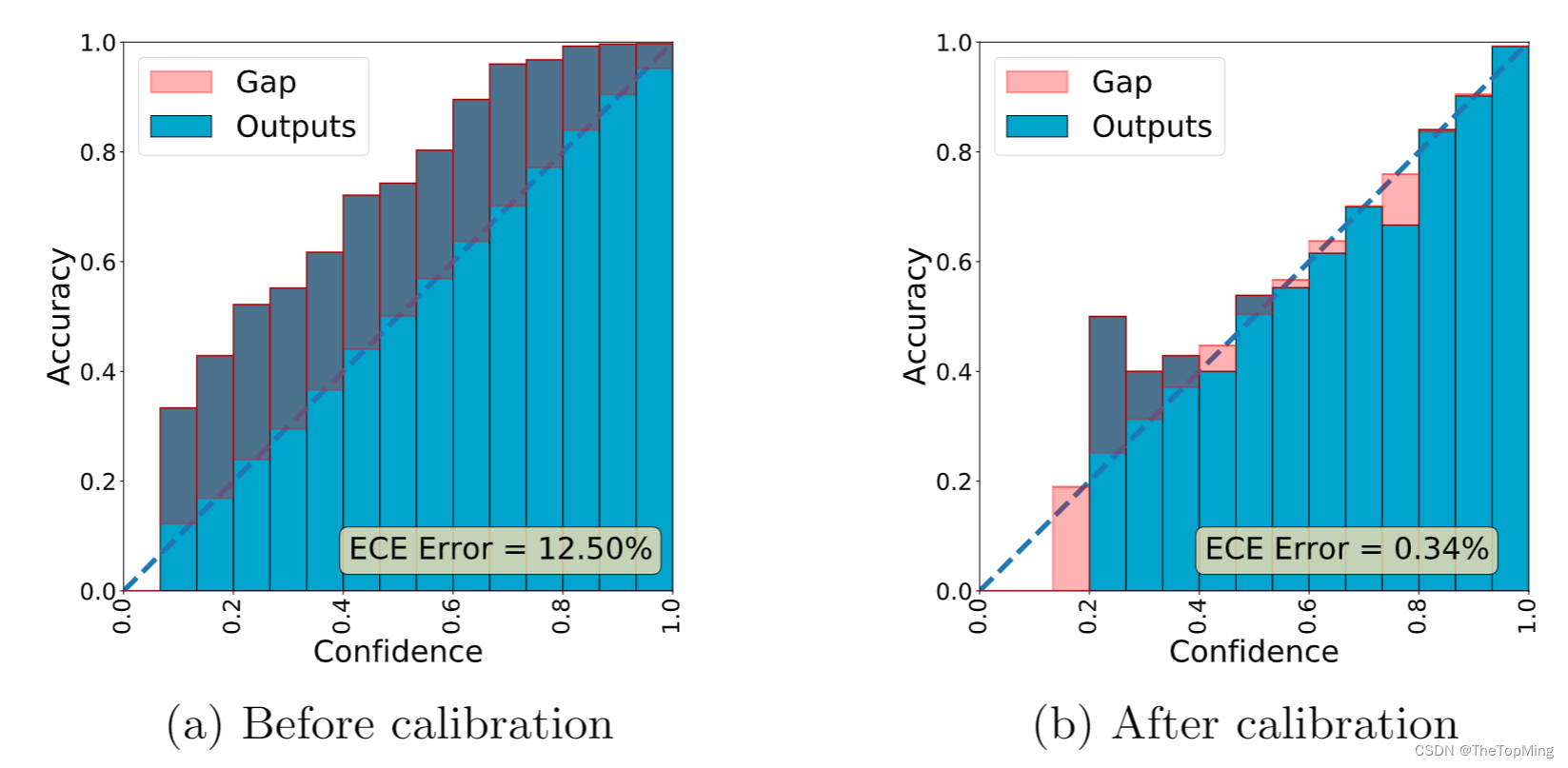
作者表示IS中预训练好的inceptionv3网络存在校准错误的问题,由于计算条件分布和边缘分布的距离不一致,给出的置信度可能过高或者过低。所以需要进行校准。
作者对分类器的置信度分数进行校准。很简单,就是在神经网络处理输出的逻辑向量进入softmax归一化层获得概率值前,对类概率进行放缩,公式如下:
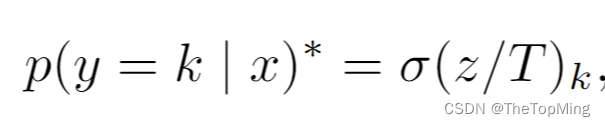
其中T 的值是通过最大化用于训练分类器的验证集上的负对数似然损失来获得的。作者在CUB上校准得到的T=0.598。校准之后,原先置信度过低的情况有所缓解,甚至一些生成的不真实的图像在IS上得分很高,在IS*上表现正常。
创新点2:多目标文本-图像生成指标
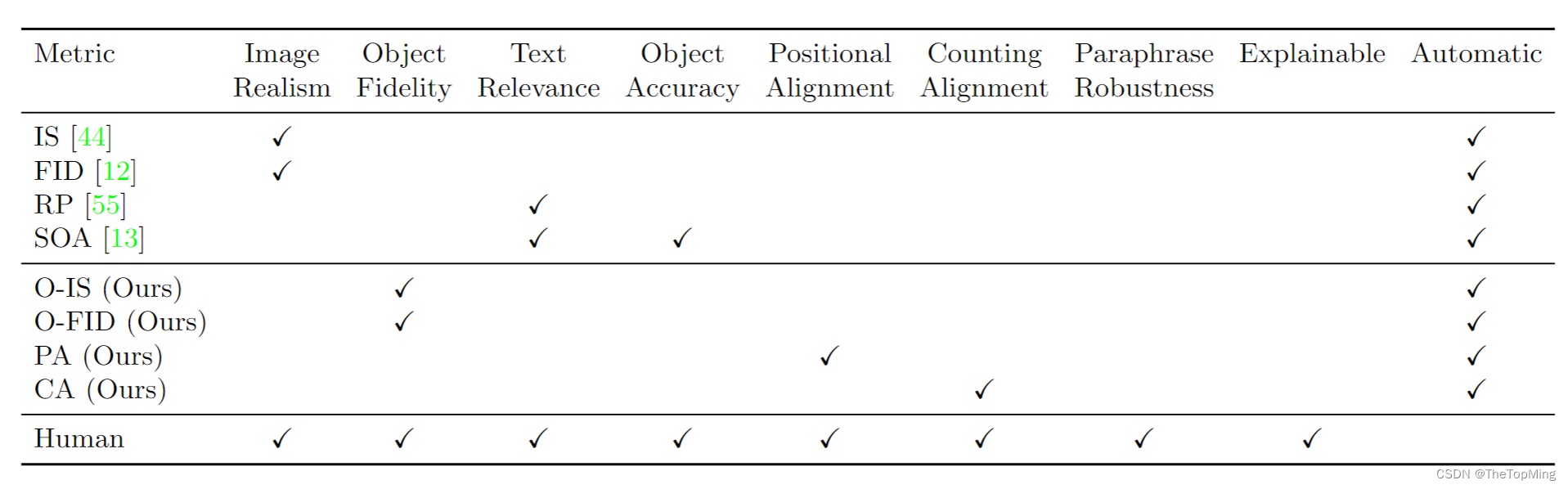
这个表格很好反映了文本到图像生成所需要的一些评价措施,除了目前常用的图像真实性评价指标之外,也有RP和SOA用来评价文本相关性和目标正确性。
预训练模型的更换
**RP(R-precision)**是通过对提取的图像和文本特征之间的检索结果进行排序,来衡量文本描述和生成的图像之间的视觉语义相似性的指标。除了生成图像的真实文本描述外,还从数据集中随机抽取其他文本。然后,计算图像特征和每个文本描述的text embedding之间的余弦相似性,并按相似性递减的顺序对文本描述进行排序。如果生成图像的真实文本描述排在前r个内,则相关。
在AttrGAN中,使用的DAMSM文本和图像编码器对多目标存在过拟合问题,作者这里将其替换为CLIP的多模态编码器。具体效果见下表,可以看到真实图像的基于CLIP的RP值最高,符合实际,其他模型也不存在过拟合问题。
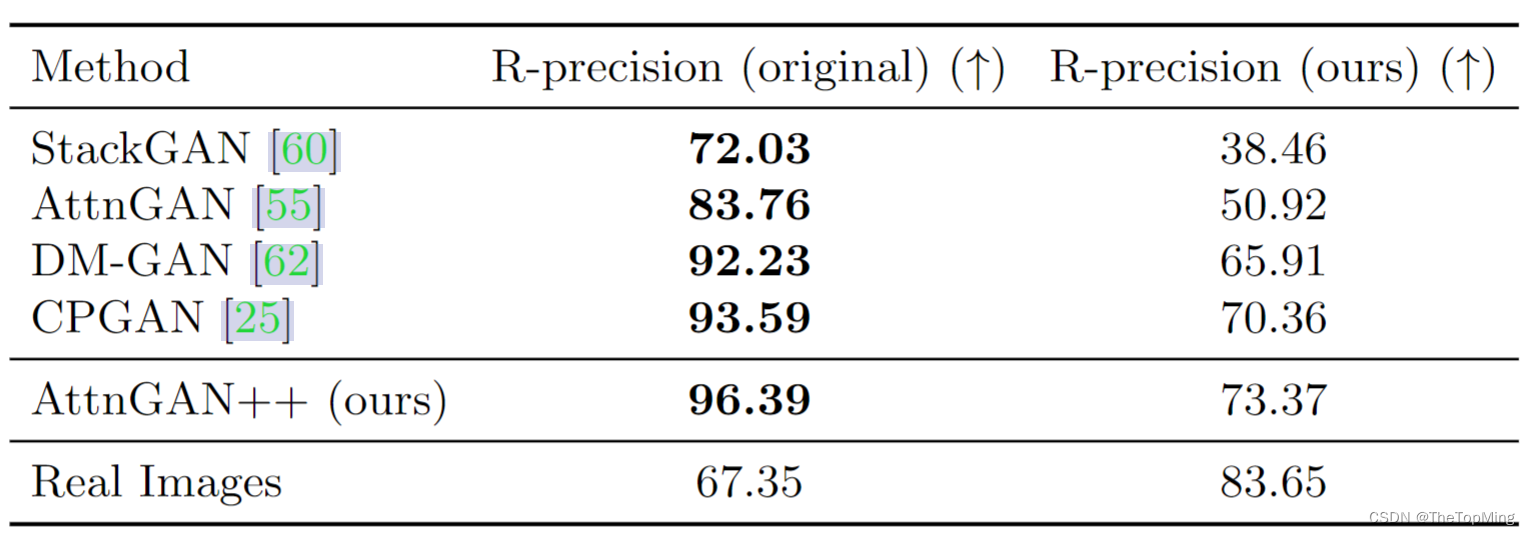
**SOA(Semantic Object Accuracy)**来衡量生成图像是否具有文本中的对象。有提出了两个子度量,包括 SOA-I(图像之间的平均召回率)和 SOA-C(类之间的平均召回率),公式为
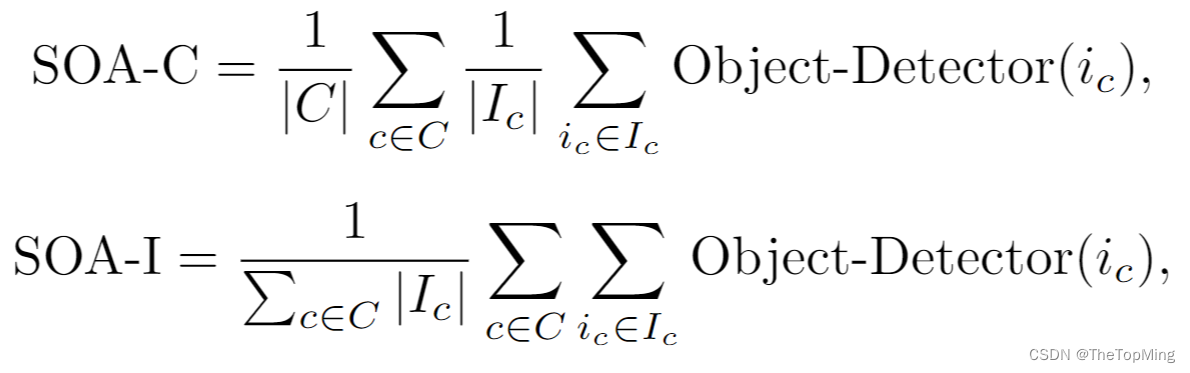
但是预训练好的YOLOv3在CPGAN上存在过拟合问题(即不真实的生成图像存在较高的SOA值,甚至高于真实图像),作者使用MaskRCNN来计算SOA值。
新的衡量指标 O-IS和O-FID
O-IS和O-FID是以对象为中心的IS和FID,旨在确保目标的保真度。
PA(Positional Alignment)
PA(Positional Alignment)是位置对齐相关的指标,作者定义了位置字表——{above, right, far, outside, between, below, on top of, bottom, left, inside, in front of, behind, on, near, under },构建<生成图像,匹配的描述,相反的描述>三元组,对每一个三元组,图像和真实的描述匹配分数高,那么就是匹配成功,公式如下:
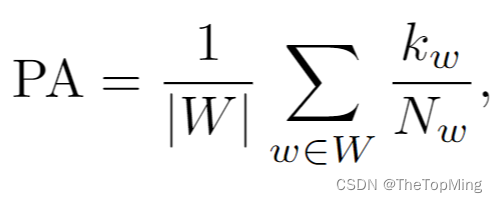
其中,N_w是带有位置单词w的句子描述数,k_w是成功的cases。基于CLIP进行计算。
CA(Counting Alignment)
CA(Counting Alignment)是计数相关的指标,在coco数据集上是{a, one, two, three, four},公式如下:
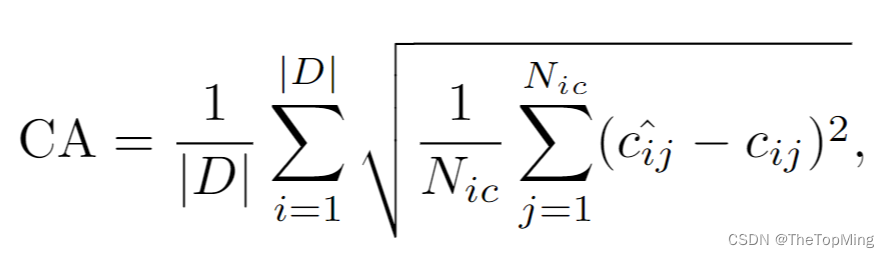
cij 和 ˆcij 是物体类别的真实的和预测的计数,N_ic 是图像 i 中可计数对象的数量,D是测试集样本数。
RS (ranking score)
来一个总结,计算所有评价指标的平均作为一个基本衡量metric:

#(metric) ∈ {1…N } 表示特定指标的排名。
一些baseline在MScoco数据集上的结果如下表:
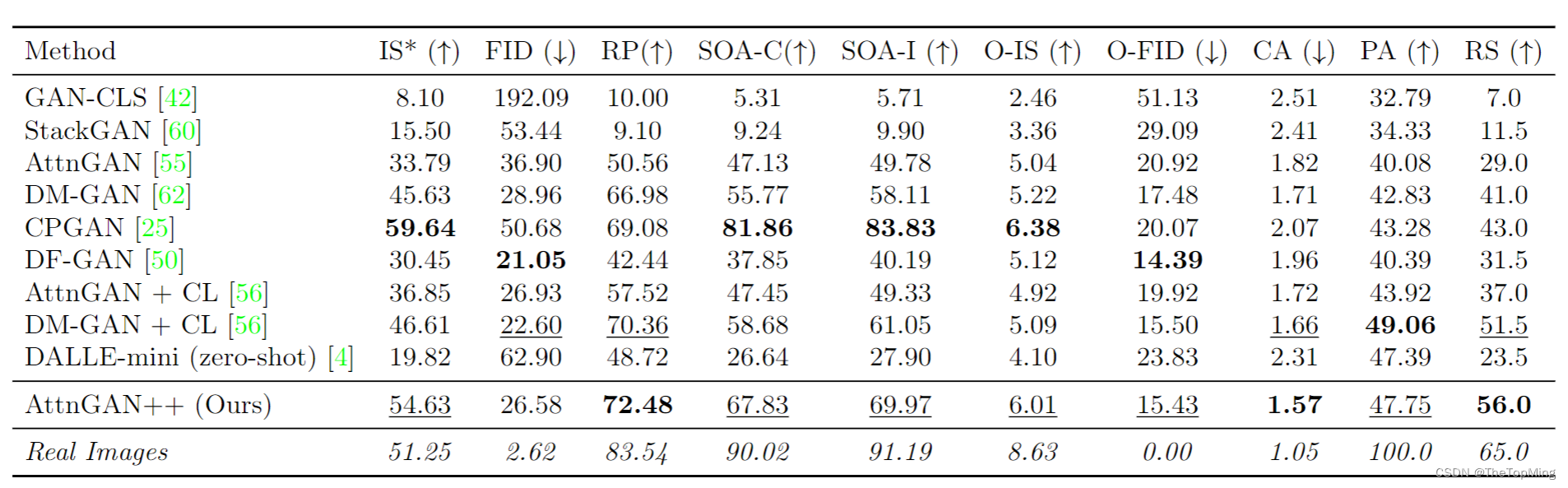
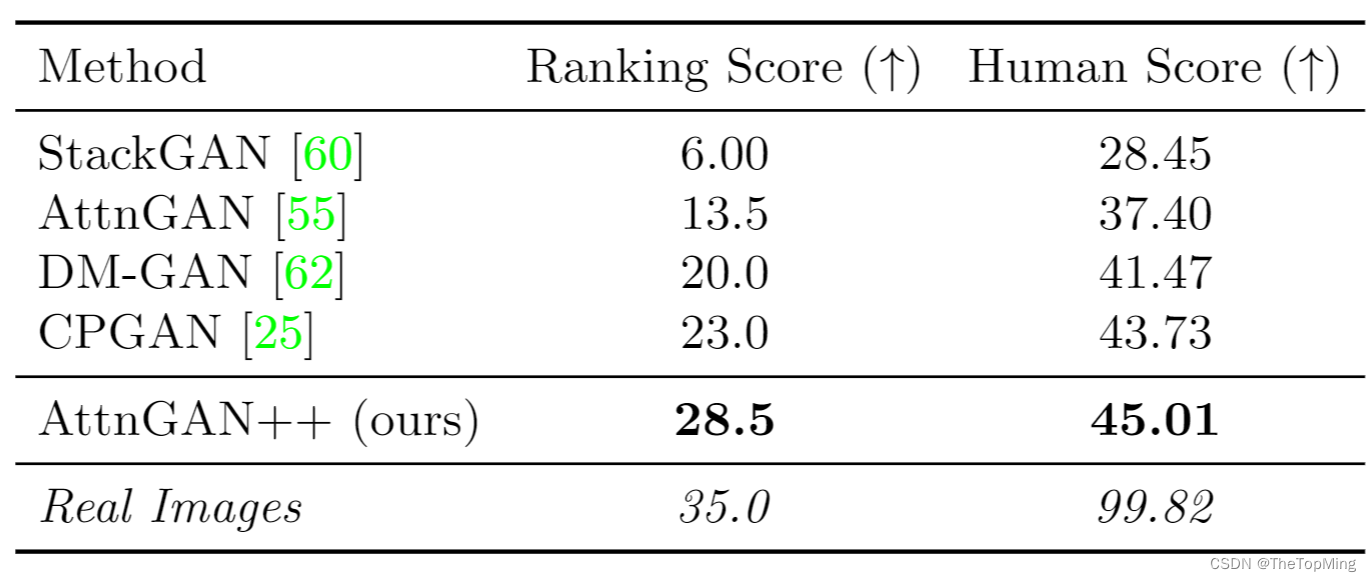
比较让人意外的是cvpr2022的DF-GAN并没有占到多少便宜,DALLE-mini使用VAGAN效果也并没有很好。待我试试。

















 3681
3681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









