







1、实验目的
学习wireshark软件使用,掌握pcap文件格式、TCP协议及数据重组知识;
2、实验工具
任意一种编程语言。
3、实验内容
A、开启wireshark软件,完成一次HTTP协议的Web网站访问并进行数据抓包,然后以pcap文件格式进行保存。
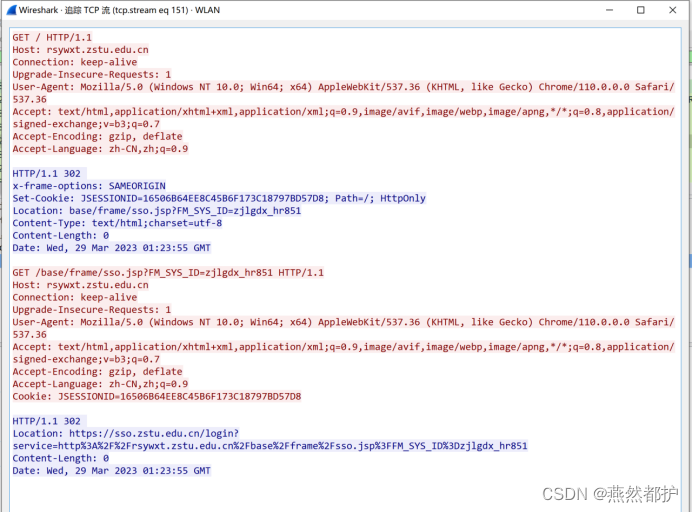
B、采用任意一种编程语言,从上述保存的pcap文件中读取数据并重组出Web网站访问的页面数据(类似下述页面的数据)
4、实验报告要求
A、对实验过程进行截图,并配合文字详述以上实验内容;
B、对实验报告中引用的互联网资料,需要以参考文献形式加以引用标注
5、实验过程
(1)访问网站并抓包
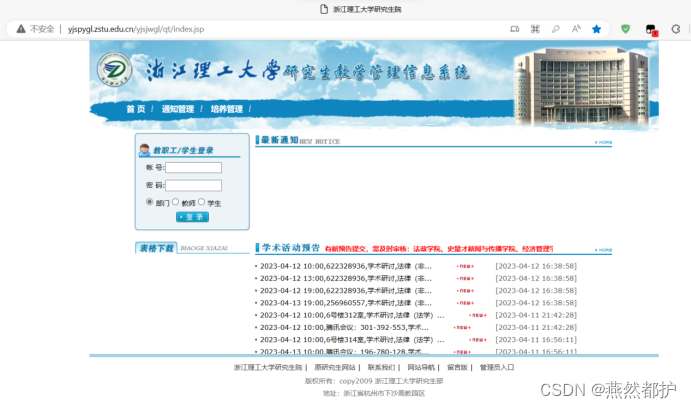
①打开wireshark进行抓包,访问网站http://yjspygl.zstu.edu.cn/yjsjwgl/qt/index.jsp。
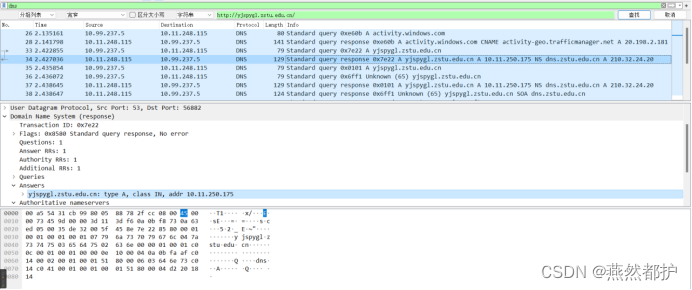
②停止抓包。在捕获结果中设置过滤条件为dns,查找包含字符串“http://yjspygl.zstu.edu.cn/”的数据包。根据dns数据包的内容,可知目标网站的IP地址为10.11.250.175。
③过滤条件设为“tcp and ip.addr == 10.11.250.175”,查找访问该网站相关的TCP流。
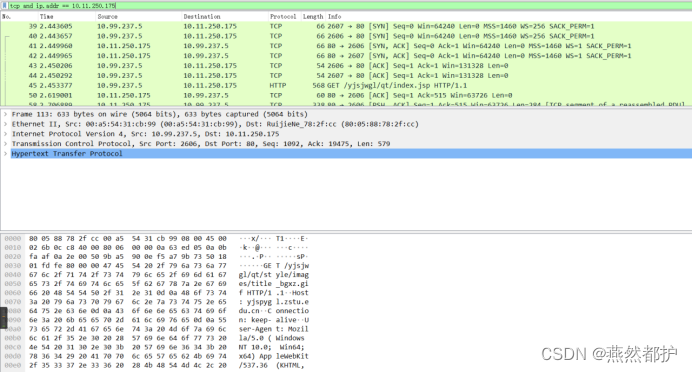
④追踪tcp流。本次实验追踪第40号数据包所在的数据流,显示结果如下,确定已捕获需要的数据包。
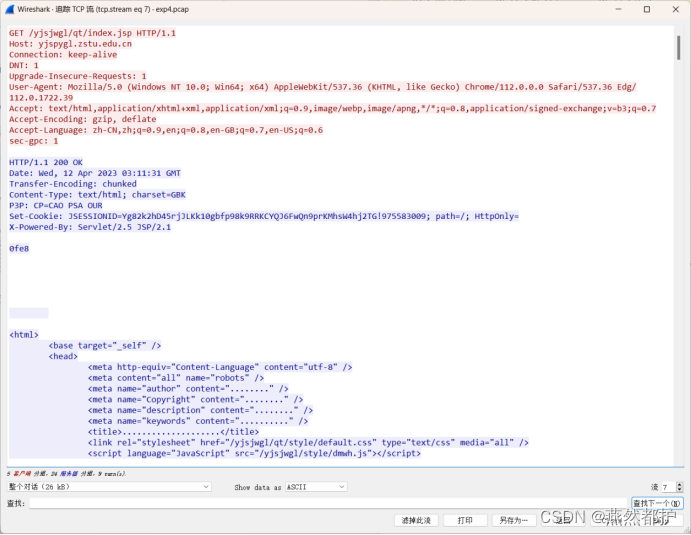
⑤保存pcap文件。
(2)编程重组网页数据
①本实验采用python语言编程,对第40号数据包所在的tcp流进行重组。代码如下:
from scapy.all import *
from scapy.layers.http import HTTP
from scapy.layers.inet import TCP
# 读取pcap文件
packets = rdpcap("D:/Wireshark/saved/exp4.pcap")
# 获取编号为40的数据包,packets的编号从0开始
packet = packets[39]
# 获取第40个数据包所在的TCP流
tcp_stream = []
for p in packets:
if TCP in p or HTTP in p and p[TCP].sport == packet[TCP].sport and p[TCP].dport == packet[TCP].dport:
tcp_stream.append(p)
# 重组HTTP流
http_payload = b""
for pkt in tcp_stream:
if HTTP in pkt:
http_payload += bytes(pkt[HTTP].payload)
# 输出HTTP流
print(http_payload.decode("gbk","ignore"))
②代码解释
首先使用rdpcap函数读取pcap文件,然后获取编号为40的数据包。接着,遍历所有数据包,找到与第40个数据包所在的TCP流相同的数据包,并将它们存储在一个列表中。最后,遍历TCP流中的所有数据包,将HTTP流重组,并使用print函数输出HTTP流。
在这段代码中,http_payload是一个用来存储重组后的HTTP流的字节串。在print函数中,使用decode函数将字节串解码,并指定解码方式为gbk。如果解码过程中出现无法解码的字符,选择忽略它们。
③运行结果
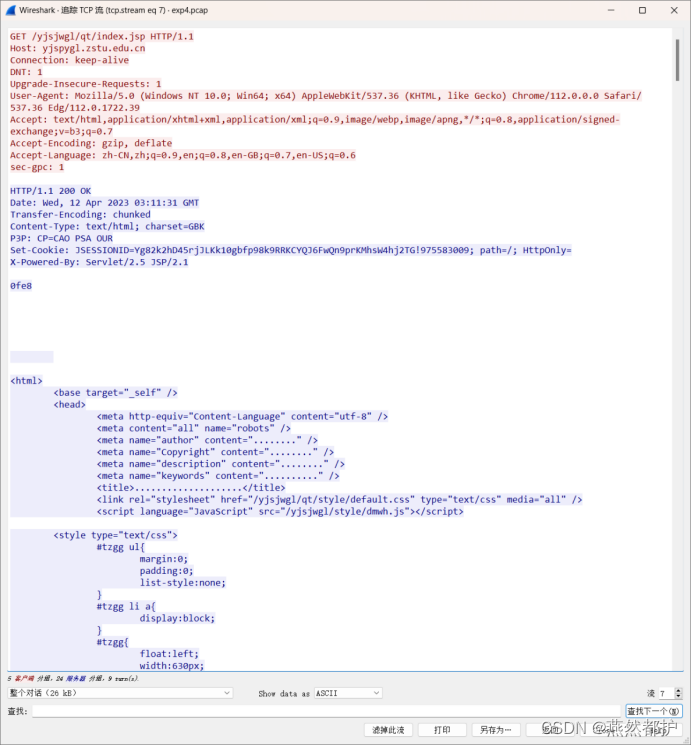
对pcap文件第40号数据包追踪tcp流的结果:
代码运行结果:
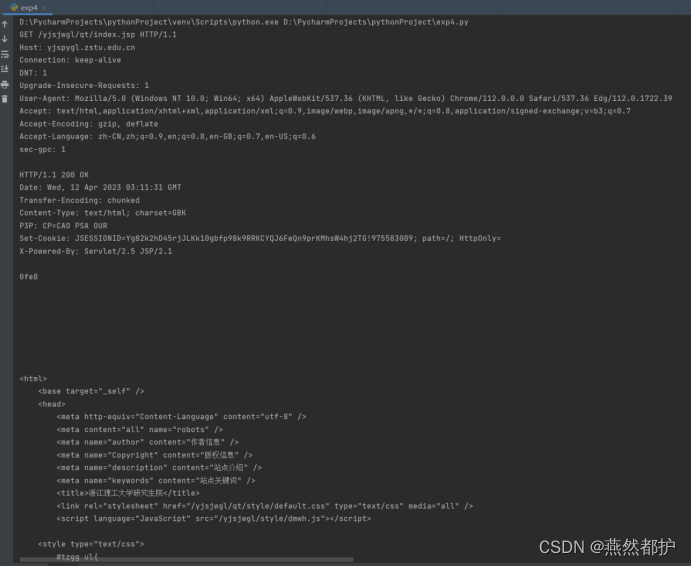
对比可以看出,成功重组出了目标网站访问的页面数据,与pcap文件中的数据一致。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









