







-
关于分区,参见《数据库分区、分表、分库、分片》。
数据表分区后,只是物理存储上分为不同的区,对于软件层面,代码处理的还是同一张表,代码不会因为分区而改变。
当需要加载的表比系统内存大,就需要使用分区表。
本文以
btcusdt_1t.csv为例进行操作。决定分区数量的原则是:每个分区的大小不超过系统内存的四分之一。 -
分区方式一:顺序分区
分区方式:根据行的顺序,将
btcusdt_1t.csv分成2区。# 构建分区数据库 db = database("D:/DolphinDB/Data/seqdb", SEQ, 2) # 将分区表并行载入 btcusdt = loadTextEx(db, "btcusdt",,"D:/DolphinDB/Data/btcusdt_1t.csv")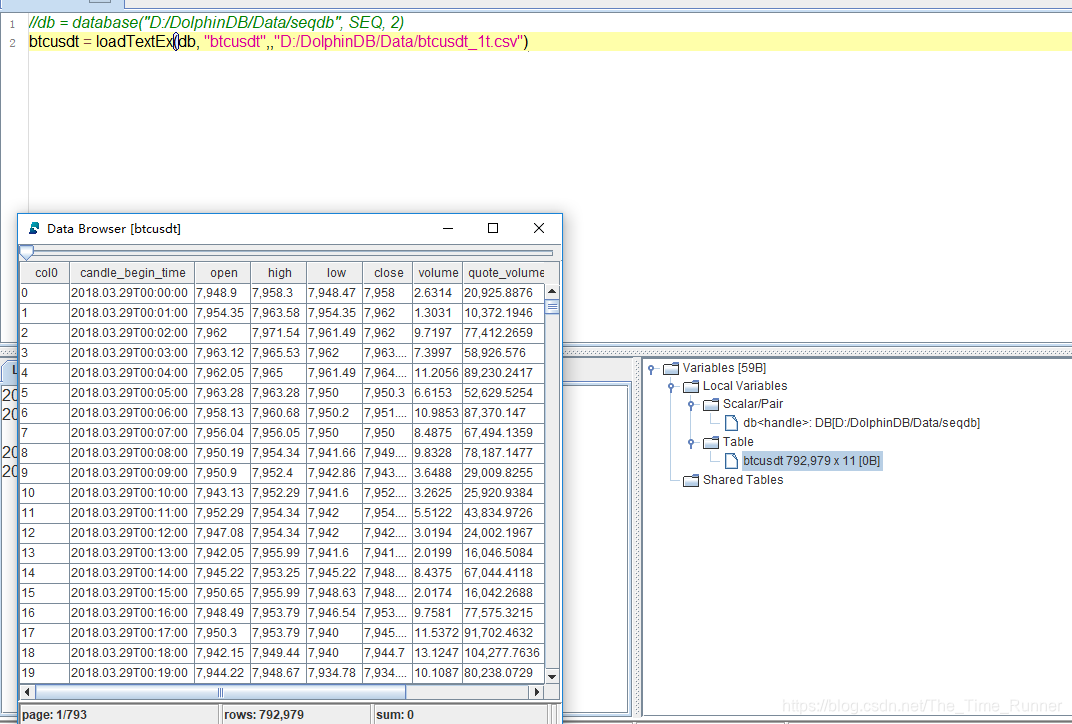
-
database数据库创建函数database(directory, [partitionType], [partitionScheme], [locations])参数 意义 备注 directory 保存数据库的目录地址 如果创建分布式文件系统中的数据库,以“dfs://” partitionType 六种分区类型 顺序分区(SEQ),范围分区(RANGE),哈希分区(HASH),数值分区(VALUE),列表分区(LIST)和组合分区(COMPO) partitionScheme 分区方案,描述分区是如何创建的 CHAR, SHORT, INT, DATE, MONTH, TIME, MINUTE, SECOND, DATETIME和SYMBOL locations 元组指定分区位置 元组中元素数量,应与分区类型、分区方案共同决定的分区数量相同。
如果不指定,则所有分区属于当前节点分区类型与分区方案对应表:
分区类型 分区符号 分区方案 顺序分区 SEQ 整型标量。表示分区的数量。 范围分区 RANGE 向量。 向量的任意两个相邻元素定义分区的范围。 哈希分区 HASH 元组。第一个元素是分区列的数据类型,第二个元素是分区的数量。 值分区 VALUE 向量。 向量的每个元素定义了一个分区。 列表分区 LIST 向量。 向量的每个元素定义了一个分区。 组合分区 COM
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















评论

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
查看更多评论
添加红包








