







1 RNN的结构
1.1 基础结构示意
核心就是:下一个的输入蕴含了上一个输出的信息

符号说明:
a^<0>等表示的激活值(是一个一维的向量,存储的是前面词的相关信息)
x^<1>等表示的是词向量(是对应字典的one-Hot形成的一维向量)
y^<1>等是预测输出(也是一维的向量,表示这词是否是人名的一部分)
具体的流程: (以仅使用前面词的信息为例)——》要使用后面词的信息,就双向循环神经网络(BRNN)
- 首先初始化激活向量a^<0>
- 然后对输入的激活向量a^<0> 和 词向量 x^<1> 利用他们对应的共享矩阵 Waa 和 Wax 和 偏置ba ——》通过tanh
计算激活向量a^<0> - 最后利用输出的矩阵Wya 和 偏置by 和激活函数 获得对应的y^<1>
- 依次重复上面的步骤
1.2 RNN 前向传播示意图:

一般开始先输入𝑎<0>,它是一个零向量。接着就是前向传播过程,先计算激活值𝑎<1>,然后再计算𝑦^<1>。
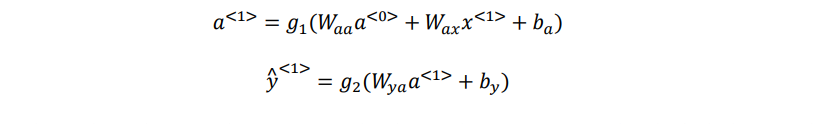
2 RNN的梯度消失和梯度爆炸
原因
DNN中各个权重的梯度是独立的,该消失的就会消失,不会消失的就不会消失。
RNN的特殊性在于,它的权重是共享的。
当距离长了,最前面的导数就会消失或爆炸,但当前时刻整体的梯度并不会消失,因为它是求和的过程。
RNN 所谓梯度消失的真正含义是,梯度被近距离梯度主导,导致模型难以学到远距离的依赖关系。
解决方案
LSTM长时记忆单元
3 RNN的演化
3.1 GRU 单元
The cat, which already ate ……, was full.
由于RNN的缺陷——不擅长捕抓长期效应 ,提出了GRU单元,用来改变了 RNN 的隐藏层,使其可以更好地捕捉深层连接,并改善了梯度消失问题。

核心是通过“两个门”决定对前面传入的——》激活向量,到底更不更新!
符号说明:
𝑐̃^<𝑡>表示的是如果进行更新的–》激活向量
𝛤u 表示的是这个激活向量到底更不更新
𝛤𝑟 表示的是输入下一层的激活向量𝑐<𝑡>,与将更新的激活向量𝑐̃<𝑡>和上一层的激活向量𝑐^<𝑡−1>的相关性
𝑐^<𝑡> 下一层输入的激活向量
具体的流程:
【1 更新门】首先是对于前面输入的激活向量c<t-1>,以及该层的词向量x,使用激活门的权重矩阵Wu 和偏置 bu 计算对对应的值,然后将该值映射到sigma(0,1)激活函数中,决定前面的激活向量更不更新在这一层中(这一层的激活向量)
【2 相关性门】𝛤𝑟门告诉你计算出的下一个𝑐<𝑡>的候选值𝑐̃<𝑡>跟𝑐^<𝑡−1>有多大的相关性。
【3 𝑐̃^<𝑡>】 计算候选值𝑐̃^<𝑡>
【4 𝑐<𝑡>】如果更新门为0,𝑐<𝑡> = 𝑐<𝑡-1>;如果跟新门为1,𝑐<𝑡> = 𝑐̃^<𝑡>
3.2 LSTM
结构
相比GRu多了一个遗忘门


各模块可以使用其他激活函数吗?
sigmoid符合门控的物理意义
tanh在-1到1之间,以0为中心,和大多数特征分布吻合,且在0处比sigmoid梯度大易收敛
一开始没有遗忘门,也不是sigmoid,后来发现这样效果好
relu的梯度是0/1,1的时候相当于同一个矩阵W连成,仍旧会梯度消失或爆炸的问题
综上所述,当采用 ReLU 作为循环神经网络中隐含层的激活函数 时,只手言当 W的取值在单位矩阵附近时才能取得比较好的效果,因此 需要将 W初始化为单位矩阵。实验证明,初始化 W为单位矩阵并使用 ReLU 激活函数在一些应用中取得了与长短期记忆模型相似的结果















 1235
1235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









